Fragen? Antworten! Siehe auch: Alternativlos
Die haben sich vor ein paar Jahren eine Menge Feinde gemacht, indem sie bei OpenSSL 3 einmal das API umgestellt haben, und plötzlich gibt es diverse Funktionen einfach gar nicht mehr oder man kriegt fette Deprecated-Warnings beim Aufrufen.
Klar kann man sagen, dass diverse interne APIs vielleicht gar nicht erst exponiert werden sollen, aber man kann sie halt nicht einfach wegmachen, wenn es keinen anderen Weg für in der Praxis benötigte Dinge gibt.
Sie haben aber auch fine-grained locking eingeführt und das ist offenbar von einem Informatik-Fuzzy frisch von der Uni gemacht worden, der noch nie gehört hat, dass mit Locking auch Kosten verbunden sind. In Benchmarks von HAProxy sinkt die Performance selbst single-threaded um ein Dritten, multithreaded sogar um Faktor 40.
Ich wusste, dass es nicht gut ist, aber dass es so schlimm ist, das schockiert mich gerade etwas.
Wer sich noch nie angeschaut hat, wie das funktioniert, könnte annehmen, dass das eigentlich ganz einfach sein könnte. Der Compiler könnte einfach Code generieren, der eine Datenstruktur auf dem Stack führt, die man beim Stack Unwinding dann halt rückwärts durchlatscht, bis jemand die Exception fangen will.
Und, so wie ich das gehört habe, lief das auch so unter Windows, und die haben das patentiert, also konnte das niemand anderes auch so machen. Es hatte auch ein Sicherheitsproblem, nämlich das ein Stack Overflow diese Datenstruktur korrumpieren kann, um so Code Execution zu erlangen.
Also haben sich die Unixer ein anderes ABI überlegt. Wenn du Code mit Exceptions hast, dann generiert der Compiler einmal den normalen Funktionscode und danach einen im Code nicht referenzierten Codepfad, der im Exception-Fall die Destruktoren aufruft. Wie findet man den? Über Metadaten in einem ELF-Segment, das man dann halt parsen muss.
Das wird natürlich erst richtig schwierig, wenn man dynamisch linkt, was ich erstmal nicht machen wollte, weil es dann pro Shared Library ein solches ELF-Segment gibt. Und es wird noch schwieriger, weil die Spec auch sprachübergreifende Exceptions vorsieht, wenn man z.B. Java und C++ zusammenlinken würde. Hatte ich nicht vor.
Egal. Jedenfalls habe ich jetzt ein paar Anläufe gemacht, zu verstehen, was da genau vor sich geht, und was ich minimal implementieren muss.
Bisher hab ich immer auf dem Weg aufgegeben, weil man da dutzende von Funktionen vorhalten muss, und ich keine verständliche, minimale Implementation gefunden habe, von der man lernen kann, wie das funktioniert.
Diesmal habe ich mir gedacht, ich nehm einfach testweise mal die Implementation von LLVM, die es inzwischen gibt, und die auch funktioniert.
Ich habe hier also ein minimales Testprogramm gemacht, in dem eine Funktion je nach ifdef eine Exception wirft oder 23 zurückliefert, und einen Aufrufer mit einer kleinen Klasse mit einem Destruktor, damit es die nötigen ELF-Datenstrukturen überhaupt gibt.
Das Binary ohne geworfene Exception ist 17k groß.
Das Binary mit geworfener Exception ist 178k groß.
Zum Vergleich: Das ist ungefähr so groß wie das aktuelle gatling-Binary ohne OpenSSL.
Ich bin gerade ziemlich entsetzt, muss ich euch sagen. Kleine C++-Binaries sind so natürlich nicht drin, außer man verzichtet auf Exception Handling und damit auf die STL.
Wenn dein Exception Handling über 100k Code braucht, ist dein Verfahren zu komplex. Finde ich.
Update: Leser empfehlen mir gerade diesen Cppcon-Vortrag dazu, den ich irgendwie übersehen habe. Ich verfolge Cppcon-Vorträge normalerweise schon ab und zu mal.
Die haben echt den Schuss nicht gehört.
"Compromised data: Github projects, Gitlab Projects, SonarQube projects, Source code, hard coded credentials, Certificates, Customer SRCs, Cisco Confidential Documents, Jira tickets, API tokens, AWS Private buckets, Cisco Technology SRCs, Docker Builds, Azure Storage buckets, Private & Public keys, SSL Certificates, Cisco Premium Products & More!," reads the post to a hacking forum.Auffällig: Alles Cloud-Dienste. Ist das am Ende gar keine tolle Idee, seine kritischen Daten in die Cloud hochzuladen?! Hätte uns nur rechtzeitig jemand gewarnt!1!! (Danke, Mark)
Insofern wäre schon eine Ankündigung von 5% mehr Performance etwas besonderes. Amazon verspricht hier aber eher 50% mehr Performance (je nach CPU-Architektur). Das ist schon ein ziemlicher Wumms.
Bemerkenswerterweise behaupten sie auch, dabei nicht die Seitenkanalfreiheit kompromittiert zu haben, und dass sie per automatisierter Korrektheitsbeweisführung nachweisen können, dass das auch alles korrekt arbeitet. Diese Art der Beweisführung ist für einen Algorithmus dieser Komplexität ein ziemlich dickes Brett.
So und dann wird es noch krasser. Der Quell-Algorithmus lag in Assembler-Code vor, und sie arbeiten auch weiterhin auf Assembler-Ebene. Ihre Beweissoftware wurde mit der genauen Semantik aller verwendeten CPU-Instruktionen konfiguriert. Das ist ziemlich heiße Scheiße, wenn es stimmt.
Und das beste: Ist Open Source, liegt auf Github. Lizenz ist die von BoringSSL, wovon sie geforkt haben. Das ist seinerseits ein Fork von OpenSSL, den Google gemacht hat. Ihre neuen Dateien sind Apache 2.0-Lizenz oder ISC-Lizenz, d.h. können sogar in kommerziellem Code verwendet werden.
Wenig bekannt ist, dass Amazon auch eine eigene TLS-Library hat. Sogar mehrere anscheinend. Auch unter freien Lizenzen.
Ist also nicht alles Scheiße, was Amazon macht. :-)
Update: Hier ist ein Paper und hier ist eine Präsentation zu der verwendeten Software. Ausgesprochen eindrucksvoll, was die da erreicht haben!
Umgerechnet fünf Fusionskraftwerke. Aber hey, "KI" braucht ja keinen Strom, gell?
Update: Falls ihr euch übrigens gefragt habt, wo eigentlich das Geld für diese Geldverbrennungsaktion herkommen soll: Das wird bei Internet-Infrastruktur-Programmen wie NGI eingespart, die damit OpenSSL-Audits und so gemacht hatten. Das war eines der ganz wenigen EU-Förderprogramme, das tatsächlich Ergebnisse vorzuweisen hat. Liegt möglicherweise daran, dass das von den Niederländern vorangetrieben wurde, nicht von Deutschland. Bei uns wäre die Kohle bei Fraunhofer versickert, ohne Ergebnisse oberhalb der Nachweisgrenze zu zeitigen.
Update: Man könnte fast vermuten, dass Flinten-Uschi NGI absichtlich weghaben will, weil der Kontrast zu ihren eigenen "Projekten" die Korruption der CDU so deutlich zeigt. Den Präzedenzfall konnte die CDU nicht dulden, dass jemand Fördermittel nimmt und nicht bloß unter seinen Wahlspendern verteilt.
Ich glaube kein Wort.
Vor vielen Jahren hat Bill Gates mal ein vergleichbares Memo herumgeschickt, das dann Dinge ausgelöst hat. An das erinnere ich mich aber als deutlich glaubwürdiger.
Man darf nicht vergessen, dass Nadella selber derjenige war, der die Tester-Ressourcen weggestrichen hat, und Security war Teil von Testing. Das ist also kein Zufall, keine Verkettung unglücklicher Umstände, keine Naturkatastrophe, das war sein aktives, zielgerichtetes, vorsätzliches Handeln. Wenn bei Microsoft Security ausbrechen soll, dann muss aus meiner Sicht erstmal Nadella weg.
Damals lief das so, dass Bill Gates irgendwo gehört wurde, wie er erzählte, er fände XML eigentlich ganz cool, und sofort ließen alle Mitarbeiter alles stehen und liegen und bauten überall XML ein. Microsoft ist halt keine militärische Hierarchie sondern eher so eine Wiese mit lauter Maulwurfhügeln. Zu deren Koordination gibt es dann eine Hierarchie, aber die macht im Wesentlichen nichts. Man raunte sich damals Geschichten zu, dass ein Feature dreimal unabhängig von verschiedenen Teams implementiert wurde, weil es keine koordinierende Führung gab und die nicht miteinander sprachen. Das fiel dann kurz vor dem Shipping auf, und da hat man dann eines weggeschmissen und die anderen beiden ausgeliefert. Soll der Markt entscheiden!1!!
Warum erzähle ich das alles? Erstens damit ihr mal gehört habt, dass ich dem Nadella und seinem Security-Push kein Wort glaube. Ich deute das so, dass die jetzt alle Security Copilot verwenden müssen und alles noch viel beschissener wird.
Anlass für diesen Blogpost war aber eigentlich dieser Artikel über "ZTDNS". ZT wie ... Zero Trust. Zero Trust DNS ist schon als Begriff hirnerweichend dämlich. Zero Trust hat was damit zu tun, wie Server in der Firma sich zu verbinden suchende Clients betrachten. Ob als "der kommt aus unserem IP-Range, der wird schon sauber sein" oder als "das ist wahrscheinlich ein Angreifer, ich will erstmal den Ausweis sehen und danach verschlüsseln wir". DNS ist unverschlüsselt. Bleibt auch nach diesem Modell unverschlüsselt.
Ich habe das jetzt dreimal gelesen, um zu verstehen, was die da eigentlich konkret vorschlagen. Das liest sich wie eine Koks-Party der Marketing-Deppen, wo sie ein paar Mal Stille Post gespielt haben. Da tauchen ein paar Wörter auf, die etwas bedeuten. Aber insgesamt kann ich da gerade keinen Sinn erkennen.
Ungefähr so habe ich das befürchtet, wenn da ein Security-Memo rumgeht, nachdem man alle Leute rausgeekelt hat, die sich damit auskannten. Jetzt spielen da ein paar Theaterfreunde lustige Handbewegungen und dann behauptet man dem Kunden gegenüber einfach, man habe jetzt Security gemacht.
Ich glaube, was sie ursprünglich meinten, war: Hey, wir packen einfach ins Active Directory, welche Hosts du sehen kannst, und die anderen filtern wir jetzt nicht nur per Firewall sondern der DNS gibt dir gar nicht erst deren IP. Hat das einen Schutzeffekt, der über Firewalling hinausgeht? Nein. Macht das andere Dinge kaputt? Natürlich!
Ich persönlich begrüße das, wenn Windows sich weiter ins Abseits schießt. Das ist ja jetzt schon nur noch eine Werbungs-Auslieferungs-Plattform mit ein paar Member Berries, die die Leute an ältere Windows-Versionen erinnern, mit denen sie groß geworden sind.
Oh, und eine Datenabgreifplattform, natürlich.
IT RUBS THE MICROSOFT ACCOUNT ON ITS SKIN OR IT GETS THE HOSE AGAIN!
Update: Eigentlich ein Fall für Radio Eriwan. Microsoft hat ein tolles Zero Trust DNS für Security! Im Prinzip ja, ist nur weder Zero Trust noch Security noch DNS. Aber der Rest ist voll geil!!
Update: Ein Kumpel meint, das soll dann alles verschlüsselt ablaufen, über DoT oder DoH. Ich las das als optional. Vielleicht irrte ich und das soll Zwang werden. Halte ich trotzdem nichts von. Die Komplexität von DoT und DoH ist Größenordnungen über der von DNS. Da werden also mit Sicherheit Lücken drin sein, und wenn eine Sicherheitslücke in OpenSSL gefunden wird (oder halt einer anderen TLS-Implementation), dann will man die bitte upgraden können, ohne dafür die verwundbare TLS-Implementation zu brauchen.
Wie kann das funktionieren? Macht Nintendo kein SSL?
Doch, aber sie haben vor ein paar Jahren in einem Update ihre SSL-Implementation verkackt und die Pretendo-Leute haben bis jetzt darauf gesessen. :-)
Ein aktueller Fall illustriert das ganz gut: SuSE Linux Enterprise Server 15 SP4 hat eine BSI-Zertifizierung gekriegt. Ausgestellt am 15.12.2023.
Die benutzen OpenSSL 1.1.1. Das war zu dem Zeitpunkt bereits seit Monaten End-of-Life. Das steht auch im auf Dezember 2023 datierten Report drin, dass sie OpenSSL 1.1.1 verwenden.
Deren OpenSSH hat glaube ich auch noch keine Post-Quantum-Crypto drin. Weiß da jemand genaueres? War jedenfalls nicht Teil des Tests.
So, meine Damen und Herren, sieht Compliance-Sesselfurzerei aus. Kostet viel Geld, bringt weniger als nichts.
Wenn sich bei euch jemand damit bewirbt, dass er ein BSI-CC-Zertifikat habt, dann wisst ihr hoffentlich spätestens ab jetzt, was ihr von dem zu halten habt.
Update: Das Produkt selbst hatte übrigens am 31. Dezember 2023 End-of-Life, also weniger als einen Monat nach Zertifizierung (außer man zahlt LTSS). (Danke, Veit)
Sucht mal in eurem Browser die Liste der vertrauenswürdigen CAs heraus und macht euch selbst ein Bild.
Wenn ihr z.B. eine sichere Verbindung zu meinem Blog aufzubauen versucht, dann ist das Zertifikat normalerweise von Let's Encrypt signiert. Wenn, sagen wir mal, der "Verfassungs""schutz" findet, dass ich regierungsfeindliche Inhalte verbreite und reingucken will, was ihr bei mir lest, dann könnten sie sich in den Netzwerkverkehr zwischen euch und meinem Blog klemmen und einfach ein anderes Zertifikat vorzeigen.
Es gibt da natürlich Vorkehrungen, um zu verhindern, dass einfach irgendeine freidrehende staatliche Repressionsbehörde Zertifikate für anderer Leute Domains holt, aber wenn die CA unter staatliche Kontrolle steht, dann ist das natürlich nutzlos. Diese Art von Angriff ist nicht theoretisch. Letztes Jahr gab es so einen Angriff auf jabber.ru, wenn ihr euch erinnert.
Warum erzähle ich das alles? Einer der Ansätze, diesen Angriff zu verhindern, ist dass man einen anderen Cert Store angibt. Curl hat dafür eine Kommandozeilenoption. Dann übergibt man da einen Cert Store, der nur genau die CA beinhaltet, die man erwartet. Und schon hat man Certificate Pinning für Arme implementiert.
Außer man verwendet curl auf Apple-Geräten. Apples SSL-Library verwendet immer auch den System Cert Store, wo Zertifikate von unvertrauenswürdigen Organisationen wie ... Apple drin sind. Falls Apple also eines Tages findet, dass sie in alle eure Kommunikationsn reingucken wollen, um "Kinderpornos zu finden" oder was an dem Tag die Ausrede der Woche ist, dann könntet ihr euch mit --cacert bei curl nicht davor schützen.
Wer kauft solchen Leuten eigentlich ihre Produkte ab?
Bei Microsoft sind natürlich auch ein halbes Dutzend Microsoft-CAs in der Liste. Unter Linux haben die Distros in ihren Root Stores auch Dutzende von CAs drin. Insofern ist das eine berechtigte Sorge, da Certificate Pinning machen zu wollen.
TLS connect failed: error:0A00018A:SSL routines::dh key too smallIn all meinen Jahren habe ich noch nie jemanden gehabt, der SO inkompetent ist, DIESE Fehlermeldung zu erzeugen.
Ich hoffe mal nicht, dass da jemand von euch Kunde ist. Heiliger Bimbam.
speicherzentrum.de ist übrigens eine Marke von 1blu. Ja, richtig gelesen. 1blu hat noch noch Unter-"marken".
Bei 1blu ist hoffentlich auch keiner von euch, so wie die interessierte Neukunden direkt mit einem Cookieterrorbanner abwehren. Operation erfolgreich. Interessierter Neukunde vertrieben.
Oder nehmen wir an, ihr kennt euch mit Computer-Architektur aus. Ihr wisst, dass es einen Kernel gibt, und der kann Userspace-Programme laufen lassen, und stellt denen virtuellen Speicher zur Verfügung und Syscalls und so weiter. Natürlich wisst ihr, dass der Kernel grundsätzlich in den Speicher der Prozesse reingucken kann.
Wenn ihr also, sagen wir mal, curl benutzt, und der spricht SSL mit einem Gegenüber, dann kann der Kernel grundsätzlich in den Speicher gucken und die unverschlüsselten Daten sehen. Da wird jetzt niemand wirklich überrascht sein, dass das so ist, hoffe ich.
Aber die Details waren bisher nicht so attraktiv. Das war mit Aufwand verbunden. OK, du kannst gucken, welche SSL-Library der benutzt, und da stattdessen eine Version mit Backdoor einblenden als Kernel. Oder du könntest die Offsets von SSL_read und SSL_write raussuchen und dann da Breakpoints setzen, wie bei den Debugging-APIs, und dann halt reingucken. Du hättest potentiell auch mit Races zu tun. Du müsstest wissen, wie man aus einer Shared Library die Offsets von Funktionen rausholt.
Gut, aber dann denkst du da ein bisschen drüber nach, und plötzlich sieht das gar nicht mehr so schwierig aus. curl lädt openssl als dynamische Library.
$ ldd =curlDa sieht man schon, dass die Adressen irgendwie krumm aussehen. Das ist ASLR. Wenn du nochmal ldd machst, kriegst du andere Adressen. OK aber warte. Die Daten hat der Kernel ja, und exponiert sie sogar an den Userspace:
linux-vdso.so.1 (0x00007ffff7dd2000)
libcurl.so.4 => /usr/lib64/libcurl.so.4 (0x00007f1df4c66000)
libssl.so.3 => /usr/lib64/libssl.so.3 (0x00007f1df4b6f000)
[...]
$ cat /proc/self/mapsUnd innerhalb des Adressbereichs, an den so eine Library gemappt wird, bleibt das Offset von SSL_write ja konstant. Wie finden wir das? Nun, da gibt es Tooling for:
[...]
7f846a8d2000-7f846aa27000 r-xp 00028000 00:14 5818768 /lib64/libc.so.6
$ nm -D /usr/lib64/libssl.so.3 | grep SSL_writeGut, also grundsätzlich könnte man den Kernel so umbauen, dass er beim Mappen von libssl.so.3 immer bei Offset 35660 einen Breakpoint setzt, und dann könnte man da die Daten abgreifen. Das ist aber eine Menge Gefummel und Kernel-Space-Programmierung ist sehr ungemütlich. Der kleinste Ausrutscher kann gleich die ganze Maschine crashen.
0000000000035660 T SSL_write@@OPENSSL_3.0.0
Warum erzähle ich das alles? Stellt sich raus: Muss man gar nicht. Ist alles schon im Kernel drin. Nennt sich uprobes und ist per Default angeschaltet. Da kann man über ein Config-File im /sys/-Tree dem Kernel sagen, man möchte gerne hier einen Breakpoint haben. Dann kann man per eBPF ein über Kernelversionen portables Kernelmodul hacken, das sich an die uprobe ranhängt und die Daten kopiert. Dann gibt es ein standardisiertes Interface dafür, wie man von dem eBPF-Modul die Daten wieder in den Userspace kopiert, wenn man das möchte.
Was hat man dann? Ein Tool, das in alle SSL-Verbindungen via OpenSSL auf der Maschine reingucken kann. Der Aufwand ist so gering, dass man das im Handumdrehen mit nur ein paar Zeilen Code auch auf gnutls erweitern kann, und auf NSS (die Mozilla-Library). Auch den TLS-Code von Go oder von Java kann man abfangen (Java ist etwas fummelig, da würde man vermutlich einen gemütlicheren Weg nehmen).
Gut, für das Eintragen der uprobe und für das Laden von dem eBPF muss man root sein. Es ist also kein Elevation of Privilege im herkömmlichen Sinne.
Aber es immanentisiert das Problem, das bis dahin bloß theoretisch war. Aus meiner Sicht heißt das, dass man ab jetzt keinem Kernel trauen kann, den man da nicht selbst hingetan hat. Mit anderen Worten: In jemand anderes Container laufen geht nicht.
Das war schon immer klar, aber jetzt ist es immanent. Was sage ich jetzt. Die Tools gibt es sogar schon seit mehreren Jahren. Ein SSL-Abgreif-Tool war das 2. Projekt, das auf diesen Frameworks gebaut wurde. Es sind sogar mehrere Tutorials und Beispielanwendungen online, wie man das macht.
Das nimmt mich gerade mehr mit als es sollte. Wir haben die Vertrauensfrage in der IT auf jeder Ebene verkackt. Der Hardware kann man schon länger nicht mehr trauen. Anderer Leute Software kann man schon länger nicht mehr trauen. Dass man Hypervisoren und Containern nicht trauen kann, ist auch schon immer klar, daher machen die ja dieses Affentheater mit "memory encryption", damit ihr euch in die Tasche lügen könnt, das sei schon nicht so schlimm. Doch. Doch, ist es.
Das könnte mich alles im Moment noch kalt lassen. Ich hacke alle meine Software selber (bis auf den Kernel), OpenSSL ist bei mir statisch reingelinkt (d.h. der Kernel sieht nicht, dass ich da eine Library lade, von der er die Offsets kennt). Man kann mit uprobes und ebpf immer noch meine Anwendungen ausspähen, aber dafür muss man die erstmal reverse engineeren und pro Anwendung die OpenSSL-Offsets raussuchen und eintragen. Das nimmt einem im Moment das Framework noch nicht ab. Aber ihr merkt hoffentlich selber, wie gering die Knautschzone hier ist. Meine Software läuft auf einer physischen Maschine, keinem vserver. Sagt der ISP. Ihr könnt euch mal mal selber fragen, wie sicher ihr euch seid, das selber nachprüfen zu können, wenn euch euer Dienstleister das verspricht.
Ich spoiler mal: Könnt ihr nicht.
Ich glaube, da muss ich mal einen Vortrag zu machen. Das ist alles sehr deprimierend, finde ich.
Einmal mit Profis arbeiten!
Both truncations and overruns of the key and overruns of the IV will produce incorrect results and could, in some cases, trigger a memory
exception. However, these issues are not currently assessed as security
critical.Es handelt sich hier um ein out of bounds read, d.h. nicht memory corruption aber kann trotzdem die Anwendung segfaulten.Hier der interessante Teil:
This issue was reported on 21st September 2023 by Tony Battersby of Cybernetics. The fix was developed by Dr Paul Dale. This problem was independently reported on the 3rd of December 2022 as part of issue
#19822, but it was not recognised as a security vulnerability at that time.Mit anderen Worten: Es ist genau so, wie ich seit Jahren in meinen Vorträgen anprangere. Man fixt nur noch Dinge, die man als Security-Problem identifiziert. Alle anderen Bugs bleiben ungefixt offen.
OpenSSL hat eine Funktion namens OPENSSL_cleanse(ptr,len). Das ruft man auf Buffer auf, die gleich out of scope gehen, damit kein Schlüsselmaterial im Speicher rumliegt. Smarte Defense-in-Depth-Maßnahme. Inhaltlich ist das bloß ein memset(ptr,0,len).
Vor ein paar Jahren fiel auf, dass Compiler unter anderem die Funktion haben, sogenannte Dead Stores wegzuoptimieren. Das hier ist z.B. ein dead store:
void foo() {
int i;
for (i=0; i<5; ++i) {
puts("huhu");
}
i=0; /* Hat keine Auswirkungen, kann weg */
}In welchem Kontext benutzt man jetzt OPENSSL_cleanse? In so einem hier:char key[128]; [...] OPENSSL_cleanse(key,sizeof(key)); return 0; }Wenn der Compiler versteht, dass OPENSSL_cleanse keine Seiteneffekte hat außer key zu überschreiben, dann ist das ein klarer Fall für die Dead Store Elimination. Ähnlich sieht es mit einem memset() vor einem free() aus.
Das ist vor ein paar Jahren aufgefallen, dass Compiler das nicht nur tun können sondern sogar in der Praxis wirklich tun. Plötzlich lagen im Speicher von Programmen Keymaterial herum. Also musste eine Strategie her, wie man den Compiler dazu bringt, das memset nicht wegzuoptimieren. Das ist leider in portablem C nicht so einfach. Hier ist, wie ich das in dietlibc gemacht habe:
1 #include <string.h>
2
3 void explicit_bzero(void* dest,size_t len) {
4 memset(dest,0,len);
5 asm volatile("": : "r"(dest) : "memory");
6 }Das magische asm-Statement sagt dem Compiler, dass der Inline-Assembler-Code (der hier leer ist) lesend auf dest zugreift, was er aber nicht tatsächlich tut. Damit ist der memset kein Dead Store mehr und bleibt drinnen. Leider ist das asm-Statement eine gcc-Erweiterung (die aber auch clang und der Intel-Compiler verstehen).Hier ist die Lösung von OpenSSL:
18 typedef void *(*memset_t)(void *, int, size_t);
19
20 static volatile memset_t memset_func = memset;
21
22 void OPENSSL_cleanse(void *ptr, size_t len)
23 {
24 memset_func(ptr, 0, len);
25 }Die Idee ist, memset nicht direkt aufzurufen sondern über einen Function Pointer. Wenn man den volatile deklariert, dann muss der Compiler annehmen, dass sich der Wert asynchon ändern kann. Kann er aber nicht, weil da nie jemand was anderes als memset reinschreibt. Das kann gcc leider erkennen, weil die Helden von OpenSSL das static volatile deklariert haben, und es damit nur innerhalb dieser Compilation Unit sichtbar ist, und da sind keine anderen Zugriffe. Niemand nimmt auch nur die Adresse davon.Wenn ich das mit einem aktuellen gcc 13.1 übersetze, kommt eine Zeiger-Dereferenzierung heraus. Aber in dem Binary kommt ein ... inline memset raus. Die haben ihr altes OpenSSL mit einem alten gcc gebaut.
Gut, der alte gcc ist nicht schlau genug, dann Calls zu OPENSSL_cleanse wegzuoptimieren, insofern ... Operation erfolgreich?
Ich blogge das hier, damit ihr mal gehört habt, dass es im Umgang mit immer schlauer werdenden Compilern Untiefen gibt, die man möglicherweise intuitiv nicht auf dem Radar hat.
Update: Wenn ihr in eurem Code das Problem habt, könnt ihr explicit_memset nehmen, das setzt sich gerade unter Unix durch, oder explicit_bzero, das kam von den BSDs, oder memset_s unter Windows. Die Situation ist immer noch insgesamtn unbefriedigend.
Update: Mit C23 kriegen wir dann endlich memset_explicit. Ist dasselbe wie explicit_memset. Habe ich gerade mal in dietlibc eingepflegt.
Das ist das schöne an freier Software. Wenn sie zerbricht, gehören dir die Scherben!
Die gibt er dann mit einem magischen setsockopt dem Kernel, und dann kann man mit dem Socket einfach wie früher read, write und sendfile machen und der Kernel übernimmt die symmetrische Krypto und die TLS-Paketierung.
Warum würde man das machen wollen? Nun, es gibt zwei Gründe. Erstens kann man so wieder sendfile machen. sendfile kriegt einen Socket, einen File Descriptor, ein Offset und eine Länge, und schickt dann das Segment aus der Datei über den Socket raus. Im Gegensatz zu traditionellem read und write spart das einmal eine Kopie der Daten. Das Google-Stichwort ist dann auch Zero-Copy.
Nun, zero copy macht Kernel-TLS natürlich auch nicht draus, der muss ja die Daten verschlüsseln und das macht ja auch eine Kopie. Allerdings gibt es Netzwerk-Karten, die TLS Offload beherrschen. Ich habe sowas nicht, aber es existiert, und dann kann der Kernel die Krypto direkt durchreichen an die Hardware, und kann es möglicherweise gar einrichten, dass die Netzwerkkarte sich die zu schickenden Daten direkt per DMA vom NVMe holt, oder halt aus dem RAM, ohne dass der Kernel die anfassen muss.
Naja gut, denkt ihr euch jetzt vielleicht, aber macht das wirklich so viel aus? Nicht bei Fast Ethernet und Gigabit geht auch noch ohne. Aber bei 10 und 100 GBit kriegt man die Leitungen ohne Zero Copy nicht saturiert. Und natürlich hat man mehr Ressourcen für andere Arbeit auf dem Server, je weniger man mit sinnlosem Hin- und Herkopieren von Daten verbraucht.
gatling habe ich damals explizit mit dem Ziel geschrieben, mich mal in Zero-Copy-TCP einzuarbeiten, aber das ist mit TLS erstmal wertlos. Bis jetzt.
Zu meiner großen Freude unterstützt OpenSSL seit Version 3 das zumindest auf dem Papier. Allerdings konnte ich das nicht funktionieren sehen. Heute habe ich das mal debugged. Auflösung: Die Kernelheader in /usr/include/linux waren zu alt :-)
Heute habe ich das zu Laufen gekriegt, und hatte bei wget einer 1 GB-Datei über das Loopback-Device sowas wie 1 GB/sec Durchsatz.
Das war mit dem alten TLS-Code, der mmap+SSL_write machte. Da hat man dann kein sendfile. Daher hat OpenSSL 3 eine Funktion namens SSL_sendfile nachgereicht. Die konnte man in meiner Abstraktion in libowfat nicht benutzen, daher hab ich die heute ein bisschen erweitert und dann in gatling per Callback SSL_sendfile eingebaut, und dann hatte ich im selben Test 1,9 GB/sec Durchsatz.
Fand ich sehr beeindruckend, muss ich euch sagen. Schön zu sehen, dass sich die Technologie auch ein bisschen weiterentwickelt.
In der Praxis wird das bei meinem Blog oder so nicht viel bewirken, weil der Großteil der CPU-Zeit da für das Handshake draufgeht, nicht für die symmetrische Krypto. Trotzdem. Hocherfreulich, wenn in der IT mal was schneller wird, und nicht immer nur langsamer und bloatiger.
Update: Richtig konsequent zuende getrieben hat das Netflix, wobei die allerdings FreeBSD und nicht Linux verwenden. Die haben dazu einen ziemlich sehenswerten Vortrag gehalten: Folien, Video.
Update: Oh und natürlich hilft Kernel-TLS mit Offloading auch auf schwachbrüstigen Embedded-SOCs, die auf Kosten- und Stromsparen ausgelegt werden, nicht auf CPU-Power.
Es war ein Buffer Overflow im Punycode-Decoding. Punycode ist ein schrottiges Encoding für Sonderzeichen in Domains.
Es gibt einen Critical 0day gegen OpenSSL, aber wir verraten ihn euch erst in einer Woche.Hey, mit solchen Leuten willste doch zusammenarbeiten, nicht wahr?Ihr seid jetzt alle gefickt, GEFICKT MWAHAHAHA!!1!
Ich glaube, Hyundai hat da gerade die neue Referenz gesetzt.
A developer says it was possible to run their own software on the car infotainment hardware after discovering the vehicle's manufacturer had secured its system using keys that were not only publicly known but had been lifted from programming examples.Ja, richtig gelesen! Die haben mit Schlüsseln aus Programmierbeispielen "verschlüsselt"!Und nicht nur das. Sie haben die Keys auch noch auf ihre Webseite hochgeladen.
As luck would have it, "greenluigi1" found on Mobis's website a Linux setup script that created a suitable ZIP file for performing a system update.The script included the necessary ZIP password for the system update archives, along with an AES symmetric Cipher-Block-Chaining (CBC) encryption key (a single key rather than an RSA asymmetric public/private key pair) and the IV (initialization vector) value to encrypt the firmware images.
Gut, aber das hatten wir ja schon häufiger, dass Leute ihre Keys bei Github und co hochluden.Zurück zu den Keys, wo die herkamen.
"Turns out the [AES] encryption key in that script is the first AES 128-bit CBC example key listed in the NIST document SP800-38A [PDF]".Ja gut, wenn die das ZIP-Passwort und den AES-Key öffentlich zugänglich haben, vielleicht ist dann auch der RSA-Schlüssel öffentlich!Luck held out, in a way. "Greenluigi1" found within the firmware image the RSA public key used by the updater, and searched online for a portion of that key. The search results pointed to a common public key that shows up in online tutorials like "RSA Encryption & Decryption Example with OpenSSL in C."That tutorial and other projects implementing OpenSSL include within their source code that public key and the corresponding RSA private key.
Und das, meine Damen und Herren, ist ein neuer Rekord. So viel geballte Inkompetenz habe ich persönlich noch nie gesehen.
Update: Betrifft nur OpenSSL 3.0.4, das gerade erst rausgekommen ist. Der kaputte Code kam auch erst kurz vor Release rein. Die haben also immer noch keine Qualitätssicherung bei OpenSSL. Seufz.
Der Launcher hinterlässt Logs unter Windows, in %localappdata%/epicgameslauncher/saved/logs. Dort findet man dann episch veraltete Versionen von curl, openssl und zlib, und den Grund für das Problem: Epic hat ihre AWS-Konfiguration verkackt.
Während des Login-Vorgangs versucht der eine Verbindung zu catalog-public-service-prod06.ol.epicgames.com aufzubauen, und da kommen so ein Dutzend oder so verschiedene IPs zurück, von denen eine zu funktionieren scheint (vielleicht auch mehr), aber andere werfen Fehler von "Unknown CA" über "certificate expired" und "hostname not found in certificate".
Using libcurl 7.55.1-DEVDa fragste dich doch echt, was diese Leute beruflich machen.supports SSL with OpenSSL/1.1.1
supports HTTP deflate (compression) using libz 1.2.8
Ich hab versucht, das bei deren Support-System zu melden, aber die sagen, meine E-Mail sei ungültig. Tja, dann halt nicht.
Aktuell sind curl 7.83.1 (gab die eine oder andere Vuln seit dem), OpenSSL 3.0.4 (gab die eine oder andere Vuln seit dem), 1.2.12 (1.2.8 ist von 2013!!). Finde ich unverantwortlich, sowas unters Volk zu bringen.
Wenn hier also jemand jemanden bei Epic kennt, oder weiß, wer da für Security zuständig ist (falls es da jemanden gibt), dann tretet die doch mal bitte kurz. Das geht so gar nicht.
Mein Workaround war jetzt, eine funktionierende IP in der hosts-Datei festzunageln. Damit geht Login wieder. Aber jetzt wo ich weiß, was da für unsichere Komponenten drin sind, habe ich spontan kaum noch Lust, den Launcher überhaupt zu starten.
Hat sich da bei OpenSSL 3.0.1 was am API geändert, das ich übersehen habe?
Update: Ah nee, war nichts mit OpenSSL. War meine eigene Schuld :-)
Lass mich raten… weil OpenSSL so einen schlechten Ruf hat?
Tavis Ormandy hat mal geguckt, wie die ihre Signaturen ablegen. Sie haben da eine Union, in der das größte Element 16 kbit groß ist, für RSA.
Okay, but what happens if you just….make a signature that’s bigger than that?Well, it turns out the answer is memory corruption. Yes, really.
Oh. Mein. Gott.Das ist schlimmer als Heartbleed. Das ist sozusagen der Hallo Welt unter den Remote Code Execution.
Sagt mal seid ihr auch so froh, dass Mozilla ihr Geld für so Dinge wie Colorways ausgegeben hat?
Oder dafür, dass ihr endlich Werbung im New Tab kriegt?
Oder für das ungefragte Einsammeln von Telemetrie?
At Mozilla, we want to make products that keep the Internet open and secure for all. We collect terabytes of data a day from millions of users to guide our decision-making processes. We could use your help.Nein, Mozilla. Wenn ihr meine Hilfe wollt, dann löscht ihr erstmal alle Daten über eure User.Aber zurück zu diesem Bug. Tavis Ormandy ist besonders geflasht, dass Mozilla da endlos static analyzer und fuzzing gemacht hat, und die Tools haben alle grüne Lampen angezeigt. Und nicht nur doofe Fuzzer sondern aktuelle state-of-the-art Fuzzer mit Coverage-Analyse!
Mich überrascht das ja nicht so doll. Ich werde praktisch nach jedem Code Audit gefragt, wieso ihre Static Analyzer das alles nicht gefunden haben. Ihr solltet vielleicht mal weniger Geld für Tools ausgeben und mehr Geld in eure Entwickler stecken, dass die lernen, wie so ein Bug aussieht und worauf man achten sollte.
Advantageous, but not required are:- an understanding of Cryptography;
- an ability to write secure code;
Leuchtet ja auch ein. Seit wann braucht man für Arbeit an TLS ein Verständnis von Kryptographie? Oder muss wissen, wie man sicheren Code schreibt?!Nee, solche Leute sollen sich mal lieber bei SAP oder Microsoft bewerben!1!! (Danke, Ben)
Einige meinten, aber Android macht das doch auch so. Das ist offensichtlich keine Ausrede für irgendwas. Google wollte halt nicht verklagt werden, weil sie keinen Support für alte Geräte machen, falls die dann gebrickt werden, weil die Zertifikate alle nicht mehr gültig sind. Das ist in meinen Augen ein Grund für eine Klage gegen Google, weil sie vorsätzlich defekte Software ausliefern.
Die andere Art Leserbrief zitiere ich hier mal:
Wie die verlinkte Archivseite erläutert, verwendet die Telematik-Infrastruktur das Kettenmodell als Gültigkeitsmodell für die Zertifikatskettenprüfung innerhalb dieser Infrastruktur (siehe das dort verlinkte Fact Sheet). Das Kettenmodell kommt aus dem Orkus des deutschen Signaturgesetzes, seiner Zeit vorangetrieben von der damaligen "Regulierungsbehörde für Telekommunikation und Post" (RegTP), heute Bundesnetzagentur.Lasst mich hier noch ergänzen: Und wir reden hier von TLS, nicht von digitalen Signaturen unter amtlichen Dokumenten oder Verträgen!Ohne jetzt ins Detail zu gehen ist es beim Kettenmodell völlig akzeptabel und normal, Zertifikate auszustellen, die über das notAfter-Datum des Ausstellerzertifikats hinausgehen. Die nachvollziehbare Grundidee dahinter ist, dass eine geleistete Signatur als Willenserklärung ja nicht plötzlich ungültig werden sollte, nur weil das Signaturzertifikat abgelaufen ist. Die Idee ist richtig, aber die Umsetzung in Form des Kettenmodells ist ein historischer Fehler, über den ich mit den Verantwortlichen bei der RegTP damals schon kontroverse Gespräche führen durfte - ohne Erfolg, versteht sich.
Das größte Problem des Kettenmodells ist, dass der Rest der Welt das Schalenmodell nach RFC5280 (Kapitel 6.1; "validation process", Punkt d) zur Gültigkeitsprüfung verwendet, bei dem erwartet wird, dass die Gültigkeit eines untergeordneten Zertifikats innerhalb der Gültigkeit des jeweiligen Ausstellerzertifikats liegt.
Nahezu die komplette Software in unserer Welt, die in irgendeiner Weise Zertifikatsprüfungen macht, verwendet das Schalenmodell, bis auf einige ranzige Spezialsoftware, die explizit für den Einsatz in der deutschen Behördenwelt geschrieben wurde und technisch gesehen RFC5280 verletzt.Oder alternativ könnte man auch einfach aufhören, die einschlägigen Standards zu verletzten, weil ein paar Sesselfurzer einer deutschen Behörde das mal irgendwann so zu Papier gefurzt haben.Der Grund für den Ausfall ist nun offenbar, dass die Telematik am Kettenmodell festhält - und zwar auch für Zertifikate die für TLS verwendet werden. Das Root-Zertifikat ist abgelaufen, aber die ausgestellten Zertifikate unter dieser CA sind laut Kettenmodell weiterhin gültig, nicht jedoch nach dem Schalenmodell. Das ist aus meiner Sicht ein heftiger Architekturfehler, sinnvollerweise wären da besser zwei PKIs zum Einsatz gekommen, eine nach Schalenmodell für den ganzen Technologiestack einschließlich TLS und von mir aus eine nach dem irrsinnigen Kettenmodell.
Das Problem dürfte nun sein, dass die verwendete Software der Teilnehmer offenbar auf Standard-Cryptobibliotheken wie OpenSSL, JCE oder der Windows Crypto API beruht und diese nun für den TLS-Handshake verwendet. Diese Software setzt aber wie erwähnt das Schalenmodell um. Und diese Software dreht nun erwartungsgemäß den Bauch nach oben, wenn in der Zertifikatskette zu einem noch gültigen Zertifikat ein abgelaufenes Zertifikat auftaucht. Das erklärt auch wiederum, warum in manchen Umgebungen dann die Zertifikatsprüfung komplett abgeschaltet wurde - weil es im normalen Betrieb vermutlich andauernd zu solchen Problemen kommt, die aufgrund der unterschiedlichen Interpretation des Gültigkeitsmodells auftreten.
Ich versuche also, gatling dagegen zu bauen. Ich kriege drei Deprecation-Warnungen vom Compiler.
OK, mal gucken, was die Manpage sagt, was man statt DH_free machen soll.
Ach gucke mal. Die Manpage erwähnt nicht mal, dass das jetzt deprecated ist. Geschweige denn sagen sie, was man stattdessen machen soll.
Großartige Arbeit, Team OpenSSL! Was macht ihr nochmal beruflich?
Knalltüten, elende.
Also hopp hopp, schön updaten alle.
Grund für Panik besteht wahrscheinlich nicht, außer eure Anwendung verwendet von Hand die ASN.1-Popel-Routinen oder den chinesischen Regierungsstandard SM2. Wenn ich das richtig sehe, ist der aktuell nur zu Fuß über das EVP-Interface erreichbar, und kann nicht per TLS erreicht werden.
Trotzdem solltet ihr alle updaten. Sofort. Immer alles sofort updaten!
Update: Ich muss an der Stelle meiner Enttäuschung ein bisschen Luft machen. Dieser SM2-Bug ... es gibt da ein beliebtes Muster, wie man Funktionen aufbaut, die variabel viel Daten zurückgeben. Entweder die Funktion gibt einen frisch allozierten Puffer zurück. Das ist am einfachsten, aber aus irgendwelchen Gründen unpopulär. Daher hat sich das populäre Muster herausgearbeitet, dass du die Funktion zweimal aufrufst. Das erste Mal mit einem ungültigen Zielpuffer, dann sagt er dir, wieviel Platz er im Puffer braucht. Dann holst du dir einen Puffer in der Größe und rufst es nochmal auf.
Ihr merkt schon: Wir haben es hier mit einem "You had ONE Job"-Szenario zu tun. DIE EINE Sache, auf die man achten muss, ist dass der nicht eine kleinere benötigte Größe zurückliefert beim ersten Mal. Und jetzt ratet mal, was OpenSSL hier verkackt hat.
Und das ausgerechnet in einer westlichen Implementation eines chinesischen Standards! Da stellen sich direkt ein paar unangenehme Fragen, finde ich.
Seufz. Seit dem Stress neulich hatte mein gatling gerade 10 Tage Uptime zusammen.
Tim Sweeney von Epic Games hat mal öffentlich gefragt, wieso ISO-Standards eigentlich nicht frei im Netz stehen. Er hat das ein bisschen undiplomatischer formuliert.
Ich persönlich fand das nicht schlau, da das Wort "Hobbyisten" in den Mund zu nehmen, weil das unnötig abwertend klingt. OpenSSL und ffmpeg sind beides Hobbyisten-Projekte, die auf Standards basieren, die zumindest zur Projektgründungszeit nicht frei zugänglich waren.
Erstmal: Das ist nicht bloß die ISO. Fast alle Standardisierungs-Organisationen wollen Geld für ihre Standards. SSL basiert auf X.509-Zertifikaten, das ist ein ITU-Standard, und die wollen Kohle sehen. Die ganzen MPEG-Versionen sind ISO-Standards und die wollen Kohle sehen. Ähnlich sieht das mit DVD und DVB aus, und so weiter.
Tim Sweeney mag ein oller Troll sein, der sich u.a. gerade einen Don-Quijote-Scharmützel mit Apple liefert, aber an der Stelle hat er völlig Recht.
Jedenfalls sprang auf die Debatte schnell Mikko Hyppönen auf, und dann ... hat die ISO Mikkos Sarkasmus kommentiert.
Ja, richtig gesehen. Mikko hat die mächtige ISO mit beißendem Sarkasmus zu einer Reaktion provoziert. Und was sagt die ISO? Nun, das zitiere ich hier mal in Gänze:
Hello, unfortunately, the ISO Central Secretariat does not provide free copies of standards. All ISO Publications derive from the work and contributions of ISO and ISO Members that contain intellectual property of demonstrable economic value.Die ISO sagt: Wir nehmen Geld, weil wir können.For this reason, considering the value of standards, their economic and social importance, the costs of their development and maintenance, we and all ISO Members have the interest to protect the value of ISO Publications and National Adoptions, not making them publicly available."Fuck you", sagt die ISO. Wir können Geld nehmen, also tun wir es.Gut, dass wir das mal geklärt haben.
Kurzfassung: GnuPG benutzt als Kryptolibrary aus religiösen, äh, Lizenzgründen nicht OpenSSL oder etwas anderes existierendes, sondern "libgcrypt", eine eigene Krypto-Library, die im Allgemeinen langsamer als andere ist und deren API noch übler ist als die von OpenSSL. Ich kenne kein Argument dafür, die gegenüber einer Alternative zu bevorzugen.
Da ist kürzlich eine neue Version released worden, 1.9, in der Assembler-Optimierungen für einige Funktionen neu dazu kamen. Unter anderem für Hashing-Verfahren. Hashing ist eine der wichtigsten Funktionen in einer Krypto-Library und spielt z.B. eine Rolle beim Validieren von Signaturen in GnuPG.
Wenn man Daten hasht, gibt es normalerweise drei Schritte. Man hat einen "Kontext", d.h. eine Datenstruktur mit dem internen Status, die initialisiert man (Funktion 1), dann ruft man so oft man es braucht "hash mal auch diese Daten hier" auf (Funktion 2), und am Ende holt man sich den Hashwert über alle bisherigen Daten (Funktion 3). Je nach Hashfunktion, für die man das macht, beinhaltet das Finalisieren noch ein mehr oder weniger abstoßendes Padding-Verfahren, denn die Hashes arbeiten normalerweise auf Blöcken von Bytes, nicht auf einzelnen Bytes.
Bei libgcrypt heißt der letzte Schritt "finalize". Der Assembler-Code nahm an, dass niemand so blöd sein würde, nach einem finalize nochmal weitere Daten hashen zu wollen, weil das nie gültige Ergebnisse liefern kann, denn da ist ja schon Padding reingeflossen.
Stellt sich raus: GnuPG macht genau das. Das sollte wohl ein halbherziger Versuch sein, einen Timing-Seitenkanal zu schließen.
Da hätte wohl der Autor von GnuPG mal mit dem Autor von libgcrypt reden sollen, denkt ihr euch jetzt vielleicht? Das ist dieselbe Person. Werner Koch.
Was heißt das? Anscheinend reicht das Öffnen einer verschlüsselten Mail mit GnuPG, um Speicherkorruption herbeizuführen und damit eventuell Remote Code Execution.
Ich habe den Bug nicht analysiert, aber wenn das stimmt, ist das auf der Krassheitsskala ungefähr so weit oben wie Heartbleed bei OpenSSL war, denn GnuPG hat keine Privilege Separation und kein Sandboxing. Die gute Nachricht ist: Das betrifft euch nur, wenn euer GnuPG so neu ist, dass er schon gegen die neue libgcrypt linkt, die vor ner Woche oder so erst rauskam.
Kann man diese Art von Bug verhindern?
Ja, kann man.
Diese Art von Bug wäre aufgefallen, wenn GnuPG eine Testsuite hätte, die z.B. mit valgrind oder dem Address Sanitizer automatisch durchläuft, bevor er eine Version released. Noch beunruhigender als dass das offensichtlich nicht stattfindet, finde ich Werner Kochs Reaktion, als Hanno Böck genau das vorschlägt. Er schließt den Bug als "invalid". Das ist selbst für Werners Verhältnisse ausgesprochen unprofessionell, aber leider nicht überraschend.
Hey, Werner, wenn du keinen Bock auf die Verantwortung hast, die der Maintainer von GnuPG tragen muss, dann übergib das Projekt doch am besten der Apache Software Foundation oder so. Jetzt wäre jedenfalls der richtige Zeitpunkt für zerknirscht Besserung geloben gewesen, nicht für close as invalid.
Ich muss dann wohl doch mal meinen OpenPGP-Code fertig machen. So geht das jedenfalls nicht weiter.
Update: Ich hatte meinen OpenPGP-Code prokrastiniert, weil ich dachte, fürs reine Signatur-Prüfen ist mein Ansatz mit der Prozessisolation vielleicht nicht nötig. Wer verkackt denn schon eine Hashfunktion, dachte ich mir.
Update: Leserbrief von Hanno Böck:
libgcrypt hat eine testsuite, und die hat den bug nicht gefunden. Müsste man jetzt genauer analysieren warum und ob das ein mangel bei der testabdeckung ist und sie den bug hätte finden sollen.
Der Punkt den ich aber kritisiert hab: Es gibt einen anderen bug in libgcrypt 1.9.0 in der testsuite, der durch asan gefunden wird. Es ist "nur" eine selbsttestfunktion, insofern ist der bug nicht so relevant, aber daraus kann man halt schließen: libgcrypt wird offenbar nicht regelmäßig vor einem release (oder via CI)mit asan getestet, sonst hätte das ja merken müssen.
Und achso, noch was: Valgrind hätte diesen Bug (also den in der testsuite) nicht gefunden. Das ist ein buffer overread in einem predefinierten array, sowas kann valgrind nicht. Siehe beispiel im Anhang.
Ich predige seit jahren dass die leute asan nutzen sollen und nicht glauben valgrind sei ein vergleichbar mächtiges tool. Ist es nicht.
Es handelt sich um eine Null Pointer Dereference, das man auslösen kann, wenn man einem OpenSSL ein böses Zertifikat gibt, das auf eine Revocation Liste zeigt, die auch böse ist, und das OpenSSL mit revocation checking läuft.
Man könnte also instinktiv sagen: Betrifft mich nicht, ich mach hier Serverseite ohne Client Certs. Und wenn ein Client segfaultet, da scheiß ich doch drauf.
Mein Rat ist: Immer alles patchen. Sofort.
gcc -march=native -dM -E - < /dev/nullDann gibt gcc alle vordefinierten Präprozessorsymbole aus. Besonders hilfreich ist das mit Crosscompilern oder mit -march=native, wenn man vergessen hat, dass das gcc-Symbol für "die CPU kann AES-NI" __AES__ hieß.
Bei der Gelegenheit fiel mir auch gerade auf, dass mein Haswell-Arbeitsgerät die SHA-Instruktionen gar nicht beherrscht. Ich dachte die sind seit Ewigkeiten überall drin. AMD hat die seit Zen. Die Unterschiede zwischen den Implementationen sind übrigens echt bemerkenswert. Hier ist ein sha1sum über eine 80MB-Datei:
libtomcrypt: e7d22debfee07c9da1c85114f14cb720956b7fca (313.4M cycles)Das ist auf meinem Atom-Reisenotebook mit SHA-Spezialinstruktionen. Hier sind die Timings für SHA2-256 auf die Datei auf demselben Notebook:
openssl: e7d22debfee07c9da1c85114f14cb720956b7fca (58.1M cycles)
botan: e7d22debfee07c9da1c85114f14cb720956b7fca (65.0M cycles)
gcrypt: e7d22debfee07c9da1c85114f14cb720956b7fca (190.2M cycles)
libtomcrypt: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (673.6M cycles)Man sieht, dass das schon einen Grund hat, wieso OpenSSL häufig verwendet wird.
openssl: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (139.6M cycles)
botan: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (137.6M cycles)
gcrypt: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (432.7M cycles)
vanilla: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (814.7M cycles)
Zum Vergleich die Timings von dem Haswell-Gerät:
libtomcrypt: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (844.8M cycles)Da sieht man, wessen Implementation die Extra-Meile gegangen ist.
openssl: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (457.1M cycles)
botan: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (686.1M cycles)
gcrypt: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (506.7M cycles)
vanilla: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (1.0G cycles)
Das Präprozessor-Symbol für SHA-Instruktionen heißt übrigens __SHA__. Die Messgröße ist die Differenz im Cycle Counter für einen Hash-Lauf über die gesamte Datei. Vanilla ist eine unoptimierte C-Implementation aus dem Standard. Der Cycle Counter ist die feinste Messeinheit, die CPUs so haben. Eine 1 GHz CPU hat eine Milliarde Cycles pro Sekunde.
Als Teil von meinem OpenPGP-Gefummel habe ich mal einen Hasher-Prozess gebastelt. Der liest von stdin ein Byte mit der OpenPGP-ID des gewünschten Hash-Algorithmus. Dann liest er von stdin bis EOF, hasht das alles mit dem gewünschten Algorithmus, und gibt das Ergebnis auf stdout aus.
Damit das auch einen Vorteil hat, sandboxt er sich am Anfang mit seccomp auf "darf nur von stdin lesen und nach stdout schreiben" ein.
Das habe ich dann einmal mit den Hash-Routinen aus libtomcrypt implementiert, und einmal mit OpenSSL. Ergebnis:
$ du -k hash-tom hash-osslDas ist gestrippt, versteht sich. Von OpenSSL rufe ich folgende APIs auf:
60 hash-tom
1864 hash-ossl
Stöhn.
Ich hab jedenfalls keine Fragen mehr, wieso gatling mit TLS in der OpenSSL-Version viermal so groß ist wie in der mbedtls-Version.
Update: Es gibt auch Low-Level-APIs für Hashes, die sehen dann z.B. so aus:
SHA1_Init(&sha1ctx);
SHA1_Update(&sha1ctx, buffer, bytesinbuffer);
SHA1_Finish(&sha1ctx, outputhash);
So sehen jedenfalls die APIs in libtomcrypt aus. OpenSSL hat diese Art API auch — aber nicht für SHA3. Nur für die älteren Hashes. Und so muss ich diese völlig überflüssige EVP-Abstraktion nehmen, weil ich sonst nicht an SHA3 rankomme. Die drückt mir dann erstmal ein malloc rein, das sonst nicht gebraucht würde in dem Binary, und ich muss plötzlich auch noch libpthread reinladen. Super, OpenSSL!
Wir haben ja in der IT schon seit einer Weile eine Kulturrevolution laufen, wo selbsternannte Moralinstanzen herumlaufen und anderen Leuten Vorhaltungen machen, wie sie in ihren Projekten Dinge zu benennen haben. Und wie bei der chinesischen Kulturrevolution drängt sich von außen ein bisschen der Eindruck auf, es ginge gar nicht um die Bekämpfung von Faschismus sondern um das Erbringen des Beweises, dass man selbst der beste Kommunist von allen ist.
Den traurigen Höhepunkt hat das kürzlich erreicht, als Rich Salz bei OpenSSL vorstellig wurde, damit die bei sich "Master Key" und ähnliche Terminologie exterminieren. Rich Salz ist bekannt dafür, dass er INN geschrieben hat, in den 1990er Jahren einer der wichtigsten Usenet-Newsserver. Rich arbeitet bei Akamai in der Security-Abteilung und in seiner Funktion als Akamai (Großkunde von OpenSSL) hat er dann bei denen genug Druck gemacht, um eine Abstimmung auszulösen. Die ging dann aber mit 4:3 Stimmen gegen die Kulturrevolution aus, woraufhin Rich Salz öffentlich ein Rumpelstilzchen pullte und was von "on the wrong side of history" brüllte, seinen Weggang von OpenSSL verkündete und sich vor Zorn in der Luft zerriss.
Und jetzt? Jetzt kommen die Einschläge näher. Jetzt geht es um White Hat und Black Hat. Das hat natürlich mit Rassismus nichts zu tun, denn das ist eine Anspielung auf die alten Schwarzweiß-Western. Da musste man dem Zuschauer einen Weg geben, den Bösewicht und den Helden auseinanderzuhalten. Der Weg war, dass man dem Guten einen hellen Hut gab, dem anderen einen dunklen. Mehr als hell-dunkel ging eh nicht bei dem Medium.
Weder White Hat noch Black Hat sind jetzt inhaltlich Fachbegriffe. Ich fand die noch nie gut. Das war schon von Anfang an Virtue Signaling. Ich bin kein böser Hacker, ich bin ein guter Hacker! Seht her, ich habe einen weißen Hut! Ein blöder Witz, der auf blöden Hollywood-Stereotypen aus den 50er Jahren basierte. Der unsicheren Software ist es auch egal, mit welcher Intention sie gehackt wird.
Mich ärgert bloß die Hybris, mit der Leute wie Rich Salz anderen Vorhaltungen machen. Und das ganz ohne vorweisbare Wirkung! Was waren denn die großen Errungenschaften der Schwarzen in den USA? Das formelle Ende der Sklaverei, Rosa Parks, Martin Luther King, Abschaffung von Jim Crow und Eintrittsverboten für Schwarze und von Schwarzen-Toiletten (gibt es im Pentagon übrigens noch, das ist älter als die Abschaffung). In jüngerer Zeit hat sich wohl die Taxi-Situation auch normalisiert. Welcher davon wurde von Sprachpolizei und Kulturrevolution befördert? KEINER!
Ich bin kein Freund der alten Terminologie, und ich bin kein Freund von OpenSSL. Aber Rich Salz hat gerade noch tiefer ins Klo gegriffen als die beiden zusammen.
"Was haben Sie eigentlich gemacht, als die Polizei George Floyd ermordet hat?"
"Ich habe ein paar wichtige Konstanten umbenannt!"
m(
Update: Wenn ihr gerade mal ne halbe Stunde Zeit habt, googelt doch mal Symbolbilder von bösen Hackern. Wenn ihr auch nur einen Schwarzen findet, dann habt ihr mehr als ich gefunden. Der Hoodie ist schwarz, die Maske ist schwarz, der Laptop ist schwarz, der Hacker ist weiß. Wenn hier also was rassistisch ist, dann in die andere Richtung. "Die Kriminellen sind alle Weiße!1!!"
Digicert, Digicert, wer war das noch gleich … ach ja! Die mit dem CA-Business von Symantec!
Da hat wohl jemand die Due Diligence verkackt? (Danke, Christian)
Wie z.B. das nächste OpenSSL-Security-Problem oder dass der git-Patch neulich das Problem nicht wirklich geschlossen hat.
Bei allem Geheule über die unfassbare Komplexität und die ständigen Lücken in Browsern: Das hier ist noch viel schlimmer.
Viele dieser Firmen haben ja eine kostenlose Version für Privatgebrauch.
Dazu kommt, dass Schlangenöl ja alle eure SSL-Verbindungen aufbeißt und reinguckt. Wegen der Sicherheit und so.
Sag mal, Fefe, das wären doch für die Werbemafia hochgradig wertvolle Datenschätze, oder?
Bei Avast gab es einen Datenreichtum bei deren Geheimverträgen und daher wissen wir jetzt: Wo ein Trog ist, da kommen die Schweine.
They show that the Avast antivirus program installed on a person's computer collects data, and that Jumpshot repackages it into various different products that are then sold to many of the largest companies in the world.Und weil es so viele Idioten gibt, die sich Schlangenöl installieren, haben die einen enormen Hebel im Markt.Avast claims to have more than 435 million active users per month, and Jumpshot says it has data from 100 million devices.Na? Ihr habt doch sicher alle brav das Kleingedruckte gelesen, bevor ihr das weggeklickt habt, oder?Oder?
Heute so: Kaspersky-Schlangenöl injected Javascript-Nachladen von ihren Servern in Russland in alle Webseiten.
Der Admin dieser Server sieht damit alle URLs aller User, inklusive URL-Parametern (mit denen bei SSL-Seiten wie Online-Banking gerne weniger besorgt umgegangen wird, weil das ja hinter SSL ist, und SSL soll uns ja gerade davor schützen, dass das auslesbar ist). Ist auch normalerweise nicht auslesbar, außer man hat ein Schlangenöl installiert, das das SSL rechnerweit unsicher macht. Wie bei Kaspersky.
Das ist erstaunlich, weil OpenSSL bisher gegenüber allen anderen TLS-Implementationen immer spürbare Performance-Vorteile hatte. So hohe Performance-Vorteile, dass viele im Gegenzug das grottige API zu erdulden gewillt waren.
Und jetzt kommt jemand und macht in Rust ein TLS, und das ist schneller? Das ist bemerkenswert! Nicht weil Rust irgendwie inhärent langsameren Code erzeugt, aber weil OpenSSL bisher für seine exzellente Performance bekannt war. Dass jemand schneller sein kann, war nicht ausgeschlossen, aber dass es dann gleich so 20% schneller sein würde, das ist echt bemerkenswert. Hut ab vor dem Rust-Hacker da! (Danke, Magnus)
Falls sich jetzt jemand denkt: Haha, ich nehm Android, betrifft mich nicht: Die Onavo-App ist auf Android gar nicht erst aus dem Play Store geschmissen worden.
Update: Oh gucke mal, das ging ja fix: Facebook will shut down its controversial market research app for iOS.
Ich bin ein bisschen traurig, dass ich nicht noch mehr Vorträge mitnehmen konnte. Ein paar waren aber noch. Hmm, IFG hatte ich ja schon berichtet (unterhaltsam und inspirierend). Ah, mein nächster Vortrag war memsad von meinem Kumpel Ilja. Da ging es um eine wichtige Prämisse, die ich auch mal im Blog hatte vor ein paar Jahren. Ilja hat daraus mal eine Übersicht gemacht, und das bei allen Compilern ausprobiert, die er finden konnte, und stellt auch die verschiedenen Ansätze vor, wie Krypto-Libraries das lösen. Highlight des Vortrags war allerdings, dass er einen 5-Zeilen-Patch für gcc gehackt hat, der beim Wegoptimieren von memset eine Warnung ausgibt, und damit mal OpenSSL und Kerberos kompiliert hat — und Warnungen kriegte! Oops.
Danach haben wir die Jung und Naiv Aufnahme gemacht (1 Stunde 15 Minuten Aufnahme und dann haben wir uns nochmal gefühlt eine Stunde festgeplaudert, das hätten wir Deppen auch mal aufnehmen sollen), und als das durch war, eilte ich zum Steini-Flashmob, der wie gesagt wunderschön war. Da stand auch eine Kamera, insofern hoffe ich, dass es eine Aufzeichnung gibt. Beim Congress laufen ja eh immer eine Menge tiefenentspannte, glückliche Menschen herum, aber nach dem Steini-Vortrag war das besonders auffällig :-)
Heute wollte ich eigentlich mit Microtargeting eröffnen, aber da hat mir der ÖPNV in Leipzig einen Strich durch die Rechnung gemacht. Die erste Tram fuhr mir vor der Nase weg. 10 Minuten warten. Die andere hielt 100m weiter hinten neben einem anderen Zug, und als die Leute da hineilten, machte der spontan die Türen zu und fuhr weg. 10 Minuten warten. Den nächsten Zug bekamen ich und die anderen verdutzten Fahrgäste dann, aber da war der Vortrag schon halb vorbei. Schade.
Der Fahrplan dieses Jahr hat mit verschiedenen Vortrags-Längen experimentiert, was leider ein paar Mal so richtig nach hinten losging. Nach dem djb-Vortrag gab es 0 Minuten Abstand zum Sonneborn, aber der war einmal über das Gelände (~10 Minuten Leute mit Skateboard/Roller oder für Sprinter, und ich bin weder noch). Daher habe ich dann den netzpolitischen Wetterbericht nicht gucken können, sonst hätte ich den Anfang von Let's reverse engineer the Universe verpasst. Der Vortrag war sehr schön, hat mir gut gefallen. Gut, war kein Steini-Vortrag, aber auf jeden Fall honorable mention. Die Vortragende war auf jeden Fall sehr enthusiastisch und hat auch ein hohes Niveau durchgehalten, ohne dabei Zuschauer zu verlieren. Sehr schön, kann ich empfehlen.
Dann lief ich zu den Security Nightmares rüber, wo schon 45 Minuten vor dem Talk das Parkett weitgehend vollbesetzt war. Heilige Scheiße. Um den Zug zu kriegen, musste ich dann leider recht überpünktlich raus und habe das Ende nicht mitgekriegt. Insgesamt habe ich aber aus früheren Jahren die Zuschauerinteraktion als größer in Erinnerung. Eher so ein Dauer-Q&A und die Vortragsfolien nur als Themen-Vorgabe und Assoziationshilfe. Gut, ich war auch echt durch und müde, insofern kann ich das jetzt nur unterdurchschnittlich objektiv beurteilen, aber es fühlte sich eher … langsam an? Zu langsam, fand ich. War ein bisschen die Luft raus. Aber dem Publikum gefiel es, und das ist ja was zählt.
In der Tram hörte ich dann den Kritikpunkt am Congress, der sei zu seicht geworden, zu wenig harte Tech-Talks. Das hört man seit ich beim Congress dabei bin, und das sind jetzt über 20 Jahre. Ich halte das für eine kognitive Illusion. Erstens entwickelt ihr euch als Publikum weiter, das verschiebt eure Anspruchshaltung. Zweitens erinnert ihr euch nicht an alle Vorträge sondern an die "guten", und in eurem Gedächtnis ist der Vergleichsrahmen dann "alle Vorträge dieses Jahr" und "die guten Vorträge letztes Jahr". Ich kann euch versichern: Die Tech-Talks auf den Congressen waren nicht immer alle "hart". Ich weiß das, denn ich habe einige von ihnen gehalten. Guckt euch nur mal meinen Routing-Vortrag aus dem Jahre 2000 an. Der würde heute auch nicht als "hart" durchgehen, eher als strukturierte Einführung. Bitte guckt ihn euch nicht zu genau an, ich war jung und wusste viel weniger :-)
Aber, nochmal, dass es früher nur voll die krassen Ultra-Tech-Talks gab, das ist glaube ich eine Illusion.
Was ja nicht heißt, dass man sich nicht für die Zukunft mehr davon wünschen könnte. Dem würde ich aber entgegenhalten wollen, dass es so schon praktisch unmöglich ist, sich einen konfliktfreien Pfad mit allen Tech-Talks durch den Fahrplan zu suchen. Und sobald man sich auch für Science oder Politik interessiert, ist es ganz vorbei.
Mich hat eher die Ausrichtung der Tech-Talks ein bisschen gestört dieses Mal. Das ist aber nicht Congress-spezifisch, sondern bei fast allen Security-Konferenzen so. Praktisch alle Security-Vorträge sind über offensive Dinge. Wie man A hackt, wie man B hackt, Angriffe auf C, VM-Ausbruch bei D, alles kaputt, alles im Eimer. Aber die Vorträge, die mal Strategien zu entwickeln versuchen, was man denn besser machen könnte, die sind völlig unterrepräsentiert. Auf diesem Congress gab es ein paar. Ich würde memsad dazu zählen wollen, und es gab ein paar Talks über formale Verifikation von Code. Das habe ich immer negativ gesehen, mit dem Argument, dass die Verifikation mindestens genau so komplex wie der zu verifizierende Code wird, und der ist schon zu komplex, sonst bräuchten wir ja die Verifikation nicht. Aber im Quantenkrypto-Vortrag von djb und Tanja Lange meinte djb gegen Ende, dass er da seine Meinung geändert hat, weil die Tools so viel besser geworden sind. Da muss ich also auch nochmal genauer hingucken, ob ich meine Einstellung ändern muss.
Jedenfalls: Wenn man da am Tech-Programm was tun sollte, meiner Ansicht nach, dann wäre es: Mehr defensive Sicherheit. Das ist ironischerweise genau das, was der CCC immer der Bundesregierung vorhält, dass sie alle ihre Mittel in offensive Security steckt und nicht in defensive. Nun, äh, wie wäre es, wenn der Club da mit gutem Beispiel vorangeht?
a malicious user could use the Kubernetes API server to connect to a backend server to send arbitrary requests, authenticated by the API server's TLS credentials.The API server is the main management entity in Kubernetes. It talks to the distributed storage controller etcd and to kublets, the agents overseeing each node in a cluster of software containers.
Das ist ein Container-Ausbruch-Szenario. Kubernetes ist ja seit Tag 1 Opfer seiner eigenen unnötigen Komplexität. Die Prämisse ist ja eigentlich relativ einfach. Man beschreibt ein System aus mehreren Containern deklarativ und ein Tool baut das dann auf. Ein Tool, um einen Container zu starten, geht in deutlich unter 100k statisches Binary. Ein Tool, um aus einer Beschreibung ein Image zu bauen, und sich die Bestandteile aus dem Internet zu ziehen, ist sagen wir mal 2 MB, da ist dann auch ein fettes OpenSSL mit drin.Aber Kubernetes hat da noch eine monströse Management-Infrastruktur draufgepackt, und alles riesige Go-Binaries natürlich. Ich habe hier gerade mal das aktuelle Kubernetes mit dem aktuellen Go gebaut -- da fallen 1.8 GB Binaries raus. Ja, Gigabytes! Kein Typo! Das ist völlig absurd. Und natürlich geht ohne die Management-Infrastruktur der Rest nicht. Aus meiner Sicht ein Architektur-Fuckup sondergleichen. Auf der anderen Seite tickt Docker ja genau so. Da muss man auch die ganze Zeit einen Docker-Daemon laufen haben. Was die sich dabei wohl gedacht haben? Ich glaube: Der läuft da hauptsächlich aus Branding-Gründen. Damit die Leute den Eindruck haben, Container sei eine hochkomplexe Docker-Tech, keine vergleichsweise einfache Linux-Kernel-Tech.
Diese Einstellung hört man glücklicherweise inzwischen nur noch sehr selten, und das begrüße ich. Meiner Erfahrung nach sind Entwickler im Allgemeinen interessiert daran, eine gute Arbeit zu machen. Und das beinhaltet: Keine Sicherheitslücken produzieren.
Ich habe schon häufig erlebt, dass Entwickler mit mir über Bugs verhandelt haben, aber das hatte immer falsche Anreize in der Organisation als Hintergrund. Sowas wie: Ich kriege einen Bonus, wenn ich keine Bugs habe. Du hast hier gerade Bugs aufgemacht, das killt meinen Bonus, daher bestreite ich die jetzt alle.
Man stelle sich mal vor, ein Architekt argumentiere so. Sagen wir mal: Ein Klimaforscher sagt: Wir haben Klimawandel, die Stürme werden stärker, ihr müsst eure Statik jetzt auf mehr Windstärke auslegen. Und die Architekten sagen dann: Der böse Klimaforscher hat mir gar nicht erklärt, was ich da genau tun muss jetzt!1!!
Undenkbar, da sind wir uns hoffentlich alle einig. Das sollten wir auch Software-Entwicklern nicht durchgehen lassen. Glücklicherweise kommt das auch jetzt schon so gut wie nicht vor, jedenfalls meiner Erfahrung nach.
Update: Ich sollte das nochmal explizit sagen: Das ist nicht die Realität. Jedenfalls nicht in meiner Erfahrung. Der Report erwähnt mindestens den Fachbegriff Integer Overflow, danach kannst du googeln und dann findest du, wie man das fixt. Oder der Report verweist auf intsafe/safeint oder die entsprechenden gcc/clang-Builtins. Und das ist auch bei ... weniger seriösen Marktteilnehmern so, weil das ein einfacher Weg ist, den Report zu strecken. Daher ist das eine akademische Diskussion hier. Ich bin aber der Meinung, dass jemand, der nicht weiß, was ein Zertifikat kaputt macht, die Finger von Code lassen sollte, der mit Zertifikaten hantiert.
Das SSL-Zertifikat bei jquery.com ist abgelaufen.
Na ein Glück, dass die bloß ihr Zertifikat auslaufen ließen und nicht Schadcode ausliefern.
Update: Und was verkauft die Post da so an Daten? Hier ist eine Liste:
Darunter befinden sich demnach Angaben zu Kaufkraft, Bankverhalten, Geschlecht, Alter, Bildung, Wohnsituation, Familienstruktur, Wohnumfeld und Pkw-Besitz. Nach eigenen Angaben kaufe die Post außerdem statistische Daten von Behörden wie dem Kraftfahrt-Bundesamt und Katasteramt
Ist das nicht ein klarer Verstoß gegen die neue EU-Datenschutzverordnung?
Update: Oh wei, da hab ich ja völlig falsch gelegen! Die Post verkauft eure Daten nicht, sie vermietet sie. Das ist dann natürlich was GANZ anderes. Wenn die Post-Seite bei euch SSL-Fehler wirft: Das ist normal. Die benutzen RapidSSL als CA, das ist inzwischen aus den seriösen Browsern rausgeschmissen worden.
Update: Lacher am Rande:
Auch CDU und FDP, die den Service im letzten Bundestagswahlkampf genutzt hatten, wiesen die von der "Bild am Sonntag" erhobenen Vorwürfe zurück. [...] Als "Datenschutzpartei" habe die FDP darauf geachtet, dass keine personenbezogenen Daten verwendet worden seien.
Oh ach sooo! "Bedenken second" war gestern, heute doch wieder Datenschutzpartei, ja? Und woran hat die FDP den Daten angesehen, ob da personenbezogene Daten verwendet wurden?
Die sind alle recht lustig, aber die Zweite ist episch:
Because of an implementation bug the PA-RISC CRYPTO_memcmp function is effectively reduced to only comparing the least significant bit of each byte.Are you fucking kidding me?!?
Golem hat mal beim BSI einen Informationsfreiheitsantrag gestellt und die haben ihm die Studie geschickt — aber sie dürfen sie nur lesen, nicht veröffentlichen.
Sehr ärgerlich ist aus meiner Sicht auch dieses Detail hier:
Das BSI bestätigte uns, dass es die Ergebnisse nicht an die Entwickler der anderen Bibliotheken weitergegeben hatDie anderen sind LibreSSL und NSS. Und um das hier ging es:
So gibt es etwa Hinweise auf Compilerwarnungen und eine Einschätzung, wie schwerwiegend diese sind, außerdem eine Auflistung von Fehlern in den State Machines der TLS-Handshake-Implementierung und Hinweise, an welchen Stellen der Code besser gegen Timing-Angriffe geschützt werden sollte.Ja, äh, was sprach denn da bitte dagegen, das den Projekten mitzuteilen?! Bei Botan haben sie ja nicht nur Bescheid gesagt sondern sogar Patches hingeschickt!
Das hinterlässt ja einen noch schlechteren Nachgeschmack als vorher, und das war vorher schon nicht gut. Wow, BSI, das war ja mal ein echter Rückschritt. Habt ihr schon aufgegeben? Glaubt ihr, euch glaubt eh nie wieder jemand was? Gut, könnte was dran sein, zumal mit dem Cyberclown jetzt. Tja.
Einen katastrophalen TLS-Fehler! Und wieder aus der Bleichenbacher-Ecke. What the fuck?
Die gute Nachricht ist: OpenSSL und mbedTLS sind anscheinend nicht betroffen (tauchen jedenfalls in der CVE-Liste nicht auf).
OpenSSL 1.1 ist im August 2016 released worden.
Qt hat sich damit (bei mir) selbst ins Aus geschossen. Projekte, die nur mit Qt gehen, verwende ich dann halt nicht mehr. Viele sind das ja eh nicht.
Aber ich kann mich da echt nur wundern, dass die da so nachlässig sind, wenn nicht gar fahrlässig. Der alte OpenSSL-Kram wird ja nicht besser, der wird irgendwann nicht mehr supported und dann muss der Schritt eh gemacht werden.
Update: Es gibt da seit Mai (!) Code, aber den liefern sie noch nicht aus. Vielleicht in 5.10 dann. Seufz.
Update: Ich sehe gerade, dass openssh nicht mehr mit openssl 1.1 baut. Ich habe hier ein openssh mit openssl 1.1 gebaut und im Einsatz, aber jetzt checkt configure das und bricht den Build ab. WTF?
Ich habe ja noch nie was positives von deren Produkten gehört. Ist mir ein Rätsel, wieso Leute sowas kaufen. Man googelt doch vorher ein bisschen, bevor man soviel Geld in die Hand nimmt?
Oder vielleicht liegt das ja auch an mir und F5 ist total super. Außer dass man gerade ihren SSL-Traffic entschlüsseln kann. Aber sonst voll super!
Es gab da z.B. einen Talk zu Owasp und deren Top 10, und der verbrachte gefühlt die erste halbe Stunde damit, dass die Top 10 ja völlig überbewertet und von der Werbung irgendwelcher Unternehmen missbraucht werden, dass das keine Pentest-Checkliste sei und nicht für Compliance gebraucht werden dürfe — und dann berichtete er darüber, wie sie da Streitereien haben zu den neuen Top 10, wie es da einen Entwurf gab, wo ein Punkt "du sollst Schlangenöl kaufen" eingefügt wurde. Anscheinend auf Betreiben von jemandem, der "privat" diese Liste maintaint und dann beruflich das geforderte Schlangenöl vertreibt. Das war mir alles neu, aber ich stalke jetzt auch nicht Owasp hinterher, die interessieren mich ehrlich gesagt nicht so stark. Aber jetzt zeigt er den neuen Entwurf, und da ist CSRF nicht mehr drin (nach wie vor eines der größten echten Probleme für Webapps, aus meiner Sicht, das viele viele Leute nicht verstanden haben, die Webapps bauen). Dafür ist da "du sollst Schlanenöl zum Monitoring und Alerting kaufen" drin. Tja, Owasp, ein Wort mit X. Das war wohl nix.
Was hab ich noch gesehen? Oh ja, "Sichere Softwareentwicklung - Anforderungen und Vorgehensweisen". Das war erst eine ewig lange Liste von "ALLE WURDEN GEHACKT! ALLE!!!", eine halbe Stunde "Wir werden alle störben" pur. Und als sie dann ein paar Maßnahmen empfahlen, machten wir ein Trinkspiel daraus und mein Kumpel Daniel drehte dann eine Siegerrunde, als er korrekt "gleich pluggen sie die SDL" vorhersagte.
Ich muss dazu sagen, dass ich relativ hohe Ansprüche habe bei Vorträgen, wenn es darum geht, was man da jetzt konkret mitnehmen kann. Und das fehlte hier bei vielen Talks. Ein paar Links auf Dinge (ich erinnere mich an drei Talks, die auf die Owasp Top 10 verwiesen, die der Owasp-Talk gerade dafür gedisst hatte). Ja, äh, wenn ich Links hinterherlaufen wollte, hätte ich mir den Vortrag nicht angucken müssen. Das Problem hatten viele Talks. Gut, die Materie ist ja auch komplex, aber das Argument kann ich nicht gelten lassen, wenn die erste Hälfte des Talks mit Platitüden und Einführungs-Blablah verplempert wird.
"Security im Entwicklerteam" habe ich auch geguckt, aber da fehlten mir auch so ein bisschen die "was machen wir denn jetzt"-Folien. Konkrete Dinge, die man jetzt tun kann, den Schritt geht irgendwie kaum jemand. Und ich meine jetzt nicht "hier ist ein Wiki, klick da mal rum". Besonders krass fand ich einen Talk am 2. Tag, bei dem es um Automatische Code-Scanner ging, und "was die Hersteller Ihnen nicht sagen werden". Da hätte ich konkrete Beispiele erwartet, mindestens aber ein paar lustige Anekdoten. Stattdessen kam unkonkretes "die versprechen viel und halten das dann nicht" (NEIN! Hold the presses!!) und "wenn Sie das genauer wissen wollen, dann holen sie sich mal die Eval-Versionen, nehmen Sie sich jeweils ein paar Tage Zeit, und testen Sie die gegeneinander". Äh, das wollte ich gerade nicht machen sondern mir hier die Ergebnisse abholen!
Am 2. Tag morgens gab es einen Vortrag, der mir vergleichsweise wichtig war. Da erzählten nämlich zwei Leute von Rohde & Schwarz von dem Projekt "Analyse und Auswahl einer allgemeinen Kryptobibliothek". Der Talk war mir wichtig, weil das Projekt für das BSI ist. Das BSI hat ja ein paar Glaubwürdigkeitsprobleme bei Kryptofragen, seit sie sich in die Bundestrojaner-Begutachtung haben verwickeln lassen. Insofern gut und richtig, das an eine externe Organisation rauszugeben. Aber Rohde & Schwarz ist an der Stelle eine zumindest aus meiner Sicht nicht viel glaubwürdiger aufgestellte Firma, die mir unter anderem als Lieferant von IMSI-Catchern für "Bedarfsträger" untergekommen ist bisher. Das ist keine gute Basis für das Erarbeiten einer unabhängigen Empfehlung für Krypto-Libraries. So und das Ergebnis von diesem Projekt war jetzt, dass sie Botan gewählt haben — eine Library mit einem Marktanteil von vielleicht 1% im TLS-Segment, von der kaum jemand überhaupt gehört hat. Ich habe mir bei Botan mal den Code angeguckt und der war jetzt nicht schlecht oder so, aber das ist ein krasser Außenseiter, und in Benchmarks ist deren Code schonmal nur halb so schnell wie der von OpenSSL. Meine Erfahrung ist, dass schon 5% Performanceunterschied reichen, um jemanden doch zu OpenSSL greifen zu lassen, wenn der bloß eine Ausrede suchte, wieso er bei OpenSSL bleiben soll. Das ist also alles schon mal nicht so gut, sowohl aus technischer als auch aus politischer Sicht. Ich hätte erwartet, dass die die Zeit nutzen, um mal so richtig knallhart inhaltlich zu zeigen, welche Kriterien ihnen wichtig waren und warum sie so entschieden haben, um jeden Geruch von Foul Play auszuschließen. Stattdessen kam ein Halbsatz dazu. Sie haben intern ein Punktesystem erarbeitet und nach dem sind sie gegangen. Ja, äh, das hilft mir jetzt nicht weiter. Das riecht jetzt nicht besser als vorher. Eines der Argumente gegen OpenSSL war, dass das API so schlimm ist. Ungefähr 20 Minuten lang haben sie dann Beispiele gezeigt, wie man in Botan Dinge tut, aber nicht Dinge wie "TLS-Verbindung aufmachen, Certificate Pinning anschalten" — nein, Dinge wie "SHA256 von diesen drei Bytes hier machen. Ja, äh, das geht auch in OpenSSL mit nur ein paar Zeilen Code. Das große Argument für Botan ist, dass es vergleichsweise wenig Code ist (im Vergleich zu OpenSSL). Allerdings kommt der viele Code in OpenSSL u.a. davon, dass sie für performancekritische Primitiven Assembler-Implementationen für ein Dutzend Plattformen haben. Und nicht nur für Performance ist Assembler wichtig, auch für das Vermeiden von Seitenkanälen. Wie da die Situation bei Botan ist, haben sie zwar gesagt, dass sie das getestet haben und was in einem Padding-Verfahren gefunden haben, aber was ist mit den anderen Verfahren? Die elliptischen Kurven, das RSA?
Zur Ehrenrettung der Vortragenden muss man aber sagen, dass die a) für eine Tochter von Rohde & Schwarz arbeiten, die die dazugekauft haben, und b) nicht den Eindruck erweckten, sie seien jetzt fiese Geheimdienstler, die unser Krypto schwächen wollen. Aber ausgeräumt haben sie den Verdacht halt auch nicht.
Mir tun die Leute beim BSI und bei dieser R&S-Tochter durchaus leid, versteht mich nicht falsch. Viele wenn nicht alle von denen meinen das sicher alles total gut, und werden jetzt völlig zu Unrecht verdächtigt.
Ich habe so ein bisschen den Eindruck gewonnen, dass ich mal einen Vortrag über Threat Modeling halten muss. Das ist gerade voll im Trend, und die meisten, die das machen, haben gar nicht verstanden, warum man das macht.
Das war dann für mich auch schon die Veranstaltung, danach kam meine Keynote und nach der bin ich ziemlich direkt in den Zug gestiegen, damit ich auf der Fahrt nach Berlin nicht komplett im Dunkeln fahren muss.
Update: Dirk, der den Owasp-Talk gemacht hatte, schreibt mir gerade, dass das nicht als Schlangenöl-Kaufen-Paragraph gemeint ist, auch wenn ich das so deute. Sie hätten extra auch Open Source erwähnt. Nun, mit Schlangenöl meine ich "verspricht Dinge, die es nicht halten kann", nicht "kostet Geld". Schlangenöl kostet natürlich im Allgemeinen auch Geld, ja, aber es gibt auch Open Source Schlangenöl. Ich finde es halt anstößig, erst die Formulierung von "wichtigste Angriffe" auf "wichtigste Risiken" zu ändern, um dann in der nächsten Runde "Reaktives Security-Produkt $XY nicht installiert" als Risiko hinzuschreiben. Das geht aus meiner Sicht gar nicht. Na mal gucken, ist ja bisher noch ein Release Candidate, vielleicht fliegt das ja auch noch raus.
Update: Ein Einsender erklärt:
Ich will den Erfolg ja nicht schmälern, das ist schon sehr erstaunlich. Der Schlüsselsatz ist aber auf Seite 7 unten:
..., we still attack the bus between ARM core and memory, ...
Klar will Fox-IT ihre Metallgehäuse verkaufen. Der Angriff funktioniert nur bei ausreichend geringen Taktraten, ohne Cache und mit Plastikgehäuse, auf Software-AES. Wenn die S-Box erst mal im Cache landet, is' Essig mit dem Abhören.
Also noch nicht Schafe züchten.
LibreSSL 2.5.1 to 2.5.3 lacks TLS certificate verification if
SSL_get_verify_result is relied upon for a later check of a
verification result, in a use case where a user-provided verification
callback returns 1, as demonstrated by acceptance of invalid
certificates by nginx.OMFG
udp.c in the Linux kernel before 4.5 allows remote attackers to execute arbitrary code via UDP traffic that triggers an unsafe second checksum calculation during execution of a recv system call with the MSG_PEEK flag.Das klingt jetzt schlimmer als es ist, denn MSG_PEEK wird selten benutzt, UDP wird selten benutzt, und MSG_PEEK bei UDP wird noch seltener benutzt. Mir ist persönlich kein Fall bekannt.Ich habe dieses Flag in meiner Laufbahn 1-2 Mal benutzt. Man nimmt es, wenn man von einem Socket ein paar Bytes lesen will, ohne die zu lesen (d.h. wenn man danach nochmal read aufruft, kriegt man die Bytes wieder). Ich benutze das in gatling, um zu sehen, ob Daten auf einer SSL-Verbindung wirklich wie ein SSL-Handshake aussehen — allerdings auf einem TCP-Socket.
Kurz gesagt: Ich mache mir da jetzt keine großen Sorgen. Die DNS-Implementationen von glibc, dietlibc und djb benutzen jedenfalls nicht MSG_PEEK, und wenn es um UDP geht, ist DNS der übliche Verdächtige.
Ich will das nicht kleinreden, das ist ein ganz übler Bug und die sollten sich was schämen. Aber es ist kein "OMG die NSA hat mich gehackt, ich reinstalliere und mache alle Keys neu"-Bug. Außer ihr fahrt auf eurem Server irgendwelche UDP-basierten Protokolle.
Update: Im OpenVPN-Code findet grep auch kein MSG_PEEK. VPN und VoIP wären die anderen in Frage kommenden Codebasen.
Update: Ein paar Leser haben bei Debian und Gentoo mal ein bisschen rumgesucht und fanden als potentiell verwundbare Pakete dnsmasq und VNC-Implementationen. dnsmasq läuft praktische allen Plasteroutern. Das wäre in der Tat potentiell katastrophal.
Update: Einsender weisen darauf hin, dass systemd angeblich MSG_PEEK benutzt, und dass möglicherweise noch Chrome in Frage kommt als Angriffspunkt, wegen QUIC.
Und als djb dann kam und spezielle elliptische Kurven vorschlug, damit Entwickler weniger Mist machen können, hielt Rüdi dagegen: Wer SO DOOF ist, dass er mit DEN SIEBEN TRIVIALEN Fällen bei Weierstraß-Kurven nicht klar kommt, der soll halt keinen Krypto-Code schreiben! Das könne doch nicht sein, und da guckte er mich hilfesuchend an, dass die Coder da draußen dermaßen inkompetent sein?!
Und ich hab ihm dann von strcpy erzählt und bestätigt, dass es im Allgemeinen eine gute Idee ist, wenn man Algorithmen so wählt, und API so auslegt, dass man nichts falsch machen kann.
Das fiel mir gerade ein, als ich diesen Bug in mbedTLS (früher PolarSSL) sah.
If a malicious peer supplies a certificate with a specially crafted secp224k1 public key, then an attacker can cause the server or client to attempt to free block of memory held on stack.Wait, what?!
Und da steht u.a. die Antwort, wieso sie lieber ein gammeliges Debian-OpenSSL nehmen würden als eigene Krypto. Sie glauben, die eigene Krypto könnte wiedererkennbar sein.
The "custom" crypto is more of NSA falling to its own internal policies/standards which came about in response to prior problems.In the past there were crypto issues where people used 0 IV's and other miss-configurations. As a result the NSA crypto guys blessed one library as the correct implementation and every one was told to use that. unfortunately this implementation used the pre-computed negative versions of constants instead of the positive constants in the reference implementation.
I think this is something we need to really watch and not standardize our selves into the same problem
Die CIA und die NSA unterhalten sich per IRC?We don't really have an official way of doing strings currently (sounds like NSA does from what I'm seeing in IRC) and I feel like we need to get to that. Off the top of my head one way of protecting against this is dumping all user ids from AD and running a strings check for that in addition to all the other dirty words out there.Und sie fahren Active Directory!
Da ist auch ein PDF zu geleaked, und die Details sind durchaus interessant. Beispielsweise:
All tools must utilize Operating System (OS) provided cryptographic primitives where available (e.g., Microsoft CryptoAPI-NG, OpenSSL, PolarSSL, GnuTLS, etc).Dass sie da Polarssl und Gnutls explizit nennen, finde ich erstaunlich. Auch generell ist das nicht unbedingt ein guter Ratschlag, denn wenn du von irgendeinem gammeligen Schrott-Debian oder Embedded Höllendevice mit OpenSSL 0.98 Daten exfiltrieren willst, dann erscheint es schon ratsam, da lieber nicht die Krypto zu nehmen, die vom OS kommt. Ich sage nur Heartbleed und erinnere an das Debian Weak Key Massaker.
Messages should be compressed prior to encryption.Die Begründung ist: Weniger Clear Text, weniger Angriffsoberfläche. Stimmt auch, aber bei TLS schaltet man im Allgemeinen das Compression-Feature absichtlich ab, weil es da mal ein Problem gab. Die CIA sagt jetzt nicht, man soll das anschalten. Aber es steht auch nicht explizit da, dass man es nicht anschalten soll. Von einem Papier, dessen expliziter Existenzgrund ist, Verwirrung zu verringern, hätte ich das erwartet.Tools should perform key exchange exactly once per connection. Many algorithms have weaknesses during key exchange and the volume of data expected during a given connection does not meet the threshold where a re-key is required. To reiterate, re-keying is not recommended.Das ist so m.W. eine eher selten ausgesprochene Empfehlung. Ich finde ihre Begründung jetzt nicht absurd. Da müsste man mal drüber diskutieren. SSH macht z.B. automatisch Re-Keying nach einer Stunde oder so (einstellbar). Mein Bauchgefühl wäre: Wenn ein Bug im Key Exchange ist, dann wäre der auch im initialen Key-Exchange, nicht nur im Re-Keying.Spannend ist auch dieses Detail bei der Collection Encryption Suite, das ist ihre Empfehlung für die Verschlüsselung von abgehörten Daten, die sie irgendwo abgefangen haben, die aber unterwegs auf irgendwelchen unvertrauenswürdigen Wegen zu ihnen kommen. Da nennen sie als Beispiel:
The Collection Encryption Suite is intended to safeguard collected information as it resides temporarily on an untrusted file system or as it transits a file-oriented communication mechanism (e.g., gap jumpers, bit torrent, HTTP post, etc.).Oh, ach? Die CIA benutzt Bittorrent für den Transport ihrer abgehörten Daten? Das ist ja mal unerwartet.Unten in der Kommentar-Abteilung wird es nochmal spannend. Da sagen sie nämlich explizit, dass sie nicht als Ausrede gegen die Benutzung der installierten OS-Krypto gelten lassen, dass die jemand gehackt haben könnte (ein anderer Geheimdienst beispielsweise):
In particular, the justification that an attacker might hook the OS provided cryptographic API to perform reverse engineering of the implant is not acceptable; any service (including execution) provided by the OS may be subverted and the security of a proven library outweighs the risk of attack.Das ist nicht von der Hand zu weisen. Einzige Ausnahme ist, wenn man Windows XP angreifen will. Nein, wirklich! Denn XP kommt mit oller Gammel-Krypto, die nicht gut genug ist, um ihren Mindestanforderungen zu genügen. Da soll man dann halt ein OpenSSL statisch reinlinken.SHA1 hat die CIA intern übrigens schon länger verboten.
Interessant ist auch, dass die CIA sagt, wenn du ein File exfiltrieren willst, und du machst Krypto und nen Hash für die Integrität drüber, dann machst du den Hash bittesehr über den Ciphertext, nicht über den Plaintext. Begründung: Wenn ein ausländischer Geheimdienst das per SIGINT mitschnüffelt, könnte er den Hash sonst gegen alle Dateien auf dem System vergleichen und so sehen, welche Datei wir exfiltriert haben. Hier ist der Absatz:
The digest is calculated over the ciphertext vice plaintext in order to protect against a SIGINT actor with access to a compromised host obtaining any information about the transfer. Using the example of an exfiltrated file (and depending on communication protocols) it is possible that a SIGINT actor could compare the hash value of every file on the compromised host to the intercepted message and thereby determine which file was exfiltrated. Calculating the digest over the ciphertext eliminates this possible information leakage without altering difficulty of implementation. See also the various debates about Encrypt-and-MAC, MAC-then-Encrypt, and Encrypt-then-MAC. The IV is authenticated by the digest in order to prevent a manipulated IV from flipping bits in the first block of the plaintext upon decryption under certain modes.Da bin ich mal gespannt, was die Crypto-Community dazu sagt. Das klingt für mich nach grobem Unfug; daher nimmt man ja nen MAC, keinen tumben Digest. Aber hey, ich bin kein professioneller Kryptologe.In einem Absatz schreiben sie explizit vor, dass ihre innere Authentisierung nicht auf Basis von irgendwelchem gammeligen Root-CAs stattfinden darf, sondern auf einer hard-coded List von CIA- CAs basieren muss. Begründung in den Fußnoten:
This makes tool X very valuable in those countries known to routinely MitM SSL (e.g., China, Iran, and other hard targets).HARR HARRDie letzte Fußnote hat auch das letzte Highlight:
One novel technique seen in the wild and provided purely as an example of a clever solution is the Random Decryption Algorithm (RDA) technique whereby a piece of malware does not possess the decryption key for its own main execution component. This malware is designed to brute force the decryption key, a process that can take several hours on modern hardware and has the added benefit of extreme resiliency to polymorphic detection heuristics and static scanning. Authors who believe they have a particularly novel approach are encouraged to contact the OCRB for a detailed discussion.Das ist in der Tat eine seit ~12 Jahren diskutierte Technik aus der Virusentwicklung :-)
Betrifft nur OpenSSL 1.1, d.h. wurde nach Verkünden des neuen Security-Fokus von OpenSSL eingebaut.
Einmal mit Profis arbeiten!1!!
Die Funktionalität ist jetzt nur noch über die Developer Tools benutzbar. F12 -> Security Tab -> View Certificate
Was die sich wohl dabei gedacht haben!?
*fluch* *schimpf* *mecker*
Eine Analyse der öffentlich im Internet erreichbaren Systeme zeigt, dass immer noch Hunderttausende für die OpenSSL-Lücke Heartbleed anfällig sind. Die bald drei Jahre alte Lücke findet sich demnach hauptsächlich in Mietservern der Cloud.Make the cloud great again!
Das erste, was bei Rust auffällt: Man kann es nicht aus den Sourcen bauen. Ich möchte immer gerne vermeiden, anderer Leute Binaries auszuführen. Das ist eine Policy bei mir. Wenn ich es nicht selbst gebaut habe, will ich es nicht haben. Es gibt nur wenige Ausnahmen, bei denen der Buildprozess zu furchtbar ist, oder so fragil, dass das selbstgebaute Binary am Ende nicht so gut funktioniert wie das "offizielle", weil die auf irgendwelche speziellen Compilerversionen setzen oder so. Die einzigen Sachen, die ich hier nicht selber baue, sind im Moment Chrome, Libreoffice (falls ich das so einmal pro Jahr mal brauche) und ripgrep. Und ripgrep wollte ich mal ändern. Außerdem finde ich Rust von den Konzepten her spannend und will mal damit rumspielen.
Erste Erkenntnis: Die neueren Versionen von openssl-rust können OpenSSL 1.1. Allerdings kann man Rust nicht aus den Sourcen bauen, ohne schon eine Version von Rust zu haben. Das finde ich sehr schade. Das ist ein Spannungsfeld, das viele Programmiersprachen betrifft. Programmiersprachen haben Angst, erst ernst genommen zu werden, wenn sie self-hosting sind. Die Download-Seite von Rust will einem erstmal Binärpakete aufdrücken, was ich immer ein schlechtes Zeichen finde. Binärpakete ist der schlechte Kompromiss für Leute, die zu doof sind, aus den Sourcen zu bauen. Und die sind bei Rust nicht Zielgruppe. Dafür ist die Lernkurve zu steil bei Rust.
Aber wenn man runterscrollt, kriegt man auch die Quellen. Und wenn man da configure und make aufruft, dann … zieht der ungefragt ein Binärpaket einer älteren Rust-Version, installiert das, und baut dann damit. Das vereint die Nachteile von "aus Binärpaket installieren" mit der Wartezeit von "aus Quellen bauen" und weicht etwaigen Vorteilen weiträumig aus. Völlig gaga. Aber es gibt eine configure-Option, dass man das installierte Rust haben will.
Aus meiner Sicht ist der perfekte Kompromiss, was Ocaml macht. Da kommen die Quellen mit einem kleinen C-Bootstrap-Interpreter, und der baut dann den Compiler, und der baut sich dann nochmal selber. So muss das sein. Ist es aber bei Rust leider nicht. Bei Go auch nicht mehr, übrigens.
Anyway. Wenn man das über sich ergehen lässt und Rust aus den Sourcen baut, dann kriegt man eine Version ohne cargo. cargo ist das Packaging-Tool von Rust. Ohne cargo kann man nichts bauen. Insbesondere kann man nicht cargo ohne cargo bauen. Und da muss ich sagen: WTF? Selbst GNU make kann man ohne make bauen! Das ist ja wohl absolut offensichtlich, dass man solche Henne-Ei-Probleme vermeiden will!?
Insgesamt muss ich also meine Kritik zurückziehen, dass Rust immer noch nicht mit OpenSSL 1.1 klarkommt. Tut es, nur halt anscheinend nicht in der stable-Version. Aber diese cargo-Situation finde ich ja noch schlimmer als die OpenSSL-Situation war. Meine Güte, liebe Rust-Leute! Bin ich ernsthaft der erste, der über das Bootstrapping nachdenkt?!
Oh ach ja, ripgrep. ripgrep kann man nicht mit der Stable-Version von Rust kompilieren. Und auch nicht mit der Beta-Version. Das braucht die Bleeding-Edge-Version.
Nun ist Rust eine relativ frische Sprache und sie haben daher eine Familienpackung Verständnis für so Kinderkrankheiten verdient. Aber dann nennt euren Scheiß halt nicht Version 1.irgendwas sondern 0.irgendwas.
Update: Wie sich rausstellt, lässt sich ripgrep doch mit älteren Rust-Versionen kompilieren, allerdings dann ohne SIMD-Support. Wenn ich ripgrep ohne SIMD-Support haben wollen würde, könnte ich auch grep -r benutzen oder silver surfer. Was ich versucht habe, um ripgrep zu bauen: git clone + cd ripgrep + ./compile. Mir erklärt jetzt jemand per Mail, dass das gar nicht der offizielle Build-Weg ist unter Rust. Das hat sich mir als Rust-Neuling so nicht erschlossen. Und es wirft die Frage auf, wieso der Autor von ripgrep dann ein configure-Skript beliegen muss und das dann auch noch was anderes tut als der Standard-Buildweg. Ist der Standard-Weg kaputt und man kann die zusätzlichen Flags, die er da benötigt, nicht einstellen?
Update: Ein paar Leute fragen jetzt rhetorisch, wie ich denn meinen C-Compiler gebootstrappt habe. Das Argument könnte man gelten lassen, wenn es von Rust aus möglich wäre, einen C-Compiler zu bootstrappen. Ist es aber nicht. Aber mit einem C-Compiler kann man diverse andere Sprachen bootstrappen, u.a. Go, Lisp, Forth, Scheme, Ocaml, C++, Javascript, Java, .... Aber um kurz die rhetorische Frage zu beantworten: Meinen C-Compiler habe ich cross-compiled. :-)
Update: Bei Ocaml ist es auch nicht so rosig, wie ich es geschildert habe. Der in C geschriebene Interpreter ist bloß ein Bytecode-Interpreter, und ein vor-gebauter Bytecode liegt dann halt binär bei. Ist auch nicht ideal. Das ist halt auch ein schwieriges Problem. Ich frage mich halt, ob man bei sowas wie Rust nicht trennen kann. Mein Verständnis war, dass die Sprache Rust schon ziemlich final ist und die Dynamik eher in der Laufzeitumgebung und den Libraries ist. Dann könnte man ja beispielsweise einen Minimal-Interpreter oder Nach-C-Übersetzer bauen, der sich die komplizierten Dinge wie Borrow-Checker, Solver und Optimizer spart.
OpenSSL 1.0 ist tot. OpenSSL 1.1 ist das API, das man benutzen müssen wird, wenn man mit OpenSSL TLS 1.3 haben will, und das will man. Software, die nicht mit den API-Änderungen von OpenSSL 1.1 klarkommt, kann auch direkt in die Tonne.
Ich finde das echt enttäuschend, wie einige Open-Source-Projekte da einen auf Winterschlaf machen. Als ob das ein Problem wäre, was man aussitzen kann. Ach komm, ich warte einfach ein halbes Jahr, dann wird schon jemand einen Patch schicken!1!!
Update: Oh super, ich sehe gerade, dass OpenSSH auch nicht mit OpenSSL 1.1 zusammenarbeiten will. Von den Leuten, die sich über Microsofts Embrace-and-Extend aufgeregt haben, kommt jetzt "wir machen kritische Infrastruktur kaputt, weil die OpenSSL-Leute uns im Sandkasten mit Sand beworfen haben". Ganz tolle Community, diese OpenBSD-Leute!1!!
Hups.
Immerhin: Wenn ihr immer schön präemptiv geupdated habt, dann besteht jetzt kein akuter Handlungsbedarf.
Ja? Echt? Warum denn bitte!? Wie krass müssen die denn noch verkacken? Hat das OpenSSL-Desaster nicht gereicht? Oder das xscreensaver-Debakel? Der letzte APT-Totalschaden?
Übrigens ist damals wie heute die korrekte Reaktion nicht "mal die Pakete updaten" sondern "mal das System komplett frisch aufsetzen".
The highest security defect being fixed is classified as severity "High", and does not affect OpenSSL versions prior to 1.1.0.
Aber man kriegt ein Gefühl dafür, mit was für Wildwestmethoden Webseiten auf die informationelle Selbstbestimmung ihrer Benutzer scheißen, und die Daten gleich an ein halbes bis ganzes Dutzend von Drittverwertern weiterreichen. Die können alle sehen, welche Artikel du liest. Und weil heutzutage überall in der URL steht, worum es in dem Artikel ging, müssen die nicht mal auf die URLs klicken, von denen der Traffic kam, um zu sehen, was deine Präferenzen so sind.
Ich habe mich daher dafür entschieden, grundsätzlich mit angeschaltetem umatrix zu surfen. Das macht regelmäßig Stress und Ärger. Eingebettete Youtube-Videos kommen erst nach Freischaltung, Webformulare failen, Onlineshopping geht nicht, weil externe Zahlungsdienstleister eingebettet werden, und die dann am besten auch noch Cross-Domain "Verified by Visa" oder ähnlichen Bullshit einzublenden versuchen. Ich kann gar nicht überbetonen, was das für ein Ärger täglich ist. Aber das ist es mir wert.
Und im Vergleich zu Lösungen wie Ghostery habe ich halt keine Liste von bekannten Trackern, die ich wegfiltere, sondern ich filtere alles weg, was nicht explizit erlaubt ist. Wenn ihr das auch mal probieren wollt, dann bereitet euch mental darauf vor, dass das mit Ärger verbunden ist. Mit Ärger und mit Erkenntnisgewinn.
Dem geneigten Leser wird bei der Gelegenheit auffallen, dass auch eine meiner Webseiten externe Referenzen macht — Alternativlos lädt die Audiodaten vom externen CDN nach. Das läuft unter einer anderen Domain, nämlich as250.net. Nun könnte ich dafür ja auch einen DNS-Alias machen, damit alternativlos.as250.net auch unter as250.alternativlos.org erreichbar ist. Der Grund, wieso ich das im Moment nicht mache, ist weil ich dem CDN dann auch für SSL-Verbindungen einen Schlüssel geben muss, der für eine alternativlos.org-Subdomain gültig ist. Das zieht aber andere Sicherheits-Nachteile nach sich.
Update: Ich sollte mal konkreter werden, was das Problem ist. Es geht darum, was der mögliche Schaden ist, wenn das CDN gehackt wird. Im Moment kann das CDN böse Audiodateien ausliefern, die den Browser verwirren oder angreifen. Wer nicht immer seine Patches einspielt, hat aber grundsätzlich ein Problem, insofern mache ich mir da weniger Sorgen. Aber wenn ich jetzt dem CDN ein SSL-Zert für cdn.alternativlos.org ausstelle, und der setzt Cookies, dann kann er die mit dem Scope alternativlos.org setzen. Das betrifft mich jetzt konkret auch nicht, weil ich nicht mit Cookies operiere, aber es ist ein Problem und einer der Gründe, wieso CDNs häufig auf eigenen Domains laufen. Schlimmer (?) noch: Wenn alternativlos.org jetzt selber Cookies setzen würde, sagen wir mal um die Session zu identifizieren, dann würden die auch alle beim gehackten CDN-Server übergeben werden, und der könnte alle Sessions klauen. Betrifft alternativlos.org jetzt nicht konkret, aber das sind so die Probleme dabei, wenn man das CDN auf eine Subdomain legt.
Ich vermute sowas wie einen RSS-Client, der gegen eine gammelige, antike SSL-Library gelinkt ist oder so. Oder vielleicht ein System mit gammeliger SSL-Library aus dem letzten Jahrtausend?
Prüft doch mal bitte, ob ihr das seid, und schaltet das ab, wenn dem so sein sollte. No hard feelings.
Update: Danke, hat aufgehört!
Ich habe in gatling vor mehreren Jahren SSL-Support eingebaut, mit OpenSSL damals. Später habe ich auch Unterstützung für PolarSSL nachgerüstet, und als die sich nach mbedtls umbenannt haben, bin ich mitgegangen. Der Code für den SSL-Support war immer ziemlich krude, weil ich a) damit keine Erfahrung hatte und b) die APIs alle furchtbar und kompliziert sind und üblicherweise die Dokumentation eher untauglich ist. So mache ich, was viele in der Situation machen, und greife mir ein Stück Code, das ich irgendwo funktionieren gesehen habe, und übernehme das. Bei PolarSSL war das recht einfach, die liefern ein relativ minimales Beispielprogramm mit. Bei OpenSSL war das die Krätze. Es gibt da im Wesentlichen ein Beispielprogramm, nämlich den Code für s_client in dem OpenSSL-Binary, und der macht lauter unnötige und unklare Sachen. Die beschreiben das sogar irgendwo als Absicht, weil das eher Code zum Testen ist als Code zum als Vorbild nehmen.
Benutzung von SSL ist nicht so schwierig, man macht einfach statt read() SSL_read() und statt write() SSL_write(), mal ganz plump gesprochen. Hacks wie sendfile gehen dann halt nicht. Im Fall von gatling kommt erschwerend hinzu, dass ich da auf non-blocking sockets operiere, und SSL halt ein Protokoll ist, d.h. die Signalisierung ist komplexer. write() sagt unter Unix EAGAIN, um mir zu sagen, dass ich später nochmal probieren muss. Bei SSL kann es aber sein, dass ich SSL_write später nochmal probieren muss, aber das nötige Event ist nicht "kann auf diesem Socket schreiben" sondern "kann von diesem Socket lesen", beispielsweise wegen einer Renegotiation oder so. Daher haben SSL_write() und SSL_read() zwei Rückgabewerte, einen für "komm wieder, wenn ich schreiben kann" und "komm wieder, wenn ich lesen kann". Aber gut, kein Ding.
Haariger ist die Initialisierung der Sockets, das ist echt fummelig und nervig. Und die Dokumentation, die da ist, kommt in Form einer Referenz, nicht in Form eines Tutorials oder einer Einführung. Bei OpenSSL operiert man nicht auf Deskriptoren, sondern auf einer Abstraktion namens SSL*. Es gibt aber auch ein SSL_CTX*, und der Unterschied ist nicht so klar, insbesondere weil man seinen Private Key in das SSL reinlädt, nicht in das SSL_CTX. Jedenfalls war das in dem Code so, den ich damals kannibalisiert habe. Wie sich rausstellt, kann man den Private Key aber auch in den SSL_CTX reinladen, und damit steht der Wiederbenutzung des selben SSL_CTX nichts im Wege. Das habe ich neulich mal eingebaut, und die SSL-Performance hat sich wenig überraschend massiv verbessert. Ist ja auch irgendwie klar. Wieso haben die überhaupt ein API, um den Private Key in das SSL* reinzuladen statt in den SSL_CTX*? Kann ich nicht nachvollziehen, verwirrt bloß.
Aber egal, darum geht es nicht. Was ich erzählen wollte: Der SSL-Code hat zwar seit Jahren funktioniert, aber auf ptrace (meinem Blog-Server) habe ich immer bizarre Probleme gesehen, wenn ich eine größere Datei per SSL runterladen wollte. Größer ist so "ab 100 KB" in dem Kontext. Der genaue Stresspunkt variierte. Das Symptom war, dass die Verbindung in der Mitte abbrach. wget verbindet sich dann neu und probiert nochmal, aber das nervt schon. Und vor allem war völlig unklar, was das Problem war. Normale SSL-Verbindungsabbrüche schicken über die Verbindung vorher ein Alert-Paket, damit die andere Seite sieht, wieso die Verbindung geschlossen wurde. Das ist auch nichts, was ich in gatling programmatisch mache, sondern das macht OpenSSL unter den Abstraktionen. So ein Paket kam bei dem wget nicht an.
Daraus schloss ich, dass ich wahrscheinlich irgendwo versehentlich einen Deskriptor schließe, der zu einer anderen Verbindung gehört, und habe aktiv nach Race Conditions und so gesucht. Zuhause konnte ich das nie nachstellen. Schlimmer noch: Wenn ich einen zweiten gatling auf ptrace gestartet habe, konnte ich das auch nicht nachstellen. Nur auf dem Haupt-Blog-gatling mit der ganzen Last tauchte das Problem auf.
Diese Untersuchungen führten zu diesen Überlegungen. Und als ich den Bug da geschlossen hatte, … brachen die SSL-Downloads immer noch ab. Es war also klar, dass ich da noch tiefer analysieren muss. Ich fing also an, mir das Log mit SSL-Fehlermeldungen zuspammen zu lassen, und kriegte da Fehlermeldungen, die so aussahen, als machte ich beim Ausgeben der Fehlermeldungen was falsch. Ich machte also einen strace auf gatling, während das Problem auftauchte, und sah eine Abfolge von Syscalls in etwa so:
accept() -> 23Hier konnte ich also ganz klar sehen, dass kein Fehler vorlag, aber die Verbindung trotzdem geschlossen wurde.
ein paar kurze read/write auf Socket 23, kein Fehler
ein längerer read auf Socket 23, kein Fehler (offenbar der HTTP-Request)
ein langes write auf Socket 23, kein Fehler
noch ein langes write auf Socket 23, diesmal wurden von den 8k nur 4k geschrieben (der Socket ist non-blocking, das soll also so sein)
SSL-Fehlermeldung im Log
close(23)
Nun ziehe ich mir ja SSL-Fehler nicht aus dem Arsch, sondern die kriege ich vom API gemeldet. Da stimmt also was nicht, und es lag nicht daran, dass meine State Machine irgendwo versehentlich einen Socket zu früh oder von woanders schließt.
Die komische SSL-Fehlermeldung, die ich bekam, war übrigens, dass "Shutdown in der Init-Phase aufgerufen wird" (ich hab mir die genaue Fehlermeldung nicht aufgeschrieben, aus der Erinnerung). SSL_Shutdown wird in gatling in cleanup() aufgerufen, das ist die zentrale "fertig, mach mal alle Ressourcen weg"-Funktion. So und jetzt der Fnord: OpenSSL hat einen Error Stack, nicht bloß eine aktuelle Fehlermeldung. Nach SSL_Shutdown habe ich keine Fehler geprüft, denn ob das protokollmäßig funktioniert oder nicht ist mir egal, ich schließe danach den unterliegenden Socket und gebe das SSL* frei. Aber gut, für das Debugging habe ich da mal ein Stück Code eingefügt, das den Error Stack leert.
Plötzlich waren die Verbindungsabbrüche weg.
Ich reime mir das jetzt so zusammen:
Ich hoffe mal, ich freue mich nicht zu früh, und der Bug tritt jetzt wirklich nicht mehr auf. Der ist nicht so einfach zu reproduzieren.
Wir lernen daraus: Error Stack nicht global sondern pro Context oder noch besser pro State machen.
Update: Hier kommt noch der Hinweis rein, dass einem dieser globale Error-Stack dann bei Multithreading massiv auf den Fuß fallen kann. Das befürchte ich auch. gatling ist im Moment noch nicht multithreaded.
Update: Ah, der Error Stack ist pro Thread. Oh Graus ist das alles widerlich.
Einmal mit Profis arbeiten!
Ich kann hier übrigens seit Wochen kein Rust kompilieren, weil deren Packaging-Tool cargo openssl benutzt und das Modul dafür nicht mit Version 1.1 kompiliert.
Zu früh gefreut! Am 22. September kommt mal wieder ein Sicherheitspatch raus, wieder katastrophal was mit HIGH dabei.
TLSv1+HIGH:!SSLv2:+TLSv1:+SSLv3:!aNULL:!eNULL:@STRENGTHWie sich rausstellt, interpretiert OpenSSL das TLSv1 als TLSv1.0, nicht "alle TLSv1 Versionen" und hat die TLS 1.2 Ciphersuites explizit rausgenommen. Ich habe das jetzt wie folgt geändert:
TLSv1.2+HIGH:TLSv1+HIGH:!SSLv2:+TLSv1:!SSLv3:!aNULL:!eNULL:@STRENGTHMöglicherweise ist ja auch der eine oder andere von euch in die Falle getappt.
Update: Hatte versehentlich zweimal den selben String eingefügt.
Die Shared Library hat eine neue Version, d.h. man muss einmal alle Software neu bauen. wget, curl, alles. curl baut gegen das neue OpenSSL, aber ist damit allein auf weiter Flur. wget musste ich patchen, mutt musste ich patchen, neon (für Subversion) musste ich patchen. git war gut. Der SSL-Code aus gatling geht überraschenderweise auch ohne Änderung. Aber sonst so? Kahlschlag.
Python baut zum Beispiel nur die Module _hashlib und _ssl nicht mit. Ihr könnt euch ja ausmalen, was das alleine an Folge-Infrastrukturapokalypse nach sich zieht. Bei mir konkret geht daher gerade SCons nicht, welches das Buildsystem von serf ist, ohne das ich Subversion nicht reparieren kann.
Die Perl-Module gingen auch. Aber so gefühlt ist über die Hälfte der Software jetzt zerbrochen.
Ich hätte mir ehrlich gesagt erhofft, dass die OpenSSL-Leute da eine klitzekleine Warnung in ihren Bart säuseln, bevor sie so eine Apokalypse lostreten.
Auf der anderen Seite ist das ja auch ein schöner Impuls, mal generell von diesem OpenSSL wegzumigrieren.
Update: Bei Debian hat es auch das eine oder andere Paket zerrissen.
Update: Ein Leserbrief dazu:
Wollte nur kurz darauf hinweisen, daß die API-Änderungen bei OpenSSL 1.1 nicht nur jede Menge inkompatibilitäten nach sich ziehen, bei denen was laut kaputt geht (compiletime error), sondern auch API-Änderungen dabei sind, die stillschweigend security-buigs erzeugen können.
Beispiel: Die HMAC manpage sagt:
HMAC_Init_ex() initializes or reuses a HMAC_CTX structure to use the
function evp_md and key key. Either can be NULL, in which case the
existing one will be reused.HMAC_Init_ex liefert erst seit kurzem einen Fehlerstatus zurück - früher hatte sie keinen Rückgabewert und konnte nicht fehlschlagen. Daher testet auch ne Menge Software nicht auf sowas, und das wra bis vor kurzem auch korrekt.
In OpenSSL 1.1 gibt es aber folgende Änderung:
/* If we are changing MD then we must have a key */
if (md != NULL && md != ctx->md && (key == NULL || len < 0))
return 0;d.h. anders als dokumentiert, kann nicht "either NULL" sein. Aber alte Software kann das nicht prüfen, und welche HMAC dann im Endeffekt berechnet wird, steht in den Sternen.
Die Reaktion von OpenSSL upstream war, die Doku zu ändern.
D.h. nicht nur breaked openssl die API (teilweise unnötig) so, daß Programme nicht mehr kompilieren, nein Programme, die mal korrekt waren und jetzt immer noch kompilieren haben jetzt unter Umständen größere Sicherheitslöcher.
(Es gibt eine Reihe ähnlicher stiller API-Änderungen in OpenSSL 1.1)
(und ja, wegmigrieren hört sich gut an, aber es gibt häufig keine alternative mit gleichen Funktionsumfang ohne diese Probleme - gnutls hat z.b. mindestens bis vor kurzem kein RSA-OEAP padding unterstützt, sondern nur das extrem anfällige kaputte PKCS-padding).
Und zu meiner Aussage, dass interne Typen opak gemacht wurden, kommentiert der Einsender noch:
Das, so würde ich sagen, ist falsch. Erstens sind viele dieser Datentypen nicht intern, sondern man musste früher darauf zugreifen weil es keine accessors gab und das auch so dokumentiert war, und zweitens ist das Hautproblem nicht, daß die Typen opak sind, sondern daß man früher structs selbst allozieren musste und das jetzt nicht mehr geht, d.h. alter code nicht compiliert, auch wenn er nicht auf irgendwelche strukturen zugegriffen hat.
Der Hintergrund für viele solche Änderungen war, daß man man structs nicht mehr auf dem Stack hat - sehr löblich. Das wurde aber so gelöst, daß man jetzt alles dynamisch über eine spezielle openssl-Funktion allozieren muss, die es früher nicht gab, und code, der die structs selbst deklariert hast, schlägt fehl, weil der Typ opak ist, auch, wenn garnicht darauf zugegriffen wird.
Im Allgemeinen ist es deshalb nicht möglich, code zu schreiben, der mit der neuen und der alten API funktioniert (also, ohne #if-massengrab).
Mir ist aufgefallen, dass auch Code mit #if-Massengrab bricht mit Version 1.1. Früher konnte man mit OPENSSL_NO_SSL2 gucken, ob die verwendete Version mit SSL2-Support kommt oder nicht. OpenSSL 1.1 hat kein SSL2 mehr, aber deklariert auch dieses Präprozessorsymbol nicht.
Update: Noch ein Leserbrief zur OpenSSL-Version:
OpenSSL 1.1 Unterstützung für Python ist fertig, hängt aber noch im Codereview, weil Python Core Devs mit OpenSSL-Kenntnissen Mangelware sind. Neben mir gibt es zur Zeit nur drei weitere aktive, von denen zwei mit anderen Dingen beschäftigt sind. Zum Glück habe ich schon vor einem halben Jahr mit meinem Patch angefangen angefangen und einige Patches bei OpenSSL eingereicht. Andernfalls würden mir jetzt die Zugriffsfunktionen auf diverse struct member fehlen.
https://bugs.python.org/issue26470Zwei weitere Punkte:
1) Es reicht nicht, nur auf OPENSSL_VERSION_NUMBER zu prüfen. LibreSSL hat OPENSSL_VERSION_NUMBER gekapert und missbraucht das Makro für die eigene Versionsnummber 2.x. Man muss also immer noch zusätzlich auf nicht-LibreSSL testen:
#if (OPENSSL_VERSION_NUMBER > 0x10100000L) || !defined(LIBRESSL_VERSION_NUMBER)2) Nach sweet32 hat OpenSSL 1.0.2 nur noch einen sicheren Algorithmus für symmetrische Verschlüsselung. ChaCha20 gibt es erst in 1.1. Ich habe mit Richard Salz vom OpenSSL Team gesprochen. Er teilt meine Sorge, trotzdem wird OpenSSL 1.0.2 LTS keine Unterstützung für ChaCha20 erhalten.
https://twitter.com/ChristianHeimes/status/768434388052938756
Nur falls jemand dachte, hey, dann bleib ich halt bei OpenSSL 1.0.2! Übrigens sei an der Stelle der Hinweis erlaubt, dass Version vor 1.0.1 schon länger gar keine Updates mehr kriegen. Man sieht vereinzelt da draußen noch OpenSSL 0.9er-Versionen rumfliegen. Ganz, GANZ gruselig.
Das mit Chacha20 war bei mir übrigens auch der Auslöser für den Umstieg auf 1.1. OpenSSL 1.1 hat nämlich endlich Support für die Dan-Bernstein-Erfindungen Chacha20 und Poly1305. Je älter ich werde, desto weniger traue ich Krypto-Sachen, die nicht von djb kommen oder von ihm abgenickt wurden. Der Mann hat einfach zu oft Recht behalten, als alle anderen abgewunken, relativiert oder gelacht haben. Ich sehe übrigens keinen inhaltlichen Grund, wieso man Chacha20 und Poly1305 nicht auch in 1.0.2 haben sollte, das gibt es seit Jahren für 1.0x-Versionen von OpenSSL als Patch, und LibreSSL hat es auch von Anfang an drin. Finde ich absolut unverständlich, was das OpenSSL-Team sich da leistet.
Besonders beunruhigend:
Remote code execution vulnerability in OpenSSL & BoringSSLNanu? Neue Lücke? Nein! Die hier! Seit Mai bekannt. Redhat hat (um nur mal ein Beispiel für eine andere Linux-Distribution zu nennen) seit dem 10.5. ein Patch draußen. Android wird jetzt gefixt. Ein Bug, den sie als "remote code execution" einschätzen und selbst als kritisch einstufen.
Soll das ein Scherz sein? Ist das der Versuch, Microsoft weniger lahmarschig aussehen zu lassen?
Naja auf der anderen Seite ist das Bulletin auch schon wieder fast nen Monat alt. Keine Ahnung, wieso das jetzt erst die Runde macht.
Die gefixten Bugs sind mehrere Memory Corruptions, die OpenSSL da jeweils als "keine akute Gefahr für die Anwohner" runterzureden versucht, und einem Fall von "ein MITM kann den Traffic entschlüsseln". Die Analyse mag im Einzelfall zutreffen, dass die Memory Corruption-Bugs normale SSL-Server nicht betreffen, aber damit sollte sich niemand rausreden und das Patchen verschieben!
New hotness: "Government-backed attackers may be trying to steal your password"-Terrorwarnseiten.
Wow. Dieser ganze Terrorwarnscheiß nimmt echt überhand. Da wünscht man sich doch ein paar schöne unsichere Blümchenwiese-Seiten zurück.
Im Übrigen ist es natürlich völlig absurd, wenn Google davor warnt, dass Regierungen Passwörter stehlen wollen. Wenn die US-Regierung klopft, rückt Google deine Mails raus. Steht so im Gesetz, da wo Google residiert.
Update: Hier ein Statement von StartSSL dazu, das einem Leser auf Nachfrage per Mail zuging:
It is not the truth , the reason why he can get the code is that the whois mail address for that domain is his Hotmail. For more information you can visit this link :
https://startssl.com/NewsDetails?date=20160322
We care much about the security ,as we do security things ;) There is no problem with our system ,no worries.
Ich finde das ein wunderschönes, sehr sympathisches Statement :-)
Erstmal gibt es von RPM direkt zwei Stränge, RPM 4 und RPM 5, und beide behaupten von sich, das "offizielle" RPM zu sein. Lolwut?
Gut, hole ich mir RPM 4, weil das auf der Zieldistro eingesetzt wird. Kompiliert nicht. Will NSPR und NSS haben, aber guckt nicht in den Default-Install-Pfaden, konsultiert nicht nspr-config, was genau dafür da ist, und fragt nicht pkg-config, was auch genau dafür da ist. Nein. Und findet es dann natürlich nicht.
OK, überschreibe ich $CC, findet er das. Und findet dann Berkeley DB nicht. Berkeley DB? Srsly? Ist systemweit installiert. Klar, könnte man nehmen. Will man aber nicht. Nein, RPM will die Sourcen in seinem Quell-Tree haben und dann neu bauen. Gut, lege ich ihm das hin.
Stellt sich raus: Einfach ein RPM zu den anderen RPMs auf dem Install-ISO tun reicht nicht. Nein. Man muss da auch "repodata" neu erzeugen. Und das kann RPM nicht.
Natürlich nicht! Warum auch?
Dafür braucht man ein externes Tool namens createrepo. Das ist in Python.
Da gehen ja bei mir direkt alle Warnlampen an.
Installiere ich das also. Rufe es auf. Geht nicht. Braucht yum. Auch ein Python-Tool. Die zweite Riege Warnlampen geht an. Installiere ich also yum. Rufe es auf. Geht nicht. Braucht das rpm-Modul. Wie, ist das nicht bei RPM dabei?
Doch, ist es. Aber RPM installiert das nicht, außer man bittet explizit darum.
Also nochmal RPM gebaut. Rufe yum auf. Geht nicht. "No module named sqlitecachec". Oh super! Wo kriegt man das her? Steht da nicht. Warum würde das da auch irgendwo stehen? Ist ja nicht so, als wäre das hier alles die zentrale Software, auf der eine "Enterprise"-Distribution aufsetzt! Warum sollte das einfach so funktionieren?
Googelt man das also, findet keine Homepage. Nee, warum auch. Man findet diverse Distro-Pakete. Oh, das kommt von "yum-metadata-parser"! Na da hätte man ja auch direkt selber drauf kommen können!1!! 2010 zuletzt angefasst.
yum geht. createrepo immer noch nicht. Braucht "deltarpm". Sagt mal, soll das hier ein Scherz sein? Sogar der Rotz von Gnome prüft vor dem Bauen, ob die Abhängigkeiten erfüllt sind!
Oh und wer hat sich denn bitte das RPM-Dateiformat ausgedacht?! Was soll das werden? Soll das außerirdische Invasoren in den Wahnsinn treiben, damit sie nicht die Menschheit ausrotten können? Heilige Scheiße. Dagegen ist ja der Debian-Kram einleuchtend und selbsterklärend! Und selbstdokumentierend gar. Wie ein .deb funktioniert, kann man mit file und Hausmitteln rausfinden, man braucht nicht mal einen Hex-Editor.
Meine Güte. Und ich kenne ansonsten durchaus zurechnungsfähige Leute, die schwören auf CentOS!
Update: Vielleicht sollte ich mal sagen, wie ich mir so ein Paketverwaltungstool vorstelle. Meine Anforderung wäre, dass das immer funktioniert. Python zerschossen? Perl nicht installiert? glibc-Update in der Mitte fehlgeschlagen? Der Paketmanager muss noch gehen und das noch retten können. Und er muss klein genug sein, um mit Metadaten in 5 MB zu passen. Muss auch ohne OpenSSL und curl und wget arbeiten können, zumindest im Notfall. Von den Systemen, die ich bisher gesehen habe, gefällt mir pacman (Arch-Linux) am besten. Aber da geht noch was.
Update: Erwähnte ich, dass repodata dann XML und Sqlite ist? Geht's noch? Wieso habe ich dann Berkeley DB in RPM reinlinken müssen? Oh und wenn mir der Distro-Installer während der Installation Werbung anzeigt, habe ich da überhaupt kein Verständnis für.
Update: Wobei mir die Übung ja wenigsten eine Sache klar gemacht hat. Jetzt verstehe ich, wieso überall diese Cloud-Spezial-Distros aus dem Boden sprießen. Das "Minimal"-Redhat ist 1GB groß nur für Code. Und da ist dann kein netstat bei.
Double free (auch bekannt als remote code execution). Severity low. Ja nee, klar.
Oh hier, noch einer. Memory Corruption. Auch bekannt als remote code execution. Severity low.
Phew, und ich habe mir schon richtig Sorgen gemacht!
Oh, und … das hier. Aber das betrifft euch bestimmt nicht, denn ihr habt bestimmt SSL2 deaktiviert. Habt ihr doch, oder? ODER?
Zur Klärung einiger Punkte, die vielleicht von dem Report nicht so ersichtlich sind…Ich habe inzwischen auch mal ein bisschen in den PDFs geblättert und muss meine Meinung zu dem Audit revidieren. Schon das Inhaltsverzeichnis macht klar, dass hier methodisch und systematisch vorgegangen wurde, und nicht nur ein bisschen Cherry-Picking stattgefunden hat.
Da es praktisch unmöglich ist, den ganzen OpenSSL-Code durchzublicken und zu evaluieren, waren im Scope der Analyse vor allem folgende Punkte:
- OpenSSL server
- TLS 1.2
- Verifikation der Gegenmaßnahmen der bekannten Angriffe (Identifikation des relevanten Codes war im Scope)
- kryptografische Angriffe
Alle Analysen und Algorithmen sollten nachvollzogen werden.
Vor allem wegen dem dritten Punkt kann ein Eindruck entstehen, dass nichts neues gemacht wurde (ja, wir haben z.b. Heartbleed, EarlyCCS nachgeprüft und es tut mir leid, wenn es dir nicht gefällt). In der Studie waren aber andere Angriffe, die vorher nicht konkret auf OpenSSL evaluiert wurden, ich nenne nur ein paar Beispiele:
- Bleichenbacher Angriff: da sind wir konkret noch tiefer auf die Angriffe eingegangen, als in unserem USENIX Paper (Link).
- DH-Kleine Untergruppen: es sind mir keine öffentlichen Dokumente bekannt, wo die Angriffe auf die letzten OpenSSL-Versionen besprochen wären.
- Invalid Curve Angriffe: vorherige Papers untersuchen andere Art dieser Angriffe, daher finde ich eine Überprüfung legitim. Bei den letzten zwei Punkten wurde es festgestellt, dass SSL_OP_SINGLE_DH_USE und SSL_OP_SINGLE_ECDH_USE nicht default sind, was im Report steht…
Ein falscher Eindruck hätte auch dadurch entstehen können, dass die Ergebnisse erst jetzt publiziert wurden. Die Studie wurde im Zeitraum cca. 6-2014/3-2015 durchgeführt.
Generell finde ich es extrem schwer in einer Bibliothek bugs zu finden, die täglich von hunderten Forschern auch untersucht wird. Da wir keine super gefährliche bugs gefunden haben, bedeutet es nicht, dass unsere Analyse schlecht war. Ein Beweis dafür liefern auch die letzten CVEs: es ist mir nicht bekannt, dass in den letzten zwei Jahren bugs gemeldet wurden, die in unserem Scope gewesen wären und die wir übersehen hätten (oder?).
Besonders die erwähnten Krypto-Dinge gefallen mir gut, denn das sind die Sachen, bei denen ich mir nicht sicher bin, dass ich das ordentlich getestet gekriegt hätte.
Für die Zukunft fände ich es gut, wenn wir vom Reaktiven zum Aktiven übergehen könnten. OpenSSL braucht mehr als einen Audit. OpenSSL braucht zum Beispiel eine Infrastruktur, um den Krypto-Kram optional in einen eigenen Prozess auszulagern, damit bei einem Bug in Apache nicht auch die privaten TLS-Schlüssel lecken können. Und was mich bei OpenSSL neben der furchtbaren Codestruktur und den ganzen bizarren Abstraktionen und Indirektionen am meisten stört, ist dass die Defaults in so vielen Fällen Scheiße sind. Erstens braucht man eine metrische Tonne Cargo Cult-Code, um überhaupt den ganzen nötigen Buchhaltungsscheiß zu erledigen, und dann braucht man nochmal zwei metrische Tonnen Code, um die ganzen schlechten Defaults zu korrigieren. Das geht so nicht.
Ich weiß nicht, ob das BSI dabei helfen kann. OpenBSD hat ja mal angefangen, einfach ein anderes API anzubieten, das weniger schlimm zu benutzen ist. Ich denke, da müssen wir hin.
Ich hätte mich da auch bewerben können, aber habe es nicht getan, weil ich lieber wollte, dass das jemand macht, der die ganzen Crypto-Details so gut versteht, wie ich typische C-Programmierfehler verstehe. Kurz: Ich habe mir Sorgen gemacht, dass wenn ich das mache, dass ich das dann nicht richtig abdecke. Sondern halt nur den Teil wirklich angucke, den ich halt besonders gut kann, und über den Rest im schlechtesten Fall gar nichts sagen kann oder im besten Fall zwar geguckt habe, aber möglicherweise nicht genug Hintergrundwissen oder Durchdringung der Materie mitbringe, so dass meine Aussage kein großes Gewicht hat am Ende.
Nun, der Audit hat stattgefunden.
Zu meiner großen Enttäuschung muss ich jetzt konstatieren, dass das dann halt andere Leute genau so gemacht zu haben scheinen, wie ich es bei mir vermeiden wollte. Die haben halt da geguckt, wo schon Lücken bekannt waren, und haben dann diese Lücken nicht mehr gefunden. Diesen Audit hätte man sich auch sparen können. Einen Black-Box-Audit auf den Zufallszahlengenerator? Soll das ein Scherz sein!? Und dann gnädigerweise auch mal kurz ein paar Zeilen Quellcode angeguckt?!?
Das war ein Reinfall. Das wäre ja sogar besser geworden, wenn ich mich beworben hätte. Und das ist keine starke Aussage, siehe oben.
Sehr schade. Eine vertane Chance.
Wobei ich meine Einschätzung jetzt natürlich auf diese Meldung bei Heise stütze. Vielleicht ist die ja falsch und es war besser als es sich da jetzt anhört.
Update: Einer der Auditoren hat mir eine Mail geschrieben:
Die Darstellung in deinem Blogeintrag bzw. Heise ist nicht korrekt (http://blog.fefe.de/?ts=a842a5a6).
Die Analyse des RNG war nur im ersten Schritt Black-Box (wodurch Schwächen gefunden wurden). Im zweiten, selbstverständlich aufwändigeren Teil haben wir uns den Source Code angeschaut, ein Modell des RNG-Algorithmus aufgebaut, den Lebenszyklus des RNGs und dessen Zustand angeschau, etc. Die Methodik ist im Bericht dokumentiert, ein Blick in das Inhaltsverzeichnis liefert schon Informationen dazu.
Bei der Schwachstellenanalyse wurde ähnlich vorgegangen. Es wurden Blackbox-Tests durchgeführt (durch die Schwächen gefunden werden konnten), sowie eine Code Review verschiedener wichtiger Komponenten durchgeführt. Wir mussten selbstverständlich den Scope einschränken (wen interessiert schon die GOST und SSL3.0-Implementierung?), aber denken, dass die wichtigen Komponenten in einem angemessenen Rahmen betrachtet wurden.
Nach meiner Einschätzung würde sich das BSI mit einer oberflächlichen Analyse nicht zufrieden geben. Da sitzen Leute, die sich mit der Thematik sehr gut auskennen.
Update: Hier ist das PDF des Berichtes.
Update: Oh, es gibt nicht nur ein PDF, sondern drei.
Das fiel mir auf, weil ich hier ein Hotel-WLAN habe, das nach dem DHCP HTTP abfängt und auf eine Login-Seite umleitet, wo man dann die AGB abnickt und dann hat man ein bisschen Internet.
Und das geht nur bei HTTP, bei HTTPS gibt es bloß Fehlermeldungen und keine Umleitung. Und ich muss dann immer von Hand eine HTTP-URL eingeben.
Auch ich als alter Zyniker muss konstatieren, dass wir ganz schön was erreicht haben mit der Verbreitung von TLS.
Aber grämt euch nicht, die Lücke betrifft nur die 1.0.2-Serie.
Die, die ich überall ausgerollt habe, weil ich annahm, der neue Code sei weniger beschissen als der alte Code bei denen.
Seufz.
SNI ist eine TLS-Erweiterung, bei der als Teil des Handshakes der Name des Servers überträgt. Vor SNI konnte man pro IP-Adresse nur einen Server per SSL hosten. Meines Wissens unterstützen alle Browser SNI. Dachte ich jedenfalls.
Ich trug also das Letsencrypt-Cert per SNI ein, testete und alles war gut.
Aber es sieht aus, als war das Zufall, denn alle Nase lang kriegte jemand noch das Fallback-Cert zu Gesicht.
Beim Debuggen kam raus, dass das SNI-Callback auch später in der Verbindung nochmal kommen konnte, nicht nur während des Handshakes am Anfang. gatling macht virtuelles Hosting über Unterverzeichnisse, d.h. die Daten für "blog.fefe.de" sind in den Unterverzeichnissen "blog.fefe.de:80" und "blog.fefe.de:443", je nach dem wie der Client reinkommt. Nach dem initialen Handshake ist gatling dann in dem jeweiligen Unterverzeichnis und findet im SNI-Callback das Zertifikat nicht mehr.
Ich habe das dann als kurzer Hack so gefixt, dass ich die Zertifikate mit dem vollen Pfad öffne. Aber im Moment bei meinem Testen habe ich den Effekt, dass Firefox das Letsencrypt-Cert sieht, aber Chrome das CACert-Cert. Ich habe ehrlich gesagt keine Theorie, wieso das so sein könnte. Ich debugge mal weiter.
Update: Nach Shift-Reload zeigt auch Chrome das Letsencrypt-Cert an. Die werden doch nicht ernsthaft die Cert-Daten cachen!? Nee, so blöde kann keiner sein!
Update: Doch, so blöde können die sein.
Update: Et tu, Firefox?
Ich weiß ja nicht, wie es euch geht, aber ich kriege Ausschlag, wenn ich selbstdenkende, selbstreparierende, selbstupdatende Software sehe. Ich habe noch nie erlebt, dass das nicht am Ende mehr Ärger macht, als wenn sie einfach gesagt hätten: diese drei Schritte müssen getan werden.
Ich meine, seien wir doch mal ehrlich hier. Die Leute schaffen es bisher auch, sich SSL-Zertifikate zu beschaffen. Es gibt da etablierte Prozesse, mit denen kommen die Leute klar, und die funktionieren auch. Aber nneeeeiiiiinnn, die Herren Startupklitschen-Vollpfosten brauchen ein selbstdenkendes Python-Environment. Nein, liebe Letsencrypt-Leute, ich werde mir GANZ SICHER NICHT auf meinem Webserver Python installieren, damit ich ein SSL-Zertifikat beantragen kann. Das wird nicht passieren. Nicht in diesem Universum auch auch nicht in irgendeinem anderen.
Diese Wartungsarbeiterzeugungshooligans bieten allen Ernstes einen Weg an, bei dem man sich eine VM oder ein Docker-Image installiert, damit darin ihre gammelige Stinksoftware laufen kann, die dann das Zertifikat beantragt. Geht's noch?!
Die STIRN, die man als so ein Projekt haben muss, um den Leuten zu erzählen, sie sollen bitte "diesen Code hier nehmen und ausführen"! WTF? Ich habe hier Risikominimierung betrieben und die Trusted Computing Base minimiert und jetzt schieße ich mir das alles weg und verdreifache den Footprint des Webservers, um ein SSL-Zert installieren zu können? Was für Leute denken sich denn bitte sowas aus?!
Unfassbar.
Ich weiß ja nicht, ob ihr euch mal angeguckt habt, wie das laufen soll. Aus "Vereinfachungsgründen" stellen die sich vor, dass ich da in meinem Webserver einen Webdienst laufen lasse, der dann aus dem Internet erreichbar sein soll — also mit anderen Worten meine Angriffsoberfläche verdutzendfache! —, und deren Dienst meldet sich dann periodisch bei diesem Webservice und dann updated irgendein Automatismus die Zertifikate. Ja nee, wird nicht passieren. Ganz sicher nicht. Man stelle sich mal vor, Microsoft würde das so machen. Klar können Sie SSL haben, aber dafür müssen Sie diese Backdoor, äh, diesen Service in ihrem IIS freischalten! Und dann meldet sich das Mutterschiff bei Ihnen und richtet das alles ein!1!! Da wäre doch hier die Hölle los!
Ja nee, letsencrypt, so wird das nichts.
Sie bieten wohl auch einen Modus an, der keinen Webservice braucht. Aber den kann ich hier gerade nicht testen, denn
"sudo" is not available, will use "su" for installation steps…Mit welcher Chuzpe diese ganzen Startupklitschenwebdesigner immer glauben, sie könnten ihre ganze Hipsterscheiße weltweit überall voraussetzen!
grep: /etc/os-release: No such file or directory
Sorry, I don't know how to bootstrap Let's Encrypt on your operating system!You will need to bootstrap, configure virtualenv, and run a pip install manually
Please see https://letsencrypt.readthedocs.org/en/latest/contributing.html#prerequisites
for more info
Creating virtual environment…
./letsencrypt-auto: line 166: virtualenv: command not found
Und nein, ich werde mir ganz sicher nicht Docker installieren. Ihr könnt mal alle gepflegt kacken gehen.
Update: Hier hat das mal jemand als statische Webseite implementiert. Ich habe das noch nicht ausprobiert, aber so stelle ich mir das vor.
Update: Weil mir jetzt einige unterstellen, ich möchte da lieber was in C mit dietlibc haben: Nein, will ich nicht. Ich will da am liebsten gar keinem zusätzlichen Code vertrauen müssen. Schon gar nicht Code anderer Leute. CAs können mir im Moment Zertifikate ausstellen, ohne dass ich irgendwelchem zusätzlichen Code vertrauen muss. Ich sehe keinerlei Grund, wieso sich das jetzt ändern sollte.
Einmal alle rumlaufen und alles updaten, bitte!
Ich bin ja generell kein Freund von Severity-Ratings, denn alles, was das tut, ist Leuten Ausreden an die Hand geben, wieso sie das Update verschieben können. In diesem Fall sind alle der Ratings Moderate oder kleiner, d.h. das sieht schon wieder so aus, als könne man sich das Update auch sparen, alles nicht so schlimm. Aber lest euch das mal durch. Das eine heißt, dass die NSA möglicherweise euren Private Key raten kann, wenn ihr DHE-Suites anbietet. Aber ist nur moderate, weil, äh, ach naja, wer hat schon so viel Ressourcen wie die NSA!1!! Ein anderer Bug ist ein Double Free, das würde bei Microsoft zum Beispiel sofort als Remote Code Execution und gelten und ein Critical kriegen. Also lasst euch nicht verarschen, updated alle euer openssl. Jetzt.
Na dann guckt mal hier. (Danke, Gerd)
Also erstmal: Ich glaube nicht, dass die NSA ein Problem damit hat, beliebig viel Geld auszugeben, wenn es aus ihrer Sicht nötig ist.
Zweitens: Die Leute nehmen noch nicht mal durchgehend PGP und SSL. Die Idee, dass die jetzt alle Onion Routing machen, weil das plötzlich performt, ist lächerlich.
Drittens: Tor SOLL langsam sein. Je mehr Jitter da drin ist, desto schwieriger ist die Korrelation anhand gesniffter Pakete. Eigentlich ist es schon völlig falsch, über Tor überhaupt Echtzeitdienste zu fahren. Man sollte da lieber mehrere Sekunden Verzögerung einbauen, künstlich, noch oben drauf.
Die Prämisse, dass Tor zu langsam ist, stimmt also schonmal nicht.
Aber ich habe mir das Paper noch nicht durchgelesen, nur Berichterstattung darüber, und könnte daher auch völlig falsch liegen.
Update: Die Schwächung gegenüber Tor ist bei näherer Betrachtung sehr gering, praktisch nicht der Rede wert. Auf der anderen Seite haben sie sich Gedanken gemacht, wie man Trafficanalyse erschweren und die Pfadlänge verbergen kann, und die Lösung ist: Padding aller Pakete auf Maximalgröße. Am Ende des Tages schluckt das viel mehr Bandbreite als Tor. Wie man unter solchem Umständen von High Performance reden kann, erschließt sich mir nicht wirklich. Im LAN vielleicht. Auf der anderen Seite wird mir gerade glaubwürdig versichert, dass bei Tor-Nodes tatsächlich das Lookup des States die CPU auf Anschlag hält. Hmm.
Es gibt zwei Arten von Parse-Routine, einmal "hier ist die Datei, mach mal" und einmal "hier ist ein char* und ein size_t, mach mal". Die Version mit der Datei ruft intern die andere Version auf.
Nun wollte ich, dass das User-Interface zwischen den SSL-Versionen in gatling nicht unnötig verschieden ist, daher nimmt mein PolarSSL-Code ein OpenSSL-Style server.pem (key und cert hintereinander gepasted in einer Textdatei), mappt das read-only in den Speicher und übergibt dann die jeweiligen Speicherregionen an die Parse-Funktion mit Zeiger und Länge.
Und die failed jetzt plötzlich. Stellt sich raus, dass der Code jetzt prüft, ob das letzte Zeichen im reingereichten Buffer ein 0-Byte ist.
Also mal abgesehen davon, dass dieser Check nicht dokumentiert ist, ist er auch völlig hirnrissig, denn dafür übergibt man ja gerade eine Länge, damit man da kein In-Band-Signalling für den Terminator braucht. Aber in meinem Fall mit dem read-only mmap kann ich auch gar kein Null-Byte da hin tun. Ich müsste also die Daten hin- und her kopieren.
Klarer Fall von "gut gemeint", würde ich sagen. Ich habe mal einen Bug gefiled. Da das mit dem 0-Byte auch nicht dokumentiert ist, kann man es ja auch gefahrlos wieder rauskanten. Ich hoffe, das tun die dann zeitnah.
Es handelt sich um ein Problem, mit dem man Zertifikatsvalidierung umgehen kann. Gefunden und gefixt wurde das Problem von BoringSSL, dem Google-Fork von OpenSSL.
Ich weiß, dass das auch in Gefängnissen so gemacht wird.
Ich befürchte, dass wir es hier mit einem Vorläufer der nächsten Kryptokriege zu tun haben. Das schrittweise die Bedeutung von Menschenrechten wie dem Briefgeheimnis immer weiter abgeschwächt werden, genau wie die NSA-Enthüllungen ja das Gefühl abgeschwächt haben, dass man sich im Internet ungestört unterhalten kann (das war übrigens noch nie gerechtfertigt, das Gefühl).
Verschlüsselung ist unsere letzte Verteidigungslinie. Wir haben uns schon von dei meisten anderen Prinzipien der Aufklärung verabschiedet.
Wir lassen unsere Nachbarn nicht in unser Internet, weil wir uns daran gewöhnt haben, dass Internet Geld kostet und das Haftungsfragen aufwirft. Ja warum eigentlich?
Wir haben uns von der Idee verabschiedet, dass man sich im Netz bewegen kann, ohne abgehört zu werden. Ja warum eigentlich?
Und jetzt versuchen sie, uns der Reihe nach abzugewöhnen, dass wir ein Recht auf Verschlüsselung haben. Erst in so Kontrollhochburgen und Randgebieten wie Gefängnissen und der Bundeswehr, dann werden sie der Reihe nach alle anderen Argumente durchprobieren. Terrorismus, organisierte Kriminalität, Kindesmissbrauch, Jugendschutz, und am Ende wird die Contentmafia in eure SSL-Verbindungen reingucken wollen, um zu prüfen, dass ihr keine Musik raubkopiert.
Ich möchte betonen, dass es keinen weiteren Rückzugsraum gibt. Wenn wir uns die Verschlüsselung wegnehmen lassen, dann können wir das Internet auch gleich wieder zumachen. Und ich rede hier von Ende-zu-Ende-Verschlüsselung, denn alles andere ist Schlangenöl. Das haben sie ja auch schon versucht, uns das als "das ist doch auch verschlüsselt dann, das reicht doch!1!!" zu verkaufen. Fallt auf sowas nicht rein.
Achtet da mal drauf. Ich sage voraus, dass das in nächster Zeit zunehmen wird, dass öffentlich "Probleme" thematisiert werden, die wir haben, weil jemand verschlüsselt hat. "Diesen Terroristen konnten wir nicht aufhalten, denn er hat seine Festplatte verschlüsselt". Das gab es schon mal zaghaft im Zusammenhang mit Skype, aber das fiel ja gleich wieder in sich zusammen, als wir darauf hinwiesen, dass Skype natürlich gesetzeskonform Abhörschnittstellen anbietet.
Update: Kommentar per Mail:
was Du unter http://blog.fefe.de/?ts=ab6b87e5 bei der Bundeswehr ansprichst, ist für Hamburger Schulen seit einiger Zeit normal.
Der feuchte Traum der bis zum Anschlag im Arsch der Contentmafia steckenden Schulbehörde ist es, jederzeit kontrollieren zu können, wer was im Internet macht (Lehrer, Schüler, etc.).
Die zu diesem Zweck ausgerollte "Lösung" nennt sich "Time for Kids" "Schulrouter Plus" und ist insgesamt ein "Internet minus", etwas derartig zusammengestricktes habe ich bisher noch nicht gesehen. Dass Sachkenntnis in diesem Bereich gerne von Stock-Fotos und bunten Flyern ersetzt wird, versteht sich von selbst…
Wobei ich ja sagen muss, dass ich das in Hamburg durchaus verstehen kann. Da ist man ja quasi direkt in der Nachbarschaft des LG Hamburg.
Update: Noch einer:
nicht nur die Bundeswehr macht das, sondern auch das Arbeitsamt. Für die habe ich mal ein Jahr lang Tech Support gemacht. Da sitzt dann ein Squid mit nem selbstgepopelten root certificate davor, was auf allen Rechnern verteilt ist. Zumindest im IE funktioniert das. Man hatte auch mal versucht, da Firefox einzuführen, aber der blockt, sobald er etwas nicht erkennt.
Update: Auch an Berliner Schulen, in mindestens einer öffentlichen Verwaltung und die Rentenversicherungen setzen sowas anscheinend ein. Wie gruselig! Schade, dass wir keine Parteien haben, die sich um Bürgerrechte kümmern, sonst würde man das gesetzlich verbieten. Fernmeldegeheimnis und so. Das kann ja wohl nicht sein, dass eine Organisation erfolgreich argumentieren kann, das Fernmeldegeheimnis sei nicht verletzt, weil da ja kein Mensch sondern nur eine Software mitliest. Das wäre ja wie wenn man behauptet, Videoüberwachung sei nicht schlimm, weil das eine Kamera und kein Mensch ist.
Tja.
Soll ich euch mal verraten, warum das so lange gedauert hat? Wegen der Werbeindustrie. Auf SSL-Seiten kann man keine Werbung von Nicht-SSL-Seiten einblenden, und die Werbeindustrie weigert sich schlicht, weil das Geld kostet.
Gut, die ganzen internen Links sind im Moment noch zur unverschlüsselten Version. Kinderkrankheiten. Dennoch, das ist ein großer und wichtiger Schritt. Da können sich unsere Medienseiten mal eine Scheibe abschneiden!
Mich stört im Moment, dass der non-blocking Mode dir zwar sagt, er ist noch nicht fertig, aber er sagt dir nicht, ob er jetzt schreiben oder lesen wollte und das geblockt hätte. Das ist für ein Event-basiertes Framework wie in gatling aber notwendig. Mal schauen, ob da nur die Doku scheiße ist, oder auch der Code :)
Einmal mit Profis arbeiten!
Ich habe ja mein SSH schon vor einer Weile auf djb-Krypto umgestellt (hier hatte ich das beschrieben). Es ist leider auffallend schwierig, mit regulären Browsern djb-Krypto im TLS hinzukriegen. Firefox supported das noch nicht (warum eigentlich nicht?), Chrome supported es angeblich, aber ich kriege das nicht negotiated. OpenSSL kann es nicht (es gibt einen alten Patch, der aber nicht auf aktuelle Versionen passt), PolarSSL kann es nicht, BoringSSL kann es zwar, aber die Knalltüten haben das Buildsystem auf cmake umgestellt, und da krieg ich die dietlibc nicht reingepfriemelt. Das muss mir auch noch mal jemand erklären, wieso heutzutage jedes gammelige Hipsterprojekt sein eigenes Buildsystem braucht. Bei autoconf ist wenigstens dokumentiert, wie man da von außen eingreifen kann. Aber dieses cmake ist in der Beziehung nur für den Arsch, ich komm aus dem Fluchen gar nicht raus.
Und so bleibt mir im Moment nur LibreSSL, das kommt in der portablen Version mit autoconf und funktioniert mit dietlibc, und da taucht das auch in der Cipherliste auf, und wenn ich mit openssl s_client die Verbindung aufmache, kriege ich auch ECDHE-ECDSA-CHACHA20-POLY1305, aber mit Chrome? Kein Glück.
Und, mal unter uns, solange man da nicht von Hand noch eine ordentliche Kurve konfiguriert, ist das auch Mist. Von den Kurven, die OpenSSL unterstützt, scheint nur secp256k1 akzeptabel.
Das Problem ist, dass Diffie Hellman praktisch die Basis von allen Online-Public-Key-Kryptographiesystemen da draußen ist — SSH, TLS, IPsec, … Schlimmer noch: Wir haben das bei TLS massiv forciert, weil Diffie Hellman erst für Perfect Forward Secrecy sorgt. Das ist die Eigenschaft eines Protokolls, dass wenn die Cops kommen und den Server mit dem Schlüssel drauf beschlagnahmen, sie damit trotzdem nicht vorherige verschlüsselte Verbindungen entschlüsseln können.
Was ist jetzt genau das Problem?
Erstens gibt es eine Downgrade Attack. Downgrade Attack heißt, dass jemand von außen die Pakete im Netz manipuliert. Nehmen wir an, ich verbinde mich zu https://blog.fefe.de/, und die NSA sieht die Pakete und manipuliert sie. Eine Downgrade Attack heißt jetzt, dass die NSA (vereinfacht gesagt) in meinen Handshake-Paketen die ganzen harten Verfahren aus der Liste der unterstützten Kryptoverfahren rausnimmt. Der Server nimmt sich das härteste vorhandene Verfahren, aber wenn die NSA die Liste manipulieren kann, dann ist das halt nicht sehr hart. TLS hat dagegen bezüglich der Cipherliste Vorkehrungen getroffen, aber jetzt kommt raus, dass die NSA von außen die Diffie-Hellman-Bitzahl auf 512-Bit runterschrauben kann. Das ist eine Katastrophe. Die einzige Lösung hierfür wäre, wenn die Server schlicht keine schwachen Diffie-Hellman-Schlüssel mehr zulassen würden. Dann käme keine abhörbare Verbindung zustande. Die NSA kann dann zwar immer noch verhindern, dass ich eine Verbindung aufnehme, aber das kann sie eh, unabhängig von Krypto.
Das zweite Problem ist noch gruseliger. Und zwar galten die Diffie-Hellman-Parameter immer als öffentlich. Das ist sowas wie ein Zahlenraum, auf den man sich einigt, in dem man dann seine Krypto-Operationen macht. Das hat dazu geführt, dass viele Server am Ende des Tages die selben Parameter verwenden. Jetzt stellt sich aber raus, dass der erste Schritt im Algorithmus zum Brechen von Diffie Hellman nur auf diesen Parametern basiert, nur auf einer Primzahl. Und wenn da alle die selbe verwenden, dann muss ein Angreifer diesen ersten Teil auch nur einmal machen. Das ist eine ganz doll gruselige Erkenntnis!
Was kann man denn jetzt tun? Zwei Dinge. Erstens müssen wir jetzt dafür sorgen, dass unsere Server "Export-Verschlüsselung" (also absichtlich geschwächte Krypto) auch bei Diffie Hellman nicht mehr akzeptieren. Ich glaube im Moment, dass man dafür die SSL-Libraries patchen muss, weil es kein API gibt. Aber ich kann mich da auch irren, vielleicht gibt es ein API. In dem Fall müsste man die ganzen Server patchen, damit sie das API benutzen.
Und der zweite Schritt ist, dass man dem Server schlicht Diffie-Hellman-Parameter vorgibt. Die erzeugt man unter Unix mit
$ openssl dhparam -out dhparams.pem 2048Man kann auch noch größere Parameter machen, aber das sollte man dann über die Mittagspause laufen lassen, das dauert ewig und drei Tage. Und dann muss man der Serversoftware sagen, dass sie diese DH-Parameter verwenden soll. Lest die Dokumentation. Das ist wichtig!
Klingt alles schon apokalyptisch genug? Wartet, kommt noch krasser!
Breaking the single, most common 1024-bit prime used by web servers would allow passive eavesdropping on connections to 18% of the Top 1 Million HTTPS domains. A second prime would allow passive decryption of connections to 66% of VPN servers and 26% of SSH servers. A close reading of published NSA leaks shows that the agency's attacks on VPNs are consistent with having achieved such a break.Update: Ich hatte vor nem Jahr mal bei https://blog.fefe.de/ 2048-Bit-Diffie-Hellman-Parameter generiert und das hat mir jetzt wohl den Arsch gerettet an der Stelle. Ein bisschen Paranoia schadet halt nicht :-)
Update: Wer in Firefox die rote Box auf der Logjam-Seite weghaben will, muss in about:config die dhe (nicht die ecdhe!)-Ciphersuiten wegkonfigurieren.
Update: Und natürlich will man auch die ganzen RC4-Ciphersuites wegkonfigurieren, das hatte ich in dem Screenshot jetzt nicht drin, weil ich nur die Einstellungen fett haben wollte, die für Logjam relevant sind.
Sehr geehrter Herr von Leitner,(Ein faszinierender Gastbeitrag von Prof. Dr. rer. nat. Dipl.-Math. Rüdiger Weis)vielen Dank fuer Ihre freundliche Anfrage. Ich überlege in der Tat, Ihr Angebot annehmen, zum Anlass des 10 jährigen Jubiläums für Ihren in der Bloggerszene ja recht bekannten Onlinedienst einen Kurzbeitrag zu schreiben.
Dies umsomehr, da ich es als wichtig halte, dass bei allem Respekt für Ihre Beiträge im Bereich der praktischen Analyse von Angriffsmöglichkeiten auf sogenannte Internetanwendungen, auch wissenschaftlich etwas anspruchsvollere Fragestellungen in Ihrem (bisweilen etwas multimedialastigen (s.a. /logo-gross.jpg)) Blog, einmal eine angemessene Würdigung finden sollten.
Hören Sie in Ihrem Blog vielleicht ein bisschen weniger auf diese Hackeszene, die Sie für Ihre Arbeiten im Bereich von in C geschriebenen Betriebssystemen nicht zu Unrecht hochschätzt. Sie vergeuden Ihr Talent ein wenig für eine Sprache, die selbst von Ihren Entwicklern inzwischen auch offen als einer der nicht immer gelungenen Hackerscherze (wie TCP/IP, THC, HTTP, SSL, SSH, OTR, gpg, git, GPL, ACID, WWW usw) aufgedeckt wurde. Da hilft es auch nicht viel, lustige Sonderzeichen wie ++ und # anzuhängen. Ich schreibe Ihnen gerade auf einem Emacs-LISP Betriebssystem, welches trotz des oftmals zurecht kritisierten Editierprogrammes bisher recht selten aus diesem Internet attackiert wurde.
Nicht zu Unrecht fragen sich sicherlich zahlreiche Ihrer Leserinnen und Leser, insbesondere angesichts Ihrer in Ihren Blogbeiträgen oftmals durchschimmernden positiven Haltung zu Elliptischen-Kurven-Kryptosystemen, beispielsweise, wieso das Diskreter-Logarithmus-Problem auf der durch Punktaddition gebildeten zyklischen Gruppe eines Generatorpunktes auf einer elliptischen Kurve über einem endlichen Körper, wegen der bisher nicht gelungene Anpassungen der subexponetiellen Index-Calculus Angriffsmethode auf derartige Gruppen, wirklich nur generisch, beispielsweise durch superpolynominale Pollard-Rho-artige Methoden, angreifbar ist, welche ich in meinem Vortrag auf dem 31C3 vielleicht etwas zuspitzend, wenn auch sicherlich nicht ganz ungerechtfertigt, als Geburtstagsparadoxonfolklore bezeichnet habe, und Sie bisweilen selbst für aufmerksame Leserinnen und Leser, insbesondere wegen ihre Länge, schwer lesbare Sätze bilden, in denen Sie bisweilen sogar ein Komma vergessen oder falsch setzen.
(Anm.d.Red.: Es ist dieser Absatz, den ich als "von Krypto hat der ja keine Ahnung" interpretiert habe)
Lassen Sie mich diesen Gedanken aufgreifen und vielleicht etwas polemisch kurz schliessen:
"Was das Geburtstagsparadox für ECC ist, ist Fefe für in C geschriebene Software."
Mit freundlichen Grüßen
Update: Boah ich Depp hab in der Eile das PS nicht mit kopiert, dabei war das doch das Highlight der ganzen Einsendung! Hier ist es:
PS
Ihr SSL Zertifikat wird nicht mal von CNNIC anerkannt.
Wie jetzt, DAS war das dringenste Problem in deren Augen?!? OMFG
U.S. government regulations prohibit double encryption. Accordingly, if you configure Oracle Advanced Security to use SSL encryption and another encryption method concurrently, then the connection fails. You also cannot configure SSL authentication concurrently with non-SSL authentication.Wait, what?! Hoffentlich erzählt das keiner den De-Mail-Leuten, sonst versuchen die hier sowas auch. (Danke, Alexander)
In particular, a network attacker can send the certificate of any arbitrary website, and skip the rest of the protocol messages. A vulnerable JSSE client is then willing to accept the certificate and start exchanging unencrypted application data. In other words, the JSSE implementation of TLS has been providing virtually no security guarantee (no authentication, no integrity, no confidentiality) for the past several years.Die Experten von Sun mal wieder! Wie war das noch? Java setzt man wegen der Sicherheit ein? Oh nein, warte, wegen der Performance!1!!Auch auf der Webseite: FREAK. Da geht es darum, dass offenbar diverse Webserver noch einen Export-Modus implementieren, aus Krypto-Uhrzeiten. Das ist ein Krypto-Downgrade, das man anscheinend auch triggern kann, dass die benutzt werden. Und dann wird ein so schwacher Schlüssel verwendet, dass man den für $50 knacken kann. Und das betraf anscheinend auch mal wieder OpenSSL.
Update: Achtet auch auf den Screenshot, wo sie den Angriff gegen NSA.gov fahren.
It's encouraging to see the GnuPG project benefitting from similar largess. But it also raises the question: how is the money best spent? Matt Green, a professor specializing in cryptography at Johns Hopkins University, said he has looked at the GnuPG source code and found it in such rough shape that he regularly assigns chunks of it to his students for review."At the end I ask how they felt about it and they all basically say: 'God, please I never want to do something like this again,'" Green told Ars.
Soweit würde ich jetzt nicht gehen. Immerhin benutzt Werner Koch seit Jahren size_t für Längen und Offsets. Ich habe schon viel schlimmeren Code gelesen. Ich glaube ja, die Jugend von heute ist verweichlicht. Was sollen die denn erst sagen, wenn sie mal OpenSSL erben und warten sollen eines Tages?Übrigens, einen noch:
Given the ramshackle state of massive GnuPG code base, it's not clear what's the best path forward. A code audit is one possibility, but such reviews typically cost a minimum of $100,000 for complex crypto programs, and it's not unheard of for the price to be double that.Stimmt. Oder man hat halt Glück und der Fefe macht das kostenlos in seiner Freizeit. Und dann schmeißt Werner Koch Das liegt daran, dass Werner Koch das Problem ist, nicht die Lösung. Werner Koch macht mit dem Code keine Wartung, eher eine Geiselnahme. Denn wer will schon gnupg forken. Wir kriegen ja schon ohne Fork die Leute nicht in signifikanter Größenordnung dazu, das zu benutzen. Das wäre noch übler, wenn es da auch noch Marktfragmentierung gäbe. Deshalb hat noch niemand gnupg geforkt. Nötig gewesen wäre es seit Jahren. Ich persönlich hoffe seit Jahren, dass Werner endlich hinwirft, und dann jemand die Wartung übernehmen kann, der auch ein Interesse daran hat, daraus ein ordentliches Projekt zu machen. Aber das wird ja jetzt nicht mehr stattfinden. Jetzt wo nicht mehr nur sein Ego sondern auch sein Lebensunterhalt direkt davon abhängt, dass er weiterhin Diktator von gnupg bleibt.
Übrigens hat Werner seine BSI-Kohle über die Jahre nicht gekriegt, weil er dafür gearbeitet hätte, sondern weil Leute mit Beziehungen beim BSI Klinken geputzt haben. Diese Leute haben zwar gesehen, dass Werner Koch das Problem ist, aber sie haben sich gedacht, wenn man dem Geld gibt, vielleicht wird das dann besser. Wurde es leider nicht. Ein bisschen Mitleid war glaube ich auch dabei. Und ein bisschen "das ist das eine erwähnenswerte Kryptoprojekt aus Deutschland, das sollte gefördert werden, um ein Signal zu setzen".
Weil mir schon die ersten Twitter-Experten Neid vorwerfen: Ich habe den Aufwand für den Patch geleistet, weil ich vorher eine Finanzierung für meine Zeit klargemacht hatte. Ich brauche keine Spenden, schon gar nicht von Facebook. Das werde ich zu vermeiden wissen, dass Facebook sich mit einer Spende für eines meiner Projekte, die ich dann aus einer Notlage heraus annehmen muss, gutes Karma kauft. Das Geld, das ich bei Kunden für ehrliche Arbeit nehme, ist Bezahlung, keine Spende. Damit finanziere ich zwar meine Open Source Arbeit, aber keiner meiner Kunden kann damit Werbung machen, über mich Open Source finanziert zu haben. Außer der Kunde hat mich explizit für die Entwicklung von Open-Source-Software bezahlt, versteht sich. Das hat es auch mal gegeben.
Ich finde übrigens nach wie vor, am besten wäre es, wenn wir einfach ein bedingungsloses Grundeinkommen hätten. Dann hätten wir das Finanzierungsproblem für Kunst und Open-Source-Softwareentwicklung gelöst und niemand müsste so entwürdigende Winselnummern bringen. Wir hätten aber immer noch das Code-Geiselnahme-Problem. Dafür kenne ich auch keine gute Lösung.
Update: Ich sollte der Sicherheit halber dazu sagen, dass das nicht bloß meine Eintschätzung ist, dass Werner Koch das Problem ist, sondern ziemlich breiter Konsens. Ich habe diverse Mails von anderen Leuten gekriegt, die mit Werner vergeblich zu kooperieren versucht haben. Ich werde die hier aber nicht zitieren. Das sind die Geschichten der jeweiligen Leute, nicht meine. Sollen die sie erzählen. Mir persönlich war das 8 Jahre lang egal. Ich hatte meinen Patch. Mein persönlicher Moment, ab dem ich der Meinung war, dass da jetzt mal was geschehen muss, war als ich auf dem 31C3 Citizen Four sah.
Sorry, aber so läuft das nicht. Richard Stallman hat auch sein Leben der guten Sache gewidmet. Linus Torvalds auch. Was ist mit den OpenBSD-Leuten? Den OpenSSL-Leuten?
Wer sein Produkt kostenlos verteilt, der kann nicht nachher herumheulen, dass sich nicht aus magischen Quellen Geld auf seinem Tisch manifestiert hat. Das muss man vorher durchfinanziert haben, dass man die Entwicklung durchführen kann. Sonst sucht man sich einen Mäzen oder einen Sponsor oder macht Crowdfunding, vielleicht ein Regierungsprojekt. Man kann gucken, ob man eine Gemeinnützigkeit anerkannt kriegt. Ist das mit Aufwand verbunden? Klar! Wer das nicht macht, hat mein Mitleid nicht verdient, sorry.
Ich schreibe auch seit 20 Jahren freie Software. Sieht mich jemand herumheulen, dass ich mir kein Abendbrot leisten kann? Nein. So läuft das nicht.
Werner Koch ist im Übrigen in der ausgesprochen privilegierten Position, dass er sogar mehrfach von der Bundesregierung Förderkohle eingesackt hat. Und dann hat er auch noch ein erfolgreiches Crowdfunding durchgezogen. Was sollen denn bitte die ganzen anderen Leute sagen?! Die, denen die Regierung keine Kohle nachwirft? Die, deren Crowdfunding in der Obskurität verlischt?
Sorry, Werner. Du schläfst in dem Bett, das du dir gebettet hast. Wenn du da jahrzehntelang dein Lebens-Management verkackst, dann stelle dich bitte nicht am Ende hin und winsel herum, dass dir die Welt ein bedingungsloses Grundeinkommen schuldet. Sowas kriegt man nicht durch geduldig Warten.
Ich persönlich bin ein Freund des bedingungslosen Grundeinkommens, unter anderem gerade damit auch Leute wie Werner Koch Software wie gnupg schreiben können, ohne sich Sorgen um ihre Abendbrot machen zu müssen. Aber soweit sind wir noch nicht. Die Realität geht nicht weg, wenn wir sie lange genug leugnen.
Im Übrigen, aber das ist nicht mein Hauptpunkt hier, finde ich die Wartung von gnupg auch keinen Vollzeitjob. Sorry, nein, ist es nicht. Seit wann macht er das jetzt? 20 Jahre? Gelegentlich kommt mal ein Feature dazu, das will ich nicht leugnen. Features, die 90% der gnupg-Benutzer nicht betrifft, sowas wie Smartcards. Aktuell wohl auch elliptische Kurven, das betrifft schon eher jemanden. Aber elliptische Kurven haben die finanziell noch schlechter aufgestellten OpenSSL-Leute ganz ohne murren mal eben nachgerüstet.
Liebe Geeks. Wir haben hier ein strukturelles Problem. Freie Software finanziert sich nicht von selbst. Auf göttliche Intervention warten ist keine Lösung. Sucht euch einen Job, der euch Spaß macht. Am besten nichts, was mit Softwareentwicklung zu tun hat. Sonst habt ihr nämlich abends nach der Arbeit auch keinen Bock mehr auf Softwareentwicklung.
Und dann entwickelt ihr in eurer Freizeit freie Software. Und dann geht ihr in eurem Bett schlafen, unter dem Dach, das ihr euch mit dem anderen Job finanziert habt. So wird ein Schuh draus.
Noch was: Geschenken wirft man keinen Guilt Trip hinterher. Entweder es ist ein Geschenk, dann erwartet man nichts dafür, oder es ist kein Geschenk. Freie Software ist ein Geschenk. Klar darf man sich über Spenden freuen. Aber meckern, wenn sie ausbleiben, darf man nicht.
Update: Oh und einen Punkt möchte ich noch machen. Es wird häufig geheult, dass so viel Open Source Software angeblich in so einem schlechten Zustand ist, angeblich weil die Leute das nicht als Vollzeitjob machen. Das stimmt so nicht. Ich zum Beispiel schreibe Software nicht als Selbstzweck, sondern weil ich was lernen will. Aspekte, bei denen ich nichts lerne, oder die mich nicht interessieren, mache ich dann auch nicht. Die Ausgabe von Fließkommazahlen im printf der dietlibc ist seit Tag 1 kaputt. Dass das nicht gefixt wird, liegt nicht daran, dass ich nen Job habe, der mich ablenkt. Sondern das liegt daran, dass mir andere Sachen wichtiger sind. Das ist eine Frage der Prioritäten, nicht der Ressourcen. Jeder von uns hat genug Freizeit um alles zu schaffen, was er wirklich schaffen will.
Update: Oder aber natürlich man macht das zum Beruf. Gründet eine Firma, die Open Source macht. In einigen Fällen hat das sogar funktioniert. Wenn das gelingt, ist es natürlich der heilige Gral. Aber ich habe zwei Befürchtungen. Erstens ist es nicht mehr das Gleiche, wenn man dafür bezahlt wird. Es macht irgendwann weniger Spaß, wenn es ein Beruf ist und nicht etwas, das man aus freien Stücken tut. Zweitens muss man ja trotzdem irgendwoher Einnahmen generieren. Support für das Produkt ist hier eine populäre Option, aber das kann man nur bringen, wenn das Open-Source-Produkt soweit fertig und stabil ist und eine wichtige Sache löst und breit eingesetzt wird. Das ist eine verschwindende Minderheit der Projekte. Und dann ist die Arbeit, die man tut, auch eher Wartung als Entwicklung. Die Frage also, wie man die Entwicklung von freier Software finanziert kriegt, ist damit weiterhin nicht geklärt.
Als letzte Option bezahlen auch manche große Firmen wie IBM oder Oracle oder Linux-Distributoren ein paar Leute für ihre Arbeit an Open Source-Projekten. Das halte ich für nicht realistisch genug, um das generell als Lebensmodell zu empfehlen. Ein paar Leute können sich das so drehen. Der Rest — fast alle! — nicht.
Update: Es haben sich $50k/Jahr-Sponsoren gefunden. Und genau die Art von Leuten, von denen man Geld annehmen möchte!1!! Na seht ihr, ist doch noch alles gut ausgegangen. Wenn ihr Werner Koch wäret, wäret ihr jetzt zufrieden?
Update: Oh und die Linux Foundation wirft auch nochmal $60k hinterher.
Update: Ich mache mir Sorgen, dass jetzt lauter Kids glauben, das könnte für sie auch funktionieren. Leute, niemand von euch hat den Hauch einer Chance, das als Finanzierungsmodell für das Leben zu replizieren. Das ist wie auf einen Lottogewinn zu hoffen. Holt euch lieber einen richtigen Job und entwickelt nebenher freie Software. Das ist das realistische Modell. Ich finde nach wie vor, dass man Leute, die sich wie Werner ohne Fallschirm aus dem Flugzeug stürzen, nicht auffangen sollte. Sonst validiert man damit das Modell, dass man so seinen Lebensunterhalt verdienen kann. Und dann machen lauter Andere das nach.
ECDHE silently downgrades to ECDH [Client] (CVE-2014-3572)Wait, what?
========================================================== Severity: Low
RSA silently downgrades to EXPORT_RSA [Client] (CVE-2015-0204) ============================================================== Severity: LowSurely some mistake?
DH client certificates accepted without verification [Server] (CVE-2015-0205) ============================================================================= Severity: LowUnd zu guter letzt kann auch noch der Fingerprint modifiziert werden und ihre Quadrier-Routine verrechnet sich gelegentlich. Ihr seht schon: Alles totale Randgruppenprobleme, kein Grund zur Beunruhigung.
Update: Falls jemandem die Signifikanz nicht klar war: Der Unterschied zwischen ECDHE und ECDH ist Perfect Forward Secrecy. Das heißt, dass wenn die Polizei den Serverschlüssel beschlagnahmt, sie trotzdem nicht damit die alten NSA-Mitschnitte entschlüsseln kann. TLS ohne Perfect Forward Secrecy auszurollen kann man sich meiner Meinung nach auch gleich sparen.
Highlights, die sich anzugucken lohnen, sind (völlig subjektiv, versteht sich):
Mit der Fnord-Show war ich dieses Jahr selber nicht so zufrieden. Wir hatten zu viele Folien. Das wussten wir auch vorher, aber wir hatten schon einen gehoben zweistelligen Prozentsatz an potentiellen Folien vorher weggeschmissen. Das werden wir nächstes Jahr anders machen. Dem Publikum hat es anscheinend trotzdem ganz gut gefallen, insofern will ich da jetzt mal nicht zu schlecht gelaunt sein. Aber zufrieden war ich nicht. Bin ich aber so gut wie nie nach meinen Vorträgen, wäre ja auch langweilig.
Den heutigen dritten Tag nutze ich hauptsächlich für Socializen und vielleicht das eine oder andere Interview. Für Erich Möchls Vortrag heute morgen konnte ich mich leider nicht rechtzeitig aus dem Bett quälen. Das will man sicher auf Video gesehen haben, er sprach über NSA-Niederlassungen in Österreich.
Meiner Einschätzung nach sollte man heute um 17:15 den DP5-Vortrag nicht verpassen, aber der leider parallel liegende Vortrag "What Ever Happened to Nuclear Weapons" ist mindestens genau so wichtig. Ich schau mal, wo ich einen guten Sitzplatz finde, und den anderen gucke ich dann auf Video. Um 18:30 würde ich den Thunderstrike-Vortrag gucken.
Um 21:15 gibt es in Saal 2 einen Vortrag über Nordkorea, der wird bestimmt voll :-)
Um 22:00 verspricht der Perl-Vortrag hochkarätig zu werden.
Heute morgen bin ich direkt von einem FAZ-Reporter zu Regin befragt worden, und habe das ein bisschen auf eine generelle Malware-Schiene umzubiegen versucht. Mal gucken, wie das wird. Danach wurde ich direkt von Tilo Jung abgefangen, der hier auf dem Congress herumrennt und Interviews führt. Wir haben uns vorher ein bisschen darüber unterhalten, was wir für ein gutes Interview halten, und ob der Interviewer da Positionen bekleiden sollte oder nur den Interviewpartner reden lassen sollte. Ich finde ja letzteres. Das optimale Interview ist eines, bei dem der Interviewer dem Interviewgast ein paar Stichworte hinlegt und ihm dann nicht dabei im Wege steht, wenn er sich um Kopf und Kragen redet. Tilo war kürzlich in Israel und Paälstina und hat dort mit allen Seiten Interviews geführt, und erzählte, dass er dann erst dafür kritisiert wurde, er würde ja nur die eine Seite zu Wort kommen lassen, und als er dann mit den anderen redete, wurde er dafür kritisiert, denen nicht ins Wort gefallen zu sein, als die da krude Parolen äußerten und sich zum Klops machten. Dieses Muster (jetzt nicht mit Israel und Palästina) habe ich schon häufiger beobachten können und finde es ausgesprochen deprimierend. Ich hatte da vor ein paar Wochen schonmal was zu gebloggt, und so fragte mich dann Tilo auch zu Ken Jebsen. Ich hoffe, ich habe mich da jetzt nicht zu sehr um Kopf und Kragen geredet *hust*. Soviel ist jedenfalls klar: Je weniger Struktur der Interviewer vorgibt, desto mehr Gelegenheiten zum Verplappern hat der Interviewpartner. Vorsicht bei Interviews mit Tilo! :-)
Wer die Kaspersky-Funktion "Sichere Verbindungen untersuchen" aktiviert, macht sein System potenziell für den Poodle-Angriff auf SSLv3 anfällig.
Oh, und, *umblätter*: Der BND möchte gerne eure SSL-Verbindungen mit 0days mitlesen.
Arsch -> Eimer!
Unfortunately, because of the large number of sites which incorrectly handled TLS v1.2 negotiation, we had to disable TLS v1.2 on the client.Dass diese Debilianisten und ihre Abkömmlinge das aber auch nicht lernen, die Finger von OpenSSL-Patches zu lassen!
Secure Connection Failed.An error occurred during a connection to blog.fefe.de. SSL received a record that exceeded the maximum permissible length. (Error code: ssl_error_rx_record_too_long)
Mein Blog hat ja schon seit einer Weile SSLv3 deaktiviert, aber jetzt hatte ich auch openssl ohne SSLv3-Support gebaut. Vielleicht ist es das. Mann ist das immer eine Freude mit diesen ganzen Hochtechnologien!Update: Ich habe die Gelegenheit genutzt, mal den PolarSSL-Support in gatling zu updaten. Mal gucken, ob das jetzt stabil läuft hier.
We show here how to put together an effective attack against CBC encryption as used by SSL 3.0, again assuming that the attacker can modify network transmissions between the client and the server. Unlike with the BEAST [BEAST] and Lucky 13 [Lucky13] attacks, there is no reasonable workaround. This leaves us with no secure SSL 3.0 cipher suites at all: to achieve secure encryption, SSL 3.0 must be avoided entirely.Ein OpenSSL-Update gibt es noch nicht, und die OpenSSL-Webseite in der SSL-Version ist für mich auch gerade nicht erreichbar. LibreSSL hat gerade erst 2.1 released, ob die schon sicher ist weiß ich nicht.Wer sich jetzt Sorgen macht, SSL 3 abzuschalten: das SSL bei meinem Blog erlaubt seit April kein SSL 3 mehr. Es gab Null Beschwerden deshalb.
Update: Und um die Apokalypse perfekt zu machen, gab es auch in der von Chrome und Firefox verwendeten SSL-Library einen RSA-Signatur-Bypass. Ja super! Sonst noch was?
Update: Ah, Busybox ist doch nicht betroffen, höre ich gerade, sondern nur Geräte mit Cyanogenmod, die bash statt der Shell von Busybox nehmen.
Update: Es gibt schon die erste Malware damit.
Update: Mein Freund Andreas hat mal einen Patch gemacht, der das ganze kaputte Feature wegoperiert. Wer will schon Shell-Funktionen im Environment haben!? Das ist relativ zu bash-4.3.24 (nicht .25).
The certificate is not trusted because it was signed using a signature algorithm that was disabled because that algorithm is not secure.(Error code: sec_error_cert_signature_algorithm_disabled)
Das bezieht sich vermutlich auf das MD5, das cacert verwendet, um ihren Root-Key damit zu hashen. Es gibt auch nichts, was ich dagegen tun könnte, das ist ein Problem von cacert.Ich finde es gelinde gesagt überraschend, dass Firefox, die seit gefühlt vorgestern überhaupt erst TLS 1.2 sprechen, jetzt solche Dinger bringen. Aber inhaltlich haben sie Recht. Zertifikate, bei denen in der Kette irgendwo MD5 auftaucht, darf man nicht mehr akzeptieren. Eigentlich schon länger nicht mehr.
Die gute Nachricht ist: Das Problem ist lösbar. Mozilla hat das vor ein paar Jahren angesagt, und cacert hat eine neue Signatur unter ihrem Root-Zertifikat gemacht. Ob ihr betroffen seid, hängt also davon ab, wann ihr die Zertifikate bei euch lokal eingepflegt habt. Und ihr könnt das Problem jetzt lösen, indem ihr die cacert-Zertifikate rausschmeißt und neu installiert.
Update: Hmm, nee, so einfach ist das nicht. Einige cacert-Sites sind mit dem einen Key signiert, der sich so reparieren lässt, einige (zu denen auch blog.fefe.de gehört) sind mit dem anderen Key signiert und gehen auch nach Neueinspielen der Zertifikate noch nicht. Ich guck mal, ob ich da was tun kann.
Update: Ich habe den Unterschied zwischen meinem Blog und der anderen Site, bei der es nach Zertifikatsupdate geht, identifiziert. Mein Blog ist mit dem Class1-Key signiert, die andere Site mit dem Class3-Key. Den kann man auch separat in den Trust Store einpflegen, dann spielt es keine Rolle mehr, ob das Class1-Root-Zertifikat den Class3-Key nur mit MD5 signiert hat. Allerdings scheint das ein politisches Problem zu sein, kein technisches, denn man kann das nicht auswählen, ob man Class1 oder Class3 haben will. Für Class3 muss man "Assured Member" sein. Bin ich nicht. Will ich auch nicht werden. Damit ist cacert dann wohl zukünftig ungeeignet.
Money Quote:
"Apple is deeply committed to protecting the privacy of all our customers," the company said in response. "Privacy is built into our products and services from the earliest stages of design. We work tirelessly to deliver the most secure hardware and software in the world."So agil muss eine Firma erstmal sein, dass sie das "earliest stages of design" betitelt, wenn sie im Jahre 2014 STARTTLS einbauen.Oder hey, vielleicht war das ja schon eingebaut und sie haben es nur noch nicht angeschaltet? Gucken wir doch mal, was sie da für einen SMTP-Server benutzen…
220 st11p00mm-smtpin005.mac.com — Server ESMTP (Oracle Communications Messaging Server 7u4-27.08(7.0.4.27.7) 64bit (built Aug 22 2013))Oh… Oracle. Nun, äh, … ich habe da so eine Theorie, wieso sie bis heute gewartet haben, SSL auszurollen. *hust*
I do not have enough energy in my life to clean up two poorly written crypto code bases.Immerhin signieren sie jetzt überhaupt, und zwar mit … signify. Nie gehört? Ich auch nicht. Das scheint was ad-hoc schnell selbst gehacktes zu sein. Hier ist das Argument dafür:$ wc -l *.cNun werdet ihr vielleicht sagen: hey, klingt gut, will ich haben. Wo ist der tarball?
29 crypto_api.c
143 mod_ed25519.c
327 mod_ge25519.c
806 signify.c
1305 totalSignify is 1305 *lines* of C code. and it's included in our development
platform. It is not that difficult to install, and
if you can't install it, you could always run OpenBSD in a vm to verify a
signature, it comes with openbsd.
Die Antwort: Es gibt keinen. Ich habe mir mal im Schweiße meines Angesichts die nötigen Teile aus dem OpenBSD-CVS herausgepopelt und in einen unter Linux bauenden Tarball getan. Mit dem ganzen Glue-Code sieht die Statistik schon mal gleich ganz anders aus, da sind wir dann plötzlich bei knapp 8000 Codezeilen (plus libc, natürlich).
Das baut bei mir, und ich kann damit die LibreSSL-Distribution verifizieren. Immerhin. Das ist aber natürlich immer noch voll für den Fuß, weil der public key von deren Signatur auf dem selben FTP-Server liegt wie die Daten. Wenn jemand den Tarball manipulieren kann, kann er also auch einen anderen pubkey daneben legen und keiner merkt was. Bei GnuPG gibt es ja wenigstens das Web of Trust.
Das ist der Todesstoß. Funding für OpenSSL zurückziehen, Foundation zumachen, Laden dichtmachen. Das geht ja mal gar nicht. Was für eine Frechheit. Die sollten sich schämen.
Update: Ganz so einfach ist das auch wieder nicht. Wie sich rausstellt, hat Theo sich für OpenBSD explizit geweigert, auf so eine Mailingliste aufgenommen zu werden. Ich weite das "Die sollten sich schämen" damit auf OpenBSD aus.
Update: Kurze Stellungnahme meinerseits, "wie schlimm" das ist. Das MITM-Zeug betrifft mich im Allgemeinen nicht, weil auf der anderen Seite üblicherweise nicht OpenSSL sitzt (Ausnahmen sind irgendwelche RSS-Reader), das ist aber ein ziemlicher Klopper. Ausgesprochen peinlich, und offenbar seit Tag 1 dabei. Das DTLS-Zeug betrifft so gut wie niemanden, weil niemand diesen DTLS-Bullshit einsetzt. Ausnahmen wären irgendwelche WAP-Geschichten oder Mobil-Spezial-Fummeleigeschichten. Ich würde auch weiterhin empfehlen, DTLS weiträumig aus dem Weg zu gehen. SSL_MODE_RELEASE_BUFFERS hätte man extra reinkompilieren müssen. Ich habe das nicht getan, ob Debian oder so das getan haben — keine Ahnung. Anonymous ECDH betrifft hoffentlich auch niemandem. Anonymous Cipher Suites sind ein Hirnkrebs, den sich die TLS-Leute ausgedacht haben, bei denen weder Client noch Server ein Zertifikat vorzeigen muss. Das hat hoffentlich überhaupt niemand jemals irgendwo angeschaltet.
Unter dem Strich also: natürlich trotzdem sofort updaten. Aber auf der Skala von 1 bis Heartbleed war das näher bei 1 als bei Heartbleed.
Update: Es sieht so aus, als sei auch der kaputte DTLS-Code wieder vom Heartbleed-Autoren gekommen. Ob der deshalb gefunden wurde?
Update: Die Greenwald-Unterlagen sind ein ziemlicher Totalschaden für Microsoft, so ab Page 113 wird es richtig übel. Money Quote (Page 115):
MS, working with the FBI, developed a surveillance capability to deal with the new SSL.
Update: Da stand "ab 2002", so kam das bei mir rein, aber ich glaube eher 2012.
Update: Das Folienlayout, die gezeigten Geräte und die Firmennamen deuten doch irgendwie eher auf 2002 an. Mhh.
Nun habe ich mir für meine SSL-Library gedacht, dass ich nur auf Systemen laufen werde, bei denen es /dev/urandom oder Äquivalent gibt, und nicht versuchen werde, da selber irgendwelche Entropie-Fummeleien zu machen. Das kann eigentlich nur nach hinten losgehen.
Aaaaaaber. Ein Kumpel von mir macht SSL auf einem Rechner, der nicht am Netz hängt, und eine Smartcard mit Hardware-RNG hat. Es gibt Smartcards mit Hardware-Zufall und einem kleinen ARM drauf. Habt ihr mal darüber nachgedacht, woher der Kernel den Zufall in /dev/urandom nimmt? Dafür nimmt man so Dinge wie das Timing zwischen Netzwerkpaketen und die Rotationslatenz von Festplatten. Timing von Tastatur- und Mauseingaben. Gibt es bei Smartcards alles nicht. Auf Smartphones gibt es Eingabegeräte aber keine Festplatten und bei den Netzwerkpaketen musst du davon ausgehen, dass sie ein Angreifer schickt, um deinen Zufall vorhersagen zu können.
Das ist ein echtes Problem in der Praxis. Gerade wenn ein Gerät frisch gebootet wurde, und die ganzen Krypto-Dienste hochfahren und Zufall für temporäre Schlüssel haben wollen. In solchen Fällen ist es wichtig, dass man den Zufallszahlengenerator irgendwie mit echtem Zufall seeden kann. Auch auf Servern mit SSD ist das ein Problem, wenn da keine Eingaben per Maus und Tastatur kommen.
Unter Linux kann man dafür einfach Daten nach /dev/random schreiben. Unter Windows gibt es zwar auch einen RNG in CryptoAPI, aber es gibt keinen Weg, da Zufall reinzuseeden. Die Sache mit dem Bildschirm-Auslesen ist natürlich echt ein Kracher. Aber da einfach die Möglichkeit wegzunehmen, externen Zufall reinzupipen, das macht LibreSSL für viele Anwendungen kaputt.
Übrigens, sowas wie ~/.rng kommt als Idee daher, dass man beim Runterfahren Entropie aus dem Pool ins Filesystem schreibt, damit man nach dem nächsten Hochfahren gute Entropie hat, wenn man ihn braucht. Das ist nicht per se eine doofe Idee.
Was ich sagen will: LibreSSL schießt sich hier gerade ziemlich massiv in den Fuß. Das sollte man dann auch erst mal ein paar Jahre aufhängen und reifen lassen, bevor man das einsetzen kann. Schade eigentlich.
Update: Mich weist gerade jemand darauf hin, dass das unter Windows doch auch geht.
Damit war nicht OpenSSL gemeint, sondern sowas wie X, perl, gcc. Aber OpenSSL fiel auch darunter, in dem Sinne, dass ich da eh noch andere Vorbehalte für einen Audit hatte. Und diese Policy hat dann dazu geführt, dass ich da auch nicht mal oberflächlich reingucken wollte.
Da ich angesichts aktueller Entwicklungen eh nicht gut schlafen kann mit OpenSSL gerade, habe ich mich entschieden, doch mal kurz einen Blick zu werfen.
Ich bin, gelinde gesagt, entsetzt. Schon die OpenBSD-LibreSSL-CVS-Checkin-Kommentare haben ja tief blicken lassen.
Es gibt so ein paar Kriterien, an denen ich bei C-Code meinen ersten Eindruck festmache. Das erste Kriterium ist, dass Längen und Offsets immer unsigned sein müssen, und vom Typ size_t. Früher hätte ich gesagt: unsigned long ist auch OK. Aber es gibt Plattformen, auf denen long 32-bit aber size_t 64-bit ist. 64-bit Windows z.B. Daher muss es size_t sein, nicht unsigned long. Und schon gar nicht long. Hier ist, was OpenSSL macht:
static int asn1_get_length(const unsigned char **pp, int *inf, long *rl, int max)Hier fallen ja schonmal als erstes die intuitiven Variablennamen auf. Da weiß man doch sofort, was gemeint ist! Ich kläre mal auf: Diese Routine soll einen ASN.1 DER Längenwert parsen. Das Encoding davon ist: Wenn das erste Byte das höchste Bit gesetzt hat, dann sind die unteren 7 Bits die Länge in Bytes für die Länge, die dahinter in big endian folgt. Wenn das erste Byte das höchste Bit nicht gesetzt hat, dann sind die unteren 7 Bits der Wert. Weil X.509 DER benutzt, gibt es zusätzlich noch die Regel, dass alle Längen minimal encoded sein müssen. Beispiele:
05 - Wert 5Meinem aktuellen Verständnis nach kann indefinite length bei X.509 nicht vorkommen, und ich unterstütze den Fall in meinen ASN.1-Routinen im Moment auch nicht sondern liefere einen Fehlerwert zurück. OpenSSL supported das. Möglicherweise übersehe ich da was. Wo ich aber nichts übersehe: OpenSSL prüft an keiner Stelle, dass das Encoding minimal ist. Der Effekt ist, dass man das identische Zertifikat auf mehrere Arten kodieren kann, und damit möglicherweise Angriffsfläche auf Krypto-Verfahren schaffen kann. Überhaupt sind Unterschiede zwischen Parsern immer doof, Differentiale will man an solchen Stellen vermeiden. Das ist jetzt kein "OMG RUN FOR THE HILLS"-Moment, aber wenn man schon eine zentrale Library macht für sowas, dann doch um da penibel solche Sachen abzufangen, damit die Leute das nicht alle von Hand machen und vergessen.
7f - Wert 127
81 01 - Ungültig, da nicht minimal encoded; wäre sonst 1
82 00 23 - Ungültig, da nicht minimal encoded; wäre sonst 35
82 12 34 - Wert 4660 (0x1234)
89 11 11 11 11 11 11 11 11 11 - Ungültig, da der 9-Byte-Wert nicht in einen Integer passt
0x80 - Sonderfall, "indefinite length".
Aber unabhängig davon. pp ist der Quell-Zeiger (das const ist ein gutes Zeichen, das wäre Kriterium 2 für das Erkennen von schlechtem Code gewesen). inf wird auf 1 gesetzt, wenn indefinite length encoding reinkommt. Ich finde, das hätte man direkt zurückweisen sollen. Indefinite length encoding funktioniert so, dass man am Anfang sagt, man weiß nicht, wie groß die Daten werden, die jetzt kommen, und dann schickt man halt so viele Daten wie halt kommen und dann zwei Null-Bytes. Ganz schlechte Idee, und habe ich in der Praxis auch noch nie im Einsatz beobachten können. Das ist ja gerade der Grund, wieso man ASN.1 DER einsetzt, damit man vorher weiß, wieviele Daten jetzt kommen werden. Und im Übrigen siehe oben zu den Parser-Differenzen. Das will man vermeiden.
Aber der eigentliche Punkt, auf den ich die ganze Zeit hinauswill: die Länge ist ein long. Das ist ein ganz schlechtes Zeichen. Die Routine versucht, das Schlimmste zu verhindern, indem sie als unsigned parsed und dann einen Fehler meldet, wenn der Wert größer als LONG_MAX ist. Und in der Tat, wenn sie das nicht gemacht hätte, hätte es im String-Parsing direkt einen schönen Buffer Overflow gegeben.
Ich habe jetzt jedenfalls ein schlechtes Gefühl bei OpenSSL und werde glaube ich erstmal die ASN.1-Routinen von PolarSSL auditieren, damit ich einen Fallback habe, wenn ich die ganzen Atommüllablagerungen in den Fracking-Schächten bei OpenSSL finde.
Update: Oh Graus, ich erfahre gerade, dass ich X.509 die ganze Zeit falsch verstanden hatte. Ich hatte das so verstanden, dass X.509 immer DER Encoding nimmt. Denn, mit Verlaub, alles andere ergibt auch gar keinen Sinn. Man will das ja in digitalen Signaturen verwenden. DER ist eine Teilmenge von BER, die genau den Zweck und die Daseinsberechtigung hat, dass man alles nur auf genau eine wohldefinierte Art kodieren kann. Begründung: Das braucht man so für digitale Signaturen. Und jetzt erfahre ich gerade, dass X.509 gar nicht DER sondern BER benutzt! Man soll das als Implementation anscheinend als BER parsen, dann soll man das als DER neu kodieren und dann die Signaturberechnungen machen!? Das kann ja wohl nicht wahr sein! Dann hätte OpenSSL Recht mit ihrem Code. Heilige Scheiße, wer denkt sich denn solche Standards aus!? In der Praxis habe ich noch nie was anderes als DER-Encoding gesehen. In meiner SSL-Library werde ich jedenfalls gleich beim parsen alles rejecten, das nicht DER ist.
Update: Interessanterweise macht OpenSSL es auch falsch, wenn BER Absicht ist.
173 if (i > sizeof(long))
174 return 0;
In short, it doesn't work and you are no more secure by switching it on.Und falls das jemand nicht auf dem Radar hatte: Er hat natürlich völlig Recht. Deshalb ist Revocation Checking bei Chrome per Default ausgeschaltet.
Fakt ist: OpenSSL ist nicht in C, weil C so geil ist. OpenSSL ist in C, weil das Ziel ist, dass das von jeder Programmiersprache aus benutzbar ist. Und alle können sie C-Code aufrufen.
Fakt ist auch: Das ist ein komplexes Problem, SSL richtig zu implementieren. Und wenn man dann noch den Anspruch hat, alle Obskuro-Plattformen und alle Extensions zu unterstützen, dann ist das Ergebnis halt Scheiße. Wenn man sich anguckt, was OpenBSD da gerade mit der flammenden Machete alles aus OpenSSL herausoperiert, da wird einem ganz anders. Unter anderem Support für Big Endian x86_64 Plattformen. Hat jemals schon mal jemand von sowas gehört? Nicht? Wie ist es mit VMS? EBCDIC-Support? Support für "ungerade" Wortlängen? You name it, OpenSSL supports it.
Dieses Java-Ding ist übrigens auch in einer Dissertation von einem der Beteiligten drin. Die kann man hier lesen (208 Seiten). (Danke, Sebastian)
Do not feed RSA private key information to the random subsystem asÄh ja, die Frage stellt sich. Ich stelle mir das ungefähr so vor:
entropy. It might be fed to a pluggable random subsystem….What were they thinking?!
Hey, Cheffe, wir brauchen hier mal Entropie für den Zufallszahlengenerator!Was sagst du? Krypto-Schlüssel haben eine hohe Entropie?
OK, Cheffe, knorke, wird gemacht!
m(
spray the apps directory with anti-VMS napalm.
so that its lovecraftian horror is not forever lost, i reproduce below
a comment from the deleted code.
/* 2011-03-22 SMS.
* If we have 32-bit pointers everywhere, then we're safe, and
* we bypass this mess, as on non-VMS systems. (See ARGV,
* above.)
* Problem 1: Compaq/HP C before V7.3 always used 32-bit
* pointers for argv[].
* Fix 1: For a 32-bit argv[], when we're using 64-bit pointers
* everywhere else, we always allocate and use a 64-bit
* duplicate of argv[].
* Problem 2: Compaq/HP C V7.3 (Alpha, IA64) before ECO1 failed
* to NULL-terminate a 64-bit argv[]. (As this was written, the
* compiler ECO was available only on IA64.)
* Fix 2: Unless advised not to (VMS_TRUST_ARGV), we test a
* 64-bit argv[argc] for NULL, and, if necessary, use a
* (properly) NULL-terminated (64-bit) duplicate of argv[].
* The same code is used in either case to duplicate argv[].
* Some of these decisions could be handled in preprocessing,
* but the code tends to get even uglier, and the penalty for
* deciding at compile- or run-time is tiny.
*/
Da ist man auch als Atheist versucht, nach dem Weihwasser zu greifen.
Spätestens jetzt brauchen wir dringend eine Alternative zu OpenSSL. Wenn die SPD das anfasst, und die CDU das gut findet, ist es so gut wie tot.
Nein, muss es nicht. Im Gegenteil. Das wäre das Ende von Open Source.
Außerdem lässt es der Artikel so klingen, als habe sich jetzt herausgestellt, dass Open Source Software weniger gut als kommerzielle sei. Das ist ganz großer Unsinn (auch wenn es natürlich auf beiden Seiten Ausreißer gibt, die deutlich besser als der Durchschnitt der anderen Seite sind).
Open Source als Bewegung ist das Konzept, dass man Leute Code schreiben lässt, deren Herzensblut dranhängt. Die es eben nicht kurz herunterpfuschen, weil sie dafür bezahlt werden. Open Source ist die Beobachtung, dass manche Menschen es lieben, Code zu schreiben. Und wenn man sie nicht mit Deadlines und Deliverables und dem monatlichen Paycheck unter Druck setzt, dann nehmen sie sich die Zeit und machen ihr Projekt ordentlich. Viel ordentlicher jedenfalls als die durchschnittliche kommerzielle Software.
Inzwischen wird kommerzielle Software wie Open Source entwickelt. Weil das Modell funktioniert. Kaum eine Firma entwickelt heute noch Software ohne Unit Tests, ohne Source Code-Versionskontrolle, überall gibt es ein Wiki für die Dokumentation und alle wollen gerne agil sein.
Der Erfolg von Open Source war so durchschlagend, dass es das Gegenmodell gar nicht mehr in freier Wildbahn gibt!
Wenn es etwas gibt, das sich bei Open Source zu ändern lohnt, dann ist es der mangelnde Respekt. Nur weil du gerne Programmieren lernen willst, heißt das nicht, dass du am Linux-Kernel herumfummeln solltest. Deine eigene SSL-Library schreiben? Kein Ding. Tu es! Da kann es nur Gewinner geben, selbst wenn es niemals fertig wird und niemand deinen Code benutzt. Du hast dabei was gelernt und als Programmierer an Größe gewonnen. Ein wenig bekanntes Detail aus der OpenSSL-Genesis ist, dass das mal SSLeay hieß — eay sind die Initialen des initialen Autoren, Eric Young —, und der hat das Projekt gestartet, weil er lernen wollte, wie die Division von 1024-Bit-Zahlen funktioniert.
Der Kern des Problems ist aus meiner Sicht, dass wir als Gesellschaft uns darauf geeinigt haben, dass Software halt ein schwieriges Problem ist, und daher Fehler halt passieren und niemand für seine Fehler geradestehen muss. Man kann sich heute bei so gut wie allen Problemen mit "das war ein Softwarefehler" herausreden. Für mich als Programmierer ist das natürlich auf der einen Seite toll, weil ich mich so Dinge trauen kann, die ich sonst nicht in Angriff nehmen würde. Aber es hat in der Szene so ein wirklich widerliches Gefühl erzeugt, als hätten wir Programmierer es verdient, als sei das unser Recht, niemals für unseren Scheiß den Kopf hinhalten zu müssen. Ich will das mal anhand dieser Tweets veranschaulich. So tief sitzt da die Panik! So ein Affront für das Weltbild ist es, dass möglicherweise jemand kommen könnte, und der sieht, dass ich gepfuscht habe! Sowas finde ich zutiefst unwürdig. Als ob der Auditor Schuld hat, wenn dein Code Scheiße ist! Wenn bei einer Frittenbude Küchenschaben gefunden werden, ist dann das Gesundheitsamt der Bösewicht? Wenn GM kaputte Autos baut, und da sterben Leute, glaubt ihr auch, die Zuständigen machen sich in erster Linie Sorgen wegen der Hater aus dem Internet? Anders gefragt: Würde irgendjemand von euch von einer Firma kaufen, die nur Qualitätskontrolle macht, weil sie Angst vor Internet-Hatern hat, wenn herauskommt, wir ranzig ihr Produkt ist?!
Dass überhaupt das Wort "Hater" gefallen ist, sagt aus meiner Sicht schon alles. Wenn du etwas baust, dann sollte das der güldene Sonnenschein sein, nach frisch gebackenem Brot durften und die filigrane Eleganz eines mathematischen Beweises haben. Und zwar nicht weil es da draußen "Hater" gibt, sondern weil das dein verdammer Anspruch an dich selbst ist! Wenn jemand kommt und dich auf Fehler in deinem Code hinweist, dann solltest du auf die Knie fallen und dem Fremden überschwänglich danken, denn er hilft dir, deinen Code näher an die Zielvorstellung der Perfektion zu bringen!
Ich glaube nicht, dass bei Software so viel mehr gepfuscht wird als anderswo. Aber physische Dinge sind vergänglich. Fehler bei physischen Dingen gehen von alleine weg, mit den Dingen selbst. Software lebt theoretisch für immer. Softwarefehler akkumulieren immer nur. Aus meiner Sicht müssen wir Software wie radioaktiven Müll behandeln — vorsichtig und mit Bedacht.
Nachdem ich all das gesagt habe, möchte ich noch sagen: Schreibt mehr Software! Aber macht es ordentlich!
Update: Jetzt bin ich ganz von meinem eigentlichen Gedankengang abgekommen. Open Source funktioniert, weil es eben nicht geldgetrieben ist. Der Programmierer zieht seinen Anreiz, die Software zu schaffen, aus der kreativen Freude des Programmierens, und aus dem Zen-ähnlichen Zustand, wenn ein komplexer Algorithmus, den man hingeschrieben hat, dann tatsächlich funktioniert. Guter Code ist seiner selbst Belohnung. Wenn man dort Geld als Anreiz einbringt, dann wird das dieses Modell kaputtmachen. Programmierer werden dann anfangen, die Arbeit pro eingenommenem Euro zu minimieren. Genau wie das überall eintritt, wo man Geld für Arbeit zahlt. Am Ende wird man feststellen, dass die Stundenlöhne anderswo niedriger sind als bei uns, und dann wird niemand mehr in Deutschland Open Source programmieren wollen. Nur weil man das mentale Modell so umgebaut hat, dass wir das "für Geld" tun, nicht um etwas zu lernen, oder den anderen Gründen. Macht das bloß nicht!
Geld für Dinge ausgeben, bei denen niemand kreative Genugtuung erfährt, das kann man diskutieren. Ich glaube, das wird man auch machen müssen, damit auch bei den SSL-Libraries wieder Open Source qualitativ führend ist. Aber fangt nicht an, das Belohnungsmodell von Open Source Programmieren auf "da gibt es Geld für" umzustellen. Das wäre der Untergang.
Update: Ich will mal eine Kommentarmail hier zitieren:
In der Psychologie unterscheidet man zwischen extrinsischer und intrinsischer Motivation. Intrinsische Motivation bedeutet, dass man etwas tut, weil es einem Spass macht, weil man es für richtig hält etc. Extrinsische Motivation bedeutet, dass man etwas tut, weil man eine Belohnung dafür erhält. Sozialpsychologische Experimente haben gezeigt, dass man intrinsische Motivation unwiederbringlich zerstören kann, indem man einen extrinsischen Anreiz schafft, etwas zu tun.
Update: Noch eine Einsendung:
Die moderne Motivationsforschung sagt an dieser Stelle „Nein“, weil die Programmierer bereits in dem Moment wo sie Geld bekommen den Spaß verlieren würden, aus Spiel wird dann Arbeit. Das Ganze geht auf die Selbstbestimmungstheorie der Motivation von Deci & Ryan, 1985a zurück (s. Wikipedia). Lese grade Drive von Daniel Pink (ISBN 978-1847677686), was die gedankliche Grundlage für die agile Softwareentwicklung z.B. Scrum beschreibt. Bei modernen Softwareschmieden gehört diese Kenntnis mittlerweile auch zum Einstellungskriterium.
Jetzt gibt es OCSP, aber das haben noch nicht alle CAs ausgerollt, viele Browser haben es noch gar nicht per Default an, und die, die es an haben, laufen regelmäßig in Timeouts, weil bei einer CA gerade mal wieder der OCSP-Service kaputt ist.
Es knirscht gewaltig im Gebälk bei SSL.
OpenBSD hat einen Audit angestoßen und der zeitigt erste Ergebnisse.
Und nicht zuletzt: Coverity, einer der bekannteren Code-Scanner, der hat Heartbleed nicht erkannt. Der Firma ist das einigermaßen peinlich, daher haben sie jetzt nach Heuristiken gesucht, um sowas doch zu finden, und dabei hatten sie eine relativ smarte Idee: Endianness-Konvertierung markiert bei denen jetzt Variablen als vergiftet. So gehen Code-Auditoren wie ich auch vor.
Ich habe die Tage erfreut festgestellt, dass PolarSSL auch ECDSA kann inzwischen, EDH eh schon, und jetzt auch GCM. Damit haben sie soweit alle wichtigen Features. Auf Client-Seite ist die Zertifikats-Validierung wohl noch nicht so toll, ich verlinkte neulich die Frankencert-Tabelle. Aber das ist ja serverseitig wurscht, außer man will Client Certs haben, was so gut wie niemand tut. Das ist neben OpenSSL die andere unterstützte SSL-Engine in gatling und von der Codequalität her macht sie einen ganz guten Eindruck. Viel kleiner und ordentlicher und weniger Makrohölle als OpenSSL. Klein genug, dass eine Einzelperson davon realistisch einen Komplett-Audit machen könnte.
Aber da war ja überhaupt keine Reue, nicht mal ein "Hups". Eher so Beobachten aus der Entfernung. "Hmm, das hat aber groß Bumms gemacht".
Mal einen Fehler zu machen, dass kann man verzeihen. Passiert. Aber nicht zu seinen Fehlern zu stehen, und in der Presse das dann noch kleinzureden versuchen, "war nur ein ganz trivialer Fehler", das geht aus meiner Sicht gar nicht. Und das dann noch dem Briten in die Schuhe schieben zu wollen, der das am Neujahrsmorgen um 1 Uhr nachts durchgewunken hat, das finde ich auch unakzeptabel.
Das ist genau so abwegig wie wenn ein Krimineller für seine Tat die Polizei verantwortlich macht, weil die ihn nicht aufgehalten haben.
Im Übrigen: Nein, der Fehler ist nicht trivial. In einem Netzwerkprotokoll keine Eingabevalidierung zu machen ist kein trivialer Fehler. Das ist auf der 1-bis-Tschernobyl-Skala ein Fukushima. Das Mindeste, was man dann tun kann, ist ein öffentliches: Meine Schuld, tut mir leid, verzeiht mir, ich gelobe Besserung. Zumindest ein bisschen "Wir entschuldigen uns für die Unannehmlichkeiten"-Heucheln ist ja wohl nicht zuviel verlangt!
Wie sieht denn das jetzt aus? "Sind die Open-Source-Leute alle so wenig teamfähig, dass sie ihre Fehler kleinreden und anderen in die Schuhe schieben?" "Vielleicht lassen wir das hier lieber nicht in Deutschland entwickeln, die stehen da nicht zu ihren Fehlern."
Aber vielleicht habe ich da einfach zu hohe Ansprüche. Ich runzle ja schon meine Stirn, dass jemand mit so wenig Erfahrung es überhaupt gewagt hat, bei OpenSSL Code einzuchecken, der auch noch Daten vom Angreifer handled. Das ist dann wohl der Dunning-Kruger-Effekt in Aktion.
Ich habe 1995 mal Code bei ssh eingeschickt, bevor es openssh gab. Das war Code für ein zusätzliches Detail in der Config-Datei. Ich weiß noch, wie ich da sehr nervös war, das überhaupt hinzuschicken. Netzwerk-Parsing-Code hätte ich mich gar nicht einzusenden getraut damals. Ist dieser Respekt vor wichtigen Infrastrukturprojekten über die Jahre verloren gegangen?
Oder habe ich das übersehen und er hat sich entschuldigt?
Update: Eigentlich ist der Typ bloß das Symptom. Das ist ja ein gesamtgesellschaftliches Problem. Oder erinnert sich jemand von euch, wann in der Politik zuletzt jemand Schuld gewesen ist an irgendwas? Kommt nicht mehr vor. Der Hoeneß war Schuld, ja, als es nicht mehr zu leugnen war. Das war die Ausnahme. War bei dem Mollath irgendjemand Schuld? Nein. Bei BER? Das war alles Schicksal. Ein Gesetz nach dem anderen haben wir wegen Verfassungswidrigkeit weggehauen. Da war auch nie jemand Schuld. Illegaler Bundestrojanereinsatz? War auch keiner Schuld. Kaufen wir halt einen anderen Trojaner. Vorratsdatenspeicherung verfassungswidrig? Niemand zeugt Reue. Ich hatte halt gehofft, dass das wenigstens in meiner Branche anders ist. Dass wenigstens die Techies zu ihrem Scheiß stehen können. Techies sind ja auch sonst ehrlicher und können den Kunden im Allgemeinen nicht so direkt ins Gesicht lügen, wenn sie nach Schwächen ihres Produkts gefragt werden.
Apropos Fukushima. TEPCO hat sich entschuldigt. Die hätten auch mit dem Finger einmal im Kreis zeigen können. Die Regulierungsbehörde, die Regierung, die Anreize, die Börse, wir haben unseren Techies vertraut, das lief doch immer alles super… aber selbst DIE haben die Größe gehabt, sich zu entschuldigen.
Die aktuelle Inkarnation war, dass die nervigen Selbstvermarkter von Cloudflare sich hingestellt haben, und behauptet haben, also in IHREM Setup käme man per Heartbleed aber nicht an die SSL-Zertifikate ran, daher müssten sie jetzt auch nicht alle zurückrufen und neumachen. Als Beweis haben sie eine Teststellung hingestellt, und das Internet herausgefordert, ihnen eine mit ihrem Schlüssel signierte Botschaft zu schicken. Hier ist ihre Challenge-Webseite.
Und siehe da: jemand hat den Key extrahiert.
Aber die Kernbotschaft, egal ab wann Geheimdienste das exploited haben, ist: Geheimdienste arbeiten gegen ihre eigene Bevölkerung, nicht für sie. Die Geheimdienste wussten davon und haben nichts gesagt.
Oh und eine Sache noch: Das sieht jetzt hier aus wie eine Bankrotterklärung von Open Source. Das stimmt nicht. Der Bug wurde von zwei Leuten gleichzeitig gefunden und gemeldet. Einmal von einer Security-Firma, die eine Testsuite für SSL-Bugs programmiert hat. Die hätte das auch bei einem Nicht-Open-Source-SSL gefunden. Aber der andere Finder war ein Google-Angestellter, der einen Quellcode-Audit gemacht hat. Den hätte es so bei einem Nicht-Open-Source-SSL nicht gegeben. Wir haben hier also die Chancen direkt verdoppelt, solche Bugs zu finden. Wer weiß, was in Kommerzsoftware noch so für Untiefen lauern.
Meiner Erfahrung nach variiert die Codequalität bei Open Source und bei kommerzieller Software immens, und der Durchschnitt liegt ungefähr auf einem vergleichbaren Niveau. Man kann nicht davon ausgehen, dass kommerzielle Software grundsätzlich ein höheres Niveau hat.
Übrigens stört mich an der Debatte ein bisschen, dass so wenig Leute daraus Konsequenzen ziehen. Wir benutzen alle die ganze Zeit Open Source Software, ohne dafür zu zahlen, und wir benutzen Kommerzsoftware und bezahlen dafür. Dann wundern wir uns, dass die Hersteller von Kommerzsoftware Geld haben, um davon Audits machen zu lassen, aber die Open Source-Leute warten müssen, bis Google mal vorbeikommt.
Eine mögliche Konsequenz aus dem aktuellen Geschehen könnte sein, dass man mal einen Fonds macht, in den Benutzer von Open Source-Software einzahlen, und mit dem dann Qualitätssicherungsmaßnahmen bezahlt werden, für die Freiwillige bei den jeweiligen Projekten nicht die Motivation aufbringen. Das meint natürlich Security-Audits, aber es meint auch sowas wie ordentliche Testsuiten basteln; Dokumentation bereitstellen.
Update: Die US-Regierung dementiert. Was sollen die auch sonst sagen. Sie behaupten sogar, dass sie alle Lücken reporten, die sie finden. Ja nee, klar.
Leute, es ist doch völlig wurscht, ob das jetzt eine Backdoor ist oder nicht. Wir müssen alle davon ausgehen, dass über dieses Ding alle unsere Passwörter rausgetragen wurden. Ob das jetzt ein Geheimdienst eingebaut hat, oder ob das ein Geheimdienst nur entdeckt und damit sein BULLRUN-Programm aufgebohrt hat, das ist doch völlig nebensächlich.
Der Punkt an der Sache ist, dass wir ab jetzt IMMER davon ausgehen müssen, dass irgendwelche Bugs auch eine Backdoor sein könnten. Es gibt für sowas keine Beweise, nur Indizien, und wir wissen es nie genau, bis es irgendwann ein Whistleblower zugibt. Und es spielt auch keine Rolle, wie viele Indizien es gibt, wie stark die sind, oder ob es wirklich eine Backdoor war oder nicht.
Es geht auch nicht um diesen Seggelmann. Der wird jetzt damit leben müssen, beim größten Security-Meltdown in der Geschichte von SSL der Mann an der Reaktorkühlung gewesen zu sein. Ob das jetzt Absicht war oder nicht — who cares.
Was eine Rolle spielt, ist dass wir jetzt das Bedrohungsszenario "jemand will uns eine Backdoor unterschieben, die bloß wie ein blöder Bug aussieht" nicht mehr als Verschwörungstheorie zu den Akten legen können nach Snowden. Wir müssen ab jetzt bei jedem Checkin davon ausgehen, dass uns jemand sabotieren will. Nicht bei allen Projekten. Aber bei sowas wie OpenSSL ganz bestimmt.
Open Source-Softwareentwicklung hat gerade den Sprung in die Geheimdienstwelt gemacht, wo man sich gegenseitig nicht mehr einfach so traut. Die Zeit der Blümchenwiesen-Softwareentwicklung ist vorbei, wenn die Software auf Millionen von Desktops läuft.
Ob das Open Source Modell in so einer Paranoia-Umgebung überleben kann, wird sich zeigen müssen. Aber einfach so tun, als beträfe uns das alles nicht, das können wir nicht mehr.
Ich bin mir übrigens sicher, dass man auch bei einigen von meinen Bugs über die Jahre rückblickend Indizien konstruieren könnte, wieso das wie eine Backdoor aussieht, oder einer anderen Backdoor hilft oder sie ermöglicht. Man müsste sich dafür recht weit aus dem Fenster lehnen, aber das ist ja kein Problem bei Verschwörungstheorien. Glücklicherweise habe ich nicht so viele sicherheitskritische Fehler gemacht über die Jahre.
Der Grund ist: Weil ich die Details von OpenSSL noch nicht genügend verstehe. Die APIs sind hochkomplex und undurchsichtig. Alleine OpenSSL anzuwenden ist schon ein Kampf gegen Windmühlen. Ich frickel jetzt seit Monaten immer mal wieder an dem OpenSSL-Interface von gatling herum und der negotiated immer noch nicht die Cipher-Suites, die ich eigentlich haben will.
So eine SSL-Library ist an sich schon hochkomplex. Da werden Kombinationen aus Verfahren und Extensions verhandelt, und OpenSSL implementiert sie so gut wie alle. Ich überlege ja seit ein paar Jahren, selber mal eine SSL-Library zu schreiben. Nicht damit ich am Ende eine SSL-Library habe, sondern weil ich dann sicher sein kann, dass ich die Details verstanden habe.
Fakt ist: Das ist alles nicht so einfach, und ein Audit bringt nur was, wenn man auch die Details verstanden hat. Sonst findet man nur die offensichtlichen Fehler. Wie sich jetzt herausstellt, wäre auch das hilfreich gewesen. Fair enough. Das war vorher nicht so klar. OpenSSL hatte an sich immer einen recht guten Track Record. Die Bugs in OpenSSL waren eher so Sachen wie Timing-Angriffe, Side-Channel-Probleme, kryptographische Designprobleme.
Ich könnte da jetzt ein bisschen auditieren, wahrscheinlich ein paar Bugs finden. Die könnte man dann fixen. Ein Kunde würde sich darüber freuen. Aber meinem Anspruch an einen Audit von kritischer Infrastruktur würde das nicht genügen. Wäre damit wirklich was geholfen? Mein Ziel bei meiner Software ist immer, dass ich nachts ruhig schlafen kann, weil ich nicht darüber nachdenken muss, ob da gerade jemand meinen Server aufmacht. Dieses Niveau an Vertrauen werde ich bei OpenSSL nicht mit einem Audit auf meinem aktuellen Kenntnisstand von den TLS- und Krypto-Details erreichen können. Damit ist aber auch klar, dass ich eigentlich nicht mehr OpenSSL einsetzen möchte, sondern etwas vertrauenswürdigeres. Und dann erscheint es mir ein besseres Investment meiner Zeit, wenn ich an meiner eigenen SSL-Library hacke.
Das ist aber so viel Aufwand, dass ich dann lieber an einem anderen Problem herumhacke, das auch auf der Liste steht, und schneller ein Erfolgserlebnis liefert.
Ob da noch mehr Gruselkram kommt?
Update: Jetzt geht auch http nur noch seeeeehr langsam. WTF? (Danke, Stefan)
Ich erwähne das, weil das aus meiner Sicht der Grund ist, wieso dieser Code es bis in OpenSSL geschafft hat. Wenn jemand da den reinkommenden Code auditiert, guckt der nach den hochriskanten Bugs. Und nach der langläufigen Einschätzung, die so bei Entwicklern vertreten wird, ist out of bounds read halt viel weniger riskant als andere Bug-Klassen. Ich kann mir gut vorstellen, dass der Auditor einfach nicht nach der Art von Bug geguckt hat. Der hat memcpy gesehen, und hat dann kurz geprüft, dass vorher genug alloziert wurde und das keinen Buffer Overflow gibt, und dann hat der das durchgewunken.
Normalerweise ist es nur meine Aufgabe, Bugs zu finden. Ich bin nicht dafür zuständig, dass die auch gefixt werden. Aber trotzdem kriege ich natürlich regelmäßig mit, wenn die Entwickler dann Bugs schließen, weil sie das Risiko für zu gering halten. Wenn es mal organisatorische Zwänge gibt, dass Bugs gefixt werden müssen, beziehen die sich normalerweise nur auf "wichtige" Bugs wie Buffer Overflows. Und auch da kommt es häufiger vor, dass Entwickler sich weigern, sowas zu fixen, wenn man ihnen keinen Exploit zeigt.
Wenn ich meine Zeit damit verbringe, einen Exploit zu schreiben, finde ich aber keine Bugs in der Zeit. Daher wird das im Normalfall nicht passieren. Wenn Entwickler einen Exploit sehen wollen, geht es nicht um den Bug, sondern das ist der Versuch, den Bug loszuwerden, ohne ihn fixen zu müssen, indem der Gegenseite eine massive Bringschuld aufgebürdet wird. Schon der Einspruch des Entwicklers kostet ihn (mich sowieso) im Allgemeinen deutlich mehr Aufwand, als das Fixen des Bugs gekostet hätte.
Warum schreibe ich das hier alles? Weil ich darauf hinweisen möchte, dass das System im Moment kaputt ist. Die Perspektive von Entwicklern auf Bugs müsste sein: You file it, we fix it. Und zwar sofort. Keine Rückfragen, kein Gezeter, kein Prokrastinieren. Alle Bugs werden sofort gefixt. Wir reden ja hier von professionellen Entwicklern. Die kriegen Geld dafür, ordentlichen Code zu schreiben. Wenn es da einen Defekt gibt, wird der sofort gefixt. Fertig. Und zwar unabhängig davon, ob das jetzt ein Security-Problem ist oder "nur" Defense in Depth. Egal ob man das Szenario für realistisch hält oder nicht.
Einige Firmen haben das mit Incentive-Programmen herbeizuführen versucht. Sowas wie "es gibt Bonus, wenn man höchstens soundsoviele Bugs hat". Das führt leider dazu, dass einige Entwickler einfach alle einkommenden Bugs sofort als ungültig schließen, damit sie nicht in die Statistik gelangen. So einfach ist es halt nicht.
Und bei Open Source ist das natürlich noch mal schwieriger, Qualitätsstandards einzuhalten, wenn du niemandem damit drohen kannst, dass er gefeuert wird, wenn er sich nicht zusammenreißt.
Ein technisches Detail habe ich noch. OpenSSL hat seinen eigenen Allokator gebaut. Theo de Raadt (der Mann hinter OpenBSD) regt sich schön darüber auf, erwähnt aber nur die halbe Problematik. Eigentlich nur ein Viertel. Der Grund, wieso OpenSSL einen eigenen Allokator gebaut hat, ist — so vermute ich jedenfalls — OpenBSD. OpenBSD scheißt auf Performance und macht ihr malloc dafür richtig doll langsam. Auf der Plus-Seite segfaultet das dann sofort, wenn jemand was falsch macht. Kann man vertreten, aber dann sieht das halt in Benchmarks so aus, als sei OpenSSL furchtbar langsam. OpenSSL hatte jetzt zwei Möglichkeiten. Sie hätten mal ihren Code entkernen können, damit der nicht so viel malloc und free aufruft. Das wäre die gute Variante gewesen. OpenSSL hat aber lieber getrickst und sich einen eigenen Allokator gebaut und damit, wie Theo kritisiert, die Sicherheitsvorteile des OpenBSD-Allokators aufgegeben.
Die andere Hälfte der Medaille ist, dass der OpenSSL-Allokator vom System größere Blöcke Speicher anfordert, und dann innerhalb von denen selber fummelt. Das heißt aber, wenn ich jetzt 64k Speicher leaken kann, die aus einem dieser Blöcke kommen, dass da nur OpenSSL-Daten drin sind. Keine anderen Daten, die jemand anderes im Prozess alloziert hat. Das ist es, was diesen Bug so tödlich macht. Ihr habt vielleicht die Speicherdumps gesehen, die gerade so rumfliegen. Das ist der Grund, wieso da immer gleich so saftige Daten drinstehen wie unverschlüsselte HTTP-Dumps mit den Cookies und Passwörtern.
Update: Einen noch. Ich kriege hier gerade von einigen Leuten Flak, weil ich den Namen des Entwicklers gebloggt habe. Als ob der vorher nicht dran gestanden hätte an dem git-Checkout. Ist das legitim, den als Schuldigen zu nennen? Ich finde: Ja. Denn die Entwickler müssen endlich chirurgisch von der Idee befreit werden, dass Fehler halt unvermeidbar sind, und daher ist das nicht so wichtig, dass ich hier ordentlich arbeite. Es geht hier nicht um Shaming, sondern darum, dass alle sehen: Das hat ein Typ wie du und ich geschrieben, und hier hat ein anderer Typ wie du und ich das durchgewunken. Wenn die das falsch machen, muss ich vielleicht auch mein Verhalten ändern? Ja, müssen wir. Alle von uns.
Wir reden hier von einer der zentralen Sicherheits-Komponenten auf der Welt. Es ist völlig unakzeptabel, dass so ein Ranz-Code bei OpenSSL submitted wird. Es ist auch völlig unakzeptabel, dass OpenSSL das dann nicht merkt und diesen Ranz-Code eingecheckt hat. Und es ist völlig unakzeptabel, dass diese Tretmine da jetzt seit Jahren in der Codebasis herumgammelte, und es keiner gemerkt hat. Wir haben hier ein massives Prozess-Problem, und dem müssen wir uns stellen. Das hat mit Shaming nichts zu tun. Millionen von Menschen verlassen sich auf diese Software. Da checkt man nicht mal eben kurz was ein, wird schon gutgehen. Die Wartung von OpenSSL sollte mit einer ähnlichen Verantwortung verbunden sein wie das Warten von Flugzeugen oder Atomkraftwerken. Wir haben schlicht keine Entschuldigungen dafür, dass es soweit kommen konnte.
Natürlich konnte ich auch an dem T-Systems-Joke nicht vorbeigehen, das seht ihr sicher ein. :-)
Hier ist der git commit. Das ist aber nicht der Punkt hier gerade.
Wo arbeitet der? Was meint ihr? Kommt ihr NIE drauf!
Robin Seggelmann T-Systems International GmbH Fasanenweg 5 70771 Leinfelden-Echterdingen DE
Update: Eine Sache noch. Nehmen wir mal an, jemand würde mich bezahlen, eine Backdoor in OpenSSL einzubauen. Eine, die auf den ersten Blick harmlos aussieht, die aber ohne Exploit-Schwierigkeiten auf allen Plattformen tut und von den verschiedenen Mitigations nicht betroffen ist. Genau so würde die aussehen.
Ich sehe in dem Code nicht mal den Versuch, die einkommenden Felder ordentlich zu validieren. Und auch protokolltechnisch ergibt das keinen Sinn, so eine Extension überhaupt zu definieren. TCP hat seit 30 Jahren keep-alive-Support. Es hätte also völlig gereicht, das für TLS über UDP zu definieren (und auch da würde ich die Sinnhaftigkeit bestreiten). Und wenn man ein Heartbeat baut, dann tut man da doch keinen Payload rein! Der Sinn von sowas ist doch, Timeouts in Proxy-Servern und NAT-Routern vom Zuschlagen abzuhalten. Da braucht man keinen Payload für. Und wenn man einen Payload nimmt, dann ist der doch nicht variabel lang und schon gar nicht schickt man die Daten aus dem Request zurück. Das ist auf jeder mir ersichtlichen Ebene völliger Bullshit, schon das RFC (das der Mann auch geschrieben hat), das ganze Protokoll, und die Implementation ja offensichtlich auch. Aus meiner Sicht riecht das wie eine Backdoor, es schmeckt wie eine Backdoor, es hat die Konsistenz einer Backdoor, und es sieht aus wie eine Backdoor. Und der Code kommt von jemandem, der bei einem Staatsunternehmen arbeitet, das für den BND den IP-Range betreut (jedenfalls vor ein paar Jahren, ob heute immer noch weiß ich nicht). Da muss man kein Adam Riese sein, um hier 1+1 zusammenzählen zu können.
Update: Es stellt sich raus, dass der Mann damals noch an seiner Dissertation geschrieben hat und an der Uni war und erst später bei T-Systems anfing. In der Dissertation geht es unter anderem um die Heartbeat-Extension, die mit UDP begründet wird. In dem Text steht auch drin, dass man keine Payload braucht. Aber lasst uns das mal trotzdem so machen, weil … Flexibilität und so!
Update: Echte Verschwörungstheoretiker lassen sich natürlich von sowas nicht aufhalten. Der Job bei T-Systems war dann halt die Belohnung!1!! Und echte Verschwörungstheoretiker googeln auch dem Typen hinterher, der den Code auditiert und durchgewunken hat, damit der eingecheckt werden konnte. Ein Brite, der nur 100 Meilen von Cheltenham (GCHQ-Sitz) entfernt wohnt!!1!
Update: Robin Seggelmann hat der australischen Presse erklärt, das sei ein Versehen gewesen.
Update: Hier ist eine Gegendarstellung dazu von Herrn Seggelmann:
Der Fehler ist ein simpler Programmierfehler gewesen, der im Rahmen eines Forschungsprojektes entstanden ist. T-Systems und BND oder andere Geheimdienste waren zu keiner Zeit beteiligt und zu meiner späteren Anstellung bei T-Systems bestand zu keiner Zeit ein Zusammenhang. Dass T-Systems im RFC genannt wird, liegt an der verspäteten Fertigstellung des RFCs und es ist üblich, den bei der Fertigstellung aktuellen Arbeitgeber anzugeben.
(Danke, Jürgen)
Naja, kein Problem, dachte ich mir, für sowas gibt es ja eine Rescue-Umgebung. Wollte die klicken — der Knopf fehlte im Webinterface. Nanu? Ticket aufgemacht. Knopf da. Knopf gedrückt — Server platt, kein Rescue kommt hoch. Ticket aufgemacht. Pause. Antwort: Wir haben da mal ne Intel e100 NIC eingebaut, damit das Rescue hochkommt, und die Onboard-NIC ausgemacht. Musst du dann in deinem Debian fixen.
Die Meldung sah ich aber erst, nachdem ich mein Problem gefixt hatte, und umgebootet hatte, und da kam dann das System zwar hoch, aber ohne Netzwerk.
Also zurück ins Rescue, aber das kam dann auch nicht mehr hoch. Ticket aufgemacht. Die haben irgendwas gebastelt, damit kam das wieder hoch.
Oh, erwähnte ich, dass das Rescue-System ohne mdadm kam? Ich hab seit gefühlt 10 Jahren kein Rescue-System mehr gebraucht. Stellt sich raus, dass sowas heutzutage ein richtiges Debian ist, wo man konfigurieren kann, inklusive apt-get install mdadm. Allerdings will er dafür über 50 MB nachladen, also hab ich lieber ein statisches dietlibc-mdadm hochgeladen und benutzt.
Das Problem, so stellte sich raus, war: Die e100-Netzwerkkarte möchte gerne Firmware nachladen, die nicht da war. Ich trag also das Repository ein und rufe apt-get auf … da baut irgendein Debian-Automatismus eine initrd neu und die ist nicht mehr bootfähig.
Nun hat mir der Hoster freundlicherweise ein KVM zur Verfügung gestellt, sonst hätte ich den Aspekt gar nicht sehen können. Aber mit der neuen initrd fand der Kernel sein root-fd nicht und panicte.
Die nächsten Schritte waren: Debian dist-upgrade (das war noch ein squeeze), grub erneuern, grub stirbt mit symbol grub_divmod64_full not found. Bekanntes Problem, offenbar, aber die Lösungen funktionierten alle nicht. purge, reinstall, deinstall, config fummel, reinstall, auf die zweite platte auch installieren, half alles nichts.
In der Mitte hatte ich noch versucht, einen eigenen Kernel zu bauen, der auf der Hardware laufen würde, aber der tat es nicht und auf dem 80x25-Screen der KVM sah ich dann auch nur die letzten statischen Zeilen eines generischen Panic-Stackdumps und konnte nicht hochscrollen. Aus irgendeinem Grund kamen Tastatureingaben nicht an über die KVM. Ich tippe auf ein Java-Problem, aber am Ende — who cares.
Der einzige Ausweg war am Ende, dass ich einen eigenen grub 2.02 beta 2 aus den Sourcen kompiliert habe. Der warf zwar auch noch lustige Fehlermeldungen, aber hat dann am Ende den Kernel doch gebootet.
So, jetzt hab ich zwar immer noch einen veralteten gcc und eine veraltete glibc, aber immerhin ist die Kiste wieder oben. Seufz.
Update: Warum war da so ein antikes Debian? Weil alle von außen erreichbaren Dienste eh von mir und nicht von Debian sind.
Update: Es gibt einen xkcd dazu! Großartig, den kannte ich noch gar nicht :-)
Update: Das SSL-Zertifikat ist dann auch mal neu, wegen des OpenSSL-Bugs gerade.
Es hat halt Vor- und Nachteile, wenn man seine eigenen Prereleases in die Produktion nimmt :-)
Diese Art Bug ist leider bei Apps üblich. (Danke, Noel)
Um so erstaunlicher: Die US-Handelsaufsicht FTC hat jetzt ein paar Mobile-App-Klitschen verdonnert, sich 20 Jahre lang jährlich unabhängig die Security testen zu lassen.
Das wird hoffentlich wie ein Donnerhall durch die Branche krachen. Noch schöner wäre es gewesen, wenn da mal eine handfeste Strafzahlung ausgeteilt worden wäre, oder gar direkt Knastdrohung für das Management. Fandango, die eine der betroffenen Apps, verkauft Kinokarten, d.h. da gehen Kreditkartendaten über das Netz.
Update: Alle zwei Jahre nur, nicht jährlich :-(
Wenn man es ernst meint, muss man natürlich auch seine symmetrischen Cipher alle einmal anfassen, was sich teilweise massiv negativ auf die Performance auswirkt, wenn man nicht z.B. AES per spezieller AES-CPU-Instruktion macht.
Lustig an den Release-Notes ist auch unten die MISC-Kategorie, wo sie die ganzen BSDs auflisten, auf denen das nicht oder kaputt kompiliert, weil die Infrastruktur stinkt. Wer dachte, im Jahre 2014 haben wir plattformübergreifend robuste und belastbare Softwareentwicklungs-Infrastruktur am Start, der täuscht sich halt.
Bestraft werden sollen jene, die die "Souveränität und territoriale Integrität der Ukraine bedrohen" und "die demokratischen Prozesse und Institutionen des Landes" untergrabenDie Formulierung finde ich echt den Gipfel. Wir haben es hier mit einer Volksabstimmung zu tun auf der Krim. Und trotzdem kommen die mit "die demokratischen Prozesse". Für SO BLÖDE halten die euch!
Man beachte, dass sie explizit davon sprechen, die Sanktionsopfer hätten die Souveränität und territoriale Integrität der Ukraine bedroht. Bedroht, nicht verletzt.
Aber hey, nichts ist so offensichtlich bescheuert, dass die Merkel nicht noch auf den fahrenden Zug aufzuspringen versuchen würde!
Bundeskanzlerin Angela Merkel erklärte, sie halte auch Sanktionen der Europäischen Union gegen Russland für unausweichlich, wenn Moskau nicht zu diplomatischen Gesprächen bereit ist. Man könne nicht einfach zur Tagesordnung übergehen, "wenn noch keinerlei diplomatische Gespräche stattfinden", sagte sie. Die Kanzlerin machte klar: "Das heißt, wir werden uns auch mit Sanktionen beschäftigen in unterschiedlicher Art und Weise."Das befürworte ich ausdrücklich. Solange die Merkel mit Sanktionen für die Ukraine beschäftigt ist, richtet sie anderswo keinen Schaden an. Natürlich sollten wir jetzt verhindern, dass es tatsächlich zu Sanktionen gegen die Ukraine kommt. Die armen Schweine dort haben schon genug Ärger und brauchen nicht noch einen Knüppel zwischen die Beine. Wieso betone ich so, dass die Sanktionen gegen die Ukraine sind? Schaut euch mal diese Grafik an, wieviel Prozent unseres Erdgases wir von Gazprom kriegen. Und WIR wollen RUSSLAND mit Sanktionen drohen? Dass ich nicht lache!
Update: Im Übrigen sei noch darauf hingewiesen, dass der Westen selbstverständlich Volksabstimmungen zur Abspaltung von Regionen für angemessen hält, wenn das zu erwartende Ergebnis der Abstimmung westliche Interessen widerspiegelt. Oder man kann natürlich auch nach Ex-Jugoslawien gucken, oder zur Aufspaltung der Tschechoslowakei. Was wohl gewesen wäre, wenn da die eine Hälfte gesagt hätte, sie wollen lieber Kommunisten werden?
Description: Secure Transport failed to validate the authenticity of the connection. This issue was addressed by restoring missing validation steps.Fast überflüssig zu erwähnen, dass es sich um Apple handelt.Update: Es handelt sich anscheinend um dieses Problem — Apple-SSL hat den Common Name nicht geprüft. Das ist ungefähr so das schlimmste, was man bei SSL verkacken kann. Und wie ihr sehen könnt, sitzt Apple seit Monaten auf dem Problem und hat ihre Kunden ins offene Messer laufen lassen. Tolle Firma ist das, wer würde… Oh guck mal da drüben, ein neues Iphone! Jetzt in hellgrün! Schnell kaufen!1!!
Update: Bei reddit behauptet jemand, es sei nicht dieser Bug. Und Adam Langley sagt, das Problem betrifft auch OS X, nicht nur die Mobilgeräte.
Update: goto fail;
$ sslscan www.ausweisapp.bund.de | grep AcceptedEinmal mit Profis arbeiten!
Accepted SSLv3 128 bits RC4-SHA
Accepted SSLv3 128 bits RC4-MD5
Accepted TLSv1 128 bits RC4-SHA
Accepted TLSv1 128 bits RC4-MD5
Update (31. Januar 2014): Jetzt kann die Site ein paar mehr Cipher, aber a) immer noch lauter schwache Export-Cipher und b) kein Perfect Forward Secrecy. Da besteht noch Handlungsbedarf! (Danke, Christian)
Übrigens habe ich Anfang Januar das Blog geändert, dass kein Cookie mehr gesetzt wird, wenn die URL zu dem CSS extern ist. Das habe ich getan, weil immer wieder Leute von irgendwelchen Trollen via URL Shortener verarscht wurden. Einbinden von externen CSS funktioniert immer noch, aber halt nur temporär.
Übrigens, Pro-Tipp, wenn ihr externes CSS hostet: bietet das auch per SSL an, damit es auch mit der SSL-Version des Blogs funktioniert.
Ich prüfe da nicht viel, im Wesentlichen will ich, dass das Opcode-Byte sagt, dass es ein Handshake ist, und dass die TLS-Version gültig aussieht, und dass die Länge des Handshake-Paketes nicht größer als 256 ist. Warum 256? Weil das nach damaligen Verhältnissen exorbitant viel war und weil 256 in Binärdarstellung ein 1-Byte in der höherrangigen Hälfte des Längenfeldes war, was sich dann leicht testen ließ.
Was jetzt passiert ist, ist dass Chrome so viel Bloat mitschickt, dass bei denen 0x200 als Länge im Header steht, also 512. Wir erinnern uns: Chrome, das waren die Leute, die wegen des angeblichen HTTP-Header-Bloats ein eigenes Konkurrenzprotokoll namens SPDY erfunden haben, das so super toll optimiert ist, dass für die zwei e kein Platz mehr im Namen war. DIE Leute haben jetzt ihr SSL-Handshake soweit aufgebläht, dass es in meinen Sanity-Check rannte.
SPDY basiert übrigens auch auf SSL.
Einmal mit Profis arbeiten!
Update: Vier der Extensions sind so neu (oder Google-proprietär?), dass Wireshark sie noch nicht kennt.
Update: Es gibt eine Erklärung, wieso der SSL-Header so groß ist. Das ist kein Bloat, sondern die machen das absichtlich, um um eine ranzige F5-Firmware herumzuarbeiten. m(
Erschwerend hinzu kam, dass die Seite dann ziemlich sofort unter der Last zusammenbrach (warum eigentlich?).
Die Fakten liegen immer noch nicht auf dem Tisch, aber so langsam scheint halbwegs Konsens zu bestehen, dass da irgendein Ermittlungsverfahren gegen irgendjemanden läuft, weil sie diese Daten gefunden haben. Daher wollen sie nicht sagen, woher sie die haben.
Ich stelle mir das so vor. Das BSI wird von einer Firma oder Behörde angerufen, weil die ein Botnetz bei sich gefunden haben. Die kommen und finden beim Stochern diese Daten. Was tun? Nun könnte man natürlich die Email-Adressen alle anschreiben, aber wer glaubt denn seit dem Bundestrojaner noch Emails von Behörden?
Diese Webseite jetzt ist aus meiner Sicht Ass Covering. Da geht es nicht darum, Leuten zu helfen. Denn Leute, die sich um ihre Sicherheit genug Sorgen machen, dass sie von der Existenz so einer Webseite erfahren, und dann da hingehen und damit interagieren, sind vermutlich eh nicht betroffen. Ich verwende z.B. eine eigene Email-Adresse pro Webseite, die meine Email-Adresse haben will — und natürlich jeweils ein anderes Passwort. Soll ich die jetzt alle beim BSI eingeben? Ich mache das ursprünglich, um zu erkennen, woher Spammer Email-Adressen haben, aber es hilft natürlich auch prima gegen solche Account-Datenbanken. Da ist dann jeweils nur der eine Account gehackt, das Passwort funktioniert nirgendwo anders.
Dazu dann das Verfahren, das die das wählen. Man kriegt die Antwort nicht direkt sondern man kriegt einen Code und später eine Email, wenn man betroffen war. Wenn man nicht betroffen war, kriegt man keine Email. Das BSI scheint zu glauben, dass davon auch die Umkehrung gilt: Wer keine Email kriegt, war nicht betroffen. Aber das ist natürlich Blödsinn, Emails können verloren gehen, im Spamfolder landen, versehentlich gelöscht werden, etc. Oder wenn die Credentials gehackt waren und auch für den Email-Provider gelten, kann jemand mit den Daten natürlich auch die Email vom BSI löschen, bevor das Opfer sie sieht. Und die Email ist im Gegensatz zu der SSL-Verbindung, über die man die Daten einschickt, nicht verschlüsselt und signiert, d.h. wenn da eine Mail kommt, gibt es keinen Grund, der zu trauen. Den Code hätte auch jemand raten können. Kurz: Die Aktion ist voll für den Fuß. Das BSI tut das daher aus meiner Sicht nur, weil sie glauben, irgend etwas tun zu müssen.
Besonders absurd mutet die Meldung von heute an, dass das BSI seit Dezember auf den Daten saß, aber so lange brauchte, weil sie wirklich sicher gehen wollte, dass ihre Webseite den Ansturm aushalten würde. Was sie dann nicht tat.
Einmal mit Profis arbeiten!
Update: Die Webseite heißt übrigens www.sicherheitstest.bsi.de und liegt bei Strato. Ohne jetzt irgendwie Strato bashen zu wollen, aber … srsly, BSI? Das konntet ihr nicht selber hosten? So sieht das aus, wenn jemand per DNS-Hijacking Domains umlenkt. Übrigens liegt die BSI-Webseite nicht nur in einem anderen Netz (das dem BSI gehört), sondern sie benutzt auch eine andere Domain. Viel mehr Indizien für "hier riecht was schlecht, hier geb ich lieber keine Daten ein" hätte man auf die Schnelle gar nicht ankreuzen können. Oh, doch, eine noch. Das SSL-Zertifikat kommt bei der BSI-Homepage von Trustcenter, und beim Sicherheitstest von T-Systems. NA SUPER. Vertrauenswürdiger geht es ja kaum!1!!
Update: Anscheinend soll die Rück-Email PGP-signiert sein. Wozu brauchen sie dann den Code, wenn sie PGP haben? Weil niemand einen Grund hat, einem angeblichen BSI-Key zu vertrauen, der vor sechs Wochen erzeugt wurde?
Update: Wo wir gerade bei T-Systems waren… guckt mal, was da auskommentiert im HTML steht:
<div style="padding-top:20px;padding-bottom:20px;">Und hier ist das Bild. Ja, das hätte ich auch lieber auskommentiert an deren Stelle *schenkelklopf* :-)
<!--<img src="/static/images/vl_powered_by_T.png" />-->
Update: Ah, sie haben auch ihren öffentlichen PGP-Schlüssel auf ihrer HTTP-Webseite. Immerhin. Ich sehe trotzdem nicht, wieso sie da überhaupt Email machen und nicht direkt per Web antworten. Das schafft doch nur zusätzliche Metadaten.
Update: Der PGP-Schlüssel ist vom 9.12., das SSL-Zertifikat ist vom 17.12. Da kann man mit ein bisschen Fantasie die Denkprozesse verfolgen.
Hey, Cheffe, wir haben hier echt viele Email-Adressen, was machen wir jetzt?
Wir schreiben denen ne Email!
Ja, aber Cheffe, seit dem BKA-Trojaner glaubt unseren Emails doch keiner mehr!
Dann signieren wir die halt mit PGP!
OK, Cheffe, hab nen Schlüssel gemacht, aber wieso sollten die Leute dem denn vertrauen? Ich hätte Frau Merkel gebeten, uns den zu signieren, aber die hat kein PGP!
Na gut, dann machen wir dazu ne Pressemitteilung und machen einen Webserver auf und da tun wir den Schlüssel hin!
Aber Cheffe, unser Webserver hält doch nichts aus, wir benutzen doch Java!
Ja, äh, hmm, na löse das halt irgendwie!1!!
OK, Cheffe, ich hab jetzt bei Strato nen Webserver geklickt, aber wir brauchen auch SSL, sonst lachen die Leute doch wieder über uns!
Hmm, also über unseren normalen Amtsweg braucht das 4 Monate. Frag mal Strato, ob die nicht auch SSL mit verkaufen können!
OK, Cheffe, hab ich gemacht, alles in Ordnung!1!!
Update: In den Mails an Betroffene steht, dass die Daten bei einem Botnet gefunden wurden. Jemand hat mir ein Zitat aus so einer Mail geschickt.
Update: Der Code steht bei den PGP-Mails übrigens im Subject, also im nicht signierten Header-Bereich.
Ich habe schonmal fürs Blog meine Vorsätze fürs neue Jahr umgesetzt: Der spricht jetzt auch ECDH und lässt kein SSLv3 mehr rein. Der Anteil des SSL-Traffics liegt übrigens bei ca 5%, was ich ziemlich beschämend finde. Ich hätte gedacht, dass mehr Leute die Dienste ärgern wollen, wenn auch bei den eh öffentlichen Inhalten auf meinem Blog eher symbolisch. Zum Vergleich: IPv6 liegt bei über 10%.
Es war für mich ein sehr schöner Congress, wenn nicht gar der schönste bisher.
Sehr lobenswert!
Im Detail gibt es da ein paar Punkte, die man kritisieren kann. Sie haben einen PGP-Schlüssel, das ist wunderbar, aber sie haben keine SSL-Version ihrer Webseite, über den man den sicher runterladen kann. Der Schlüssel ist 2048 Bit lang, das ist OK. Der Schlüssel ist auch auf den Keyservern. Das mit dem SSL sollten sie noch machen, und eigentlich sollten sie auch gleich ein per SSL erreichbares Upload-Fach einrichten, damit man Dokumente aus einem Internet-Cafe abwerfen kann, ohne Kontaktdaten zu hinterlassen.
Das im Zweifelsfall auf einen USB-Stick zu tun und per Post zu schicken ist ein guter Ratschlag. Allerdings hinterlässt man dann möglicherweise auf oder an dem Stick Spuren. Alte gelöschte Dateien, Fingerabdrücke, DNA, etc. Für Daten wie die Snowden-Files wäre das nichts, außer man will danach einen Snowden pullen und sich öffentlich bekennen.
Trotzdem: Guter Schritt, liebes Nachrichtenmagazin!
Update: Noch ein Hinweis: Die Sortiermaschinen bei der Post rupfen reihenweise USB-Sticks aus Briefen. Daher ein Kouvert mit Polsterung nehmen, oder auf einem Stück Pappe festkleben oder so.
Lawyer: "Are you familiar with public key encryption?"Und dann versucht der Anwalt des Patenttrolls ernsthaft, Diffie anzupinkeln, dass ja in Wahrheit jemand anderes Public Key Crypto erfunden habe, nämlich die GCHQ-Forscher, deren Arbeit geheim blieb. Lustigerweise ist deren Kram ja inzwischen öffentlich. Die hatten zwar die Idee, man könnte den Schlüssel aufsplitten, aber hatten kein Schema, kein Protokoll, nichts. Zu sagen wegen deren Arbeit seien Diffies Ansprüche hinfällig ist wie wenn man sagt, Gene Roddenberry habe Reisen mit Überlichtgeschwindigkeit erfunden.Whitfield Diffie: "Yes, I am"
"And how is it that you're familiar with public key encryption?"
"I invented it."
Accepted SSLv3 128 bits RC4-SHA
Accepted SSLv3 128 bits RC4-MD5
Accepted TLSv1 128 bits RC4-SHA
Accepted TLSv1 128 bits RC4-MD5
Weiß das BSI etwas, das wir nicht wissen? Oder war da nur mal wieder einer der BESTEN der BESTEN der BESTEN am Start? (Danke, Steffen)
Update: Mit Metadaten ist hier eine Trafficanalyse gemeint.
pub 4096R/A534A9C6 2013-10-03Ich habe ihn mit meinen alten, noch herumfliegenden Schlüsseln signiert. Wenn ihr also einen meiner alten Schlüssel signiert oder unabhängig validiert habt, signiert bitte auch den neuen und ladet die Signatur bei den PGP-Keyservern hoch. Die Infrastruktur stinkt leider ziemlich bei PGP. Ich bitte darum, die alten Keys nicht mehr zu verwenden; die Schlüssellängen sind nicht mehr zeitgemäß.
Key fingerprint = 2DEC 3301 51BB 9F7D AD8B 0BDC FC32 CEEC A534 A9C6
uid Felix von Leitner <felix (at) fefe.de>
sub 4096R/530FBDF3 2013-10-03
Den Schlüssel kann man auch bei mir per https runterladen, aber wegen des schlimmen Zustands der Validierung bei X.509-Zertifikaten ist damit natürlich keine Gewähr verbunden. Möglicherweise reicht es aber dem einen oder anderen von euch trotzdem als Indiz, um dem Schlüssel zu vertrauen.
Ich werde demnächst wohl auch mal einen neuen SSL-Schlüssel mit 4096 Bit machen.
Update: Auf den Keyservern kursiert auch ein Schlüssel C18AE64E mit meinen Daten (aber ohne die Signaturen, versteht sich). Der ist nicht von mir.
Die schlechte: RSA BSAFE benutzt das als Default-RNG. Und nicht nur die, NIST hat eine Liste. Cisco, Apple, Juniper, McAfee, Blackberry, … bei den meisten wird das allerdings nicht Default sein.
Die gute Nachricht: BSAFE wird von keiner freien Software eingesetzt. Wenn ihr also Firefox unter Linux einsetzt, seid ihr sicher.
Ich bin mir gerade nicht sicher, wie das unter Windows ist. Da gibt es ein TLS vom System namens "SChannel". Das wird meines Wissens u.a. von IE und Chrome verwendet. Benutzt der BSAFE? Vermutlich. Es gab mal eine Zeit, da konnte man RSA und co gar nicht ohne BSAFE legal einsetzen in den USA, aus Patentgründen. Das müsste mal jemand herausfinden, wie das ist, und ob Windows den NSA-RNG einsetzt.
OpenSSL ist auch auf der Liste, aber die haben schon angesagt, dass sie das nur implementiert haben, weil ihnen jemand dafür Geld gegeben hat, und das ist nur an, wenn man den FIPS-Modus aktiviert, von dem sie im Übrigen dringend abraten und was nicht der Default ist.
Dieses Problem betrifft die ganzen MIPS-Linux-basierten Plastikrouter da draußen. SSL oder VPN oder so besser lieber nicht damit machen.
Update: Und die WLAN-APs natürlich, das fasste ich mal unter Plastikrouter zusammen.
Erstens: "Known Plaintext" heißt die Angriffsart, bei der der Angreifer sowohl den Klartext als auch die verschlüsselten Daten hat und daraus den Schlüssel errechnen will. Intuitiv würde man denken, dass das total einfach sein muss, dann den Schlüssel zu errechnen. Bei antiken Verfahren ist das auch so, bei modernen nicht. Die von Truecrypt verwendeten Verfahren haben allesamt die Eigenschaft, dass bei ihrem Design darauf geachtet wurde, dass das nicht signifikant leichter geht, als mögliche Schlüssel durchzuprobieren.
Dann: Durchprobieren. Die Kryptographie geht schon immer davon aus, dass der Gegenüber über unbegrenzte Geld- und Material-Möglichkeiten verfügt und über das beste Know-How, das es auf der Welt gibt. Überspitzt gesagt, ist das Modell des Gegenübers, vor dem wir uns mit Kryptographie schützen wollen, die NSA. Schon immer. Unter der Annahme, dass sie Roswell-Technologie reverse engineered und im Einsatz haben. Verfahren werden grundsätzlich mit so großen Sicherheits-Margen versehen, dass selbst unter pessimistischsten Annahmen (und Kryptographien sind ausgesprochen pessimistisch, wenn es um die NSA geht) noch genug Raum für ein paar Jahrzehnte stetig schneller werdende Hardware drin ist. Die NSA hat über die Jahre mehrere Anläufe genommen, um Krypto-Standards mitzudefinieren. Weil allen anderen Beteiligten völlig klar ist, was die Kernaufgabe der NSA ist, traut denen grundsätzlich genau niemand über den Weg. Man lässt die dann ihren Standard machen, aber niemand benutzt ihn. Die Angriffe, über die man beim Diskutieren von Verfahren redet, sind daher nicht in der Liga "das wäre aber sehr teuer" sondern in der Liga "das würde so lange dauern, dass die Erde vorher in die Sonne stürzen wird". Hier rechnet das mal jemand für 256-Bit-Schlüssel aus.
Es hat sich daher aus meiner Sicht nichts geändert bei der Kryptographie. Wo sich etwas geändert hat, ist bei der Frage, wo man seine Krypto-Software eigentlich her hat, und ob man dem trauen kann. Aus meiner Sicht ist es jetzt an der Zeit, dass sich mal die Hacker der Welt zusammen tun, und in aller Ruhe und mit größter Sorgfalt die ganze Krypto-Software da draußen auditieren. Eine wirklich gute Hintertür sieht man bei einem Audit auch nicht notwendigerweise, aber wann soll man sowas denn bitte in Angriff nehmen wenn nicht jetzt? Ich für meinen Teil habe mir ja seit einigen Jahren vorgenommen, mal eine SSL-Library zu schreiben. Einen X.509-Parser habe ich schon, aber die ganzen Cipher und so noch nicht. So viel Arbeit ist das nicht, aber ich bin halt Hacker und kein professioneller Kryptograph und mache mir da natürlich Sorgen, einen subtilen Fehler zu machen, der dann meine Benutzer kompromittieren würde. Das (und die Komplexität der Sache) hat mich bisher davon abgehalten, das mal "einfach zu machen".
Übrigens, falls jemand mal sehen will, wie so NSA-Einflussnahme in der Praxis ausschaut: Dieser Thread hier scheint in der Hinsicht zu liefern. Die Sache mit IPsec ist seit Jahren bekannt, das Paper von Bruce Schneier ist von 2003.
Übrigens, der von der NSA unterwanderte Krypto-Standard, der in der New York Times erwähnt wird, ist wohl Dual EC DRBG.
Update: Übrigens forschen auch seit Jahren schon Leute daran, wie man weiter Daten verschlüsseln kann, wenn Quantencomputing eine Realität wird.
The document reveals that the agency has capabilities against widely used online protocols, such as HTTPS, voice-over-IP and Secure Sockets Layer (SSL), used to protect online shopping and banking.Und auch eine andere Verschwörungstheorie wird endlich bestätigt.A more general NSA classification guide reveals more detail on the agency's deep partnerships with industry, and its ability to modify products. It cautions analysts that two facts must remain top secret: that NSA makes modifications to commercial encryption software and devices "to make them exploitable", and that NSA "obtains cryptographic details of commercial cryptographic information security systems through industry relationships".
Erstens ist es unglaublich, dass die bisher noch kein STARTTLS hatten. Das RFC dazu ist 14 Jahre alt! Soll das ein Witz sein?! JETZT rollen die das aus? Und tun auch noch so, als sei das ein bewerbenswertes Feature?!? Das ist wie wenn VW damit Werbung machen würde, dass sie jetzt auch Sicherheitsgurte mitliefern. WTF?
Und dann: STARTTLS basiert auf SSL und X.509, aber ohne Nutzer-Interaktion. Damit fallen Dinge wie manuelle Zertifikats-Prüfung weg. Was macht man, wenn man sich wohin verbindet, und das Zertifikat ist von einer CA unterzeichnet, die man nicht kennt? Zurückschicken? Doch zustellen? Mit anderen Worten: Das ist zwar ein kleines Bausteinchen, aber das jetzt als die große Security-Infrastruktur zu bewerben, das ist mehr als unehrlich.
Und im Übrigen ist das natürlich eh alles Schlangenöl. Solange die Verschlüsselung nicht Ende-zu-Ende ist, kann das BKA zum Provider gehen und die Mail lesen. Oder der BND. Oder irgendjemand, der sich da reinhackt. Der Verfassungsschutz. Ein schlecht gelaunter Admin dort.
Und überhaupt, dass ausgerechnet die Telekom als Ausgliederung der Post jetzt einen auf "eure Sicherheit ist uns wichtig" macht, das finde ich unerträglich.
Update: Die Krönung an der Geschichte ist, wie sich der Friedrich darüber freut, dass seine alten Kumpels von der Telekom dafür sorgen, dass die Kunden glauben, sie kriegten Verschlüsselung, aber die "Bedarfsträger" immer noch an alle Mails rankommen.
Mit dieser Verschlüsselung werden die Zugriffsmöglichkeiten Unberechtigter weiter erschwert.
Die "Berechtigten" kommen natürlich immer noch an alles ran. Oh und natürlich weist er darauf hin, dass die Berechtigten gerne noch mehr Hilfestellung von euch Abhöropfern haben wollen. Im Moment, wenn man so eine Mail abschnorchelt, kann man sich nicht sicher sein, wer die wirklich geschrieben hat. Daher seid doch bitte so liebenswert und macht da eine digitale Signatur drunter!
Darüber hinaus aber bietet die De-Mail den Vorteil einer eindeutigen Identifizierung von Absender und Empfänger
Sobald man einen E-Mail-Account auf dem Telefon einrichtet, kann man auf seinem Mailserver erfolgreiche Verbindungsversuche für IMAP und SMTP von der Adresse 68.171.232.33 sehen, und zwar mit dem Username und Passwort des Accounts, den man gerade eingerichtet hat.Wenn man nicht Zwangs-SSL eingeschaltet hat auf dem Mailserver, dann werden die Accountdaten im Klartext via NSA und GCHQ geroutet.Die Adresse gehört zum Netzbereich von Research In Motion, kurz RIM, der Herstellerfirma der Blackberry-Telefone in Kanada.
Ich würde das ja zum Bug des Tages küren, aber ich glaube nicht, dass das ein Bug ist. Die machen das absichtlich. Völlig unakzeptabel. Für mich ist das die Kategorie Fehler, von der sich eine Firma wie RIM nie wieder erholen kann. Es ist egal was die tun, ich werde von denen nie etwas kaufen.
Update: Nokia macht das auch, wird mir gerade versichert. zusätzlich zu dem Web-Traffic ihrer Kunden. Deren Produkte waren ja eh schon unkaufbar deswegen.
Hier gehen gerade verzweifelte Mails ein, ob sich der Einsatz von PGP denn überhaupt lohne, wenn man davon ausgehen müsse, dass das Windows darunter Hintertüren hat. DAS IST GENAU DER PUNKT. Es gibt Alternativen. Das hat viel Schweiß und Mühe gekostet, die soweit zu bringen, dass man mit ihnen arbeiten kann. Muss man sich dabei etwas zurücknehmen gegenüber polierten kommerziellen Systemen? Kommt drauf an. Ich als Softwareentwickler empfinde eher Arbeiten unter Windows als zurücknehmen. Grafikdesigner werden das möglicherweise anders erleben.
Aber dass wir überhaupt eine Infrastruktur haben, in der die Dienste sich gezwungen sehen, bei Google und Microsoft die entschlüsselten Daten abzugreifen, weil wir internetweit Verschlüsselung ausgerollt haben, das ist ein großer Sieg. Klar ist das alles immer noch nicht befriedigend. Schöner wäre es, wenn das Internet eine Blümchenwiese wäre. Aber wir haben es geschafft, dass man, wenn man will, gänzlich ohne Software-Hintertüren arbeiten kann. Wie weit man dabei gehen will, hängt natürlich von jedem einzelnen ab. Aber zur Not kann man heutzutage auch sein BIOS als Open Source haben.
Natürlich können auch in Linux und OpenBIOS theoretisch Hintertüren sein. Das liegt an jedem von euch, sich da genug einzulesen, um seinen Teil mitzuhelfen, die Wahrscheinlichkeit dafür zu senken. Muss man dann natürlich auch tun. Die Software kann man zwar kostenlos runterladen, aber man zahlt dann eben auf andere Art. Indem man sich einbringt.
Kurz gesagt: Dass wir überhaupt ein Gegenmodell zu "alle setzen walled garden backdoored NSA-technologie ein" haben, das ist ein immenser Sieg, der in den 80er Jahren, als diese ganzen Geschichten hochblubberten, wie ein feuchter Fiebertraum wirkte. Wir haben immens viel geschafft. Es liegt an uns, das konsequent einzusetzen und konsequent weiterzuentwickeln. Und es ist eure verdammte Pflicht, nachfolgenden Generationen dieses Stückchen Hoffnung zu erhalten. Helft mit!
Update: Um das mal ganz klar zu sagen: Linux einsetzen und Verschlüsseln ist keine Lösung für alles. Per Trafficanalyse wissen die immer noch, wer wann mit wem geredet hat. Nur nicht mehr notwendigerweise worüber. Das sehen die nur, wenn einer der Gesprächsteilnehmer Hintertüren im System hatte oder das dann auch auf Facebook oder Twitter rausposaunt oder bloggt. Open Source ist ein Werkzeug, nicht die Lösung. Ihr müsst auch euer Verhalten entsprechend ändern.
Ich habe also ein paar Abhilfen implementiert, um das zu beschleunigen. Die selben Dinge, die ich auch im Blog implementiert habe, im Wesentlichen. Ich sende einen Date-Header, einen Last-Modified-Header, und beantworte If-Modified-Since-Header. Chrome war unbeeindruckt. Ich habe dann zum Testen einen Expires-Header in der Zukunft eingefügt, und das hat auch nichts gebracht. Jetzt glaube ich, die Erklärung gefunden zu haben: Chrome cached keine Seiten über SSL mit "ungültigem" Zertifikat. Dazu gehören alle Zertifikate, bei denen die rote Warnseite kommt, die man wegklicken muss. Aber selbst wenn man die wegklickt, schmeißt Chrome alle Daten nach dem Anzeigen weg und cached nichts, auch nicht temporär nur im RAM.
Wenn also einer von euch bei meinem Blog aus Faulheit (nicht aus anderen, möglicherweise validen Gründen) das Root-Zertifikat von cacert.org nicht importiert hat, und stattdessen immer die rote Warnseite wegklickt, dann erzeugt das bei meinem Blog unnötigen Traffic. Ich bitte diejenigen, lieber das Root-Cert zu importieren. Und wenn einer von euch bei Chrome mitarbeitet, fände ich es prima, wenn ihr da mal Stunk machen könntet. Das Verhalten ist nicht akzeptabel. Das nicht auf Platte zu speichern ist OK, aber das nicht mal in der History im RAM zu halten ist in meinen Augen nicht zu verteidigen.
Einmal mit Profis arbeiten!
Update: Die Android-Mail-App scheint auch sonst eher apokalyptisch schlecht zu sein. Au weia.
Update: Die Sudo-Sprallos veröffentlichen ernsthaft keine PGP-Signaturen für ihre Releases?!? Au weia.
Update: Oh und wo wir gerade bei peinlichen Bugs waren: Ubuntu fixt einen Buffer Overflow in cfingerd. Wo kommt der Bug her? Aus einem Ubuntu-Patch für cfingerd. Erinnert ein bisschen an das OpenSSL-Dingens damals.
Update: Ich höre gerade, dass OS X auch zu den Kinderunixen zählt, wo man ohne Superuserrechte die Systemzeit ändern kann. Und da steht "der User" auch im sudoers-File.
Das ist der fehlende Puzzlestein.
Google bietet seit einer Weile DNS für alle an, und in den USA auch in manchen Gegenden Glasfaser-Internet. Mit dem DNS und dem Glasfaser-Internet können sie ihre Benutzer umlenken, und mit der eigenen CA können sie per Man-in-the-Middle das SSL mitlesen oder manipulieren.
Bisher gibt es natürlich keine Hinweise darauf, dass sie das auch tun. Aber aus meiner Sicht ist da eine Linie überschritten. Wer deren DNS-Service benutzt, sollte sich das nochmal genau überlegen. Da bieten sich sehr gruselige Möglichkeiten jetzt.
Das selbe gilt natürlich auch für alle anderen ISPs und DNS-Server-Betreiber, die eine eigene CA haben. Die Telekom z.B. Vor deren CA hab ich ja auch schon mal gewarnt hier.
Viele von diesen paranoiden Szenarien haben wir uns immer damit wegdiskutiert, dass man da SOO viel Einfluss haben müsste, man müsste sowohl DNS manipulieren können als auch eine CA in alle Browser kriegen, oder vielleicht gar gleich dem User einen neuen Browser unterschieben. Google macht das alles heute einfach.
VR-Protect sieht aus und funktioniert wie ein normaler Browser. Der besondere Unterschied: Er lässt nur wenige vertrauenswürdige Seiten zu, nämlich die Seiten der Bank des Nutzers.Welche Plattformen unterstützen sie? Steht da nicht. Klingt nach "Windows only".
Nun könnte man mit so einem Spezialbrowser tatsächlich was reißen, wenn man die IPs und die SSL-Zertifikate der Bank fest einbrennt. Davon steht da aber nichts. Und das hätte natürlich auch Nachteile. Dafür soll der Browser sich selbst updaten können. Na DANN ist ja alles gut, da kann ja so gut wie NICHTS schiefgehen!1!! Erwähnte ich, dass man den von CD starten soll? Das Autoupdate brennt dann ne neue CD heraus oder wie? Und woher weiß der Benutzer, dass das Update echt ist und kein Trojaner? Wie hilft dieser Spezialbrowser dagegen, dass ein Trojaner die Tastatur mitsnifft? Gar nicht vermutlich.
Kurzum: aus meiner Sicht sieht das aus wie eine windige PR-Maßnahme. Von Leuten, die es besser wissen sollten. Aber das nicht tun, wie man z.B. an diesem Abschnitt hier gut sehen kann:
Jede Bank erhält ihren eigenen Browser. Selbst wenn also eine Browserversion gecrackt würde, sind doch alle anderen Bank-Versionen davon nicht betroffen und der Angriff wird ökonomisch unsinnig."Gecrackt"? m(
Update: Habe ein paar Details in Erfahrung bringen können. Das Ziel von diesem Browser ist anscheinend, die momentan verbreiteten Banking-Trojaner auszuschalten. Dafür haben sie da Arbeit investiert, um den Browser für die verbreiteten Manipulationsmethoden weniger anfällig zu machen. Mit meiner "Windows Only"-Vermutung lag ich wohl richtig. Aus meiner Sicht hat man verloren, wenn man von Schadcode-Befall ausgeht. Das kann man mit solchen Browser-Tricks ein bisschen schwieriger machen, und hoffen, dass die Trojaner dann lieber die anderen Banken angreifen, aber letztendlich halte ich es für nicht seriös, da große Versprechungen zu machen. Ich versuche weiterhin die oben genannten Details rauszufinden, mal gucken was da noch so reinkommt.
Update: Hier kommen noch ein paar Details. Plugins, Toolbars und co sind per CLSID-Whitelist verboten, es wird nicht Wininet benutzt, die URLs und IP und SSL-Zertifikate der Bank sind per Whitelist festgenagelt. Wenn das stimmt dann haben sie da soweit alles rausgeholt. Man kann sich immer noch streiten, wie viel man davon erwarten kann, und der Teufel steckt wie immer in den Details. Aber es sieht nicht mehr ganz so vollständig sinnlos aus wie es die Presseerklärung vermuten ließ.
TURKTRUST told us that based on our information, they discovered that in August 2011 they had mistakenly issued two intermediate CA certificates to organizations that should have instead received regular SSL certificates.Das ist wie wenn man zur Bank geht, Geld abheben, und die Bank drückt einem stattdessen eine Gelddruckmaschine mit unbegrenzt Spezialpapiervorrat in die Hand. Un-glaub-lich!Oh und wisst ihr was, ich habe TÜRKTRUST hier sogar schon mal explizit namentlich erwähnt. Als ich erklärt habe, wieso dieser ganze SSL-Kram kaputt ist. *Seufz*
Das ist schon deshalb sportlich, weil DNSSEC bei den Kryptoprimitiven immer etwas hinterherhinkt. Die haben 2048 Bit RSA-Schlüssel erst Jahre später spezifiziert, nachdem die paranoideren Leute das schon für ihr SSH und PGP und SSL ausgerollt hatten.
Bei DNSSEC war daher Designentscheidung, dass die privaten Schlüssel gar nicht erst im Server stecken sollen. Man signiert seine Zonen off-line und lädt dann die signierten Zonen zum Server hoch. Selbst wenn jemand den Server hackt, kann er den Schlüssel nicht klauen, weil der nicht auf dem Server ist.
Die Idee ist natürlich, dass der Schlüssel gar nicht am Internet hängt. Jetzt stellt sich aber raus: das mit dem off-line, das ist so unhandlich, wir machen das lieber online!1!! Damit das automatisierbar ist. Bei einer TLD wie .de oder .ch kommen ja auch im Sekundentakt Änderungen rein. Da muss dann jeweils neu signiert werden. Da erhöhen sich dann natürlich die Anforderungen an das Hosting entsprechend. Immerhin könnte die Sicherheit der ganzen Welt auf diesem DNSSEC ankern.
Wie wird das denn dann am Ende gehostet? Hier gibt es Webcams. Das ist ein kleiner Server in einem Safe, in einem Safe. Mit klein meine ich den Stromverbrauch, denn Abwärmeabtransport ist ein bisschen schwierig, könnt ihr euch ja vorstellen. Alleine von der "Alien Power Source"-Optik her ein echter Sieger, dieses Hosting. Oh und der Schlüssel ist nicht auf dem PC sondern auf einem separaten sicheren Hardwaremodul. Wenn jemand die Kiste hackt, kann er zwar Änderungen signieren, aber er kann nicht den Schlüssel extrahieren. Nachdem der Hacker gefunden und rausgeschmissen wurde, kann er nichts mehr signieren. Er kann natürlich immer noch anderen Leuten seine vorher signierten Falschdaten unterschieben. Dazu sagt die DNSSEC-Spec: Aber, äh, *räusper* *aufdieuhrguck* oh schaut mal, schon sooo spät *wegrenn*
Oh, übrigens. Wie bindet man so ein Hardwaremodul an? Per IP über Ethernet! Genau wie den Rechner selbst. Auf dem läuft übrigens Linux, der ist also unhackbar!1!!
Noch ein paar Zahlen: der Rechner verbraucht so 30W, und die LEDs draußen auch noch mal so viel :-)
Update: Solange die Site down ist, könnt ihr euch ja die Folien hier angucken, die haben noch ein paar Details zu dem Setup.
Was für ein Anfängerfehler.
Update: HAHAHAHA, der eigentliche Kracher ist, dass Mark Dowd das schon 2006 in einem Buch erwähnt hat (Beleg) :-)
Das weltweite Internet bietet alle Voraussetzungen, um die in den ersten zehn Artikeln unserer Verfassung verankerten Grundrechte aller Bürger in diesem Land auszuhöhlenWait, what?!
Das gilt insbesondere für das Recht auf freie Meinungsäußerung und Pressefreiheit in Artikel Fünf — eine wesentliche Grundlage unserer funktionierenden Demokratie — und es gilt letztlich auch für den Kernsatz unserer Verfassung, den Artikel Eins des Grundgesetzes: Die Würde des Menschen ist unantastbar.Hat jemand dem Gauck mal gezeigt, wie so ein Internet aussieht? Man kann ja viel sagen über das Internet, aber dass es die Pressefreiheit oder das Recht auf freie Meinungsäußerung einschränkt, das ist ja nun wirklich das exakte Gegenteil der Realität. WTF? Haben die da keinen Lektor bei der Post? Wie können die ihn denn so einen Mumpitz im Vorwort schreiben lassen? Der arme alte Mann macht sich da doch gerade lächerlich!
Es geht bei der Demo darum, dass das Opfer bei Google Maps rumklickt — über SSL. Aber dass man, wenn man gut vorbereitet ist, aus der Größe der gezogenen Kacheln sehen kann, wo auf der Welt der gerade herumklickt.
Falls ihr also mal jemandem erklären wollt, wie schlimm das mit dem Datenschutz im Internet wirklich ist (und wieso ich immer mein Laptop per Kabel anschließe und nicht per Wifi), dann ist dieser Blogpost vielleicht ein guter Ansatz.
Das hat soviel Eindruck gemacht, dass es jetzt plötzlich cool und hip ist, gegen SOPA zu sein, dass Google, Amazon und Facebook angeblich über ein Protest-Selbstabschalten nachdenken und sogar Nintendo, EA und die Videospielsparte von Sony ihren SOPA-Support zurückgezogen haben. Jetzt nach Weihnachten haben die eh erst mal Flaute, und das will sich wohl keiner leisten, die paar Käufer wegen sowas zu verlieren.
So schön das aussieht, so klein ist in meinen Augen der Sieg hier. Denn SOPA ist ja nur eines in einer langen Reihe solcher Gesetze. Nächsten Monat kommt dann bestimmt die nächste Iteration.
Aber hey, Siege soll man feiern wie sie kommen. In diesem Sinne: Hoch die Tassen!
Vielleicht kommt ja auch bei unseren "Netzpolitikern" die Botschaft an.
Update: Hahaha, auch bei den Spieleherstellern war der Rückzug nur geheuchelt.
Dabei ist so ein typischer Internetausdrucker-Fehler!
Update: Oh und was das Feld "Common Name" in SSL-Zertifikaten bedeutet, das muss ihnen offensichtlich auch nochmal jemand erklären.
Update: OK, hat jemand angefasst, vorhin stand da der Name des Admins im CN.
Theorien und Vorschläge nehme ich gerne per Email entgegen. Im Moment tendiere ich zu "die haben ihre LI-Software von Digitask gekauft und die spackt jetzt halt herum" :-)
Update: Bei diversen Leuten geht es offenbar problemlos.
Update: Es gibt einen Schuldigen. CACert hat offensichtlich gerade einen OCSP-Fuckup. Wenn Firefox bei denen eine OCSP-Anfrage für mein Cert stellt, kriegt er ein "403 Access Forbidden" zurück. Mit anderen Worten: Chrome macht kein OCSP. m( Man kann OCSP auch in Firefox ausschalten (security.OCSP.enabled = 0), aber an sich will man ja OCSP haben. Dieses SSL ist echt ein Haufen Sondermüll. Macht Firefox bei jedem Zugriff einen OCSP-Request oder nur einmal pro Tag? Man fragt ja ein spezifisches Zertifikat an, das hieße ja, dass CAcert ein Bewegungsprofil erstellen kann. Mann ist das alles für den Fuß.
Update: Mir mailt gerade jemand: Firefox prüft einmal pro Session, und Chrome macht doch OCSP aber macht daraus keinen Timeout sondern zeigt dann ein kleines gelbes Dreieck als Warnung an.
Und heute: GlobalSign zieht die Notbremse, stellt Zertifikatsverkauf ein, startet Monster-Audit.
Wir sind jetzt also soweit, dass man mit Pastebin CAs runterfahren kann :-)
DigiNotar geht einen anderen Weg. Hier ist ihre Presseerklärung. Und das ist Comedy Gold, sage ich euch! Nicht nur behaupten sie, die Zertifikate gar nicht ausgestellt zu haben, nein, sie pullen die "wir wurden gehackt!1!!"-Karte. Nun ist die Ansage, als CA, dass man gehackt werden kann, natürlich der ultimative Totalschaden. Das ist wie bei RSAs Tokens. Niemand bei Verstand kauft jemals wieder bei einem solchen Anbieter. Die ehrenhafte Variante wäre, gleich direkt ganz zuzumachen. Aber soviel Arsch in der Hose hat halt niemand.
Inhaltlich ist diese Presseerklärung der Lacher. Sie sagen erst, dass sie im Juli gemerkt haben, dass sie ein Zertifikat für google.com rausgerückt haben. Sie haben reagiert, indem sie die Zertifikate zurückgezogen haben. Das ist ja an sich ein Kapitel an sich, SSL-Zertifikate-Zurückziehen. Aus meiner Sicht ist das zum Gutteil Augenwischerei.
Nächster Schritt: ein externer Audit hat bestätigt, dass sie alle Zertifikate erwischt haben. Und dann taucht noch ein Zertifikat auf. Mit anderen Worten: ihr Audit war für den Arsch. Man kann sich also nicht auf ihre Security verlassen und auch nicht auf ihren externen Audit-Dienstleister.
Spätestens hier ist Totalschaden. Was tun sie als nächstes? Sie gestikulieren wild in der Luft herum und behaupten, der Rest ihrer Operationen sei aber nach wie vor voll zuverlässig und sicher. Und was machen die sonst so? "PKIoverheid". PKI für die Öffentlichkeit. Die LANDES-PKI FÜR HOLLAND. m(
Ich finde es sehr putzig, wie das in dem verlinkten Artikel so dargestellt wird, als sei die arme Firma Diginotar vom fiesen und gemeinen Iran "missbraucht" worden.
Stellt sich raus: Firefox hat Recht. Nicht alles ist verschlüsselt.
Ratet mal, was nicht verschlüsselt war.
Kommt ihr NIE drauf!
Der OCSP-POST-Request zu cacert.org.
Update: Weil hier verzweifelte Nachfragen kommen: Wenn man SSL macht, wird die Verbindung verschlüsselt und signiert. Die Signatur ist mit einem Schlüssel gemacht, von dem man nicht weiß, ob der nicht in der Zwischenzeit zurückgerufen wurde (Reallebenäquivalent wäre der Bankautomat, der prüfen will, ob die Karte gestohlen gemeldet wurde). Für diese Prüfung gibt es ein Protokoll namens OCSP. Der Schlüssel, der die Webdaten unterschrieben hat, ist selbst unterschrieben, von einer sogenannten CA. In meinem Fall ist das cacert.org. Per OCSP geht jetzt der Browser beim Besuch meiner Webseite zu cacert.org und fragt die, ob mein Zertifikat eigentlich noch gültig ist. Und diese Verbindung ist unverschlüsselt, darüber hat sich mein Firefox geärgert.
Nun klingt das alles wie "na das muss man doch aber auch absichern!!1!", und das stimmt auch, aber OCSP überträgt über den unsicheren Kanal auch signierte Daten. Und sieht auch eine Möglichkeit vor, um Replay-Angriffe (also das Abspielen einer früher aufgezeichneten "ist OK" Antwort) zu verhindern. In der Praxis ist das alles eine furchtbare Baustelle, weil SSL halt insgesamt an diversen Stellen krankt. Sonderlich zielführend ist diese Warnung jedenfalls nicht, als erstes Mal schon weil er mir bei der Warnung nicht gesagt hat, welcher Teil da jetzt unverschlüsselt übertragen wurde.
Seit dem hat es eine neue Entwicklung gegeben. In dem Interview spekuliere ich, dass RSA die Seeds der Tokens ihrer Kunden aufgehoben haben könnte, und dass die gestohlen wurden bei dem Einbruch, und dass das den Einbruch bei Lockheed erklären würde. Die Sprache im Original-Statement deutete so ein bisschen indirekt darauf hin, als wollten sie das einräumen, war aber nicht klar genug, um es als Geständnis zu werten. Inzwischen will RSA alle Tokens austauschen. Das ist was ich mit "das wäre ein Totalschaden" im Interview meinte. Angeblich haben RSA-nahe Quellen zugegeben, dass die Seeds geklaut wurden.
Die Presseberichterstattung fokussiert sich im Moment auf SecurID, aber ich finde, dass das nicht weit genug greift. Die Firma hat die geheimen Schlüssel ihrer Kunden gespeichert! Einen größeren Vertrauensverlust kann ich mir gar nicht vorstellen für einen solchen Dienstleister! Nicht nur würde ich nie wieder eine Authentisierungslösung von denen kaufen, ich würde denen auch sonst nie wieder vertrauen. Und was machen die sonst so? Na? Kommt ihr NIE drauf! Die betreiben eine SSL-CA, der u.a. Firefox vertraut.
Der Hammer an der ganzen Geschichte ist ja die Begründung, warum sie das nicht gleich zugegeben haben, dass ihr Verfahren vollständig kompromittiert wurde:
RSA Security Chairman Art Coviello said that the reason RSA had not disclosed the full extent of the vulnerability because doing so would have revealed to the hackers how to perform further attacks.Äh, wie meinen?! Lieber die Kunden im Stich lassen und hoffen, dass die nicht merken, wenn sie gehackt werden?! Wenn das keine vertrauensbildende Maßnahme ist, dann weiß ich auch nicht!1!!
Update: Im Statement von Comodo heißt es, der Angriff kam aus dem Iran. Ich glaube ja nicht, dass die Amis sich da schlauer angestellt hätten, aber die hätten Comodo halt dazu bringen können, die Klappe zu halten. Usertrust scheint übrigens ein Label von Comodo zu sein, also kein externer Reseller. Jedenfalls legt deren Webseite das nahe.
Ich für meinen Teil bin beeindruckt, was der Iran da selbständig hingekriegt hat.
Fürs Archiv: Der Hersteller der Äpp, und was sticht mir da sofort ins Auge: die werben da mit Common Criteria EAL4+ Zertifizierung. Da sieht man mal wieder, wie wertlos diese ganze Zertifizierungsscheiße ist. Reines Snake Oil.
Oh und wo wir gerade bei Hirnriss waren: aus der BSI-FAQ zur Ausweis-App:
Der Windows7-eigene Screenreader fängt beim Vorlesen die Eingaben über die Tastatur direkt ab. Dadurch wird auch die eingegebene PIN im Klartext vorgelesen. Unter JAWS, NVDA und VoiceOver tritt dieses Problem nicht auf.
Update: So eine Autoupdatefunktion einer Ausweis-Äpp wäre ja auch genau die Infrastruktur, die man für die Installation des Bundestrojaners braucht.
Und wer denkt, das sei eine schlechte Idee, dem Bundestag eine CA zu geben, für den habe ich eine schlechte Nachricht: die Telekom hat auch dem DFN-Verein eine CA gegeben, und die sind damit rumgelaufen haben allen Unis jeweils ein CA-fähiges Zertifikat in die Hand gedrückt. Jede FH Kleinkleckersdorf kann gültige Zertifikate für paypal.com ausstellen. Kein Wunder also, dass Paypal und co sich auf dieses lächerliche Extended Validation Snake Oil haben einschwören lassen. Da muss die CA dann "besondere Audits" überstehen. Nun, so schlimm können die Audits nicht sein, wenn Anbieter wie Godaddy sowas ausstellen dürfen. In erster Linie ist das eine Gelddruckmaschine, weil die bisherige Gelddruckmaschine, die SSL-Zertifikatsausstellung eh schon ist, nicht mehr genug Profit abwirft für die Gier der Herren Anzugträger. (Danke, Marcus und Jan)
Daher erkläre ich mal. Wenn man eine https-Webseite einrichtet, braucht man ein Zertifikat. Wenn sich der Webbrowser zum https-Server verbindet, zeigt ihm der Server dieses Zertifikat. Der Browser guckt dann, ob das aktuelle Systemdatum innerhalb des im Zertifikat stehenden Gültigkeitsdatumsbereichs ist (aktuell ist das bei mir 28.8.2010 bis 24.2.2011), und ob das Zertifikat von jemandem unterschrieben ist, der im Browser als vertrauenswürdig eingetragen ist. Browser kommen mit einer mehr oder weniger langen Liste von vertrauenswürdigen Zertifikaten. Ich hatte das auch kurz bei Alternativlos Folge 5 erklärt. Da sind lauter suuuper vertrauenswürdige Zertifikats-Aussteller drin wie z.B. Verisign (und deren Tochterunternehmen Comodo, Thawte, GeoTrust, …), der bekannteste. Verisign ist so nahe an der US-Regierung dran, dass sie u.a. auch die DNS Top Level Domains .com und .net betreiben dürfen. Wie bei Alternativlos empfohlen, sollte sich jeder mal die Zeit nehmen, in seinem Browser die Liste der Zertifikate anzugucken. Bei Firefox guckt man in die Preferences, das Advanced Tab, dann das Encryption Unter-Tab, dann den View Certificates Knopf drücken, und in dem neuen Fenster das Tab "Authorities" öffnen. Da mal durchscrollen. JEDER von denen ist für den Browser vertrauenswürdig. Da ist z.B. auch die Deutsche Telekom dabei. Wenn jetzt z.B. die Bundesregierung gerne eure verschlüsselte Kommunikation abhören wollte, würden sie der Telekom einfach sagen, hey, macht uns mal ein Zertifikat für den Banking-Webserver der Sparkasse oder wo auch immer ihr euch so hinverbindet, auch Email und Jabber benutzen SSL. Und euer Browser würde sehen, dass deren Zertifikat von der Deutschen Telekom unterschrieben ist, und würde es kommentarlos akzeptieren.
Neben der US-Regierung und der Bundesregierung sind da auch noch die Chinesen am Start ("CNNIC"), die Contentmafia ("AOL Time Warner Inc."), America Online (nein, wirklich!), TÜRKTRUST, die Bankenmafia (VISA, Wells Fargo, …), die Schweizer ("Swisscom"), Geert Wilders ("Staat der Nederlanden"), die Schweden und Finnen ("Sonera"), die Japaner, Intel und Microsoft. Das hängt auch von der Browserversion ab. Aber es ist wichtig, dass ihr versteht, dass jeder von denen, wenn er wollte, eure Email mitlesen könnte, indem er euch ein ungültiges (also ein von ihnen generiertes, von ihnen unterschriebenes, und daher vom Browser akzeptiertes) Zertifikat vor die Nase hält.
So, wenn ich jetzt einen SSL-Dienst einrichte, und ich möchte, dass das in eurem Browser ohne Terrorpanikmeldung funktioniert, dann kann ich einem der Kommerzanbieter ein paar Euro in die Hand drücken, und der gibt mir dann ein Zertifikat, das ein Jahr gültig ist. Marktführer ist Godaddy, da zahlt man pro Jahr pro Domain sowas wie $30.
Wer das noch nie gemacht hat: das geht so. Man geht dahin, gibt Daten in ein Webformular ein, gibt denen die Kreditkartennummer, und bei denen wirft sich dann ein Perl-Skript an, das das Zertifikat generiert. Die haben genau Null Arbeit. Zum Validieren schicken sie eine Mail an eine Mailadresse bei der Domain, üblicherweise sowas wie postmaster@ oder root@ oder webmaster@, in der Mail ist ein Link drin, den klickt man dann, und dann glaubt einem der Anbieter, dass man berechtigt ist, für die Domain ein SSL-Zertifikat zu haben. Mehr ist da nicht dabei. Ein Perl-Skript.
Nun habe ich aus grundsätzlichen Erwägungen heraus ein Problem damit, Leuten Geld für so eine Schutzgeldnummer zu geben, bei der die Gegenseite nichts tut, das ich nicht auch mal schnell selber hätte machen können. Die einzige Sache, die die von mir trennt, ist dass die eine Mail an Mozilla und Microsoft und Opera geschickt haben, um in die Liste der vertrauenswürdigen Aussteller aufgenommen zu werden. Ich habe mal herauszufinden versucht, was für Anforderungen die Browserhersteller an einen stellen, wenn man auf die Liste will. Die Details hängen vom Browser ab, aber ich will das mal so zusammenfassen: keine erwähnenswerten.
Wenn ich nun nicht einsehe, so einer Firma für das Aufrufen eines Perl-Skripts Geld zu geben, dann bleiben zwei Optionen, um eine SSL-Site zu kriegen. Ich kann mir selber ein Zertifikat machen und selbst unterschreiben. Oder ich kann zu cacert.org gehen, die bieten kostenlose Zertifikate an. In beiden Fällen gibt es von den Browsern einen großen roten Terrorpanikdialog. Der bei Firefox involviert inzwischen ein halbes Dutzend Interaktionen, bevor Firefox ein ihm unbekanntes Zertifikat erlaubt.
Aus meiner Sicht ist es egal, wie ich es mache. So rein fundamentalistisch betrachtet sind selbst-signierte Zertifikate die ehrlichste Variante. Je nach dem, wie man es betrachtet, gebe ich dann niemandem zusätzlich die Möglichkeit, sich eurem Browser gegenüber als meine Webseite auszugeben. CAcert ist der Kompromiss. Auf der einen Seite kostet das nichts, und ein User muss nur einmal CAcert trauen mit ihrem Browser und kommt dann auf alle https-Seiten mit deren Unterschrift drauf. Auf der anderen Seite prüfen die auch nicht weniger als kommerzielle CAs. Ich habe keine Ahnung, wieso die nicht bei den Browsern drin sind als vertrauenswürdig, ich finde CAcert persönlich vertrauenswürdiger als sagen wie Equifax, die Telekom oder CNNIC. Denn bei CAcert kann man den GPL-Quellcode runterladen. Und die Mailinglistenarchive sind öffentlich einsehbar. Wenn ihr keinen Bock habt, bei meinem Blog jedesmal rote Terrorpanikdialoge wegzuklicken, dann könnt ihr euch hier deren Root-Schlüssel holen und in eure Browser importieren. Wie das genau geht, hängt vom Browser ab. Deren Wiki beschreibt, wie man das macht. Achtung: wenn ihr das tut, kann zusätzlich zu den anderen unvertrauenswürdigen CAs auch CAcert euch gefälschte Webseiten vorspielen.
Aber, was ich an der Stelle nochmal ganz deutlich sagen will: nur weil ihr SSL benutzt, heißt das noch lange nicht, dass die Kommunikation sicher ist und nicht abgehört oder manipuliert werden kann. Im Zweifelsfall sollte man immer zusätzlich zu SSL noch eine Ende-zu-Ende-Verschlüsselung fahren. Bei Email und Jabber kann man z.B. openpgp haben, bei diversen Chatprotokollen gibt es OTR. Wenn ihr eine Wahl habt: immer das zusätzlich einschalten. Und wenn ihr mal jemanden im realen Leben trefft, nutzt die Chance, deren Schlüssel zu vergleichen, damit ihr sicher sein könnt, dass euch da keiner verarscht. Sowas nennt sich dann PGP Keysigning Party.
Update: Vielleicht sollte ich noch klarer sagen: ich habe die CAcert root key in meinen Trusted Root im Browser eingetragen. Fundamentalistisch gesehen müsst man einmal durch seinen Cert Store laufen und alles als unvertrauenswürdig markieren, und dann alle Zertifikate im Web manuell prüfen. Aber in den meisten Fällen geht das ja gar nicht. Wenn ich jetzt hier z.B. hinschreibe, dass der SHA1-Fingerprint für mein aktuelles Zertifikat
12:2F:49:D9:86:8D:29:40:38:FF:7D:85:48:FD:0A:89:CA:70:67:E8ist, dann seid ihr auch nicht weiter als vorher. Wenn jemand die SSL-Verbindung zwischen euch und meinem Server manipulieren kann, um euch ein anderes Zertifikat unterzujubeln, dann kann der natürlich auch diese Fingerprintangabe fälschen. Objektiv gesehen müsste man an der Situation mit den SSL-Zertifikaten verzweifeln. Daher plädiere ich dafür, lieber die Leute zu informieren, wie viel Sicherheit ihnen das wirklich bietet, damit sie mit einer angemessenen Erwartungshaltung an SSL herangehen. Oh und: SSL hilft auch nicht gegen Trafficanalyse. Wenn jemand wissen will, welche Seiten ihr hier aufruft, dann kann er das anhand der Größe der Antworten rekonstruieren. Die Daten sind ja immerhin öffentlich. Trotzdem halte ich es für gut und wichtig, Verschlüsselung auch ohne Not einzusetzen, denn je höher der Anteil an verschlüsselten Daten im Netz ist, desto weniger macht man sich verdächtig, wenn man seine Daten verschlüsselt.
Die Forschung wurde übrigens von meinen Freunden und Kollegen bei iSec Partners gemacht, die ich an dieser Stelle herzlich grüßen möchte :-)
Die Erklärung ist, dass irgendein Arschloch zu Torrent-Trackern gelaufen ist, und den SSL-Port meines Blogs als Torrent-Client eingetragen hat. Ich habe keine Ahnung, welcher Tracker das announced, oder gar um welches Torrent-File es sich handelt, aber da steckt Absicht dahinter, denn Bittorrent funktioniert so, dass der Tracker die IPs wegschmeißt, wenn die sich nicht periodisch wieder melden. Da sitzt also irgendwo jemand und meldet sich periodisch bei mindestens einem Torrent-Tracker, damit die IP meines Blogs dort gelistet ist, und dann Leute bei mir aufschlagen.
Warum ist das ein Problem? Weil es sich um den SSL-Port handelt. SSL ist ein notorisch schlecht designetes Protokoll, weil es die Last bei einer Verbindung nicht auf dem Client hat, sondern auf dem Server. Wenn also mehr Clients kommen, hat der Server mehr Arbeit. Nicht nur das: der Server muss am Anfang erstmal kryptographisch aufwendige Operationen machen, um das Handshake durchführen zu können. D.h. wenn man sich einfach nur zu SSL-Ports verbindet und ein bisschen Müll schickt, dann ist der Server damit beschäftigt, sinnlosen Krypto-Kram zu machen. Nun ist der Server, auf dem mein Blog läuft, eh keine besonders fette Hardware. Es handelt sich um einen nach heutigen Standards antiken Sempron 2800+ (1,6 GHz) mit 512 MB RAM. Ihr könnt euch also denken, was da passiert ist: der gatling-Prozess hat mit Krypto-Kram alle CPU gefressen.
Mir bleiben jetzt zwei Dinge zu tun. Erstens kann ich SSL wieder ausschalten. Das wäre schade, weil mir das schon wichtig ist, SSL anzubieten.
Zweitens kann ich tricksen, um diesen Angriff abzuwehren. Ich habe jetzt in gatling Code drin, der guckt, ob die einkommenden Daten wie ein SSL-Handshake aussehen. Und wenn nicht, dann legt er auf.
Das wehrt den Torrent-Traffic ab. Die CPU-Last ist von >90% auf 8% gesunken. Wenn die Angriffe schlauer werden und tatsächlich ein SSL-Handshake mit mir machen, dann muss ich SSL abschalten, um den Dienst zumindest per HTTP weiter anbieten zu können. Und den Traffic für die einkommenden Anfragen bin ich natürlich auch nicht los. Mal gucken, was mein Provider dazu sagt.
Schade, dass schlechtes Protokolldesign es einigen wenigen erlaubt, derartig viel Schaden anzurichten. Wenn das hier jemand liest, der Tracker-Software schreibt: filtert doch mal Clients, die behaupten, auf Port 443 erreichbar zu sein.
Update: Habe die Gelegenheit auch genutzt, mal einen weniger antiken Kernel zu booten. Ade, du schöne Uptime!
Übrigens, auf ca. 170 Anfragen pro Minute kommen gerade 6500 Junk-Anfragen von 3000 verschiedenen IPs. Nur damit ihr mal die Größenordnung seht. Inzwischen verteilt sich die Last gleichmäßig auf Port 443 und Port 80. Also, liebe Tracker-Autoren, auch Port 80 filtern. Überhaupt alle Ports kleiner 1024, wenn ihr mich fragt.
Update: Übrigens gibt es Hoffnung: Google arbeiten am Tieferlegen von SSL.
Ich freu mich schon auf die Schlagzeile, wenn die 4chan-Vandalen über diesen Haufen PHP-Müll herfallen und die Enquete-Kommission rickrollen.
Auf der anderen Seite haben die sich auch alle gegenseitig verdient. Karma is a bitch. :-)
Update: Nur weil die Vorurteile über Internet-Sprallos sind, habe ich nicht die Teilnehmer der Kommission alle als Sprallos bezeichnet. Haben Teile meiner Leser wirklich eine so geringe Lesekompetenz?
I propose that the "RSA Security 1024 V3" root certificate authority beDas ist so völlig unglaublich, da fehlen mir die Worte. Der CA Store ist die Liste der Krypto-Zertifikate, denen wir vertrauen, andere Webseiten zu zertifizieren. Jemand, der da ein Zertifikat reinkriegt, kann sich in den Traffic von anderer Leute SSL-Seiten reinhängen und sich als die ausgeben. Und jetzt findet Mozilla, dass sie nicht wissen, wessen Cert das ist?!? OMFG!!!
removed from NSS.OU = RSA Security 1024 V3
O = RSA Security Inc
Valid From: 2/22/01
Valid To: 2/22/26
SHA1 Fingerprint:
3C:BB:5D:E0:FC:D6:39:7C:05:88:E5:66:97:BD:46:2A:BD:F9:5C:76I have not been able to find the current owner of this root. Both RSA
and VeriSign have stated in email that they do not own this root.
Neulich erst gab es die Story, dass eine Firma Appliances verkauft, die (für die Polizei, natürlich!1!!) sich genau so in SSL-Verbindungen reinklemmen. Ihr erinnert euch vielleicht auch daran, dass Mozilla groß herumdebattiert hat, ob sie die CA der Chinesischen Regierung da reinnehmen sollen. Und jetzt das!
Oh und wisst ihr, was man dagegen tun könnte? Das hier.
Update: angeblich ist das von Paypal. (Danke, Jan)
Nach nur wenigen Dekaden der Arbeit, nachdem sogar Wine an ihnen vorbeigezogen ist in der Versionierung, nachdem es einen Hurd-Release gab und es eine Weile lang so aussah, als würde Duke Nukem Forever früher fertig werden… nun, was lange währt, wird endlich gut. :-)
Herzlichen Glückwunsch an das OpenSSL-Projekt an der Stelle!
Update: Die sind auch in den Root-Zertifikaten von OS X, mailt mir gerade jemand.
Update: Und angeblich sind die auch bei Windows im Certificate Store.
Falls der Name jemandem nichts sagt: der postet auch zu jeder Pro-Stimme in der Löschdebatte eine Contra-Stimme. Für den Fall, dass jemand auf die Idee kommt, dass da demokratisch nach Mehrheiten entschieden wird. Was nicht der Fall ist.
Schade, dass Wikipedia bei der Accountvergabe so geringe und beim Behalten von Weltwissen so hohe Anforderungen stellt.
curl/7.19.0 (x86_64-suse-linux-gnu) libcurl/7.19.0 OpenSSL/0.9.8h zlib/1.2.3 libidn/1.10In der Useragent-Statistik ist das mit weitem Abstand Platz 1 im Moment, hat doppelt so viele Vorkommen wie Firefox.
Interessant ist daran, dass das alles SuSE ist, dass die Zugriffe auf die HTML-Version des Blogs gehen, nicht die RSS-Version (die man in Skripten haben wollen würde, weil die einfacher zu parsen ist), und dass die Zugriffe praktische alle nicht aus Deutschland oder auch nur deutschsprachigen Regionen kommen. Die Top 10 Quell-IPs liegen in China, Lettland, und einer bei Bell Kanada. Chinanet, da denkt man erst mal an ein Botnet. Aber das sind nicht genug Zugriffe, um als DoS zu zählen.
Hat jemand unter meinen Lesern ähnliche Zugriffsmuster woanders beobachten können oder hat eine Idee, was das sein könnte? Sachdienliche Hinweise werden gerne entgegen genommen.
Update: Nein, das ist kein Aprilscherz. Ich habe jetzt diverse Leute, die befürchten, sie seien Schuld. Die Zugriffsmuster entsprechen keiner menschlichen Nutzung, sonst hätte ich ja nichts gesagt. Da kommt sowas wie 80 Zugriffe auf / (immer die selbe URL) innerhalb von 2 Sekunden, dann fünf Sekunden Pause, dann wieder 80 Zugriffe. Da muss sich jetzt keiner Sorgen machen, dass er das mit seinem Firefox versehentlich auslöst.
Mal gucken, was die dazu sagen. Das wäre sozusagen das SSH-Sicherheitsmodell. Wir haben sowas ähnliches im Moment bei self-signed certs, dass er sich das Zertifikat merkt und später nicht mehr rumheult, wenn das gleiche Cert wieder kommt. Nur wenn dann jemand MITM mit einem Cert von Verisign macht später, dann kriege ich das nicht mit, dass das nicht mehr das self-signed cert ist, dem ich mal vertraut habe.
Nachschlag zur Debian-Sache: ich hatte ja erzählt, dass whitehouse.gov betroffen war. Nun, stellt sich raus, auch Akamai ist betroffen. Akamai, das sagt vielleicht dem einen oder anderen nichts, das ist ein Content Distribution System. Das wird von allen möglichen Sites benutzt, u.a. von ATI für den Treiber-Download, und, besonders pikant, ELSTER zum Formular-Download für die Steuern:
DownloadWas heißt das jetzt konkret? Deren X.509-Zertifikat ist ja public, wurde von deren Webserver ausgeliefert. Inzwischen haben sie den natürlich ersetzt. Aber wer schnell genug war (und jemand war schnell genug und hat mir das gemailt), der hat jetzt ein Zertifikat mit dazugehörigem Private Key von "a248.e.akamai.net".Der Download erfolgt von einem externen Server des Anbieters Akamai "a248.e.akamai.net" der von der Finanzverwaltung für die Bereitstellung der ElsterFormular-Dateien genutzt wird.
Was heißt das? Nun, dieses Zertifikat ist ja signiert. Von einer CA, der die Browser der Welt vertrauen. Ich kann mich jetzt also mit diesem Zertifikat hinstellen und Browsern gegenüber erfolgreich behaupten, ich sei Akamai. Konkret: wenn jemand neben mir auf einer LAN-Party einen ATI-Treiber runterläd, oder sein Steuer-Formular zieht, kann ich mich in die TCP-Verbindung einklinken, und dann ist der SSL-Schutz ausgehebelt.
Um den Schaden von sowas zu minimieren haben SSL-Zertifikate eine Verfallsdauer von einem Jahr (naja, einstellbar, aber üblicherweise ist es ein Jahr). Dieses Akamai-Zertifikat läuft im Oktober aus. Ich habe das Zertifikat lokal geprüft und es funktioniert. Also, mal unter uns: das ist eine echt große Katastrophe. Nicht nur für Akamai. Es gibt auch nichts, was Akamai tun kann. SSL hat für solche Fälle die Idee einer Revocation List, aber das skaliert nicht und daher haben die Browser das alle abgeschaltet oder gar nicht erst implementiert. PKI funktioniert schlicht nicht in der Breite. SSL ist überhaupt ein Kapitel für sich. Habt ihr mal in eurem Browser die Liste der CAs angeschaut, denen euer Browser vertraut? Kennt ihr auch nur bei einer davon nähere Informationen, die Vertrauen rechtfertigen würden? Seht ihr? Ich auch nicht.
Ich möchte noch eine Sache bestonen: Akamai hat sich hier nichts vorzuwerfen. Die haben alles richtig gemacht. Wir bauen unser Kryptographie-Fundament auf Sand, da kann man noch so tolle Best Practices haben und einhalten. Im Übrigen gelten diese Überlegungen auch für alle anderen Varianten, wie jemand an einen Private Key kommen kann, z.B. Einbruchsdiebstahl. Und es gilt analog für alle anderen Public Key Systeme und PKIs im Moment, z.B. bei e-Government und der Gesundheitskarte. Skalierender Schlüsselrückruf ist ein ungelöstes Problem.
Update: Noch ein Nachschlag zu ELSTER. Stellt sich raus, dass die Elster-Leute auch noch ein Cross Site Scripting Problem haben, und man gar nicht SSL spoofen muss, um denen den Bundestrojaner unterzujubeln. Danke an Thomas für den Hinweis.
Update: Alexander Klink hat offenbar auch eine große deutsche Bank mit dem Problem gefunden, und, besonders hart: deren Zertifikat läuft erst in drei Jahren ab.
In the wake of the Debian weak key issue it was revealed that whitehouse.gov had a weak key. It turns out that the Akamai SSL key is also weak. Akamai, in case you never heard of them, is a major content distribution network. They have tens of thousands of servers distributed over the world. If you have a high traffic web site, you can contract with them, and they will host it and redirect visitors to the site closest to them. Their customer list includes Microsoft, the New York Times, and — particularly interesting for this — ATI's driver downloads.
Akamai obviously replaced their keys immediately. BUT. If you were quick enough, you could get their old public key (it is sent as part of the SSL handshake), and since the private key is weak (there are only 32k possible keys), you can generate the private key to it. Someone did (who wishes to remain anonymous) and sent the key to the CCC. I verified it. The key works. The part that has not sunk in yet for most people is: the public key is signed by a CA that browsers trust. I have a public key and a private key. I can now impersonate Akamai. If I can manipulate your TCP connection (which is easy, for example, if you are using Wifi or are on the same LAN with me), I can send you malware instead of the ATI driver.
SSL has two defenses for this. First: keys expire. This particular key expires October 2008. Second: Certificate Revocation Lists. SSL originally had the idea that CAs would publish a list of compromised keys, and as part of the SSL handshake, the browser would check if the key is on the list. The problem is: that does not scale. At all. There are billions of SSL connections being established per second, Verisign can not possibly pay for the traffic to send their list to everyone. So — noone checks the CRLs. This is the main reason why PKI does not work in practice.
One more thing: I'd like to stress that Akamai did nothing wrong here. They did everything right and still have a problem. The same problem occurs if someone gets the private key by some other means, for example breaking and entering. The foundation upon which we build our infrastructure is less stable than most people realize.
Hey, but you stand vindicated, because you shouted the correct contact address to the whole world in the 38th comment to the 327th post on your blog (which must surely compare favorably to being posted on the bottom of a locked filing cabinet stuck in a disused lavatory with a sign on the door saying 'Beware of the Leopard'.).Sehr spaßig.Währenddessen gibt es wachsende Spannungen wegen der Tatsache, dass Debian den Fix 5 Tage vor dem Advisory eingepflegt hat. Die Terroristen (oder Debian-Insider, die der Versuchung auf Botnet-Expansion nicht widerstehen konnten) hatten also 5 Tage Zeit, einen Exploit zu entwickeln und damit Rechner zu übernehmen. Wenn man mal bei denyhosts.net guckt, gibt es da auch einen deutlichen Spike [lokale Kopie der Grafik].
Oh übrigens, Spaß mit URL-Redirects: debian.wideopenssl.org :-]
Affected keys include SSH keys, OpenVPN keys, DNSSEC keys, and key material for use in X.509 certificates and session keys used in SSL/TLS connections. Keys generated with GnuPG or GNUTLS are not affected, though.Den Fehler haben sie am 17. September 2006 eingebaut. Juchee für die Sicherheit!Update: falls das jemandem nicht klar ist: Ubuntu == Debian. Auch alle Ubuntu-User sind betroffen.
Ja. Richtig gelesen. Die AMIS werfen RUSSLAND vor, die Lage im Nahen Osten zu destabilisieren. HAHAHAHAHAHAHAHA, die merken echt gar nichts mehr, die Amis. Völlig weggetreten.
Also ich habe ja auf sowas schon gewartet. Adobe war noch nie für die sorgfältige Security ihrer Software bekannt, aber wenn so eine Firma dann auch noch Macromedia kauft… die kombinierte Eiterblase mußte irgendwann aufplatzen. Auf der anderen Seite, was weiß schon ich. Vielleicht ist es ja ein Honeypot. Normalerweise liegt der Private Key nicht für die webserver-uid lesbar herum. Da muss man sich schon besonders dämlich anstellen.
there were several reports of OpenSSL being broken when compiled with GCC 4.2. It turns out OpenSSL uses function casting feature that was aggressively de-supported by GCC 4.2 and GCC goes as far as inserting invalid instructions ON PURPOSE to discourage the practice.Das ist ja nicht zu fassen. (Danke, Arne)
Allerdings gibt es da eine Art Hochgefühl, wenn man einen Angriff findet, oder wenn man einen Angriff noch einen Schritt weiter treibt, oder fast genau so schön: wenn man aus einer zeitkritischen Routine wieder ein paar Cycles rausoptimiert hat. Es gibt da ein Phänomen namens Deep Hack Mode, das man beim Hacken erreichen kann, und zwar beim Reverse Engineering genau so wie beim Programmieren. Darunter muss man sich eine Art Tunnelblick vorstellen, in dem man sich hinein steigert. Ein starker Fokus auf das, was man gerade tut. Ein so starker Fokus, daß manche Leute von Meditation sprechen. Das geht natürlich am besten, wenn man nicht gestört wird, daher kriege ich spät abends die meisten Sachen fertig. Gestern habe ich im Deep Hack Mode die Bignum-Multiplikation auf i386 portiert, und heute habe ich mal einen Additions-Generator gemacht. Die aktuellen Cycle-Werte sind:
Der Browser (als IE7, Mozilla macht bei diesem Humbug nicht mit) soll dann die URL-Leiste grün hinterlegen.
Jetzt ist eine Studie rausgekommen, die zeigt, daß mit Extended Validation Certificates Phishing-Erkennungsraten nicht steigen. Im Gegenteil, wenn man die User schult, sinken die Phishing-Erkennungsraten sogar. Und wer hat die Studie gemacht? MS Research. Autsch!
Update: Der Mann zeigt Einsicht und steigt jetzt auf RSA um. Ist zwar auch anfällig gegen MITM, aber hey, schon mal ein Fortschritt. (Danke, Thierry)
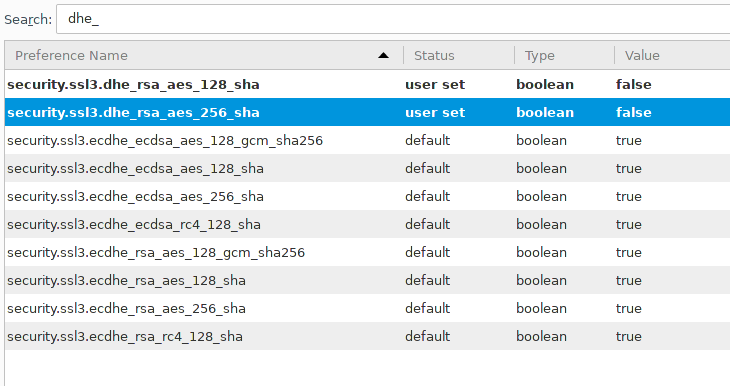{kind=link}
{kind=link}
{kind=link}
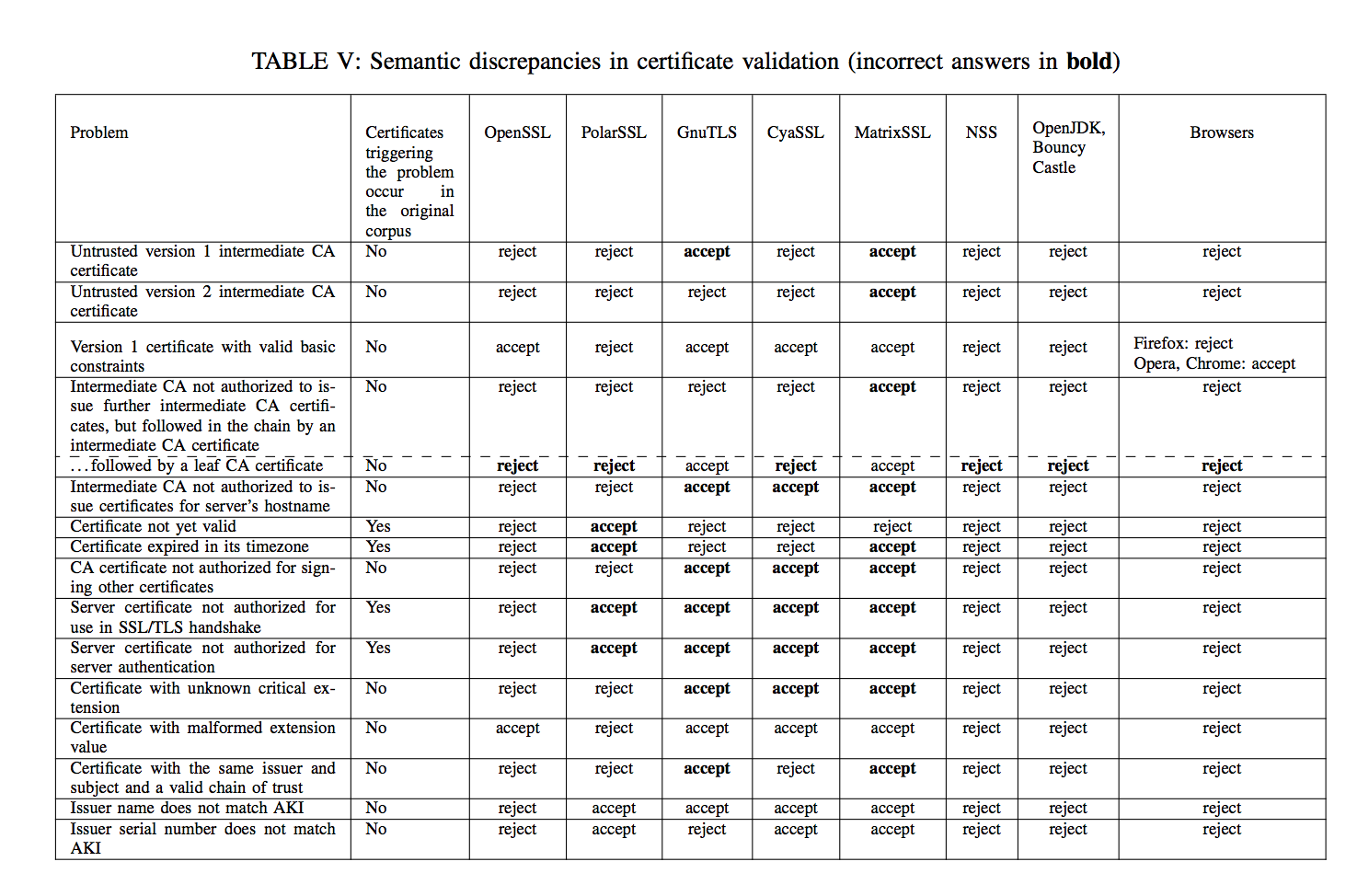{kind=link}
{kind=link}
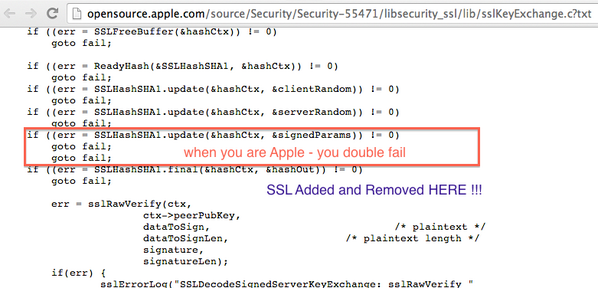{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}