Fragen? Antworten! Siehe auch: Alternativlos
Es ist wohl MOV. Nach allen Benchmarks ist es ganz offensichtlich nicht der Rechenleistung sondern die Kommunikation, die am Limit läuft.Und der zweite Einsender:
Die bleiben da auch wunderbar kühl. Die IDELn und sind halt trotzdem langsamer als die Intels.Zuerstmal ist die Frage warum das auf den Intels so viel besser läuft. Nachdem AMD den Scheduler ausschließt, heißt das IMHO wohl dass Caching bei den Intels im Moment deutlich besser läuft.
Das ist auch der einzige Teil, der so anders bei Spielen ist. Die greifen ziemlich Wild auf unterschiedlichste Stellen zu, während andere Programme halt entweder dauernd sequenziell lesen oder lange lokal bleiben, sodass auch primitive Caches das schaffen.
Oder eben doch die Kommunikation zwischen den CCX. Aber dann würde man das je mit dem Scheduler in den Griff bekommen können.Die wirklich Interessante Frage ist allerdings, wie sie das per SW-Update in den Griff bekommen wollen.
Ich meine man kann auch per SW den Memory Controler übertakten. Aber das ist wohl eher nicht im Sinn von AMD.
Schnelleren RAM habe ich auch noch selten durch die Internetleitung flutschen gesehen.
Kann mir nicht vorstellen, dass man bei spielen da wirklich so viel auf Caching hin optimieren kann.Idee wäre Socket Pinning in die Spiele zu schmeißen oder das Threadmanagement abzuändern.
In Zukunft wird sich das Problem vermutlich von alleine erledigen. Der Anteil Memory Zugriffe zu Rechenoperationen nimmt seit langem ab.
Das ist auch das was passiert wenn du die Detailgenauigkeit hoch schraubst. Dann sehen die AMDs wieder richtig gut aus.
(Ein Detail, dass gerne weggelassen wird. Es ist sind gar nicht so arg die Auflösung sondern vor allem auch anderen Grafikeinstellungen die da eine große Rolle spielen.)
bei den Desktop Ryzen CPUs habe ich einen ganz starken Verdacht, warum der sich so verhält wie er sich eben verhält. Dazu muss ich mal etwas ausholen. Die Zen Architektur sind ja eigentlich Quadcore NUMA-Nodes, ich meine damit so ein einzelnes Zen CCX Modul. So ein CCX hat 2x DDR4-2666 Ramkanäle und 32 PCIe gen3 Lanes. Dann hat AMD da noch die geniale Idee gehabt HyperTransport soweit aufzubohren, dass es nur noch ein Protokoll ist, dass relativ unabhängig von der Hardware ist. Das neue heißt Infinity Fabric und AMD benutzt es gerne über PCIe Lanes.Kleine Korrektur: Ein Load ist eine Cache-Line, nicht 1 Byte. Das ist also noch viel schlimmer. Aber auf der anderen Seite ist das ja auch seit "schon immer" so, dass Prozessoren im Wesentlichen auf ihren RAM warten.Jetzt schauen wir uns mal den Desktop Ryzen 7 an. Das sind 2 CCX Module, aber trotzdem hat die Desktop (ich betone das hier sehr, wail es bei den Server CPUs offenbar richtig gemacht wurde) nur 2x DDR4-2666 Ramkanäle und nur 24 PCIe gen3 Lanes. 16 bzw 8/8 davon sind für die Grakas vorgesehen, 4 für NVMe und 4 weitere für die Southbridge (oder wie auch immer man das nun nennen will). Mein Verdacht hier ist, dass ein CCX mit seinen beiden Ramkanälen und seinen 24 PCIe Lanes üben den AM4 Sockel rausgeführt ist und das zweite CCX über Infinity Fabric (hier 8 PCIe Lanes) an den ersten CCX gekoppelt ist. Das bedeutet dann aber auch, dass die ganze Speicheranforderung vom zweiten CCX durch den ersten CCX muss (es muss ja durch seinen Ramcontroller). Der Ryzen hat 2 Load/Store Units, die entweder 2 Loads oder 1 Load und 1 Store können. Ein Load ist immer ein Byte (außer da hat sich was in den letzten 20 Jahren was fundamental geändert). Rechne einfach mal aus: 2 Loads mal 8 Kerne mal 3,6 GHz macht so ca 53 GiB/s. Diese Bandbreite kann ein Ryzen unter Benutzung aller 8 Kerne erreichen (mit den Turbos wird es noch etwas mehr). 2x DDR4-2666 sind theoretisch 42 GiB/s, real sieht man hier mit etwas Glück vielleicht 35 GiB/s. Der Ryzen 7 hat also offenbar Rambandbreiten Problem. Und wenn das Setup wirklich so ist, wie da oben beschrieben, dann ist das Bandbreitenproblem beim zweiten CCX wirklich übel. 8x PCIe gen3 (die Infinity Fabric Verbindung) macht nicht mal 8 GiB/s. Da kommt dann noch die ganze Cache-Coherenz für die 3 Cache-Stufen dazu.
Nimm jetzt mal ein aktuelles Spiel her, dass vermutlich sogar seine Texturen herein streamt. Stell dir mal vor das benutzt mehr als 4 Threads, sodass dann welche auf dem zweiten CCX laufen. Da ist nicht nur die Bandbreite ein Problem, sondern auch noch die Latenz. Oder kurz gesagt, der Ryzen 7 ist in allem gut was 4 (oder weniger) Threads benutzt oder hauptsächlich in den ersten beiden Cache Stufen stattfindet (vermutlich sehen deswegen auch die Raytracing Benchmarks so gut aus). Das Problem ist weniger die Architektur, ich finde sie sogar ziemlich gut. Das Problem ist wohl eher der AM4 Sockel, der einfach zu wenig Pins hat um 4x DDR4 und 32+ PCIe Lanes rauszuführen. Wie oben schon gesagt, bei der Server Variante ist alles korrekt gemacht. Diese CPU sind 4 CCX Module mit 8x DDR4 und 96 PCIe Lanes, die über den neuen Sockel rausgeführt werden.
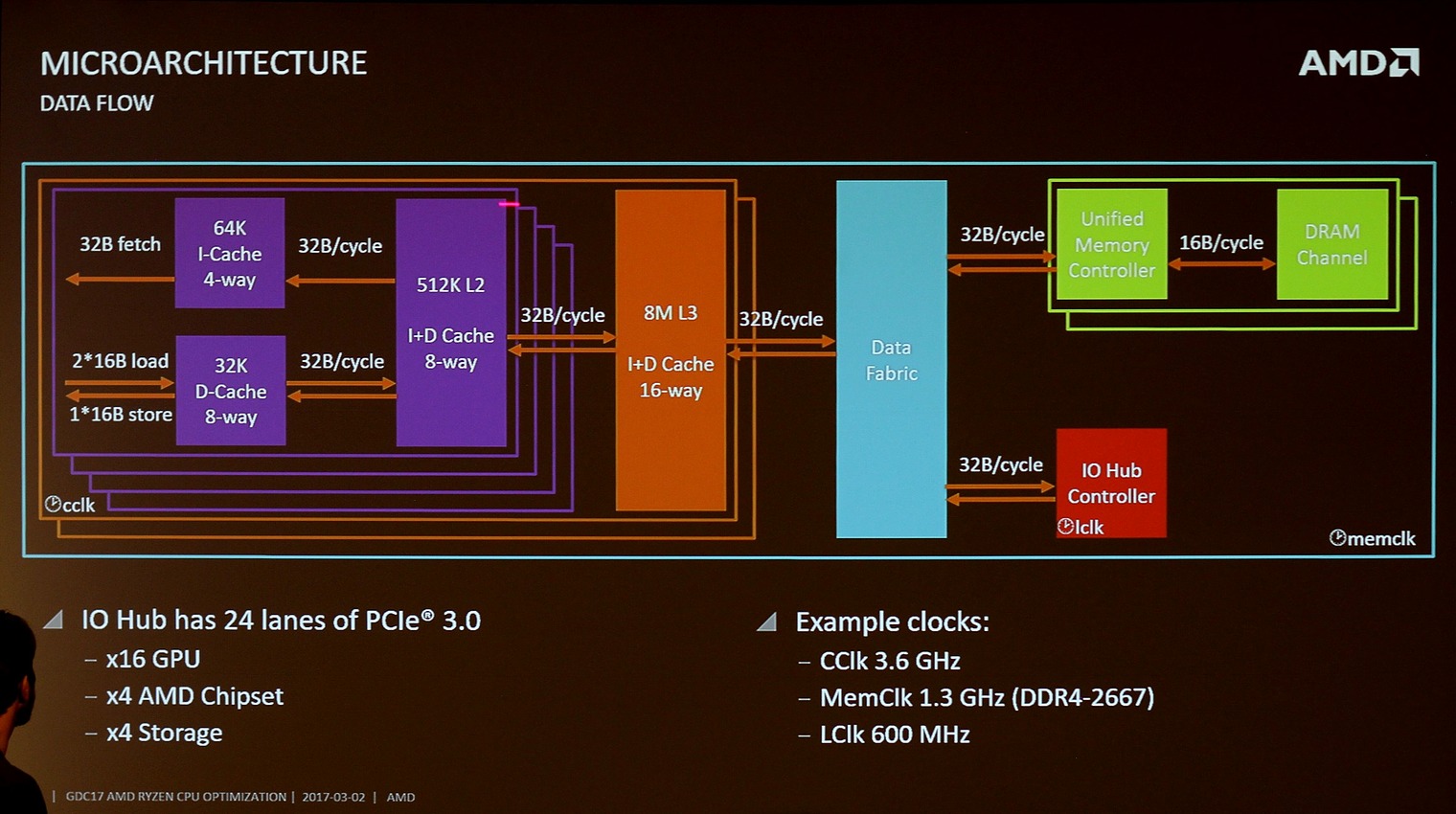
Update: Ein dritter Einsender hat dieses Ryzen-Architektur-Diagramm ausgegraben, auf dem es nicht so aussieht, als müsste der zweite CCX seine Anfragen durch den ersten durchrouten.
{kind=link}