Fragen? Antworten! Siehe auch: Alternativlos
Ein aktueller Fall illustriert das ganz gut: SuSE Linux Enterprise Server 15 SP4 hat eine BSI-Zertifizierung gekriegt. Ausgestellt am 15.12.2023.
Die benutzen OpenSSL 1.1.1. Das war zu dem Zeitpunkt bereits seit Monaten End-of-Life. Das steht auch im auf Dezember 2023 datierten Report drin, dass sie OpenSSL 1.1.1 verwenden.
Deren OpenSSH hat glaube ich auch noch keine Post-Quantum-Crypto drin. Weiß da jemand genaueres? War jedenfalls nicht Teil des Tests.
So, meine Damen und Herren, sieht Compliance-Sesselfurzerei aus. Kostet viel Geld, bringt weniger als nichts.
Wenn sich bei euch jemand damit bewirbt, dass er ein BSI-CC-Zertifikat habt, dann wisst ihr hoffentlich spätestens ab jetzt, was ihr von dem zu halten habt.
Update: Das Produkt selbst hatte übrigens am 31. Dezember 2023 End-of-Life, also weniger als einen Monat nach Zertifizierung (außer man zahlt LTSS). (Danke, Veit)
Oder nehmen wir an, ihr kennt euch mit Computer-Architektur aus. Ihr wisst, dass es einen Kernel gibt, und der kann Userspace-Programme laufen lassen, und stellt denen virtuellen Speicher zur Verfügung und Syscalls und so weiter. Natürlich wisst ihr, dass der Kernel grundsätzlich in den Speicher der Prozesse reingucken kann.
Wenn ihr also, sagen wir mal, curl benutzt, und der spricht SSL mit einem Gegenüber, dann kann der Kernel grundsätzlich in den Speicher gucken und die unverschlüsselten Daten sehen. Da wird jetzt niemand wirklich überrascht sein, dass das so ist, hoffe ich.
Aber die Details waren bisher nicht so attraktiv. Das war mit Aufwand verbunden. OK, du kannst gucken, welche SSL-Library der benutzt, und da stattdessen eine Version mit Backdoor einblenden als Kernel. Oder du könntest die Offsets von SSL_read und SSL_write raussuchen und dann da Breakpoints setzen, wie bei den Debugging-APIs, und dann halt reingucken. Du hättest potentiell auch mit Races zu tun. Du müsstest wissen, wie man aus einer Shared Library die Offsets von Funktionen rausholt.
Gut, aber dann denkst du da ein bisschen drüber nach, und plötzlich sieht das gar nicht mehr so schwierig aus. curl lädt openssl als dynamische Library.
$ ldd =curlDa sieht man schon, dass die Adressen irgendwie krumm aussehen. Das ist ASLR. Wenn du nochmal ldd machst, kriegst du andere Adressen. OK aber warte. Die Daten hat der Kernel ja, und exponiert sie sogar an den Userspace:
linux-vdso.so.1 (0x00007ffff7dd2000)
libcurl.so.4 => /usr/lib64/libcurl.so.4 (0x00007f1df4c66000)
libssl.so.3 => /usr/lib64/libssl.so.3 (0x00007f1df4b6f000)
[...]
$ cat /proc/self/mapsUnd innerhalb des Adressbereichs, an den so eine Library gemappt wird, bleibt das Offset von SSL_write ja konstant. Wie finden wir das? Nun, da gibt es Tooling for:
[...]
7f846a8d2000-7f846aa27000 r-xp 00028000 00:14 5818768 /lib64/libc.so.6
$ nm -D /usr/lib64/libssl.so.3 | grep SSL_writeGut, also grundsätzlich könnte man den Kernel so umbauen, dass er beim Mappen von libssl.so.3 immer bei Offset 35660 einen Breakpoint setzt, und dann könnte man da die Daten abgreifen. Das ist aber eine Menge Gefummel und Kernel-Space-Programmierung ist sehr ungemütlich. Der kleinste Ausrutscher kann gleich die ganze Maschine crashen.
0000000000035660 T SSL_write@@OPENSSL_3.0.0
Warum erzähle ich das alles? Stellt sich raus: Muss man gar nicht. Ist alles schon im Kernel drin. Nennt sich uprobes und ist per Default angeschaltet. Da kann man über ein Config-File im /sys/-Tree dem Kernel sagen, man möchte gerne hier einen Breakpoint haben. Dann kann man per eBPF ein über Kernelversionen portables Kernelmodul hacken, das sich an die uprobe ranhängt und die Daten kopiert. Dann gibt es ein standardisiertes Interface dafür, wie man von dem eBPF-Modul die Daten wieder in den Userspace kopiert, wenn man das möchte.
Was hat man dann? Ein Tool, das in alle SSL-Verbindungen via OpenSSL auf der Maschine reingucken kann. Der Aufwand ist so gering, dass man das im Handumdrehen mit nur ein paar Zeilen Code auch auf gnutls erweitern kann, und auf NSS (die Mozilla-Library). Auch den TLS-Code von Go oder von Java kann man abfangen (Java ist etwas fummelig, da würde man vermutlich einen gemütlicheren Weg nehmen).
Gut, für das Eintragen der uprobe und für das Laden von dem eBPF muss man root sein. Es ist also kein Elevation of Privilege im herkömmlichen Sinne.
Aber es immanentisiert das Problem, das bis dahin bloß theoretisch war. Aus meiner Sicht heißt das, dass man ab jetzt keinem Kernel trauen kann, den man da nicht selbst hingetan hat. Mit anderen Worten: In jemand anderes Container laufen geht nicht.
Das war schon immer klar, aber jetzt ist es immanent. Was sage ich jetzt. Die Tools gibt es sogar schon seit mehreren Jahren. Ein SSL-Abgreif-Tool war das 2. Projekt, das auf diesen Frameworks gebaut wurde. Es sind sogar mehrere Tutorials und Beispielanwendungen online, wie man das macht.
Das nimmt mich gerade mehr mit als es sollte. Wir haben die Vertrauensfrage in der IT auf jeder Ebene verkackt. Der Hardware kann man schon länger nicht mehr trauen. Anderer Leute Software kann man schon länger nicht mehr trauen. Dass man Hypervisoren und Containern nicht trauen kann, ist auch schon immer klar, daher machen die ja dieses Affentheater mit "memory encryption", damit ihr euch in die Tasche lügen könnt, das sei schon nicht so schlimm. Doch. Doch, ist es.
Das könnte mich alles im Moment noch kalt lassen. Ich hacke alle meine Software selber (bis auf den Kernel), OpenSSL ist bei mir statisch reingelinkt (d.h. der Kernel sieht nicht, dass ich da eine Library lade, von der er die Offsets kennt). Man kann mit uprobes und ebpf immer noch meine Anwendungen ausspähen, aber dafür muss man die erstmal reverse engineeren und pro Anwendung die OpenSSL-Offsets raussuchen und eintragen. Das nimmt einem im Moment das Framework noch nicht ab. Aber ihr merkt hoffentlich selber, wie gering die Knautschzone hier ist. Meine Software läuft auf einer physischen Maschine, keinem vserver. Sagt der ISP. Ihr könnt euch mal mal selber fragen, wie sicher ihr euch seid, das selber nachprüfen zu können, wenn euch euer Dienstleister das verspricht.
Ich spoiler mal: Könnt ihr nicht.
Ich glaube, da muss ich mal einen Vortrag zu machen. Das ist alles sehr deprimierend, finde ich.
Both truncations and overruns of the key and overruns of the IV will produce incorrect results and could, in some cases, trigger a memory
exception. However, these issues are not currently assessed as security
critical.Es handelt sich hier um ein out of bounds read, d.h. nicht memory corruption aber kann trotzdem die Anwendung segfaulten.Hier der interessante Teil:
This issue was reported on 21st September 2023 by Tony Battersby of Cybernetics. The fix was developed by Dr Paul Dale. This problem was independently reported on the 3rd of December 2022 as part of issue
#19822, but it was not recognised as a security vulnerability at that time.Mit anderen Worten: Es ist genau so, wie ich seit Jahren in meinen Vorträgen anprangere. Man fixt nur noch Dinge, die man als Security-Problem identifiziert. Alle anderen Bugs bleiben ungefixt offen.
Es war ein Buffer Overflow im Punycode-Decoding. Punycode ist ein schrottiges Encoding für Sonderzeichen in Domains.
Es gibt einen Critical 0day gegen OpenSSL, aber wir verraten ihn euch erst in einer Woche.Hey, mit solchen Leuten willste doch zusammenarbeiten, nicht wahr?Ihr seid jetzt alle gefickt, GEFICKT MWAHAHAHA!!1!
Update: Betrifft nur OpenSSL 3.0.4, das gerade erst rausgekommen ist. Der kaputte Code kam auch erst kurz vor Release rein. Die haben also immer noch keine Qualitätssicherung bei OpenSSL. Seufz.
Der Launcher hinterlässt Logs unter Windows, in %localappdata%/epicgameslauncher/saved/logs. Dort findet man dann episch veraltete Versionen von curl, openssl und zlib, und den Grund für das Problem: Epic hat ihre AWS-Konfiguration verkackt.
Während des Login-Vorgangs versucht der eine Verbindung zu catalog-public-service-prod06.ol.epicgames.com aufzubauen, und da kommen so ein Dutzend oder so verschiedene IPs zurück, von denen eine zu funktionieren scheint (vielleicht auch mehr), aber andere werfen Fehler von "Unknown CA" über "certificate expired" und "hostname not found in certificate".
Using libcurl 7.55.1-DEVDa fragste dich doch echt, was diese Leute beruflich machen.supports SSL with OpenSSL/1.1.1
supports HTTP deflate (compression) using libz 1.2.8
Ich hab versucht, das bei deren Support-System zu melden, aber die sagen, meine E-Mail sei ungültig. Tja, dann halt nicht.
Aktuell sind curl 7.83.1 (gab die eine oder andere Vuln seit dem), OpenSSL 3.0.4 (gab die eine oder andere Vuln seit dem), 1.2.12 (1.2.8 ist von 2013!!). Finde ich unverantwortlich, sowas unters Volk zu bringen.
Wenn hier also jemand jemanden bei Epic kennt, oder weiß, wer da für Security zuständig ist (falls es da jemanden gibt), dann tretet die doch mal bitte kurz. Das geht so gar nicht.
Mein Workaround war jetzt, eine funktionierende IP in der hosts-Datei festzunageln. Damit geht Login wieder. Aber jetzt wo ich weiß, was da für unsichere Komponenten drin sind, habe ich spontan kaum noch Lust, den Launcher überhaupt zu starten.
Advantageous, but not required are:- an understanding of Cryptography;
- an ability to write secure code;
Leuchtet ja auch ein. Seit wann braucht man für Arbeit an TLS ein Verständnis von Kryptographie? Oder muss wissen, wie man sicheren Code schreibt?!Nee, solche Leute sollen sich mal lieber bei SAP oder Microsoft bewerben!1!! (Danke, Ben)
Eigentlich wollte ich nur eine eMail an ein Mitglied der SPD-Franktion im Berliner Abgeordnetenhaus senden. Sollte im Jahre 2021 eigentlich kein Problem sein. Einen OpenPGP-Hinweis habe ich keinen gefunden, aber das hatte ich auch nicht unbedingt erwartet.Ich finde ja, politischen Parteien sollten automatisch ihren Parteienstatus verlieren, wenn sie keine Mails von ihren Bürgern annehmen, indem sie DSL-IPs sperren.Doch kurz nach Versand heute morgen kam gleich ein Bounce zurueck. Der Posteo Mailserver erzaehlt mir:
TLS is required, but was not offered by host spdpostman.spd.parlament-berlin.de[212.121.136.130]Na gut, dachte ich. Vielleicht schrauben sie gerade rum und ich probiere es einfach heute abend noch einmal. Sicherheitshalber habe ich noch am morgen im Parlament (Abteilung 'Internet') angerufen. Half aber nix. Am abend immer noch keine TLS.
Hmm.. also mal mit "openssl s_client -starttls .." geschaut: .. Connection refused ..
Hmm.. DSL-Kunden IPs geblockt?
Dann eben so:
https://ssl-tools.net/mailservers/spdpostman.spd.parlament-berlin.de
Autsch, wirklich kein STARTTLS!
Ein anderes Tool hat sogar noch was von Microsoft auf der Serverseite gefaselt.
Also hopp hopp, schön updaten alle.
Grund für Panik besteht wahrscheinlich nicht, außer eure Anwendung verwendet von Hand die ASN.1-Popel-Routinen oder den chinesischen Regierungsstandard SM2. Wenn ich das richtig sehe, ist der aktuell nur zu Fuß über das EVP-Interface erreichbar, und kann nicht per TLS erreicht werden.
Trotzdem solltet ihr alle updaten. Sofort. Immer alles sofort updaten!
Update: Ich muss an der Stelle meiner Enttäuschung ein bisschen Luft machen. Dieser SM2-Bug ... es gibt da ein beliebtes Muster, wie man Funktionen aufbaut, die variabel viel Daten zurückgeben. Entweder die Funktion gibt einen frisch allozierten Puffer zurück. Das ist am einfachsten, aber aus irgendwelchen Gründen unpopulär. Daher hat sich das populäre Muster herausgearbeitet, dass du die Funktion zweimal aufrufst. Das erste Mal mit einem ungültigen Zielpuffer, dann sagt er dir, wieviel Platz er im Puffer braucht. Dann holst du dir einen Puffer in der Größe und rufst es nochmal auf.
Ihr merkt schon: Wir haben es hier mit einem "You had ONE Job"-Szenario zu tun. DIE EINE Sache, auf die man achten muss, ist dass der nicht eine kleinere benötigte Größe zurückliefert beim ersten Mal. Und jetzt ratet mal, was OpenSSL hier verkackt hat.
Und das ausgerechnet in einer westlichen Implementation eines chinesischen Standards! Da stellen sich direkt ein paar unangenehme Fragen, finde ich.
Seufz. Seit dem Stress neulich hatte mein gatling gerade 10 Tage Uptime zusammen.
Es handelt sich um eine Null Pointer Dereference, das man auslösen kann, wenn man einem OpenSSL ein böses Zertifikat gibt, das auf eine Revocation Liste zeigt, die auch böse ist, und das OpenSSL mit revocation checking läuft.
Man könnte also instinktiv sagen: Betrifft mich nicht, ich mach hier Serverseite ohne Client Certs. Und wenn ein Client segfaultet, da scheiß ich doch drauf.
Mein Rat ist: Immer alles patchen. Sofort.
gcc -march=native -dM -E - < /dev/nullDann gibt gcc alle vordefinierten Präprozessorsymbole aus. Besonders hilfreich ist das mit Crosscompilern oder mit -march=native, wenn man vergessen hat, dass das gcc-Symbol für "die CPU kann AES-NI" __AES__ hieß.
Bei der Gelegenheit fiel mir auch gerade auf, dass mein Haswell-Arbeitsgerät die SHA-Instruktionen gar nicht beherrscht. Ich dachte die sind seit Ewigkeiten überall drin. AMD hat die seit Zen. Die Unterschiede zwischen den Implementationen sind übrigens echt bemerkenswert. Hier ist ein sha1sum über eine 80MB-Datei:
libtomcrypt: e7d22debfee07c9da1c85114f14cb720956b7fca (313.4M cycles)Das ist auf meinem Atom-Reisenotebook mit SHA-Spezialinstruktionen. Hier sind die Timings für SHA2-256 auf die Datei auf demselben Notebook:
openssl: e7d22debfee07c9da1c85114f14cb720956b7fca (58.1M cycles)
botan: e7d22debfee07c9da1c85114f14cb720956b7fca (65.0M cycles)
gcrypt: e7d22debfee07c9da1c85114f14cb720956b7fca (190.2M cycles)
libtomcrypt: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (673.6M cycles)Man sieht, dass das schon einen Grund hat, wieso OpenSSL häufig verwendet wird.
openssl: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (139.6M cycles)
botan: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (137.6M cycles)
gcrypt: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (432.7M cycles)
vanilla: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (814.7M cycles)
Zum Vergleich die Timings von dem Haswell-Gerät:
libtomcrypt: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (844.8M cycles)Da sieht man, wessen Implementation die Extra-Meile gegangen ist.
openssl: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (457.1M cycles)
botan: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (686.1M cycles)
gcrypt: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (506.7M cycles)
vanilla: cd80cbb9adb86378eee193cf73e0c660aa2abf460cc85e1ef0611437d18cddec (1.0G cycles)
Das Präprozessor-Symbol für SHA-Instruktionen heißt übrigens __SHA__. Die Messgröße ist die Differenz im Cycle Counter für einen Hash-Lauf über die gesamte Datei. Vanilla ist eine unoptimierte C-Implementation aus dem Standard. Der Cycle Counter ist die feinste Messeinheit, die CPUs so haben. Eine 1 GHz CPU hat eine Milliarde Cycles pro Sekunde.
Wie z.B. das nächste OpenSSL-Security-Problem oder dass der git-Patch neulich das Problem nicht wirklich geschlossen hat.
# root ca key
openssl genrsa -passout pass:Huawei123 -out ca.key 2048
Wisst ihr noch damals? Als die Leute sich Sorgen machten, Huawei könnte ein Sicherheitsrisiko sein? (Danke, Danny)
Ich baue da ja absichtlich keinen Watchdog mit Autorestart ein, damit es einen Leidensdruck gibt, das Problem mal zu debuggen und zu fixen.
Das ist erstaunlich, weil OpenSSL bisher gegenüber allen anderen TLS-Implementationen immer spürbare Performance-Vorteile hatte. So hohe Performance-Vorteile, dass viele im Gegenzug das grottige API zu erdulden gewillt waren.
Und jetzt kommt jemand und macht in Rust ein TLS, und das ist schneller? Das ist bemerkenswert! Nicht weil Rust irgendwie inhärent langsameren Code erzeugt, aber weil OpenSSL bisher für seine exzellente Performance bekannt war. Dass jemand schneller sein kann, war nicht ausgeschlossen, aber dass es dann gleich so 20% schneller sein würde, das ist echt bemerkenswert. Hut ab vor dem Rust-Hacker da! (Danke, Magnus)
Die sind alle recht lustig, aber die Zweite ist episch:
Because of an implementation bug the PA-RISC CRYPTO_memcmp function is effectively reduced to only comparing the least significant bit of each byte.Are you fucking kidding me?!?
OpenSSL 1.1 ist im August 2016 released worden.
Qt hat sich damit (bei mir) selbst ins Aus geschossen. Projekte, die nur mit Qt gehen, verwende ich dann halt nicht mehr. Viele sind das ja eh nicht.
Aber ich kann mich da echt nur wundern, dass die da so nachlässig sind, wenn nicht gar fahrlässig. Der alte OpenSSL-Kram wird ja nicht besser, der wird irgendwann nicht mehr supported und dann muss der Schritt eh gemacht werden.
Update: Es gibt da seit Mai (!) Code, aber den liefern sie noch nicht aus. Vielleicht in 5.10 dann. Seufz.
Update: Ich sehe gerade, dass openssh nicht mehr mit openssl 1.1 baut. Ich habe hier ein openssh mit openssl 1.1 gebaut und im Einsatz, aber jetzt checkt configure das und bricht den Build ab. WTF?
Der re-keying code in vielen libraries, allermindestens openssl, nss, gnutls, ist total kaputt. Wir haben das über Jahre in postgres (nur openssl zu dem Zeitpunkt) verwendet, und haben unmengen von Bugs gefunden. Und weitgehend sind die immer noch vorhanden.Und zu meinem Bauchgefühl, dass dann ja auch der initiale Handshake im Arsch sein müsste, schreibt er:Das reicht von "passiert nichts mehr über der Verbindung" weil der interne Status keinen Sinn mehr macht bis zu crashes. In postgres war das wohl besonders schlimm weil wir a) non-blocking IO verwendet haben und openssl da noch weniger getestet ist b) teilweise sehr viele Daten transferiert werden (replication läuft auch über so eine Verbindung und eine Verbindung kann terrabytes überleben).
Zumindest in openssl würde ich sagen dass das nicht ganz so ist - während die renegotiation in progress ist muss openssl auch noch damit zurechtkommen dass Daten mit dem alten Schlüssel ankommen. Ich finde es schwer dem openssl code wirklich zu folgen, aber soweit ich es verstanden habe sind schlichtweg nicht alle korrekt implementiert.Oha. Mein Verständnis war, dass man renegotiation benutzt, um in TLS auszuschließen, dass die Cipher-Suites in der initialen (unverschlüsselten) Handshake-Negotiation von einem aktiven Angreifer ausgedünnt worden sind. D.h. wenn man Renegotiation wegschmeißt, man messbar Sicherheit einbüßt. Aber vielleicht habe ich das falsch verstanden.Man bemerke auch dass tls 1.3 key renegotiation komplett rausschmeisst.
Ich wäre *sehr* verwundert wenn der "live" renegotiation code in openssl nicht ein paar exploitable bugs hätte.
Update: Ein anderer Einsender erklärt:
bitte nicht Re-Negotiation mit Re-Keying verwechseln.
Re-Keying ist auch in TLS 1.3 noch drin.
Und das ist auch gut so, den im Gegensatz zur Re-Negotiation ist Re-Keying bei vielen (den meisten?) Krypto-Algorithmen einfach notwendig, da mit einem Key nur eine begrenzte Menge an Daten verschlüsselt werden darf, bevor das Verfahren unsicher wird. (z.B. weil dann die Wahrscheinlichkeit, dass zufällig gewählte Nonces per Birthday-Paradoxon mehrfach verwendet werden, zu hoch wird.)
Betrifft nur OpenSSL 1.1, d.h. wurde nach Verkünden des neuen Security-Fokus von OpenSSL eingebaut.
Einmal mit Profis arbeiten!1!!
*fluch* *schimpf* *mecker*
Das erste, was bei Rust auffällt: Man kann es nicht aus den Sourcen bauen. Ich möchte immer gerne vermeiden, anderer Leute Binaries auszuführen. Das ist eine Policy bei mir. Wenn ich es nicht selbst gebaut habe, will ich es nicht haben. Es gibt nur wenige Ausnahmen, bei denen der Buildprozess zu furchtbar ist, oder so fragil, dass das selbstgebaute Binary am Ende nicht so gut funktioniert wie das "offizielle", weil die auf irgendwelche speziellen Compilerversionen setzen oder so. Die einzigen Sachen, die ich hier nicht selber baue, sind im Moment Chrome, Libreoffice (falls ich das so einmal pro Jahr mal brauche) und ripgrep. Und ripgrep wollte ich mal ändern. Außerdem finde ich Rust von den Konzepten her spannend und will mal damit rumspielen.
Erste Erkenntnis: Die neueren Versionen von openssl-rust können OpenSSL 1.1. Allerdings kann man Rust nicht aus den Sourcen bauen, ohne schon eine Version von Rust zu haben. Das finde ich sehr schade. Das ist ein Spannungsfeld, das viele Programmiersprachen betrifft. Programmiersprachen haben Angst, erst ernst genommen zu werden, wenn sie self-hosting sind. Die Download-Seite von Rust will einem erstmal Binärpakete aufdrücken, was ich immer ein schlechtes Zeichen finde. Binärpakete ist der schlechte Kompromiss für Leute, die zu doof sind, aus den Sourcen zu bauen. Und die sind bei Rust nicht Zielgruppe. Dafür ist die Lernkurve zu steil bei Rust.
Aber wenn man runterscrollt, kriegt man auch die Quellen. Und wenn man da configure und make aufruft, dann … zieht der ungefragt ein Binärpaket einer älteren Rust-Version, installiert das, und baut dann damit. Das vereint die Nachteile von "aus Binärpaket installieren" mit der Wartezeit von "aus Quellen bauen" und weicht etwaigen Vorteilen weiträumig aus. Völlig gaga. Aber es gibt eine configure-Option, dass man das installierte Rust haben will.
Aus meiner Sicht ist der perfekte Kompromiss, was Ocaml macht. Da kommen die Quellen mit einem kleinen C-Bootstrap-Interpreter, und der baut dann den Compiler, und der baut sich dann nochmal selber. So muss das sein. Ist es aber bei Rust leider nicht. Bei Go auch nicht mehr, übrigens.
Anyway. Wenn man das über sich ergehen lässt und Rust aus den Sourcen baut, dann kriegt man eine Version ohne cargo. cargo ist das Packaging-Tool von Rust. Ohne cargo kann man nichts bauen. Insbesondere kann man nicht cargo ohne cargo bauen. Und da muss ich sagen: WTF? Selbst GNU make kann man ohne make bauen! Das ist ja wohl absolut offensichtlich, dass man solche Henne-Ei-Probleme vermeiden will!?
Insgesamt muss ich also meine Kritik zurückziehen, dass Rust immer noch nicht mit OpenSSL 1.1 klarkommt. Tut es, nur halt anscheinend nicht in der stable-Version. Aber diese cargo-Situation finde ich ja noch schlimmer als die OpenSSL-Situation war. Meine Güte, liebe Rust-Leute! Bin ich ernsthaft der erste, der über das Bootstrapping nachdenkt?!
Oh ach ja, ripgrep. ripgrep kann man nicht mit der Stable-Version von Rust kompilieren. Und auch nicht mit der Beta-Version. Das braucht die Bleeding-Edge-Version.
Nun ist Rust eine relativ frische Sprache und sie haben daher eine Familienpackung Verständnis für so Kinderkrankheiten verdient. Aber dann nennt euren Scheiß halt nicht Version 1.irgendwas sondern 0.irgendwas.
Update: Wie sich rausstellt, lässt sich ripgrep doch mit älteren Rust-Versionen kompilieren, allerdings dann ohne SIMD-Support. Wenn ich ripgrep ohne SIMD-Support haben wollen würde, könnte ich auch grep -r benutzen oder silver surfer. Was ich versucht habe, um ripgrep zu bauen: git clone + cd ripgrep + ./compile. Mir erklärt jetzt jemand per Mail, dass das gar nicht der offizielle Build-Weg ist unter Rust. Das hat sich mir als Rust-Neuling so nicht erschlossen. Und es wirft die Frage auf, wieso der Autor von ripgrep dann ein configure-Skript beliegen muss und das dann auch noch was anderes tut als der Standard-Buildweg. Ist der Standard-Weg kaputt und man kann die zusätzlichen Flags, die er da benötigt, nicht einstellen?
Update: Ein paar Leute fragen jetzt rhetorisch, wie ich denn meinen C-Compiler gebootstrappt habe. Das Argument könnte man gelten lassen, wenn es von Rust aus möglich wäre, einen C-Compiler zu bootstrappen. Ist es aber nicht. Aber mit einem C-Compiler kann man diverse andere Sprachen bootstrappen, u.a. Go, Lisp, Forth, Scheme, Ocaml, C++, Javascript, Java, .... Aber um kurz die rhetorische Frage zu beantworten: Meinen C-Compiler habe ich cross-compiled. :-)
Update: Bei Ocaml ist es auch nicht so rosig, wie ich es geschildert habe. Der in C geschriebene Interpreter ist bloß ein Bytecode-Interpreter, und ein vor-gebauter Bytecode liegt dann halt binär bei. Ist auch nicht ideal. Das ist halt auch ein schwieriges Problem. Ich frage mich halt, ob man bei sowas wie Rust nicht trennen kann. Mein Verständnis war, dass die Sprache Rust schon ziemlich final ist und die Dynamik eher in der Laufzeitumgebung und den Libraries ist. Dann könnte man ja beispielsweise einen Minimal-Interpreter oder Nach-C-Übersetzer bauen, der sich die komplizierten Dinge wie Borrow-Checker, Solver und Optimizer spart.
The highest security defect being fixed is classified as severity "High", and does not affect OpenSSL versions prior to 1.1.0.
Sind die alle im Winterschlaf oder was?
Einmal mit Profis arbeiten!
Ich kann hier übrigens seit Wochen kein Rust kompilieren, weil deren Packaging-Tool cargo openssl benutzt und das Modul dafür nicht mit Version 1.1 kompiliert.
Zu früh gefreut! Am 22. September kommt mal wieder ein Sicherheitspatch raus, wieder katastrophal was mit HIGH dabei.
Die Shared Library hat eine neue Version, d.h. man muss einmal alle Software neu bauen. wget, curl, alles. curl baut gegen das neue OpenSSL, aber ist damit allein auf weiter Flur. wget musste ich patchen, mutt musste ich patchen, neon (für Subversion) musste ich patchen. git war gut. Der SSL-Code aus gatling geht überraschenderweise auch ohne Änderung. Aber sonst so? Kahlschlag.
Python baut zum Beispiel nur die Module _hashlib und _ssl nicht mit. Ihr könnt euch ja ausmalen, was das alleine an Folge-Infrastrukturapokalypse nach sich zieht. Bei mir konkret geht daher gerade SCons nicht, welches das Buildsystem von serf ist, ohne das ich Subversion nicht reparieren kann.
Die Perl-Module gingen auch. Aber so gefühlt ist über die Hälfte der Software jetzt zerbrochen.
Ich hätte mir ehrlich gesagt erhofft, dass die OpenSSL-Leute da eine klitzekleine Warnung in ihren Bart säuseln, bevor sie so eine Apokalypse lostreten.
Auf der anderen Seite ist das ja auch ein schöner Impuls, mal generell von diesem OpenSSL wegzumigrieren.
Update: Bei Debian hat es auch das eine oder andere Paket zerrissen.
Update: Ein Leserbrief dazu:
Wollte nur kurz darauf hinweisen, daß die API-Änderungen bei OpenSSL 1.1 nicht nur jede Menge inkompatibilitäten nach sich ziehen, bei denen was laut kaputt geht (compiletime error), sondern auch API-Änderungen dabei sind, die stillschweigend security-buigs erzeugen können.
Beispiel: Die HMAC manpage sagt:
HMAC_Init_ex() initializes or reuses a HMAC_CTX structure to use the
function evp_md and key key. Either can be NULL, in which case the
existing one will be reused.HMAC_Init_ex liefert erst seit kurzem einen Fehlerstatus zurück - früher hatte sie keinen Rückgabewert und konnte nicht fehlschlagen. Daher testet auch ne Menge Software nicht auf sowas, und das wra bis vor kurzem auch korrekt.
In OpenSSL 1.1 gibt es aber folgende Änderung:
/* If we are changing MD then we must have a key */
if (md != NULL && md != ctx->md && (key == NULL || len < 0))
return 0;d.h. anders als dokumentiert, kann nicht "either NULL" sein. Aber alte Software kann das nicht prüfen, und welche HMAC dann im Endeffekt berechnet wird, steht in den Sternen.
Die Reaktion von OpenSSL upstream war, die Doku zu ändern.
D.h. nicht nur breaked openssl die API (teilweise unnötig) so, daß Programme nicht mehr kompilieren, nein Programme, die mal korrekt waren und jetzt immer noch kompilieren haben jetzt unter Umständen größere Sicherheitslöcher.
(Es gibt eine Reihe ähnlicher stiller API-Änderungen in OpenSSL 1.1)
(und ja, wegmigrieren hört sich gut an, aber es gibt häufig keine alternative mit gleichen Funktionsumfang ohne diese Probleme - gnutls hat z.b. mindestens bis vor kurzem kein RSA-OEAP padding unterstützt, sondern nur das extrem anfällige kaputte PKCS-padding).
Und zu meiner Aussage, dass interne Typen opak gemacht wurden, kommentiert der Einsender noch:
Das, so würde ich sagen, ist falsch. Erstens sind viele dieser Datentypen nicht intern, sondern man musste früher darauf zugreifen weil es keine accessors gab und das auch so dokumentiert war, und zweitens ist das Hautproblem nicht, daß die Typen opak sind, sondern daß man früher structs selbst allozieren musste und das jetzt nicht mehr geht, d.h. alter code nicht compiliert, auch wenn er nicht auf irgendwelche strukturen zugegriffen hat.
Der Hintergrund für viele solche Änderungen war, daß man man structs nicht mehr auf dem Stack hat - sehr löblich. Das wurde aber so gelöst, daß man jetzt alles dynamisch über eine spezielle openssl-Funktion allozieren muss, die es früher nicht gab, und code, der die structs selbst deklariert hast, schlägt fehl, weil der Typ opak ist, auch, wenn garnicht darauf zugegriffen wird.
Im Allgemeinen ist es deshalb nicht möglich, code zu schreiben, der mit der neuen und der alten API funktioniert (also, ohne #if-massengrab).
Mir ist aufgefallen, dass auch Code mit #if-Massengrab bricht mit Version 1.1. Früher konnte man mit OPENSSL_NO_SSL2 gucken, ob die verwendete Version mit SSL2-Support kommt oder nicht. OpenSSL 1.1 hat kein SSL2 mehr, aber deklariert auch dieses Präprozessorsymbol nicht.
Update: Noch ein Leserbrief zur OpenSSL-Version:
OpenSSL 1.1 Unterstützung für Python ist fertig, hängt aber noch im Codereview, weil Python Core Devs mit OpenSSL-Kenntnissen Mangelware sind. Neben mir gibt es zur Zeit nur drei weitere aktive, von denen zwei mit anderen Dingen beschäftigt sind. Zum Glück habe ich schon vor einem halben Jahr mit meinem Patch angefangen angefangen und einige Patches bei OpenSSL eingereicht. Andernfalls würden mir jetzt die Zugriffsfunktionen auf diverse struct member fehlen.
https://bugs.python.org/issue26470Zwei weitere Punkte:
1) Es reicht nicht, nur auf OPENSSL_VERSION_NUMBER zu prüfen. LibreSSL hat OPENSSL_VERSION_NUMBER gekapert und missbraucht das Makro für die eigene Versionsnummber 2.x. Man muss also immer noch zusätzlich auf nicht-LibreSSL testen:
#if (OPENSSL_VERSION_NUMBER > 0x10100000L) || !defined(LIBRESSL_VERSION_NUMBER)2) Nach sweet32 hat OpenSSL 1.0.2 nur noch einen sicheren Algorithmus für symmetrische Verschlüsselung. ChaCha20 gibt es erst in 1.1. Ich habe mit Richard Salz vom OpenSSL Team gesprochen. Er teilt meine Sorge, trotzdem wird OpenSSL 1.0.2 LTS keine Unterstützung für ChaCha20 erhalten.
https://twitter.com/ChristianHeimes/status/768434388052938756
Nur falls jemand dachte, hey, dann bleib ich halt bei OpenSSL 1.0.2! Übrigens sei an der Stelle der Hinweis erlaubt, dass Version vor 1.0.1 schon länger gar keine Updates mehr kriegen. Man sieht vereinzelt da draußen noch OpenSSL 0.9er-Versionen rumfliegen. Ganz, GANZ gruselig.
Das mit Chacha20 war bei mir übrigens auch der Auslöser für den Umstieg auf 1.1. OpenSSL 1.1 hat nämlich endlich Support für die Dan-Bernstein-Erfindungen Chacha20 und Poly1305. Je älter ich werde, desto weniger traue ich Krypto-Sachen, die nicht von djb kommen oder von ihm abgenickt wurden. Der Mann hat einfach zu oft Recht behalten, als alle anderen abgewunken, relativiert oder gelacht haben. Ich sehe übrigens keinen inhaltlichen Grund, wieso man Chacha20 und Poly1305 nicht auch in 1.0.2 haben sollte, das gibt es seit Jahren für 1.0x-Versionen von OpenSSL als Patch, und LibreSSL hat es auch von Anfang an drin. Finde ich absolut unverständlich, was das OpenSSL-Team sich da leistet.
Besonders beunruhigend:
Remote code execution vulnerability in OpenSSL & BoringSSLNanu? Neue Lücke? Nein! Die hier! Seit Mai bekannt. Redhat hat (um nur mal ein Beispiel für eine andere Linux-Distribution zu nennen) seit dem 10.5. ein Patch draußen. Android wird jetzt gefixt. Ein Bug, den sie als "remote code execution" einschätzen und selbst als kritisch einstufen.
Soll das ein Scherz sein? Ist das der Versuch, Microsoft weniger lahmarschig aussehen zu lassen?
Naja auf der anderen Seite ist das Bulletin auch schon wieder fast nen Monat alt. Keine Ahnung, wieso das jetzt erst die Runde macht.
Die gefixten Bugs sind mehrere Memory Corruptions, die OpenSSL da jeweils als "keine akute Gefahr für die Anwohner" runterzureden versucht, und einem Fall von "ein MITM kann den Traffic entschlüsseln". Die Analyse mag im Einzelfall zutreffen, dass die Memory Corruption-Bugs normale SSL-Server nicht betreffen, aber damit sollte sich niemand rausreden und das Patchen verschieben!
Double free (auch bekannt als remote code execution). Severity low. Ja nee, klar.
Oh hier, noch einer. Memory Corruption. Auch bekannt als remote code execution. Severity low.
Phew, und ich habe mir schon richtig Sorgen gemacht!
Oh, und … das hier. Aber das betrifft euch bestimmt nicht, denn ihr habt bestimmt SSL2 deaktiviert. Habt ihr doch, oder? ODER?
Ich hätte mich da auch bewerben können, aber habe es nicht getan, weil ich lieber wollte, dass das jemand macht, der die ganzen Crypto-Details so gut versteht, wie ich typische C-Programmierfehler verstehe. Kurz: Ich habe mir Sorgen gemacht, dass wenn ich das mache, dass ich das dann nicht richtig abdecke. Sondern halt nur den Teil wirklich angucke, den ich halt besonders gut kann, und über den Rest im schlechtesten Fall gar nichts sagen kann oder im besten Fall zwar geguckt habe, aber möglicherweise nicht genug Hintergrundwissen oder Durchdringung der Materie mitbringe, so dass meine Aussage kein großes Gewicht hat am Ende.
Nun, der Audit hat stattgefunden.
Zu meiner großen Enttäuschung muss ich jetzt konstatieren, dass das dann halt andere Leute genau so gemacht zu haben scheinen, wie ich es bei mir vermeiden wollte. Die haben halt da geguckt, wo schon Lücken bekannt waren, und haben dann diese Lücken nicht mehr gefunden. Diesen Audit hätte man sich auch sparen können. Einen Black-Box-Audit auf den Zufallszahlengenerator? Soll das ein Scherz sein!? Und dann gnädigerweise auch mal kurz ein paar Zeilen Quellcode angeguckt?!?
Das war ein Reinfall. Das wäre ja sogar besser geworden, wenn ich mich beworben hätte. Und das ist keine starke Aussage, siehe oben.
Sehr schade. Eine vertane Chance.
Wobei ich meine Einschätzung jetzt natürlich auf diese Meldung bei Heise stütze. Vielleicht ist die ja falsch und es war besser als es sich da jetzt anhört.
Update: Einer der Auditoren hat mir eine Mail geschrieben:
Die Darstellung in deinem Blogeintrag bzw. Heise ist nicht korrekt (http://blog.fefe.de/?ts=a842a5a6).
Die Analyse des RNG war nur im ersten Schritt Black-Box (wodurch Schwächen gefunden wurden). Im zweiten, selbstverständlich aufwändigeren Teil haben wir uns den Source Code angeschaut, ein Modell des RNG-Algorithmus aufgebaut, den Lebenszyklus des RNGs und dessen Zustand angeschau, etc. Die Methodik ist im Bericht dokumentiert, ein Blick in das Inhaltsverzeichnis liefert schon Informationen dazu.
Bei der Schwachstellenanalyse wurde ähnlich vorgegangen. Es wurden Blackbox-Tests durchgeführt (durch die Schwächen gefunden werden konnten), sowie eine Code Review verschiedener wichtiger Komponenten durchgeführt. Wir mussten selbstverständlich den Scope einschränken (wen interessiert schon die GOST und SSL3.0-Implementierung?), aber denken, dass die wichtigen Komponenten in einem angemessenen Rahmen betrachtet wurden.
Nach meiner Einschätzung würde sich das BSI mit einer oberflächlichen Analyse nicht zufrieden geben. Da sitzen Leute, die sich mit der Thematik sehr gut auskennen.
Update: Hier ist das PDF des Berichtes.
Update: Oh, es gibt nicht nur ein PDF, sondern drei.
Aber grämt euch nicht, die Lücke betrifft nur die 1.0.2-Serie.
Die, die ich überall ausgerollt habe, weil ich annahm, der neue Code sei weniger beschissen als der alte Code bei denen.
Seufz.
Einmal alle rumlaufen und alles updaten, bitte!
Ich bin ja generell kein Freund von Severity-Ratings, denn alles, was das tut, ist Leuten Ausreden an die Hand geben, wieso sie das Update verschieben können. In diesem Fall sind alle der Ratings Moderate oder kleiner, d.h. das sieht schon wieder so aus, als könne man sich das Update auch sparen, alles nicht so schlimm. Aber lest euch das mal durch. Das eine heißt, dass die NSA möglicherweise euren Private Key raten kann, wenn ihr DHE-Suites anbietet. Aber ist nur moderate, weil, äh, ach naja, wer hat schon so viel Ressourcen wie die NSA!1!! Ein anderer Bug ist ein Double Free, das würde bei Microsoft zum Beispiel sofort als Remote Code Execution und gelten und ein Critical kriegen. Also lasst euch nicht verarschen, updated alle euer openssl. Jetzt.
Es handelt sich um ein Problem, mit dem man Zertifikatsvalidierung umgehen kann. Gefunden und gefixt wurde das Problem von BoringSSL, dem Google-Fork von OpenSSL.
Mich stört im Moment, dass der non-blocking Mode dir zwar sagt, er ist noch nicht fertig, aber er sagt dir nicht, ob er jetzt schreiben oder lesen wollte und das geblockt hätte. Das ist für ein Event-basiertes Framework wie in gatling aber notwendig. Mal schauen, ob da nur die Doku scheiße ist, oder auch der Code :)
Ich habe ja mein SSH schon vor einer Weile auf djb-Krypto umgestellt (hier hatte ich das beschrieben). Es ist leider auffallend schwierig, mit regulären Browsern djb-Krypto im TLS hinzukriegen. Firefox supported das noch nicht (warum eigentlich nicht?), Chrome supported es angeblich, aber ich kriege das nicht negotiated. OpenSSL kann es nicht (es gibt einen alten Patch, der aber nicht auf aktuelle Versionen passt), PolarSSL kann es nicht, BoringSSL kann es zwar, aber die Knalltüten haben das Buildsystem auf cmake umgestellt, und da krieg ich die dietlibc nicht reingepfriemelt. Das muss mir auch noch mal jemand erklären, wieso heutzutage jedes gammelige Hipsterprojekt sein eigenes Buildsystem braucht. Bei autoconf ist wenigstens dokumentiert, wie man da von außen eingreifen kann. Aber dieses cmake ist in der Beziehung nur für den Arsch, ich komm aus dem Fluchen gar nicht raus.
Und so bleibt mir im Moment nur LibreSSL, das kommt in der portablen Version mit autoconf und funktioniert mit dietlibc, und da taucht das auch in der Cipherliste auf, und wenn ich mit openssl s_client die Verbindung aufmache, kriege ich auch ECDHE-ECDSA-CHACHA20-POLY1305, aber mit Chrome? Kein Glück.
Und, mal unter uns, solange man da nicht von Hand noch eine ordentliche Kurve konfiguriert, ist das auch Mist. Von den Kurven, die OpenSSL unterstützt, scheint nur secp256k1 akzeptabel.
Das Problem ist, dass Diffie Hellman praktisch die Basis von allen Online-Public-Key-Kryptographiesystemen da draußen ist — SSH, TLS, IPsec, … Schlimmer noch: Wir haben das bei TLS massiv forciert, weil Diffie Hellman erst für Perfect Forward Secrecy sorgt. Das ist die Eigenschaft eines Protokolls, dass wenn die Cops kommen und den Server mit dem Schlüssel drauf beschlagnahmen, sie damit trotzdem nicht vorherige verschlüsselte Verbindungen entschlüsseln können.
Was ist jetzt genau das Problem?
Erstens gibt es eine Downgrade Attack. Downgrade Attack heißt, dass jemand von außen die Pakete im Netz manipuliert. Nehmen wir an, ich verbinde mich zu https://blog.fefe.de/, und die NSA sieht die Pakete und manipuliert sie. Eine Downgrade Attack heißt jetzt, dass die NSA (vereinfacht gesagt) in meinen Handshake-Paketen die ganzen harten Verfahren aus der Liste der unterstützten Kryptoverfahren rausnimmt. Der Server nimmt sich das härteste vorhandene Verfahren, aber wenn die NSA die Liste manipulieren kann, dann ist das halt nicht sehr hart. TLS hat dagegen bezüglich der Cipherliste Vorkehrungen getroffen, aber jetzt kommt raus, dass die NSA von außen die Diffie-Hellman-Bitzahl auf 512-Bit runterschrauben kann. Das ist eine Katastrophe. Die einzige Lösung hierfür wäre, wenn die Server schlicht keine schwachen Diffie-Hellman-Schlüssel mehr zulassen würden. Dann käme keine abhörbare Verbindung zustande. Die NSA kann dann zwar immer noch verhindern, dass ich eine Verbindung aufnehme, aber das kann sie eh, unabhängig von Krypto.
Das zweite Problem ist noch gruseliger. Und zwar galten die Diffie-Hellman-Parameter immer als öffentlich. Das ist sowas wie ein Zahlenraum, auf den man sich einigt, in dem man dann seine Krypto-Operationen macht. Das hat dazu geführt, dass viele Server am Ende des Tages die selben Parameter verwenden. Jetzt stellt sich aber raus, dass der erste Schritt im Algorithmus zum Brechen von Diffie Hellman nur auf diesen Parametern basiert, nur auf einer Primzahl. Und wenn da alle die selbe verwenden, dann muss ein Angreifer diesen ersten Teil auch nur einmal machen. Das ist eine ganz doll gruselige Erkenntnis!
Was kann man denn jetzt tun? Zwei Dinge. Erstens müssen wir jetzt dafür sorgen, dass unsere Server "Export-Verschlüsselung" (also absichtlich geschwächte Krypto) auch bei Diffie Hellman nicht mehr akzeptieren. Ich glaube im Moment, dass man dafür die SSL-Libraries patchen muss, weil es kein API gibt. Aber ich kann mich da auch irren, vielleicht gibt es ein API. In dem Fall müsste man die ganzen Server patchen, damit sie das API benutzen.
Und der zweite Schritt ist, dass man dem Server schlicht Diffie-Hellman-Parameter vorgibt. Die erzeugt man unter Unix mit
$ openssl dhparam -out dhparams.pem 2048Man kann auch noch größere Parameter machen, aber das sollte man dann über die Mittagspause laufen lassen, das dauert ewig und drei Tage. Und dann muss man der Serversoftware sagen, dass sie diese DH-Parameter verwenden soll. Lest die Dokumentation. Das ist wichtig!
Klingt alles schon apokalyptisch genug? Wartet, kommt noch krasser!
Breaking the single, most common 1024-bit prime used by web servers would allow passive eavesdropping on connections to 18% of the Top 1 Million HTTPS domains. A second prime would allow passive decryption of connections to 66% of VPN servers and 26% of SSH servers. A close reading of published NSA leaks shows that the agency's attacks on VPNs are consistent with having achieved such a break.Update: Ich hatte vor nem Jahr mal bei https://blog.fefe.de/ 2048-Bit-Diffie-Hellman-Parameter generiert und das hat mir jetzt wohl den Arsch gerettet an der Stelle. Ein bisschen Paranoia schadet halt nicht :-)
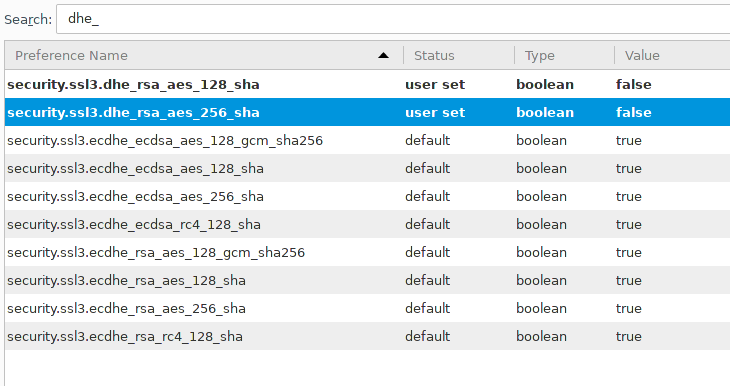
Update: Wer in Firefox die rote Box auf der Logjam-Seite weghaben will, muss in about:config die dhe (nicht die ecdhe!)-Ciphersuiten wegkonfigurieren.
Update: Und natürlich will man auch die ganzen RC4-Ciphersuites wegkonfigurieren, das hatte ich in dem Screenshot jetzt nicht drin, weil ich nur die Einstellungen fett haben wollte, die für Logjam relevant sind.
Wie jetzt, DAS war das dringenste Problem in deren Augen?!? OMFG
ECDHE silently downgrades to ECDH [Client] (CVE-2014-3572)Wait, what?
========================================================== Severity: Low
RSA silently downgrades to EXPORT_RSA [Client] (CVE-2015-0204) ============================================================== Severity: LowSurely some mistake?
DH client certificates accepted without verification [Server] (CVE-2015-0205) ============================================================================= Severity: LowUnd zu guter letzt kann auch noch der Fingerprint modifiziert werden und ihre Quadrier-Routine verrechnet sich gelegentlich. Ihr seht schon: Alles totale Randgruppenprobleme, kein Grund zur Beunruhigung.
Update: Falls jemandem die Signifikanz nicht klar war: Der Unterschied zwischen ECDHE und ECDH ist Perfect Forward Secrecy. Das heißt, dass wenn die Polizei den Serverschlüssel beschlagnahmt, sie trotzdem nicht damit die alten NSA-Mitschnitte entschlüsseln kann. TLS ohne Perfect Forward Secrecy auszurollen kann man sich meiner Meinung nach auch gleich sparen.
Unfortunately, because of the large number of sites which incorrectly handled TLS v1.2 negotiation, we had to disable TLS v1.2 on the client.Dass diese Debilianisten und ihre Abkömmlinge das aber auch nicht lernen, die Finger von OpenSSL-Patches zu lassen!
Secure Connection Failed.An error occurred during a connection to blog.fefe.de. SSL received a record that exceeded the maximum permissible length. (Error code: ssl_error_rx_record_too_long)
Mein Blog hat ja schon seit einer Weile SSLv3 deaktiviert, aber jetzt hatte ich auch openssl ohne SSLv3-Support gebaut. Vielleicht ist es das. Mann ist das immer eine Freude mit diesen ganzen Hochtechnologien!Update: Ich habe die Gelegenheit genutzt, mal den PolarSSL-Support in gatling zu updaten. Mal gucken, ob das jetzt stabil läuft hier.
We show here how to put together an effective attack against CBC encryption as used by SSL 3.0, again assuming that the attacker can modify network transmissions between the client and the server. Unlike with the BEAST [BEAST] and Lucky 13 [Lucky13] attacks, there is no reasonable workaround. This leaves us with no secure SSL 3.0 cipher suites at all: to achieve secure encryption, SSL 3.0 must be avoided entirely.Ein OpenSSL-Update gibt es noch nicht, und die OpenSSL-Webseite in der SSL-Version ist für mich auch gerade nicht erreichbar. LibreSSL hat gerade erst 2.1 released, ob die schon sicher ist weiß ich nicht.Wer sich jetzt Sorgen macht, SSL 3 abzuschalten: das SSL bei meinem Blog erlaubt seit April kein SSL 3 mehr. Es gab Null Beschwerden deshalb.
Update: Kurze Stellungnahme meinerseits, "wie schlimm" das ist. Das MITM-Zeug betrifft mich im Allgemeinen nicht, weil auf der anderen Seite üblicherweise nicht OpenSSL sitzt (Ausnahmen sind irgendwelche RSS-Reader), das ist aber ein ziemlicher Klopper. Ausgesprochen peinlich, und offenbar seit Tag 1 dabei. Das DTLS-Zeug betrifft so gut wie niemanden, weil niemand diesen DTLS-Bullshit einsetzt. Ausnahmen wären irgendwelche WAP-Geschichten oder Mobil-Spezial-Fummeleigeschichten. Ich würde auch weiterhin empfehlen, DTLS weiträumig aus dem Weg zu gehen. SSL_MODE_RELEASE_BUFFERS hätte man extra reinkompilieren müssen. Ich habe das nicht getan, ob Debian oder so das getan haben — keine Ahnung. Anonymous ECDH betrifft hoffentlich auch niemandem. Anonymous Cipher Suites sind ein Hirnkrebs, den sich die TLS-Leute ausgedacht haben, bei denen weder Client noch Server ein Zertifikat vorzeigen muss. Das hat hoffentlich überhaupt niemand jemals irgendwo angeschaltet.
Unter dem Strich also: natürlich trotzdem sofort updaten. Aber auf der Skala von 1 bis Heartbleed war das näher bei 1 als bei Heartbleed.
Update: Es sieht so aus, als sei auch der kaputte DTLS-Code wieder vom Heartbleed-Autoren gekommen. Ob der deshalb gefunden wurde?
Nein, muss es nicht. Im Gegenteil. Das wäre das Ende von Open Source.
Außerdem lässt es der Artikel so klingen, als habe sich jetzt herausgestellt, dass Open Source Software weniger gut als kommerzielle sei. Das ist ganz großer Unsinn (auch wenn es natürlich auf beiden Seiten Ausreißer gibt, die deutlich besser als der Durchschnitt der anderen Seite sind).
Open Source als Bewegung ist das Konzept, dass man Leute Code schreiben lässt, deren Herzensblut dranhängt. Die es eben nicht kurz herunterpfuschen, weil sie dafür bezahlt werden. Open Source ist die Beobachtung, dass manche Menschen es lieben, Code zu schreiben. Und wenn man sie nicht mit Deadlines und Deliverables und dem monatlichen Paycheck unter Druck setzt, dann nehmen sie sich die Zeit und machen ihr Projekt ordentlich. Viel ordentlicher jedenfalls als die durchschnittliche kommerzielle Software.
Inzwischen wird kommerzielle Software wie Open Source entwickelt. Weil das Modell funktioniert. Kaum eine Firma entwickelt heute noch Software ohne Unit Tests, ohne Source Code-Versionskontrolle, überall gibt es ein Wiki für die Dokumentation und alle wollen gerne agil sein.
Der Erfolg von Open Source war so durchschlagend, dass es das Gegenmodell gar nicht mehr in freier Wildbahn gibt!
Wenn es etwas gibt, das sich bei Open Source zu ändern lohnt, dann ist es der mangelnde Respekt. Nur weil du gerne Programmieren lernen willst, heißt das nicht, dass du am Linux-Kernel herumfummeln solltest. Deine eigene SSL-Library schreiben? Kein Ding. Tu es! Da kann es nur Gewinner geben, selbst wenn es niemals fertig wird und niemand deinen Code benutzt. Du hast dabei was gelernt und als Programmierer an Größe gewonnen. Ein wenig bekanntes Detail aus der OpenSSL-Genesis ist, dass das mal SSLeay hieß — eay sind die Initialen des initialen Autoren, Eric Young —, und der hat das Projekt gestartet, weil er lernen wollte, wie die Division von 1024-Bit-Zahlen funktioniert.
Der Kern des Problems ist aus meiner Sicht, dass wir als Gesellschaft uns darauf geeinigt haben, dass Software halt ein schwieriges Problem ist, und daher Fehler halt passieren und niemand für seine Fehler geradestehen muss. Man kann sich heute bei so gut wie allen Problemen mit "das war ein Softwarefehler" herausreden. Für mich als Programmierer ist das natürlich auf der einen Seite toll, weil ich mich so Dinge trauen kann, die ich sonst nicht in Angriff nehmen würde. Aber es hat in der Szene so ein wirklich widerliches Gefühl erzeugt, als hätten wir Programmierer es verdient, als sei das unser Recht, niemals für unseren Scheiß den Kopf hinhalten zu müssen. Ich will das mal anhand dieser Tweets veranschaulich. So tief sitzt da die Panik! So ein Affront für das Weltbild ist es, dass möglicherweise jemand kommen könnte, und der sieht, dass ich gepfuscht habe! Sowas finde ich zutiefst unwürdig. Als ob der Auditor Schuld hat, wenn dein Code Scheiße ist! Wenn bei einer Frittenbude Küchenschaben gefunden werden, ist dann das Gesundheitsamt der Bösewicht? Wenn GM kaputte Autos baut, und da sterben Leute, glaubt ihr auch, die Zuständigen machen sich in erster Linie Sorgen wegen der Hater aus dem Internet? Anders gefragt: Würde irgendjemand von euch von einer Firma kaufen, die nur Qualitätskontrolle macht, weil sie Angst vor Internet-Hatern hat, wenn herauskommt, wir ranzig ihr Produkt ist?!
Dass überhaupt das Wort "Hater" gefallen ist, sagt aus meiner Sicht schon alles. Wenn du etwas baust, dann sollte das der güldene Sonnenschein sein, nach frisch gebackenem Brot durften und die filigrane Eleganz eines mathematischen Beweises haben. Und zwar nicht weil es da draußen "Hater" gibt, sondern weil das dein verdammer Anspruch an dich selbst ist! Wenn jemand kommt und dich auf Fehler in deinem Code hinweist, dann solltest du auf die Knie fallen und dem Fremden überschwänglich danken, denn er hilft dir, deinen Code näher an die Zielvorstellung der Perfektion zu bringen!
Ich glaube nicht, dass bei Software so viel mehr gepfuscht wird als anderswo. Aber physische Dinge sind vergänglich. Fehler bei physischen Dingen gehen von alleine weg, mit den Dingen selbst. Software lebt theoretisch für immer. Softwarefehler akkumulieren immer nur. Aus meiner Sicht müssen wir Software wie radioaktiven Müll behandeln — vorsichtig und mit Bedacht.
Nachdem ich all das gesagt habe, möchte ich noch sagen: Schreibt mehr Software! Aber macht es ordentlich!
Update: Jetzt bin ich ganz von meinem eigentlichen Gedankengang abgekommen. Open Source funktioniert, weil es eben nicht geldgetrieben ist. Der Programmierer zieht seinen Anreiz, die Software zu schaffen, aus der kreativen Freude des Programmierens, und aus dem Zen-ähnlichen Zustand, wenn ein komplexer Algorithmus, den man hingeschrieben hat, dann tatsächlich funktioniert. Guter Code ist seiner selbst Belohnung. Wenn man dort Geld als Anreiz einbringt, dann wird das dieses Modell kaputtmachen. Programmierer werden dann anfangen, die Arbeit pro eingenommenem Euro zu minimieren. Genau wie das überall eintritt, wo man Geld für Arbeit zahlt. Am Ende wird man feststellen, dass die Stundenlöhne anderswo niedriger sind als bei uns, und dann wird niemand mehr in Deutschland Open Source programmieren wollen. Nur weil man das mentale Modell so umgebaut hat, dass wir das "für Geld" tun, nicht um etwas zu lernen, oder den anderen Gründen. Macht das bloß nicht!
Geld für Dinge ausgeben, bei denen niemand kreative Genugtuung erfährt, das kann man diskutieren. Ich glaube, das wird man auch machen müssen, damit auch bei den SSL-Libraries wieder Open Source qualitativ führend ist. Aber fangt nicht an, das Belohnungsmodell von Open Source Programmieren auf "da gibt es Geld für" umzustellen. Das wäre der Untergang.
Update: Ich will mal eine Kommentarmail hier zitieren:
In der Psychologie unterscheidet man zwischen extrinsischer und intrinsischer Motivation. Intrinsische Motivation bedeutet, dass man etwas tut, weil es einem Spass macht, weil man es für richtig hält etc. Extrinsische Motivation bedeutet, dass man etwas tut, weil man eine Belohnung dafür erhält. Sozialpsychologische Experimente haben gezeigt, dass man intrinsische Motivation unwiederbringlich zerstören kann, indem man einen extrinsischen Anreiz schafft, etwas zu tun.
Update: Noch eine Einsendung:
Die moderne Motivationsforschung sagt an dieser Stelle „Nein“, weil die Programmierer bereits in dem Moment wo sie Geld bekommen den Spaß verlieren würden, aus Spiel wird dann Arbeit. Das Ganze geht auf die Selbstbestimmungstheorie der Motivation von Deci & Ryan, 1985a zurück (s. Wikipedia). Lese grade Drive von Daniel Pink (ISBN 978-1847677686), was die gedankliche Grundlage für die agile Softwareentwicklung z.B. Scrum beschreibt. Bei modernen Softwareschmieden gehört diese Kenntnis mittlerweile auch zum Einstellungskriterium.
Update: Der Vollständigkeit halber: Dieser Bug sieht auf den ersten Blick nicht backdoorfähig aus. Eher nach Schlamperei oder Inkompetenz. (Danke, Florian)
OpenBSD hat einen Audit angestoßen und der zeitigt erste Ergebnisse.
Und nicht zuletzt: Coverity, einer der bekannteren Code-Scanner, der hat Heartbleed nicht erkannt. Der Firma ist das einigermaßen peinlich, daher haben sie jetzt nach Heuristiken gesucht, um sowas doch zu finden, und dabei hatten sie eine relativ smarte Idee: Endianness-Konvertierung markiert bei denen jetzt Variablen als vergiftet. So gehen Code-Auditoren wie ich auch vor.
Ich habe die Tage erfreut festgestellt, dass PolarSSL auch ECDSA kann inzwischen, EDH eh schon, und jetzt auch GCM. Damit haben sie soweit alle wichtigen Features. Auf Client-Seite ist die Zertifikats-Validierung wohl noch nicht so toll, ich verlinkte neulich die Frankencert-Tabelle. Aber das ist ja serverseitig wurscht, außer man will Client Certs haben, was so gut wie niemand tut. Das ist neben OpenSSL die andere unterstützte SSL-Engine in gatling und von der Codequalität her macht sie einen ganz guten Eindruck. Viel kleiner und ordentlicher und weniger Makrohölle als OpenSSL. Klein genug, dass eine Einzelperson davon realistisch einen Komplett-Audit machen könnte.
Ich möchte die Gelegenheit nutzen, nochmal darauf hinzuweisen, dass ich selbstverständlich nicht behauptet habe, Herr Seggelmann habe hier absichtlich eine Backdoor programmiert. Ich habe behauptet, dass er den Code programmiert hat. Dazu verlieh ich meiner Einschätzung Ausdruck, dass der Code wie eine Backdoor aussieht. Nicht dass es eine ist. Denn das kann man anhand des Codes auch gar nicht entscheiden, wie ich auch in dem FAZ-Artikel ausführe. Daher gibt es auch keine Grundlage für so eine Behauptung.
Update: Spon hat den Artikel umgeschaltet, und sie haben mir versichert, dass es nicht so gemeint war, wie es da stand. OK. Schwamm drüber.
Ob da noch mehr Gruselkram kommt?
Update: Jetzt geht auch http nur noch seeeeehr langsam. WTF? (Danke, Stefan)
Hier ist der git commit. Das ist aber nicht der Punkt hier gerade.
Wo arbeitet der? Was meint ihr? Kommt ihr NIE drauf!
Robin Seggelmann T-Systems International GmbH Fasanenweg 5 70771 Leinfelden-Echterdingen DE
Update: Eine Sache noch. Nehmen wir mal an, jemand würde mich bezahlen, eine Backdoor in OpenSSL einzubauen. Eine, die auf den ersten Blick harmlos aussieht, die aber ohne Exploit-Schwierigkeiten auf allen Plattformen tut und von den verschiedenen Mitigations nicht betroffen ist. Genau so würde die aussehen.
Ich sehe in dem Code nicht mal den Versuch, die einkommenden Felder ordentlich zu validieren. Und auch protokolltechnisch ergibt das keinen Sinn, so eine Extension überhaupt zu definieren. TCP hat seit 30 Jahren keep-alive-Support. Es hätte also völlig gereicht, das für TLS über UDP zu definieren (und auch da würde ich die Sinnhaftigkeit bestreiten). Und wenn man ein Heartbeat baut, dann tut man da doch keinen Payload rein! Der Sinn von sowas ist doch, Timeouts in Proxy-Servern und NAT-Routern vom Zuschlagen abzuhalten. Da braucht man keinen Payload für. Und wenn man einen Payload nimmt, dann ist der doch nicht variabel lang und schon gar nicht schickt man die Daten aus dem Request zurück. Das ist auf jeder mir ersichtlichen Ebene völliger Bullshit, schon das RFC (das der Mann auch geschrieben hat), das ganze Protokoll, und die Implementation ja offensichtlich auch. Aus meiner Sicht riecht das wie eine Backdoor, es schmeckt wie eine Backdoor, es hat die Konsistenz einer Backdoor, und es sieht aus wie eine Backdoor. Und der Code kommt von jemandem, der bei einem Staatsunternehmen arbeitet, das für den BND den IP-Range betreut (jedenfalls vor ein paar Jahren, ob heute immer noch weiß ich nicht). Da muss man kein Adam Riese sein, um hier 1+1 zusammenzählen zu können.
Update: Es stellt sich raus, dass der Mann damals noch an seiner Dissertation geschrieben hat und an der Uni war und erst später bei T-Systems anfing. In der Dissertation geht es unter anderem um die Heartbeat-Extension, die mit UDP begründet wird. In dem Text steht auch drin, dass man keine Payload braucht. Aber lasst uns das mal trotzdem so machen, weil … Flexibilität und so!
Update: Echte Verschwörungstheoretiker lassen sich natürlich von sowas nicht aufhalten. Der Job bei T-Systems war dann halt die Belohnung!1!! Und echte Verschwörungstheoretiker googeln auch dem Typen hinterher, der den Code auditiert und durchgewunken hat, damit der eingecheckt werden konnte. Ein Brite, der nur 100 Meilen von Cheltenham (GCHQ-Sitz) entfernt wohnt!!1!
Update: Robin Seggelmann hat der australischen Presse erklärt, das sei ein Versehen gewesen.
Update: Hier ist eine Gegendarstellung dazu von Herrn Seggelmann:
Der Fehler ist ein simpler Programmierfehler gewesen, der im Rahmen eines Forschungsprojektes entstanden ist. T-Systems und BND oder andere Geheimdienste waren zu keiner Zeit beteiligt und zu meiner späteren Anstellung bei T-Systems bestand zu keiner Zeit ein Zusammenhang. Dass T-Systems im RFC genannt wird, liegt an der verspäteten Fertigstellung des RFCs und es ist üblich, den bei der Fertigstellung aktuellen Arbeitgeber anzugeben.
(Danke, Jürgen)
Naja, kein Problem, dachte ich mir, für sowas gibt es ja eine Rescue-Umgebung. Wollte die klicken — der Knopf fehlte im Webinterface. Nanu? Ticket aufgemacht. Knopf da. Knopf gedrückt — Server platt, kein Rescue kommt hoch. Ticket aufgemacht. Pause. Antwort: Wir haben da mal ne Intel e100 NIC eingebaut, damit das Rescue hochkommt, und die Onboard-NIC ausgemacht. Musst du dann in deinem Debian fixen.
Die Meldung sah ich aber erst, nachdem ich mein Problem gefixt hatte, und umgebootet hatte, und da kam dann das System zwar hoch, aber ohne Netzwerk.
Also zurück ins Rescue, aber das kam dann auch nicht mehr hoch. Ticket aufgemacht. Die haben irgendwas gebastelt, damit kam das wieder hoch.
Oh, erwähnte ich, dass das Rescue-System ohne mdadm kam? Ich hab seit gefühlt 10 Jahren kein Rescue-System mehr gebraucht. Stellt sich raus, dass sowas heutzutage ein richtiges Debian ist, wo man konfigurieren kann, inklusive apt-get install mdadm. Allerdings will er dafür über 50 MB nachladen, also hab ich lieber ein statisches dietlibc-mdadm hochgeladen und benutzt.
Das Problem, so stellte sich raus, war: Die e100-Netzwerkkarte möchte gerne Firmware nachladen, die nicht da war. Ich trag also das Repository ein und rufe apt-get auf … da baut irgendein Debian-Automatismus eine initrd neu und die ist nicht mehr bootfähig.
Nun hat mir der Hoster freundlicherweise ein KVM zur Verfügung gestellt, sonst hätte ich den Aspekt gar nicht sehen können. Aber mit der neuen initrd fand der Kernel sein root-fd nicht und panicte.
Die nächsten Schritte waren: Debian dist-upgrade (das war noch ein squeeze), grub erneuern, grub stirbt mit symbol grub_divmod64_full not found. Bekanntes Problem, offenbar, aber die Lösungen funktionierten alle nicht. purge, reinstall, deinstall, config fummel, reinstall, auf die zweite platte auch installieren, half alles nichts.
In der Mitte hatte ich noch versucht, einen eigenen Kernel zu bauen, der auf der Hardware laufen würde, aber der tat es nicht und auf dem 80x25-Screen der KVM sah ich dann auch nur die letzten statischen Zeilen eines generischen Panic-Stackdumps und konnte nicht hochscrollen. Aus irgendeinem Grund kamen Tastatureingaben nicht an über die KVM. Ich tippe auf ein Java-Problem, aber am Ende — who cares.
Der einzige Ausweg war am Ende, dass ich einen eigenen grub 2.02 beta 2 aus den Sourcen kompiliert habe. Der warf zwar auch noch lustige Fehlermeldungen, aber hat dann am Ende den Kernel doch gebootet.
So, jetzt hab ich zwar immer noch einen veralteten gcc und eine veraltete glibc, aber immerhin ist die Kiste wieder oben. Seufz.
Update: Warum war da so ein antikes Debian? Weil alle von außen erreichbaren Dienste eh von mir und nicht von Debian sind.
Update: Es gibt einen xkcd dazu! Großartig, den kannte ich noch gar nicht :-)
Update: Das SSL-Zertifikat ist dann auch mal neu, wegen des OpenSSL-Bugs gerade.
Theorien und Vorschläge nehme ich gerne per Email entgegen. Im Moment tendiere ich zu "die haben ihre LI-Software von Digitask gekauft und die spackt jetzt halt herum" :-)
Update: Bei diversen Leuten geht es offenbar problemlos.
Update: Es gibt einen Schuldigen. CACert hat offensichtlich gerade einen OCSP-Fuckup. Wenn Firefox bei denen eine OCSP-Anfrage für mein Cert stellt, kriegt er ein "403 Access Forbidden" zurück. Mit anderen Worten: Chrome macht kein OCSP. m( Man kann OCSP auch in Firefox ausschalten (security.OCSP.enabled = 0), aber an sich will man ja OCSP haben. Dieses SSL ist echt ein Haufen Sondermüll. Macht Firefox bei jedem Zugriff einen OCSP-Request oder nur einmal pro Tag? Man fragt ja ein spezifisches Zertifikat an, das hieße ja, dass CAcert ein Bewegungsprofil erstellen kann. Mann ist das alles für den Fuß.
Update: Mir mailt gerade jemand: Firefox prüft einmal pro Session, und Chrome macht doch OCSP aber macht daraus keinen Timeout sondern zeigt dann ein kleines gelbes Dreieck als Warnung an.
Hey, but you stand vindicated, because you shouted the correct contact address to the whole world in the 38th comment to the 327th post on your blog (which must surely compare favorably to being posted on the bottom of a locked filing cabinet stuck in a disused lavatory with a sign on the door saying 'Beware of the Leopard'.).Sehr spaßig.Währenddessen gibt es wachsende Spannungen wegen der Tatsache, dass Debian den Fix 5 Tage vor dem Advisory eingepflegt hat. Die Terroristen (oder Debian-Insider, die der Versuchung auf Botnet-Expansion nicht widerstehen konnten) hatten also 5 Tage Zeit, einen Exploit zu entwickeln und damit Rechner zu übernehmen. Wenn man mal bei denyhosts.net guckt, gibt es da auch einen deutlichen Spike [lokale Kopie der Grafik].
Oh übrigens, Spaß mit URL-Redirects: debian.wideopenssl.org :-]
Im Vorstand sitzen KPMG, PwC und Interxion, ein echtes Dream Team, wenn es um Sicherheits-Knowhow geht. Auch ansonsten die ranghöchsten IT-Security-Experten, die sie finden konnten. Ich verstehe nur nicht, wieso da Symantec nicht mitmacht. Die würden da echt zu passen. Sogar eine PR-Agentur ist dabei! Bwahahaha. Im wissenschaftlichen Beirat sitzen zwei Juristen und ein Professor aus der Verwaltung. Dann gibt es da noch einen Exekutivbeirat (was soll das eigentlich sein? Exekutiv oder Beirat?) mit lauter Politikern.
Aber halt, keine IT-Security-Lachnummer wäre perfekt ohne ein "Kompetenzzentrum", bei dem es sich offenbar um eine Vermarktungsplattform für die Mitglieder handelt. Bei "Software-Sicherheit" findet man jedenfalls einen PR-Blurb und eine Weiterleitung zu Compuware, und an die denke ich auch immer ZUERST, wenn ich an Software-Sicherheit denke! Was die DA schon geleistet haben, das weiß JEDER in der Branche!1!!
Update: siehe auch … *schenkelklopf* (einmal alles von php über openssl, zlib und pcre in alt und unsicher, und register_globals ist auch noch On)
there were several reports of OpenSSL being broken when compiled with GCC 4.2. It turns out OpenSSL uses function casting feature that was aggressively de-supported by GCC 4.2 and GCC goes as far as inserting invalid instructions ON PURPOSE to discourage the practice.Das ist ja nicht zu fassen. (Danke, Arne)
{kind=link}
{kind=link}