Fragen? Antworten! Siehe auch: Alternativlos
Da habt ihr doch bestimmt alle nur drauf gewartet, oder? Ein Glück, dass wir so einen Monopolmarkt bei Browsern geschaffen haben.
Hah, ihr dachtet, ihr könntet Microsofts Copilot-Krebsgeschwür entgehen, indem ihr Chrome benutzt, hmm? Falsch gedacht!
10 Jahre nichts, und dann läuft das Cert der Intermediate CA ab.
Für Chromecast 2 device authentication. (Danke, Jörg)
Update: Oh ich habe das wohl falsch interpretiert und das ist keine Änderung in Edge (wie Chrome das mit Google-Diensten gemacht hat). Die ändern die Cookies, damit man sich nicht alle 10 Minuten neu einloggen muss, nur weil irgendeine Session ausgelaufen ist. Das betrifft also nicht nur Microsoft-Browser.
Ich ändere also das PSA: Microsoft-Dienste nur im Private Mode benutzen. :-)
Ich glaube nicht, dass das ernst gemeint ist. Ich glaube, das Kalkül lief etwa so: Biden ist eine lahme Ente, wir sind frisch abgewählt, und Trump hasst unsere Kumpels, die Tech Bros.
Trump findet ja, dass die Social Networks und Suchmaschinen ihn unfair benachteiligt haben, indem sie seine Misinformationen zu bekämpfen und rauszufiltern versucht haben, und hat daher als neuen FCC-Chef (deren Kommunikations-Regulierer) diesen Spezialexperten ausgesucht, der von einem "Zensurkartell" spricht, das man jetzt zerschlagen müsse.
Das ungerechte Zorn der Republikaner richtet sich vor allem gegen Facebook, aber auch gegen Google, wegen Suche und Youtube, wo Google bei Covid-Lügnern Hinweise eingeblendet hat, so man sich inhaltlich belastbarer informieren kann.
Aus Sicht der untoten Democrats im abgewählten Justizministerium ist also absehbar, dass Trump die Tech-Riesen zerschlagen wird. Die Democrats wissen auch, dass Kartelle Scheiße sind, und wenn die Tech Bros nicht alle in Democrat-Hochburgen säßen und dort Arbeitsplätze schüfen, hätte man vielleicht auch schonmal etwas zu unternehmen versucht. Aber hey, wenn die eh demnächst geschlachtet werden, dann kann man wenigstens jetzt so tun, als sei man selbst der Auslöser gewesen, der hier Gerechtigkeit schafft. Denn das Narrativ ist den Democrats ja bereits ziemlich komplett entglitten an der Stelle. Google Search ist so schlecht geworden, dass Googles "das schadet dem Kunden" vor allem Gelächter auslöst.
gatling komprimiert nichts, aber wenn man nach foo.html fragt, und man kann Brotli, und da liegt foo.html.br, dann kriegt man das ausgeliefert. Es kostet also nicht viel, auch kurz nach foo.html.zst zu gucken.
Ich habe das also kurz gemacht. Nota bene: Die Browser, die jetzt zstd können, können auch alle brotli.
Stellt sich raus: brotli komprimiert in eigentlich allen Fällen besser. Das liegt vor allem daran, dass Brotli bescheißt, und mit einem Dictionary an bekannten Wörtern kommt, die aus typischen HTML- und Javascript-Dateien extrahiert wurden.
Das könnte man mit zstd natürlich auch machen. Machen die Browser das? Wüsste ich gerade nicht. Wenn doch, könnte ich meine Dateien natürlich auch mit einem shared dictionary ala brotli zstd-komprimieren.
Ist zstd damit nutzlos? Nein, bei weitem nicht. Wenn man dynamische Daten ausgibt, wie es beispielsweise mein Blog tut, dann kann ich die ja nicht vorkomprimiert ins Dateisystem legen. Also könnte ich vielleicht doch partiell, wenn ich ein bisschen trickse. Mache ich aber nicht.
Jedenfalls: Für mein Blog würde es Sinn ergeben, zstd zu unterstützen. Da mache ich im Moment nur gzip, und das auch nur bei einer relativ kleinen Kompressionsstufe. Da würde sich zstd wahrscheinlich lohnen, weil es vergleichsweise rattenschnell komprimieren kann.
Das ist jetzt jedenfalls ein bisschen antiklimaktisch und ich werde auf die Erkenntnis mal reagieren, indem ich einfach nur zstd-Dateien hinlege, wenn die kleiner als die Brotli-Version sind.
Update: Das Blog kann jetzt zstd. Das hat die Größe des Binaries direkt verdoppelt. Lohnt sich hoffentlich in der Praxis.
Wie? Nein, nicht für euch. Für die Werbeindustrie.
Aus Komfortgründen haben sie auch gleich für alle ihre Kunden das Opt-In durchgeführt. Wer nicht will, kann ja Opt-Out machen!1!!
Die Reaktionen sind entsprechend. Wenn ich der Werbemafia helfen will, kann ich auch gleich Chrome verwenden.
Das ist immer ein gutes Zeichen, wenn der Hersteller selber erkennt, dass er eine Funktion lieber versteckt.
Für Leute ohne Twitter-Account, die den Thread nicht sehen können, gibt es hier einen Screenshot.
NATÜRLICH tun sie das. Was würden die auch sonst tun? Etwa eigene Ideen haben? Dinge zum Vorteil ihrer Kunden tun?
Es ist wieder soweit!
Jemand hat einen Anwendungsfall für Windows Copilot gefunden. Copilot hat ihm geholfen, Copilot zu deinstallieren. (Danke, Ralph)
Add advanced security protections on top of the streamlined management benefits of Chrome Enterprise Core, all with the expertise and scale of Google.Mit anderen Worten: Google sagt uns gerade ins Gesicht, dass der reguläre Chrome-Browser unsicher ist. Setzt den jemand von euch ein? Ich hoffe nicht! Wenn nicht mal der Hersteller den für sicher hält!?Was kriegt man denn für das Geld? "Malware deep scanning"! Auf der anderen Seite ist Idioten von ihrem Geld zu trennen das älteste Geschäftsmodell der Welt. (Danke, Kris)
Damit haben sie dann in Snapchat, Youtube und Amazon-Webaufrufe reingeguckt, um ihre Konkurrenz zu analysieren.
Der eine oder andere von euch wird sich vielleicht gedacht haben: Aber ist nicht genau dafür Certificate Pinning gedacht, um sowas zu verhindern? Google hat doch sogar Werbung damit gemacht, dass sie böse Zertifikate erkennen, wenn Chrome zu Youtube oder einem anderen Google-Dienst verbinden will und ein Nicht-Google-Zertifikat sieht.
Was ist da also los?
Nun, nichts genaues weiß man nicht, aber eine Sache kann ich bei der Gelegenheit mal kurz erläutern: Cert Pinning schaltet sich ab, wenn man ein Root-Cert im Local Store hat, und dann das auf Pinning zu prüfende Zertifikat von dieser Root-CA signiert reinkommt.
Warum ist das so? Wegen Compliance-Bullshit. Ich wettere hier ja seit Jahrzehnten gegen Compliance-Bullshit, und dies ist ein schönes Beispiel dafür, wie Compliance-Bullshit Dinge für alle Menschen schlechter macht.
Für Banken und Versicherungen und Aktienbroker gibt es regulatorische Vorschriften, dass die ihren Traffic mitprotokollieren müssen, damit man danach Insider Trading nachweisen kann.
Kann man natürlich nicht. Also könnte man schon, macht man aber nicht. Wie auch alles andere Security-Theater hören die Aktivitäten bei "wir sammeln alle Daten ein" auf. Niemand guckt je in diese Daten rein.
Aber der Effekt ist, dass Banken ihren Mitarbeitern dann halt ein Root-Cert auf dem Gerät installieren. Und wenn Chrome dann immer meckern würde, dann müsste Google sich mit wütenden Kunden auseinandersetzen. Also schaltet man lieber Cert-Pinning ab.
Chrome macht das so. Firefox macht das auch so. Daher: Wenn euch jemand im lokalen Cert Store irgendwelche Root-Certs installiert, dann solltet ihr das immer ablehnen. Hier ist die Mozilla-Dokumentation zu dem Verhalten. Ctrl-F insert
Die Hoffnung war, dass ihr euch mal mit der Frage beschäftigt, wie man eine Fake-Fehlermeldung von einer echten unterscheidet. So richtig smart ist das nämlich nicht, wenn Systemmeldungen nachgebaut werden können.
Der einfachste Weg (bei Firefox und Chrome) ist Ctrl-U. Das zeigt normalerweise den HTML-"Quellcode" einer Seite an. Bei einer echten Zertifikatsfehlermeldung zeigt er die Fehlermeldung an, nicht den Quellcode. Außerdem ist bei einer echten Fehlermeldung im URL-Bar das Schloss anders.
Das lohnt sich bei Text (könnt ihr im Browser in den Developer Tools sehen, da steht aktuell sowas wie 6,56KB übertragen, Größe war 12,46KB). Bilder und Videos sind schon komprimiert, da ist das Zeitverschwendung.
Wenn ihr also mein Blog aus der Bahn oder im Handy ladet, dann halbiert Kompression eure Wartezeit. Umso bedauerlicher, dass sich da in den Browsern seit Jahren nicht mehr viel getan hat.
Vor einer Weile hat Chrome Brotli-Support in Chrome eingebaut. Brotli komprimiert geringfügig besser als gzip, aber nicht überzeugend viel besser und es ist auch deutlich langsamer dabei.
Kompression hilft übrigens auch gut bei Font-Dateien, die man per Web einbindet.
Ich erzähle das, weil es ein relativ neues Kompressionsverfahren gibt, zstandard. Ich habe das hier im Blog 2016 zum ersten Mal erwähnt. zstd deckt das ganze Spektrum ab (von "schnell aber nicht so effektiv" bis "langsam und hocheffektiv"). Es hat aber zwei wichtige Vorteile gegenüber Brotli:
"Schnell und dafür nicht so effektiv" ist so schnell, dass man es viel leichter verargumentiert kriegt, das in Protokolle einzubauen. Mein Blog hat im Moment keine Brotli-Kompression, aber wenn die Browser zstd könnten, würde ich sofort zstd-Kompression einbauen. Da kriege ich für den gleichen Aufwand, den ich im Moment bei gzip schon abgenickt habe, deutlich bessere Kompression, bzw. kriege die Kompression, die ich im Moment von gzip kriege, für deutlich weniger CPU-Last im Blog. Das ist also quasi ein No-Brainer, dass man das im Browser will.
Nun, ... hier ist der Firefox-Bug. Der ist von "8 years ago". Immer noch offen. Denn bei Firefox gibt es keine Innovation mehr. Die bauen Dinge erst ein, wenn Chrome sie einbaut. Wenn Chrome etwas ausbaut, baut Firefox es auch aus, wie zuletzt bei jpeg-xl passiert, völlig hanebüchen.
Jetzt wo Chrome zstd hat, wird das hoffentlich auch bald Firefox kriegen, und dann haben wir alle gewonnen.
Update: Heutzutage macht man Webfonts als woff oder woff2 und das ist dann im Wesentlichen ein ttf mit brotli. Es ist immer schlauer, Dateien vorzukomprimiert abzulegen, als sie beim Rausgehen im Webserver zu komprimieren.
"This is a one-time notification giving people the choice to set Bing as their default search engine on Chrome," Microsoft told BleepingComputer."We value providing our customers with choice, so there is an option to dismiss the notification."
Wieso kauft eigentlich jemand von denen?
Welches Problem?
"Nach verheerendem Angriff auf Südwestfalen-IT: 205 Kommunen lassen IT prüfen"
Hunderte Kommunen in NRW lassen ihre IT-Sicherheit überprüfen, die Landesregierung bezahlt das. Sie will das Land künftig besser vorbereitet wissen.Hier also meine Hilfe. Kostenlos sogar.
Erstens: Spart euch das. Die Prüfung ist bereits abgeschlossen. Die Ransomwarer haben euch geprüft und ihr seid durchgefallen. Das Geld gibt man am besten VOR dem erfolgreichen Angriff aus.
Zweitens: Schmeißt die vier apokalyptischen Reiter raus: Windows, Office, Exchange und Active Directory. Lasst euch eure IT als Webanwendung machen und installiert den Leuten dumme Terminals. Irgendwas Linux-basiertes mit Komplett-Lockdown, das keine Daten lokal speichern kann, und als read-only Image verteilt und automatisch geupdated wird.
ChromeOS hat gezeigt, dass das grundsätzlich geht. Sollte vielleicht mal jemand als Produkt anbieten. Sowas wie Chromeos Flex aber ohne Google.
Oder ... gut, ich meine, ihr könnt natürlich einfach weiterpfuschen. Wir sehen uns dann beim nächsten Ransomwarevorfall. *winke*
Die Details sind noch ein bisschen unklar, aber der Exploit wurde schon aktiv zum Installieren von Staatstrojanern ausgenutzt, insofern ist das eher dringend jetzt. Ihr solltet also mal schnell manuell euren Browser updaten.
[$NA][1479274] Critical CVE-2023-4863: Heap buffer overflow in WebP. Reported by Apple Security Engineering and Architecture (SEAR) and The Citizen Lab at The University of Torontoʼs Munk School on 2023-09-06Wenn The Citizen Lab einen Bug meldet, dann weil sie einen Staatstrojaner reverse engineered haben, und den Exploit in der freien Wildbahn gefunden haben.Aber eigentlich wollte ich an der Stelle folgende Bemerkung loswerden:
Immer diese versifften unsicheren Schrottimplementationen von inkompetenten Anfängern wie ... *akteumblätter* Google!1!!
Sagt mal, seid ihr auch Kunden von der Google-Cloud ? Weil ihr annahmt, dass der Code, den die produzieren, weniger schlecht ist als der von Microsoft oder Amazon? Tja, das war dann wohl nicht so schlau.
Update: Falls das jemand nicht wusste: WebP ist auch in allen anderen Browsern drin. Und in diverser sonstiger Software, die Bilder entgegennimmt oder verarbeitet.
Update: Saved on Google ist anscheinend sowas wie ein Link-Sharing-Dienst, und dieser Typ hat seine Bookmarks da (unabsichtlich?) rein verbunden.
New hotness: Chrome kriegt einen "KI"-basierten Zusammenfasser.
Das sollten sie auch mal für Youtube-Videos anbieten!
Wer also jetzt noch Chrome oder Chromium oder einen auf Chromium basierenden Browser benutzt, sollte schnell mit den Füßen wählen und zu Firefox gehen. Ansonsten haben wir bald eine Welt, wo dein Browser keine Webseiten mehr anzeigen kann, weil du einen Adblocker installiert hast.
Erstens: Apple hat ohne große Ankündigung ein DirectX12-Emulationslayer ausgeliefert, wenn ich das richtig verstehe. Damit könnte man dann zumindest theoretisch Windows-Spiele einfach so auf Apple-Hardware spielen. Damit stehen sie natürlich auf den Schultern von Open-Source-Giganten, die auch schon DXVK und co im Angebot haben. Valve hat Millionen in DirectX-Emulation in Wine gesteckt. Da wird sich Apple einfach mal bedient haben.
Erwähnenswert ist das aus zwei Gründen. Erstens haben sie wohl einen großen Patch an Wine zurückgeschickt. Die GPL funktioniert also!
Zweitens sind ja in den M1 und M2-ARM-Geräten angeblich sehr gute GPUs drin, die es mit gehobenen Mittelklasse-GPUs auf PCs aufnehmen können. Konnte man nur nie sinnvoll nutzen, weil es keine erwähnenswerten Spiele für Apple gab. Es könnte also sein, dass die wirtschaftlich eh schon darbenden GPU-Hersteller jetzt auch noch von Apple Stress kriegen.
Die andere Ankündigung war, dass Apple überraschend in Safari plötzlich JPEG XL unterstützt. Ich bin ein Fan von JPEG XL und war sehr ungehalten, als Chrome und Firefox das abgekündigt haben, obwohl das größte Argument gegen die Unterstützung schon vom Tisch war: Dass das viel Arbeit ist. Die war schon getan.
Jetzt habe ich Hoffnung, dass Chrome und Firefox ihre hirnrissige Abkündigung zurücknehmen und wir doch noch alle JPEG XL bekommen.
Erstens: Nitrokey verbreitet, dass der Qualcomm-Chipsatz deine privaten Daten in die Cloud hochlädt.
Das ist Blödsinn. Der Cloud-Kontakt von dem Qualcomm-Chipsatz ist das Runterladen des GPS-Almanachs. GPS funktioniert so, dass Satelliten Signale schicken, und du kannst dann deine Position ausrechnen, wenn du die Signale siehst, und weißt, wo die Satelliten gerade waren. Im Signal ist ein Timestamp, mit dem du sehen kannst, wie lange das Signal unterwegs war. Jetzt musst du nur noch wissen, wo die Satelliten sind, und da deren Laufbahnen ständig nachkorrigiert werden, sind das keine statischen Daten. Die Positionen stehen in einem sogenannten Almanach, und den lädt Qualcomm halt alle zwei Wochen oder so aus der Cloud nach.
Dass das über HTTP geht, kann man kritisieren. Aber was Nitrokey hier verbreitet überschreitet die Grenze der grotesken Inkompetenz und sieht für mich nach mutwilliger Irreführung aus.
Zweitens: Heise verbreitet, dass Google Authenticator deine Zwei-Faktor-Seeds in die Cloud backupt und dabei nicht Ende-zu-Ende-Krypto einsetzt.
Analysieren wir doch mal die Situation. Wir haben hier ein Cloud-Backup "im Klartext", d.h. der Typ in der Cloud kann die Daten einsehen. Der Weg zur Cloud ist TLS-verschlüsselt, und Google spricht jetzt davon, dass die Daten auch verschlüsselt bei ihnen abgelegt sind. Das ist natürlich ekelhafte Irreführung, denn damit meinen sie Platten-Krypto. Das schützt gegen "jemand bricht bei Google ein und klaut die Platten". Es schützt nicht gegen "jemand bricht bei Google ein und kopiert die Daten". Das ist das Szenario, vor dem man hier Sorgen haben sollte, und da hat Heise einen Punkt, dass das ein Problem ist.
Auf der anderen Seite läuft auf deinem Telefon Google-Software. Das Google-Android schützt deine Seeds auf dem Telefon vor dem Zugriff anderer Apps und verhindert Netzwerk-Kommunikation der Google Authenticator App. Wenn dein Bedrohungsmodell also ist, dass jemand bei Google einbricht und dort böse Dinge tun kann, dann hast du eh schon komplett verloren, weil derjenige dir auch ein böses Android-Update schicken kann, das deine Seeds auf Facebook postet oder bei Github hochlädt oder so.
Was hätte man besser machen können? Man könnte das Backup mit einem Schlüssel verschlüsseln, den Google nicht kennt. Allerdings muss diesen Schlüssel halt dein Telefon kennen, sonst kann es ja nicht die Daten damit verschlüsseln, und die Software auf deinem Telefon kommt von Google. Die Forderung hier ist also gerade, dass Google deine Daten vor Google schützt. Das klingt nicht nur bekloppt, das ist bekloppt.
Zusammenfassend: Ich würde nie meine Daten zu Google (oder sonstwo) in die Cloud backuppen oder auch nur mein Windows an einen Microsoft-Account binden. Aber selbst mit dieser paranoiden Grundeinstellung bin ich machtlos, mich auf einem Android-Telefon gegen böse Updates zu wehren.
Insofern: Ist das ein Problem? Ja. Aber ein weitgehend akademisches. Mit "E2E" (passt in diesem Szenario eigentlich nicht, weil beide Enden du selbst bist) würde man sich gegen ein Szenario schützen, wo ein Einbrecher es innerhalb von Google bis zu dem Backup-Storage schafft, aber nicht die Updates kompromittiert kriegt. Ist das sonderlich realistisch? Müsst ihr selbst beurteilen. Aus meiner Sicht sieht das nach "Sommerloch bei Heise" aus. Wenn du mit Firmen wie Microsoft oder Google überhaupt kooperierst, hast du schon direkt ziemlich komplett verloren. So zu tun als gäbe es da Graustufen und man hätte aber eigentlich doch noch Reste von Kontrolle ist aus meiner Sicht Augenwischerei.
Ist 2FA damit vollständig Bullshit? Ich bin grundsätzlich kein Freund von 2FA, weil das im Wesentlichen nur einen Zweck erfüllt: Eine Beweislast- und Schuldumkehr von Google zu mir. Vorher: Mein Google-Account wird gehackt? Google war Schuld. Nachher: Mein Google-Account wird gehackt? Ich bin Schuld.
Wieso würde ich da mitspielen wollen? Sehe ich nicht ein.
Aber WENN man schon 2FA macht, dann zwischen konkurrierenden Firmen. Wenn Microsoft 2FA erzwingt, dann generiere das Token unter Android. Wenn Google 2FA erzwingt, generiere das Token unter Windows oder Linux oder sonstwo, wo Google nicht rankommt. D.h. dann auch: Wo kein Chrome läuft!
Der ganze postulierte Sicherheitsgewinn von 2FA kommt daher, dass Username+Passwort und Token nicht an derselben Stelle abgreifbar sind. Das muss man dann auch sicherstellen. Wenn du also Google Authenticator verwendest, dann darfst du dich von dem Android aus nie in den Account einloggen, sonst kann Google auch Username+Passwort sehen (über die Keyboard-App u.a.).
Update: Hat der Fefe gerade argumentiert, dass man Cloud-Backup nicht verschlüsseln muss? Nein! Das ist grundsätzlich eine gute Idee. Da gibt es gute Gründe für, Backups immer zu verschlüsseln, auch wenn das Backup lokal ist. Nehmen wir an, eine der Platten geht kaputt und du willst die entsorgen. Wenn die Backups verschlüsselt waren, kannst du die einfach wegschmeißen (der Schlüssel darf dann natürlich nicht daneben liegen). Wenn die Backup-Infrastruktur komplett nur verschlüsselte Daten sieht, kannst du da unvertrauenswürdige Infrastruktur einsetzen (z.B. ein SMB-Share, NFS, Cloud-Storage, whatever). Da kann dann nichts absichtlich oder versehentlich leaken. Wenn die Software Temp-Files rumliegen lässt oder Daten im RAM cached, dann musst du dir keine Sorgen machen.
Aber die Gelegenheit war günstig, mal zu zeigen, wie man so eine Risikoanalyse in der Praxis machen sollte. Mein Argument war nicht, dass Backup-Crypto nicht notwendig ist, sondern dass Google auch mit Backup-Crypto an deine Daten rankommt und daher die Auswirkungen nicht so groß sind wie man erstmal instinktiv annehmen könnte.
Es gibt noch ein Argument für E2E-Krypto in diesem Fall. Wenn jemand bei Google deine Daten abgreifen will, kann der im Moment entweder dir ein böses Update schicken oder deine Backups abgreifen. Die Risiken sind additiv. Wenn du die Backups ordentlich verschlüsselt hast, bleibt zwar der andere Teil des Risikos bestehen, aber dieser Teil fällt weg. Hilft halt nichts gegen "der CEO / das FBI verlangt Zugriff auf deine Daten", und das ist der Fall, der mir persönlich mehr Sorgen machen würde.
Update: Ja aber Fefe, muss ich mir für meinen Google-Account ein Iphone kaufen, damit das 2FA auf einem anderen Gerät als dem Android läuft? Nein. Für sowas kann man auch FIDO2-Tokens nehmen, von Yubikey oder so.
Your iPhone's analytics data includes an ID number tied to your name, email, and phone number, say researchers who uncovered other holes in Apple' promises.Sehr lustig finde ich auch folgenden Teil:“I think people should be upset about this,” Mysk said. “This isn’t Google. people opt for iPhone because they think these kinds of things aren’t going to happen. Apple doesn’t have the right to keep an eye on you.”*schenkelklopf*Ja aber aber aber schützt Apple uns nicht vor Facebook? Kann sein, aber nur um den Wert von ihrem Big Data Pool in der Cloud zu erhöhen!
OK aber was für Daten sammelt Apple denn da?
In some cases, this analytics data apparently includes details about your every move. Mysk’s tests show that analytics for the App Store, for example, includes every single thing you did in real time, including what you tapped on, which apps you search for, what ads you saw, and how long you looked at a given app and how you found it.Ach. Ach was. Aber, äh, ... das ist ja wie bei Google!!1!Update: Dieser Artikel ist sogar noch ein bisschen schöner:
This isn’t an every-app-is-tracking-me-so-what’s-one-more situation. These findings are out of line with standard industry practices, Mysk says. He and his research partner ran similar tests in the past looking at analytics in Google Chrome and Microsoft Edge. In both of those apps, Mysk says the data isn’t sent when analytics settings are turned off.
(Im Gegensatz zu Apple, die auch Telemetrie senden, wenn man das explizit ausgeschaltet hat)
Along the way, Apple developed a very convenient definition of what privacy means that lets the company criticize its rivals’ privacy practices while harvesting your data for similar purposes. Apple says you shouldn’t think of what it does as “tracking.” According to the company’s website:Apple’s advertising platform does not track you, meaning that it does not link user or device data collected from our apps with user or device data collected from third parties for targeted advertising
Seht ihr? Apple shared die Daten nicht mit dem Data Broker, Apple ist der Data Broker! Damit ist das nach ihrer Definition kein Tracking. Wobei, hey, wenn Apple die Daten nicht weiterverkauft, dann sind sie ja technisch gesehen nicht mal ein Broker sondern nur ein Datenkrake. Man kann ja von sowas auch profitieren, ohne dass man es weiterverkauft.
Wegen, äh, *papierraschel* zu wenig Nachfrage.
Die User so: Das war hinter einem Experimental-Switch, von dessen Existenz der Normaluser nichts wusste.
Ja aber Fefe, wieso interessierst du dich denn für Chromium? Du benutzt doch Firefox! Nun ja, immer wenn Chrome etwas verkackt, verkackt Firefox es noch krasser. Bei Firefox gibt es auch JPEG XL, aber es ist auch hinter einen Experimental-Switch, von dem die meisten Leute nichts wissen, und jetzt der Teil, den Firefox noch krasser verkackt als Chrome: Den anzumachen hilft nicht. Man muss auch die Nightly-Version von Firefox einsetzen. Die Normal-Version hat den Switch aber er bewirkt nichts.
Ach naja, wer braucht denn JPEG XL, es gibt doch noch AVIF und HEIC!
Ja schon, aber HEIC kann kein Browser und AVIF wird zwar weitgehender unterstützt aber es wo man ein 1080p JPEG nach JPEG XL in einer Sekunde umwandeln kann, braucht AVIF eher so eine Minute (natürlich je nach Hardware, die man drauf wirft).
In diesem Sinne war JPEG XL tatsächlich der Hoffnungsträger. Der klare Gewinner unter den Formaten. HEIC hat auch noch ein Patentproblem übrigens.
HEIC kommt von der Patentmafia, JPEG XL kommt von den Leuten hinter JPEG, und AVIF kommt von Google.
Wir haben hier also mal wieder einen klaren Fall von Monopolmissbrauch. Wisst ihr, was wir mal bräuchten? Eine Behörde, die sowas verhindert! Ihr wisst schon, sowas wie die Inder haben.
Ja OK und wie ist das mit den anderen Wahllokalen? Nun, das war nicht für ein Wahllokal, sondern für die ganze Gegend.
Ja, äh, wie, wieviele wohnen denn da? Für unter 40000 Menschen baut da ja wohl keiner ein Atomkraftwerk hin?
Laut Text wohnen da 1,7 Millionen Menschen. Man muss da ein bisschen vorsichtig sein, denn das ist sowohl der Name einer Stadt als auch einer Gegend. Die Stadt hatte 2017 700.000 Einwohner. 1,7 Millionen für die Gegend kann also gut hinkommen.
Wir reden hier also von einer Wahlbeteiligung im unteren einstelligen Prozentbereich.
Auf der einen Seite ist die Aussagekraft eines Referendums bei 3% Beteiligung natürlich Null. Auf der anderen Seite stellt sich die Frage, wieso die das so veröffentlichen würden, wenn das die ganze Geschichte so schlecht aussehen lässt. Und wieso unsere Medien behauptet haben, Russland habe behauptet, die Wahlbeteiligung sei bei 97% gelegen. Dieses amtliche Endergebnis auf dem Bild kommt ja von Russland. Haben die gleichzeitig hohe und niedrige Wahlbeteiligung behauptet?
In Deutschland gibt es ja das Instrument des Volksbegehrens, das hat auch eine Mindestmenge an Stimmen, die nötig sind, und dann ist das noch nicht mal bindend sondern das Parlament kann das immer noch einfach verwerfen. Bei Bundestagswahlen haben wir allerdings auch keine Mindestwahlbeteiligung, wir tun in den Grafiken sogar absichtlich so, als gäbe es gar keine Nichtwähler, und zeigen nur die gültigen Stimmen. Da sind wir also diesen Referenden unkomfortabel nahe und sollten vielleicht auch mal eine Mindestquote einführen, sonst ist die Wahl ungültig.
Der Typ, der das getweetet hat, hat eine Wikipediaseite, allerdings in der Вікіпедія. Kann man aber maschinell übersetzen. Der kommt aus der Gegend und ist Journalist, musste aber vor dem Krieg fliehen.
Update: Ah ich habe ein Beispiel für die russischen Behauptungen zur Wahlbeteiligung gefunden. Da geht es um Kherson und sie behaupten 87% Zustimmung bei 497,051 abgegebenen Stimmen.
Kann hier jemand den Text auf dem Bildschirmfoto übersetzen? Ist das wirklich für die ganze Region oder doch bloß ein Wahllokal?
Update: Oh wow! Stellt sich raus: Wenn man den Tweet mit dem Foto in Chrome öffnet, und dann auf das Foto rechtsklickt, dann kann man Google Lens klicken und dann holt der nicht nur den Text aus dem Foto raus, sondern bietet auch eine Maschinenübersetzung an. Das ist ja mal Scifi, ey! In der Tat steht in der Übersetzung: Referendum für die Saporischschja-Region. Heilige Scheiße!
Update: Ah, in den Klammern steht der Hinweis, dass es sich um Wahllokale auf dem Gebiet der russischen Föderation handelt. Also der jetzigen russischen Föderation. Flüchtlingslager vielleicht?
Bei der Bahn kann ich schon seit Jahren nicht mit meiner Firmenkreditkarte zahlen, weil die da irgendeinen Compliance-Validierungs-Scheiß eingeführt haben, der bei meiner Karte immer failed. Die Karte ist zwar in meinem Namen aber halt nicht mit meinem Privatkonto verbunden, für das ich Onlinebanking hätte.
Gut, zahl ich halt mit Lastschrift. Ist mir eh das liebste Zahlungsverfahren unter den Kandidaten, weil ich betrügerische Abbuchungen zurückholen kann. Das lief seit Jahren gut. Heute nicht mehr. Ich kann zwar SEPA-Lastschrift auswählen, und das sieht auch erstmal so aus, als liefe es, aber dann kommt wieder die Auswahl, diesmal ohne Lastschrift. Da habe ich dann die Wahl zwischen Kreditkarte (funktioniert nicht), Giropay oder Paypal. Paypal macht am Ende Lastschrift, was ich die ganze Zeit haben wollte.
Dieses ganze Herumversagen der Bankenindustrie treibt mich am Ende zu Paypal, weil das die einzigen sind, die mich ohne Bullshit-Theater Dinge bezahlen lassen. Was zur Hölle ist denn bitte mit diesen ganzen Leuten los? WOLLEN die sich aus meinem Geschäftsleben rausekeln?
Giropay hab ich in Erwägung gezogen, aber der Prozess involviert, dass man einen Freischaltlink in seinem Homebanking erzeugt. Was der genau freischaltet ist für mich nicht nachprüfbar. Also mache ich das nicht.
Außerdem finde ich es nicht gut, dass Giropay (oder Paypal!) sehen kann, dass ich bei der Bahn was bezahle. Schlimm genug, wenn die Bahn und meine Bank das sehen können! Wenn ich das System designen sollte, wäre das eines der obersten Designziele gewesen, die anfallenden Daten zu minimieren.
Für die Sache mit dem Aktivierungslink kann Giropay m.W. nichts, das hat ihnen irgendeine Compliance-Bullshitlavine einer Behörde reingedrückt, oder waren es die Banken? Spielt für mich aber auch keine Rolle, wieso das so ist. Es ist so, und ich mag es nicht.
Update: Warum mag ich es nicht? Weil es ein Dark Pattern für Einleitung der Beweislastumkehr ist. "Aber Sie haben doch zugestimmt!" Nee. DEM HIER habe ich NICHT zugestimmt. Daher stimme ich dann lieber niemals irgendwas zu.
Update: Ein Leser meint, er hatte dasselbe Problem, und in Chrome ging es dann, nur Firefox ging nicht. Ein Kumpel von mir hat Firefox und bei dem geht es auch. Ich vermute irgendeinen a/b-Test-Bullshit.
Ein anderer Leser meint, es gäbe da noch einen Unterschied zwischen Giropay und Giropay Paydirekt, und das mit dem Link sei nur bei Giropay Paydirekt. Bei Giropay ohne Paydirekt, sagt er, brauchst du keinen Account irgendwo anlegen sondern du generierst im Onlinebanking eine TAN und die gibst du dann der Bahn-Webseite. Das finde ich ja eher noch gruseliger, muss ich sagen. Das klingt für mich wie eine Sepa-Lastschrift aber mit Beweislastumkehr und ohne Rückbuchbarkeit.
Update: OK, das mit der TAN stimmt offenbar auch nicht. Das ist doch eher wie Sofortüberweisung. Du klickst bei der Bahn, die schickt den Browser zu deiner Bank, da ist ein vorausgefülltes Überweisungsformular, und wenn du das abschickst, dann benachrichtigt die Bank die Bahn, dass du gezahlt hast. Also: Vorkasse und nicht zurückrufbar. Kombiniert geschickt alle Nachteile.
Update: Ein Leser spekuliert, dass die Lastschrift absichtlich für Sparpreis-Tickets abgeschaltet wurde. Das kann sein, ich hab in der Tat Sparpreis-Tickets gebucht.
Jetzt machen sich Leute Sorgen, dass versiffte Web-Frameworks mit der dreistelligen Versionsnummer nicht klarkommen.
Mein Vorschlag: Alles niederbrennen.
Lass mich raten… weil OpenSSL so einen schlechten Ruf hat?
Tavis Ormandy hat mal geguckt, wie die ihre Signaturen ablegen. Sie haben da eine Union, in der das größte Element 16 kbit groß ist, für RSA.
Okay, but what happens if you just….make a signature that’s bigger than that?Well, it turns out the answer is memory corruption. Yes, really.
Oh. Mein. Gott.Das ist schlimmer als Heartbleed. Das ist sozusagen der Hallo Welt unter den Remote Code Execution.
Sagt mal seid ihr auch so froh, dass Mozilla ihr Geld für so Dinge wie Colorways ausgegeben hat?
Oder dafür, dass ihr endlich Werbung im New Tab kriegt?
Oder für das ungefragte Einsammeln von Telemetrie?
At Mozilla, we want to make products that keep the Internet open and secure for all. We collect terabytes of data a day from millions of users to guide our decision-making processes. We could use your help.Nein, Mozilla. Wenn ihr meine Hilfe wollt, dann löscht ihr erstmal alle Daten über eure User.Aber zurück zu diesem Bug. Tavis Ormandy ist besonders geflasht, dass Mozilla da endlos static analyzer und fuzzing gemacht hat, und die Tools haben alle grüne Lampen angezeigt. Und nicht nur doofe Fuzzer sondern aktuelle state-of-the-art Fuzzer mit Coverage-Analyse!
Mich überrascht das ja nicht so doll. Ich werde praktisch nach jedem Code Audit gefragt, wieso ihre Static Analyzer das alles nicht gefunden haben. Ihr solltet vielleicht mal weniger Geld für Tools ausgeben und mehr Geld in eure Entwickler stecken, dass die lernen, wie so ein Bug aussieht und worauf man achten sollte.
Zensursoftware? Wie meinen?
Flagship phones sold in Europe by China's smartphone giant Xiaomi Corp (1810.HK) have a built-in ability to detect and censor terms such as "Free Tibet", "Long live Taiwan independence" or "democracy movement", Lithuania's state-run cybersecurity body said on Tuesday.Ja aber komm, das ist doch nicht angeschaltet in Europa, oder?!The capability in Xiaomi's Mi 10T 5G phone software had been turned off for the "European Union region", but can be turned on remotely at any time, the Defence Ministry's National Cyber Security Centre said in the report.Aber Fefe, haben die nicht völlig Recht? Ist das nicht ein Problem? Wieso schreibst du denn da Lacher des Tages dran?
Weil Apple und Google und Firefox und Chrome und Windows selbstredent dieselbe Befähigung haben. Nur shippen die das Zensurmodul nicht die ganze Zeit mit, wo es möglicherweise auffallen würde, sondern sie nennen es Updateschnittstelle. Sie nötigen uns außerdem alle, ständig auf Zuruf Updates einzuspielen. Und sie haben so verkackte beschissene Software, dass das in der Tat gar nicht sicher betreibbar ist, wenn man nicht alle Updates immer sofort einspielt.
Wo ist da also noch gleich der fundamentale Unterschied? Oh, gibt gar keinen? Na sowas!
Wir haben alle schon lange die Souveränität über unsere Geräte und Daten abgegeben. Damit haben wir uns ein bisschen Convenience gekauft, die wir jetzt gar nicht nutzen können, weil die immer neuen Security-Theater-Maßnahmen jede Convenience schon längst aufgefressen haben.
Wie? Was sagt ihr? Oh warte, ich kann gerade nicht. Ich muss kurz Pause machen. Windows will meinen Rechner nach Malware scannen. Mit einem frisch remote eingespielten Malware-Scanner.
Lasst euch mal bitte noch von dieser plumpen Nato-Propaganda verarschen.
Ich hab das mal experimentell als AVIF statt JPEG hochgeladen, das jetzt angeblich alle Browser können. Bin mal gespannt, ob das Format realitätsfest ist.
Update: Hups, da hat mich meine Toolchain verarscht. Die kann gar kein AVIF und hat da ein JPEG abgelegt. m(
Update: OK jetzt liegt da tatsächlich ein AVIF und es kommt auch mit MIME-Type image/avif raus. Bei mir zeigen Firefox und Chrome das unter Linux richtig an. Leser berichten, dass der Android-Firefox das noch nicht kann, aber Android-Chrome kann es. Unter Windows können es wohl auch alle namhaften Browser. Safari kann anscheinend gar kein AVIF, egal wie aktuell man ist.
Update: Stellt sich raus: Firefox 92 hat das wegen eines Bugs wieder rausgenommen. Bei mir ging Firefox, weil ich unter Windows den beta Channel angeschaltet habe, das ist dann 93, und unter Linux den Nightly selber baue.
Wow. Gibt es da niemanden, der den Hebel zieht?!
5,6 Milliarden, das ist fast so viel wie dieser Hedgefunds durch die Reddit-Foristen verloren hat! Wat!?!? Das blutet Google mal eben über ein Jahr raus?
Na kein Wunder, dass Google alle Nase lang vielgenutzte und geliebte Dienste zumacht. Ich habe hier gerade die Warnung gekriegt, dass mein Chromebook keine Updates mehr kriegen wird. Damit ist Google der einzige (!) Marktteilnehmer, der es schafft, einen Webbrowser alszuliefern, der keine Security-Patches mehr kriegt. Microsoft macht es besser, Apple macht es besser, Chromium macht es besser, fucking Mozilla macht es besser! Nur Google hält das für ein akzeptables Geschäftsgebahren, Kunden einfach ins Gesicht zu sagen, sie können die Geräte ja gerne weiter nutzen, wenn ihnen ihre Daten darauf nicht so viel wert sind.
Ja toll, Google, dann wandelt mal euer Geld weiter in Wolken um. Per Verbrennung.
Das geht ja mal GAR nicht!
Google nagelt dann mal die APIs zu.
Wenn ihr also Google-Features nutzt und demnächst mit eurem Browser Probleme habt, könnte das daran liegen. Der Abschalttag ist der 15. März. (Danke, Lutz)
Konzeptionell bin ich ja ein Freund von Rust. Was die sich da an Neuerungen überlegt haben, das hat die Industrie insgesamt vor sich hergetrieben.
Von welchem Nachteil rede ich denn dann? Nun, ich baue hier regelmäßig mein Firefox selbst.
Mozilla stellt der Reihe nach Teile von Firefox auf Rust um.
Das ist ja auch gut so.
Aber zwei Effekte zeigen sich dabei schnell. Der erste ist, dass Rust nicht parallel baut. Neben den ganzen C++-Teilen, die vom Build-Prozess schön auf die Cores verteilt werden, läuft da dann halt ein cargo build für sowas wie 15 Minuten auf einem Core und baut den Rust-Kram. Noch gibt es genug C++-Zeug, dass das noch wenig zu Lasten der CPU-Auslastung geht, aber wenn man inkrementell baut und sich in der Zeit drei C++ und zwei Rust Quellcodedateien geändert haben, dann merkt man das deutlich, denn bei Rust ist die Unterscheidung zwischen Compiler und Linker anders verschoben. Der scheint immer eine Art LTO-Pass zu machen. Jedenfalls kommt es vor, dass der C++-Teil fertig ist und dann das make mit einer 100%-Auslastung auf einem Kern ewig lang an Rust herumrödelt.
Das ist das erste Problem. Das zweite Problem ist noch schwerwiegender. Rust verbraucht echt viel RAM. Ich habe hier eine Kiste mit 16 GB RAM. Die reicht bei praktisch allen Projekten, um die aus der Ramdisk (tmpfs) zu bauen. Nicht so bei Firefox. Da musste ich schon vor einer Weile die Quellen auf der Platte haben, weil sonst der Build mit out of memory abbrach. Jetzt ist es so, dass der Build auch beim von-Platte-bauen gerne mit out of memory abbricht. Stellt sich raus: Der LTO-Teil in dem Rust-Teil von Firefox schluckt mal eben sowas wie 13 GB am Stück. Wenn du da noch ein paar C++-Dateien parallel zu bauen versuchst, dann ist Ende Gelände.
Ich beobachte das mit großer Sorge, wie sorglos Entwickler mit dem Speicherbedarf ihrer Software umgehen. Ich habe noch zwei andere Projekte, bei denen der Speicher knapp wird. Qt muss ich auch von Platte bauen, nicht von Ramdisk. Und LLVM hat neuerdings einen Fortran-Compiler drin. Ich weiß nicht, was die da gemacht haben, aber das Bauen davon muss ich auf zwei Kerne zur Zeit beschränken, sonst frisst das zu viel RAM. Ich vermute eine Template-Instanziierungs-Hölle oder sowas. Der Fortran-Compiler setzt bei LLVM auf ein neueres Fundament als der C++-Compiler, ein generalisiertes Compilerframework namens mlir (ist auch Teil von LLVM).
Chrome und Libreoffice benutze ich nicht und habe ich daher auch nicht zu bauen versucht. Ich vermute mal, das wird mit 16 GB auch knapp.
Update: Dass Rust nicht parallel baut ist eigentlich auch nicht korrekt. Ich kann daher gerade das bei Firefox beobachtete Verhalten nicht erklären. Das liegt allerdings auch schon ein bisschen zurück, denn Firefox hat vor einer Weile angefangen, einfach gefühlt immer darauf zu bestehen, dass man einen komplett neuen Build startet und nicht inkrementell baut. Jedenfalls definitiv immer zwischen Versionen. Insofern kommt der Fall bei mir kaum noch vor, dass ich auf einen Rust warten muss bei Firefox.
Ja aber aber aber Chrome hat doch eine Sandbox? Ja schon, aber der 2. Teil des Exploits ist ein Sandbox-Ausbruch für Windows. Beide Hälften sind 0days.
Dass wir überhaupt davon erfahren haben wir (mal wieder) Google Project Zero zu verdanken.
Das mit dem Sandbox-Ausbruch gegen Chrome ist übrigens ein großes Problem, denn der Chrome-Sandbox-Code gilt als der Goldstandard unter Windows. Den haben diverse andere Projekte kopiert. Deren Sandbox ist im Moment dann auch außer Betrieb.
Update: Ooooh, stellt sich raus: Edge ist nicht Teil des Patchday-Hirnrisses.
New hotness: Apple-Apps sind von die Privatsphäre schützenden Firewall-Regeln ausgenommen.
Ich stelle mir bei sowas immer vor, wie groß der Aufschrei gewesen wäre wenn Microsoft das vor zehn Jahren oder so gebracht hätte.
Aber das reicht ihnen nicht. Das sind auch die mit dem öffentlichen DNS-Server, der sieht, auf welche anderen Seiten ihr so geht.
Aber das reicht ihnen nicht. Das sind auch die mit dem Pilotprojekt für "verschlüsseltes DNS" mit Mozilla, damit sonst keiner sieht, was sie sehen können.
Und jetzt stellt sich raus: Auch das reicht ihnen noch nicht. Jetzt wollen sie auch noch, dass ihr ihren Cloud-Webbrowser benutzt. Damit sie auch noch sehen können, wo ihr die Maus hinbewegt aber nicht draufklickt, und wie lange ihr auf welcher Seite bleibt.
Gut, man könnte sagen, so häufig wie die ihre eigene Infrastruktur abschießen, da muss man keine großen Sorgen haben, dass nicht auch ihre Datenbanken mit den Datenkrankendaten periodisch gelöscht werden. Aber darauf würde ich mich ja eher nicht verlassen wollen. Browser in der Cloud ist jedenfalls die denkbar dämlichste Idee, die ich in den letzten Jahren gehört habe. Ja, NOCH dämlicher als "wir leiten alle Mozilla-DNS-Anfragen über Cloudflare".
Es ist natürlich auch ein massives Sicherheitsproblem, weil dann alle eure Logindaten für Webseiten bei denen in der Cloud landen und dort abgreifbar sind, für Cloudflare und sonstige Angreifer.
Wo wir gerade bei Datenkraken waren: Stellt sich raus, dass Google Chrome Google-Webseiten gerne mal von Privatsphäreneinstellungen ausnimmt. Uns hat der Benutzer bestimmt nicht gemeint, als er gesagt hat, er will alle Cookies löschen!1!!
Update: Hier kommt gerade noch ein Leserbrief dazu rein, der einen anderen wichtigen Aspekt beleuchtet:
dieser Satz hier (Zitat)
As a result, the only thing every sent to a user's device is a package of draw commands to render the webpage and this also means that the company's new service will be compatible with any HTML5 compliant browser including Chrome, Safari, Edge and Firefox.hat für mich noch eine ganz andere Implikation. Wenn ich den Ansatz richtig verstehe, bekommt der *echte* Browser auf dem so kastrierten Gerät nur noch einen Satz svg.Draw-Kommandos statt der eigentlichen Webseite. Das bedeutet, dass auch alle Meta-Informationen über die Objekte der Seite wegfallen und alles nur noch über Koordinaten, wo der User klickt, laufen muss. Wie sie mit Tastatureingaben umgehen sagt der Artikel nicht. Auf jeden Fall zerschießt ein derartiger Ansatz einmal komplett und rückstandsfrei den Access-Tree einer Seite - nein *aller* Seiten. Das ist der Ort, wo assistive Software heutzutage 95% ihrer Informationen hernehmen um beispielsweise Webseiten vorlesen zu können, Vergrößerung anzubieten oder Navigation in Seitenstrukturen möglich zu machen.
Das ist ein Arbeitsplatz-Zerstörungsprojekt für jegliche Menschen mit einer Behinderung, die ihren PC anders als mit Point and click bedienen wollen oder müssen!
Stell dir nur mal den ersten Arbeitstag für so einen Menschen in seinem neuen Unternehmen vor.
Im Bewerbungsgespräch noch so: "Mit assistiver Technik kann ich, ggf. mit Anpassung, heute ziemlich jede Software schnell und produktiv bedienen."
Vor Ort so: "Dann richten Sie sich mal ein. Gern geben wir Ihnen etwas mehr Zeit dafür. Wir nutzen übrigens Cloudflare for Teams mit Browser Isolation."
Neue Angestellte: "Oh ..." *panischer Blick* "Kriegen wir das irgendwie anders hin?" (Erklärungsversuch)
Vorgesetzte und Personalerin: "..." *tauschen Blicke*
Bei Firefox muss man aktuell noch in about:config nach avif suchen ein ein Flag auf true setzen.
Encoding ist im Moment noch ein bisschen fummelig, weil die üblichen Verdächtigen das noch nicht in ihre Toolchains eingebaut haben, aber es gibt ein simples Go-Frontend, das auf den Encoding-Code aus libaom aufsetzt, das ich eh schon für meine Videocodec-Testereien installiert hatte, und der hat spontan funktioniert und ein 5MB JPEG runterkomprimiert auf unter 400k. Das Encoding dauert noch echt lange (für mein 4k-Testbild sowas wie 30 Sekunden), aber das Decoding im Browser flutscht, und darauf kommt es ja an.
Nun war mein Testbild einfach irgendein Foto, das ich rumliegen hatte, das war jetzt wahrscheinlich auch nicht gerade effizient JPEG-komprimiert. Aber dass AVIF was kann, das könnt ihr hier selber gucken. Angeblich kann Windows 10 das auch schon seit einer Weile, wenn man den kostenlosen AV1-Codec aus dem Store nachinstalliert. Interessiert mich aber nicht außerhalb von Firefox, ehrlich gesagt.
Und jetzt so: Ach scheiß drauf, wir nehmen lieber Chrome?
Das wäre doch eigentlich die Gelegenheit für eine Milliardenstrafe durch die EU gewesen. Wieso gab es die nicht?
Um mal den typischen Einwänden von Leuten, die den Artikel nicht gelesen haben, die Luft aus den Segeln zu nehmen:
Ich empfehle daher, die Spenden mit Zweckbindung zu versehen. Nur für Arbeiten an den Zukunfttechnologien Rust, Servo und Webrender. Man könnte sogar zweckbinden auf das Mozilla-Office in Deutschland und vor der Zahlung der nächsten Rate Effektivitätskontrollen setzen, wenn man Angst hat, dass die das verprassen. Die Sorge würde ich mir aber eher nicht machen, denn was die bisher auf diesen Gebieten geleistet haben ist durchaus eindrucksvoll und hat mich überzeugt.
Mag sein, aber wenn man nur Kommentare zu Visionen online stellt, bei denen keine Gefahr besteht, dass die Politik es verkackt, dann bleibt nichts übrig.
Um so wichtiger, dass man da Geld in die Hand nimmt, um Firefox als Alternative oder zumindest als glaubwürdige Drohung aufrecht zu erhalten!
Update: Kamen noch gute Entgegnungen rein. 1. "SAP kann das doch nicht" und 2. "Politiker? Die kriegen doch nicht mal die Sommerzeit abgeschafft".
Zu Punkt 1: Es ging nicht darum, ob jemand das im Moment gut macht oder nicht, sondern ob wir das Personal und die Ressourcen hätten, mit dem man das machen könnte. SAP leidet unter denselben Dingen wie alle anderen Großunternehmen. Wenn man da die Anreize ändert und das Management es mal ernsthaft betreiben würde, könnten die morgen anfangen, exzellente Software zu schreiben.
Zu Punkt 2: OK. You got me. Stimmt auffallend. Ich räume ein, dass der Artikel Teil meines Paper Trails ist, damit ich auch in 10 und in 20 Jahren kraftvoll sagen kann, ich hätte rechtzeitig angesagt, was getan werden muss.
Update: Zur Medienkompetenzschulung veröffentliche ich bei sowas immer meine Rohfassung.
Hier sind die Kriterien:
In einem ersten Schritt haben die Chrome-Entwickler Grenzwerte festgelegt: Anzeigen sollen maximal 4 Megabyte an Netzwerkverkehr verursachen. Innerhalb von 30 Sekunden darf eine Werbung maximal 15 Sekunden CPU-Last verursachen dürfen oder 60 Sekunden insgesamt.4 MB Daten! Ich glaube ja, Megabyte sind keine gute Einheit an dieser Stelle. Man braucht da verständlichere Einheiten. Praxisnahe Einheiten. Sowas wie Fußballfelder!
Ich schlage vor, Datenverbrauch ab jetzt in ICE-Kilometern auszudrücken. 4 MB ist dann sowas wie einmal Berlin-Hannover.
Update: Ein Leser aus Österreich merkt an, dass die Forderung nach verständlicheren Einheiten auch international gut ankommt. So sprach da eine FPÖ-Abgeordnete von "38 Gigabyte CO2-Ausstoß". Hier böten sich vielleicht Nightjet-Kilometer als Einheit an?
Der Effekt ist, dass Videokonferenzsysteme, wenn sie nicht von völlig inkompetenten Vollpfosten implementiert wurden, mit einer Größenordnung weniger Datenübertragung auskommen als ein Hollywood-Actionfilm oder gar ein gestreamtes Videospiel. Dieser Effekt macht so grob einen Faktor von 10 aus.
Es gibt allerdings auch einen Gegeneffekt. Videokompression kostet viel Rechenzeit. Wenn man mehr Rechenpower aufwendet, kriegt man effektivere Kompression. Bei Plattformen wie Netflix und Youtube lohnt es sich daher, einmalig in maximale Kompressionseffizienz zu investieren, weil man ja deutlich mehr ausstrahlt als man reinkriegt. Netflix und Youtube haben daher schon auf AV1 gesetzt, als das noch weit von Echtzeit-Kompressionsfähigkeit entfernt war. Heutzutage haben Grafikkarten auch Videokompressions-Hardware an Bord, aber die braucht für die gleiche Qualität im Allgemeinen deutlich mehr Bits als wenn man das in Software macht. Videokonferenzsysteme und Twitch-Streaming brauchen daher wegen ihrer Echtzeit-Anforderungen mehr Bandbreite. Dieser Effekt macht so grob einen Faktor von 2 aus.
Ein dritter Effekt hat wieder Vorteile für Filme statt Streaming: Für die Vorhersage überträgt man ein Standbild "aus der Zukunft", anhand dessen dann die Bilder dazwischen besser vorhergesagt werden können. Die Übertragung eines Standbildes kostet um die Faktor 100 so viele Daten wie die interpolierten Bilder zwischen Standbildern. Bei Konferenzen und Echtzeit-Streaming ala Twitch hat man keine Bilder aus der Zukunft, daher packt man auf den ganzen Stream ein bisschen Latenz. Aber nicht viel, denn das soll ja Echtzeit sein. Daher greift man nicht weit in die Zukunft und muss daher häufiger Standbilder übertragen. Bei undynamischem Content wie einer Telefonkonferenz kann das so Faktor 2 Bandbreitenbedarf ausmachen. Bei hochdynamischem Content wie einem Videospiel ist es eh egal, weil sich zwischen den Frames so viel ändert, dass man eh nicht so gut interpolieren kann.
Effekt 2 und 3 werden mehr als ausgeglichen durch den ersten Effekt, weil sich in Videokonferenzen im Allgemeinen kaum jemand bewegt und sich das daher super komprimieren lässt.
Wenn es jetzt also tatsächlich Knappheit im Internet gäbe (und nicht nur innerhalb der Netze von Kapitalisten-ISPs, die nie was in Netzausbau investiert haben), und man eine Stellschraube drehen wollen würde, dann sollte man lieber bei Twitch und co drosseln als bei Youtube und Netflix. Die arbeiten jetzt schon sehr nahe am technisch machbaren. Und man könnte Streamer aufrufen, nicht so rumzuwackeln :-)
Update: Was auch super gut komprimiert sind Vorträge, außer wenn der Kameraengel auf Speed war und die ganze Zeit die Kamera umschaltet und herumzoomt. Ihr könntet also die Zeit gerade gut nutzen, um euch mal die ganzen alten Kongressvideos vom CCC reinzuziehen. Weil solcher Content gut komprimiert müsst ihr euch auch kein schlechtes Gewissen machen, zuviel Bandbreite verschwendet zu haben.
Update: Noch ein paar Details. Man kann die Qualität der Standbilder runterdrehen, um Bandbreite zu sparen. Die Details kann man dann mit den Interpolations-Frames nachliefern. Der Effekt ist etwas, das ihr bestimmt schon mal bei einem Livestream gesehen habt: So ein "pumpen" der Qualität. Man kriegt immer ein total verwaschenes Bild und das wird dann rapide besser aufgelöst. Das macht niemand freiwillig, sondern das passiert, wenn man Codecs im Fernsehmodus betreibt. Fernsehen wird traditionell über Transponder in Satelliten gemacht, und jeder Kanal hat eine bestimmte Bandbreite. Die darf dann aber auch nicht überschritten werden. Daher waren die ersten Codecs auch alle auf eine fixe Bandbreite ausgelegt. So machen das aber heute weder Videokonferenzen noch Youtube noch Twitch. Im Internet überträgt man halt mehr Daten, wenn die Szene mehr Bandbreite braucht. Beim Digitalfernsehen teilen sich mehrere Kanäle einen Transponder. Die erste Gammelhardware hat dann halt jedem Kanal ein festes Stück Bandbreite gegeben, auch wenn auf Kanal 1 ein Testbild lief und auf Kanal 2 ein Actionfilm. Das ist heute nicht mehr so.
Update: Oh einen noch. Firefox und Chrome haben keinen Support für H.265 eingebaut. Das ist einer der Gründe, wieso es von Netflix unter Windows eine App gibt. Die kann dann H.265 verwenden und kommt mit weniger Bandbreite aus. Jedenfalls war das immer so. Jetzt rollt Netflix gerade AV1 aus, was auch Chrome und Firefox können. Damit wäre der Vorteil der App dann dahin.
Update: Ach du je, Twitch empfiehlt ernsthaft ihren Streamern konstante Bitrate. Der Hintergrund wird sein, dass sie keine Bandbreiten-Peaks haben wollen, wenn das Spiel hektisch wird. Aber das heißt, dass alle anderen Streams völlig sinnlos Bandbreite verplempern. Ich nehme also meine Aussage von oben bezüglich Twitch zurück und empfehle die Schließung von Twitch statt der Drosselung von Youtube und Netflix. Was für Pfeifen.
Und hat sich Sorgen gemacht, dass Microsoft in letzter Zeit so wenig versucht hat, ihren Usern unter illegaler Ausnutzung ihres Monopols ihre unterperformenden Ranztechnologien überzuhelfen, ob sie wollen oder nicht?
Gut, in Sachen erzwungene Windows-Updates und endlosem Rumgenerve, man möge Windows 10 installieren, war Microsoft eher nicht zurückhaltend. Aber es gab schon länger kein DU WIRST JETZT INTERNET EXPLORER BENUTZEN!!1! mehr.
Keine Sorge. Das Warten ist vorbei. Microsoft installiert jetzt allen Office 365-Usern ungefragt und ungebeten eine Chrome-Extension, die die Suchmaschine zu Bing umstellt.
Ach komm, Fefe, ich verwende Firefox, das betrifft mich nicht!
Support for the Firefox web browser is planned for a later date.Ach komm, Fefe, das ist doch nur die englische Seite, sowas würden die sich in der EU nie trauen!At this time, the extension will only be installed on devices in the following locations, based on the IP address of the device:- Australia
- Canada
- France
- Germany
- India
- United Kingdom
- United States
Doch, würden sie!Es ist allerhöchste Zeit, dass die EU diese Firma mal in ganz kleine Teile zertrümmert. Alternativ müsste einfach ein Gericht urteilen, dass man denen die Arbeitszeit für das Rückgängigmachen in Rechnung stellen kann. Dann könnte ich damit auch gut leben.
Stellt sich raus: Wenn man das Testing an Freiwillige crowdsourced, sind die Teilnehmer nicht aus dem Enterprise-Bereich. So segelte der Code ohne Probleme durch Monate des Testens.
Und jetzt merken plötzlich alle, wie sehr sie sich von Chrome abhängig gemacht haben.
"This has had a huge impact for all our Call Center agents and not being able to chat with our members," someone with a Costco email address said in a bug report. "We spent the last day and a half trying to figure this out.""Our organization with multiple large retail brands had 1000 call center agents and many IT people affected for 2 days. This had a very large financial impact," said another user.
"Like many others, this has had significant impact on our organization with our entire Operations (over 500 employees) working in a RDS environment with Google Chrome as the primary browser," said another system administrator.
"4000 impacted in my environment. Working on trying to fix it for 12 hours," said another.
"Medium sized call center for a local medical office lost a day and a half of work for 40-60 employees," added another.
Auf der anderen Seite muss man sagen, dass bei Chrome erstaunlich wenig schiefgeht. Wenn man das mal mit den ganzen verkackten Windows-Patches vergleicht, ist Chrome geradezu ein Anker der Stabilität und Verlässlichkeit.Update: Zur Klarstellung: Die Firmen haben das getestet und Chrome war erfolgreich im Einsatz, aber der Autoupdater von Chrome hat halt eines Tages diesen Experimentalcode ausgerollt, und ein "mach mal das letzte Update rückgängig" gibt es bei Chrome nicht.
Und jetzt ratet mal, welcher Firmenname explizit genannt wird! Kommt ihr NIE drauf!
"We have confirmed that in addition to the known incompatibility with specific versions of Symantec Endpoint Protection, some additional software applications may be causing “Aw, Snap!” messages in the latest Chrome M78 release."Nicht doch!! Symantec?! Ich dachte, das sind die Guten!!1! (Danke, Maciej)
Anfang des Jahres hatte uns ein Nutzer mitgeteilt, dass sein Browser, Firefox, meinte, Gentoo’s Installationsmedium würde Malware beinhalten.Erinnert an gmail. Da könnt ihr ja mal einen von Google ausgehenden Spam zu melden versuchen. Wenn ihr auf Kafka-Geschichten steht.Leider hatte der Nutzer den Download nicht beendet bzw. gleich wieder gelöscht (die Warnung sieht halt auch gefährlich aus!). Es stellte sich dann schnell heraus, dass zumindest zum Zeitpunkt unserer Prüfung, alle Mirrors die gleichen Dateien ausgespielt haben (Checksummen stimmen überein) und diese sauber waren (ja, wir haben unsere Images mit verschiedenen Schlangenöl-Lösungen geprüft).
Was war dann der Grund? Die Herkunft! Gentoo nutzt noch Mirrors, kostenlos bereitgestellt von Dritten und kein zentrales CDN. Einer dieser Spiegelserver, mirrors.kernel.org, ist in Google’s SaferBrowsing System gelistet. Aber nicht generell, nein, nur für das *gesamte* "/gentoo"-Unterverzeichnis.
Das schließt eben auch unser Installationsmedium in "/gentoo/releases/amd64/..." mit ein.
Wir haben dann irgendwann durch unsere Kontakte die Information bekommen, dass die Ursache im *Quellcode*-Archiv zu "Shadowinteger's Backdoor" (http://tigerteam.se/dl/sbd/) einem netcat-Klon stecken würde.
Was wir bis heute nicht wissen:
- Da Google’s SafeBrowsing offenbar in der Lage ist auf Verzeichnisebene zu flaggen, wieso haben sie dann die Warnung nicht zumindest auf /gentoo/distfiles beschränkt?
- Warum ist nur mirrors.kernel.org betroffen? Die Datei liegt auf allen unseren Spiegeln. Wenn nun also wirklich Gefahr von dieser Datei ausgehen sollte müsste der gemeine User, der sich auf SaferBrowsing verlässt, doch erwarten können, dass die gleiche Datei immer und überall erkannt und geblockt werden würde.
- Aktuell (das war vor paar Wochen noch anders) scheint tatsächlich die Quellcode-Datei von allen Quellen blockiert zu werden (also wirklich nur sbd-1.37.tar.gz), was Browser, die gegen das SafeBrowsing Download-API prüfen, verhindern.
Seit dieser Zeit kämpfen wir jetzt mit Google um eine Korrektur der Einstufung. Selbst mit unseren noch immer guten Kontakten zu Google (Hallo ChromeOS!) ist da nicht viel zu machen denn bekanntlich ist Google ein technisches Unternehmen: Die wissen, dass Menschen Geld kosten. Also tun die alles um Probleme technisch zu lösen und den Einsatz von Menschen zu minimieren, so auch im "Support": Erst wenn die Error-Rate zu einem gemeldeten Problem eine bestimmte Prozentschwelle überschritten hat, schaut sich ein Mensch den Sachverhalt an... :/
Zum Thema "Schlangenöl nimmt Webseite als Geisel und verhindert, dass Leute mit gängigen Browsern sie überhaupt zu Gesicht bekommen" möchte ich dir über meine Erlebnisse erzählen. Betrachte dich also bitte als Kummerkasten ;) Vielleicht findest du aber auch den ein oder anderen (Ab-)Satz für deine Leser interessant; in diesem Falle: bedien dich. (Und spring' von mir aus gleich zum TL;DR am Ende :)Lacher am Rande: Die Schlangenöl-Community macht das auch so. Die müssen sich ja auch ihre Samples gegenseitig zuschicken. Die tun das auch in ZIP-Files mit Standardpasswort.Im Vorfeld: Ich bin, was amoklaufende Virenscanner angeht, schon einiges gewohnt. Ich bin in der Demoszene aktiv (also jetzt nicht der mit den brennenden Autos, sondern der mit den Grafikdemos), insbesondere im Bereich 4k- und 64k-Intros, also Demos mit einer Größenbeschränkung auf wenige Kilobyte. Da kommen praktisch immer sehr spezielle Laufzeitpacker wie "Crinkler" (http://www.crinkler.net/) und "kkrunchy" (http://www.farbrausch.de/~fg/kkrunchy/) zum Einsatz, um noch das letzte Byte herauszukitzeln. Dummerweise haben wohl auch mal Malware-Autoren diese Packer zur Obfuscation benutzt, und da Schlangenöl-Hersteller das Brett an der dünnsten Stelle bohren, haben sie, anstatt die Malware ordentlich zu analysieren, einfach die Packer auf die schwarze Liste gesetzt. Da ich selbst ein paar mit besagten Packern komprimierte, aber an sich völlig harmlose 4k- und 64k-Intros auf meiner Webseite hoste, habe ich schon mehrfach von meinem Hosting-Provider böse Mails bekommen, ich möge doch binnen X Stunden meine Site saubermachen, sonst wird sie vom Netz genommen. Bisher ist das immer mit einer erklärenden Mail aufzulösen gewesen, zum Glück.
Andere Demoszener haben übrigens angefangen, ihre Intros in einer Form zum Download anzubieten, die automatisches Scanning unmöglich macht. Standard sind inzwischen ZIP-Archive, in denen die EXE-Dateien verschlüsselt abgelegt sind, und der Key steht in einer readme.txt oder so. Oder, ein besonders schräger Hack: Da liegt das Executable im Download-Archiv einfach ohne die "MZ"-Signatur (also die ersten zwei Bytes jedes Windows-Executables) vor. Erst eine mitgelieferte .bat-Datei klebt Header und Rest wieder zusammen und erzeugt eine gültige Windows-EXE.
Aber ich schweife ab.Irgendwann wurde es jedenfalls mit den Fehldetektionen noch schlimmer und Nutzer wurden daran gehindert, auch meine "normalen" Utilities, die nichts mit der Demoszene zu tun haben, herunterzuladen. Beliebte Ziele sind ein Tool, das in Python geschrieben ist und das ich für faule Windows-Nutzer mit einem Standard-Programm(!) in eine einzelne EXE verpackt habe. Oder ganz normale, mit Microsoft Visual C++ compilierte Executables.
Auch Google hatte mich schon immer auf dem Kieker. Der Aufruf des Verzeichnisses auf dem Server, in dem die Downloads lagen, führte schon länger bei Chrome-Nutzern zum gefürchteten "roten Bildschirm". Das war mir noch egal, aber vor zwei Wochen begann Google damit, meine gesamte .de-Domain als gefährlich einzustufen — einschließlich *aller* Subdomains, nicht nur der, wo das (angeblich) gefährliche Zeug lagert! Selbstverständlich wurde ich darüber nicht informiert (Mail an webmaster@meinedomain.de oder so? I wo!), ich habe es von Nutzern meiner anderen Webdienste erfahren, die auf anderen Subdomains liegen sind als der persönliche und Demoszenen-Kram.
Nun gibt es bei Google keine öffentliche, funktionierende Möglichkeit, "false positives" zu melden. Es gibt Dokumentation für Webmaster, was man tun soll, wenn Google Malware auf der eigenen Domain erkannt hat, aber die geht stets davon aus, dass man wirklich mit irgend einem Wurm infiziert ist. Die Option auf eigenen Irrtum scheint Google gar nicht zu kennen. Vor allem kriegt man nicht einmal heraus, *welche* konkreten Inhalte denn als schädlich erkannt wurden.
Es gibt aber eine Möglichkeit, nämlich die "Search Console". Um die zu nutzen, muss man sich gegenüber Google mit einem permanentem DNS-TXT-Record als Besitzer der Domain ausweisen (wohl dem, der die DNS-Records seiner Webseite unter Kontrolle hat!). Die Console selbst ist eher für SEO-Kram gedacht, aber da gibt es auch einen Menüpunkt "security issues" und tatsächlich stehen dort mal ein paar konkrete URLs von angeblich bösen Inhalten. Überraschenderweise waren das bei mir nicht die erwartete Handvoll Demoszenen-Intros, sondern nur eine zehn Jahre alte .tar-Datei mit einer Library, die als Beispielprogramm ein kkrunchy-gepacktes Windows-Executable enthielt. (Das Programm selbst war völlig harmlos: Es handelte sich um einen schlichten MP3-Player.) Nun ja, da gibt es einen "I have fixed the issues, request review"-Button, also hab' ich den mal gedrückt und im Freitextfeld eingegeben, dass es ein "false positive" ist (mitsamt ein paar Erläuterungen, wie was wo warum). Zwei Tage später die Antwort: Meinem Review Request konnte nicht stattgegeben werden, die Malware sei immer noch da. Die haben meine Erklärung gar nicht gelesen! Also habe ich die inkriminierende EXE-Datei aus dem Archiv entfernt und das Archiv zudem umbenannt (die ganze Library ist eh' obsolet). Nochmal "request review" gemacht, mit Freitext "ich hab's jetzt entfernt, aber ehrlich jetzt, Jungs, das wäre gar nicht nötig gewesen, weil …". Daraufhin: Nichts. Eine Woche lang keine Reaktion. Nach einer anderthalben Woche schaue ich nochmal in die Search Console, und siehe da: Jetzt ist ein anderes Programm der Stein des Anstoßes. Eins, das vorher schon da war. Eins, das nichtmal Crinkler oder kkrunchy benutzt, sondern schlicht UPX, den bekanntesten Executable-Packer überhaupt. Ein Bildbetrachter, in C++ geschrieben, mit Visual Studio compiliert und statisch gegen libjpeg-turbo und die Microsoft Visual C++ Runtime gelinkt. Das reicht also heutzutage aus, um mit einer ganzen Domain auf dem Malware-Index zu landen!
Zum Glück war das nur eine Testversion, also konnte ich die gefahrlos löschen und wieder den "request review"-Affentanz aufführen. Jetzt ist meine Domain erstmal wieder als unbedenklich markiert, aber für wie lange?TL;DR: Alles Scheiße.
Takeaway #1: Wenn Google deine Domain wegen angeblicher Malware-Infektion hops nimmt, erfährst du es nur indirekt von deinen Nutzern (außer du nutzt selbst Chrome mit aktiviertem "ich schicke erstmal jede aufgerufene URL an Google"-Phishing-Schutz, aber hey, das tust du natürlich nicht). Wenn du wissen willst, wo Google denn nun genau Malware auf deiner Domain gefunden hat, musst du an deinem DNS herummanipulieren und einen Google-Account haben, um die "Search Console" benutzen zu können. "False Positives" reporten geht nicht: Derlei Anfragen werden ignoriert, also lösch den Kram oder fuck you.
Takeaway #2: Es braucht nicht viel, um Schlangenöl zu triggern, deine (Windows-)Software als Malware zu erkennen.
- Laufzeit-Packer verwendet? Verdächtig!
- C-Library statisch gelinkt? Verdächtig! (siehe https://twitter.com/KeyJ_trbl/status/1138885991517839360 — selbst ein verdammtes "Hello World"-Programm wird schon von diversen Schlangenöl-Anbietern als Malware erkannt!)
- Python-Software mit PyInstaller (einem Standard-Paket in der Python-Welt) in eine einzelne Windows-EXE verpackt? Verdächtig! Wenn man (wie ich) möglichst kompakte Software für Windows (nur eine EXE-Datei, keine weiteren Dependencies) schreiben und veröffentlichen möchte, ist man quasi am Arsch.
Ich hab mich da immer aus der Ferne drüber totgelacht.
Mal ganz neutral analysiert ist das natürlich ein weiterer Fall von Externalisierung von Kosten. Wenn ich mir einen wirtschaftlichen Vorteil verschaffe, indem ich die durch meine Aktivitäten entstehenden Kosten Anderen aufdrücke. Wie bei Umweltverschmutzung und Atommüll. Die Tech-Riesen bieten einen Mail-Service an, und externalisieren die Spam-Kosten auf den Rest der Welt.
Ach ICH soll mir jetzt irgendwelche DNS-Records anlegen, und meine Mails vom Mailserver mit einem Domainkey digital signieren lassen, um EUER Spamproblem für euch einfacher lösbar zu machen? Go fuck yourself!
Oh aber selbst habt ihr nicht mal eine funktionierende abuse@-Adresse, wo man sich über von euch ausgehenden Spam beklagen könnte? Go fuck yourself!
Ihr verkauft Schlangenöl, das prinzipiell seine Funktion nicht erfüllen kann, und die Kosten für False Positives externalisiert ihr an … mich? Go fuck yourself!
Ich glaube, wir brauche mal eine Behörde für Digitalumweltschutz, die solche Geschäftsmodelle systematisch aus dem Verkehr zieht. Alle solche Firmen systematisch zumachen. Eine nach der anderen. Wer Kosten externalisiert, wird zugemacht. Und der Aufsichtsrat / der CEO / die Gründer / die Investoren sind persönlich haftbar für die Verfahrenskosten.
Ja aber Fefe wenn wir die ganzen Kosten selber tragen müssten, dann würde sich unser Geschäftsmodell nicht tragen!!1!
Wenn sich euer Geschäftsmodell nur durch Externalisierung von Kosten trägt, DANN TRÄGT ES SICH GAR NICHT. Man stelle sich mal vor, ein Wurstproduzent würde so argumentieren! Ja klar könnte ich hier Hygienestandards erfüllen, aber dann wäre das nicht profitabel!!1! Da würde doch niemand auch nur eine halbe Sekunde zögern, den aus dem Verkehr zu ziehen!
Ja klar könnten wir auch Bremsen in die Autos einbauen, aber dann wären wir preislich nicht mehr konkurrenzfähig!1!!
Unfassbar.
Heute so: "Norton Support" (nur echt mit dem Deppenleerzeichen!) reagiert auf Twitter auf einen meiner unautorisierten RSS-Reposter dort. Sagen, sie hätten es gefixt.
Aber wenn man auf den Link klickt, landet man bei der Norton-Statusseite zu ... einer völlig anderen Domain?! blog.fefe.de ist immer noch blockiert, obwohl die angebliche Schadsoftware auf www.fefe.de liegt und nicht auf blog.fefe.de. Und übrigens weder Schad- noch Software ist.
Wow, Symantec.
Das kann nicht einfach gewesen sein, meine Erwartungen noch zu enttäuschen. Und die waren eh nur knapp über der Nachweisgrenze.
Update: Hahaha, großartiges Timing, Symantec!
Fourth time in three months when Symantec's antivirus crashes something.
Das geht bald nur noch mit der Enterprise-Version.
In a response to the overwhelming negative feedback, Google is standing firm on Chrome’s ad blocking changes, sharing that current ad blocking capabilities will be restricted to enterprise users.Google ist halt wie die CDU. Zu sehr an ihren Erfolg gewöhnt. Kritik hören die gar nicht mehr. Wenn dann ist das bloß ein Missverständ nis. Die Kritiker haben bloß noch nicht klar genug erklärt bekommen, wie großartig wir sind, dsas wir die Guten sind. Wir sind so gut, wir können gar nichts böses tun!
Das killt mal eben 30-40% der (bezahlten) Performance. Und wegen der armen notleidenden Intel-Aktionäre verlang jetzt niemand von denen, dass sie ihre kaputte Hardware tauschen. Das muss daran liegen, dass Intel eine US-Company ist. Bei VW sah das noch ganz anders aus. Und bei Monsanto. Jedenfalls solange die nicht von Bayer gekauft wurden.
Der Effekt wird wahrscheinlich sein, dass die Leute jetzt neue Prozessoren mit mehr echten Cores kaufen. Win-Win-Win-Win für Intel!
Ich schalte Hyperthreading jedenfalls nicht ab bei mir. Und mein nächster Prozessor wird ein Ryzen.
Völlig unvorhergesehen und überraschend stellt sich nämlich heraus, dass Zertifikate ablaufen. Tsja, Mozilla, und DAS ist die Hölle, die ihr mit Letsencrypt einmal auf die ganze Welt rausgehauen habt. Nur halt nicht alle paar Jahre mal sondern alle paar Wochen mal. Wegen … uh … Yolo!!1!
Das Zertifikat, das hier abgelaufen ist, ist ein Intermediate Cert, das im Prozess des Signierens aller Add-Ons beteiligt ist. Denn Add-Ons müssen ja neuerdings signiert sein. Damit, wenn man sie über eine signierte Verbindung von Mozilla lädt, und da Malware drin ist, Mozilla sagen kann: Haha, nicht unsere Schuld!1!!
Ich frage mich ja, wie häufig Code Signing noch komplett versagen muss, bevor dieser unsägliche Bullshit-Trend mal endlich geerdet wird.
Mozilla hat jetzt jedenfalls Add-Ons komplett abgeschaltet.
Das Problem hat den schönen Namen "armagadd-on-2.0" gekriegt :-)
Update: Solange bei Firefox die Addons nicht gehen, würde ich lieber Chrome mit ublock/umatrix nehmen als Firefox ohne.
Update: Ein Leser meldet, dass man bei Firefox Nightly in about:config Addon-Signaturprüfung deaktivieren kann (Key xpinstall.signatures.required). Das hat natürlich andere Nachteile, wenn ihr nicht ausschließen könnt, dass euch freidrehende Software Firefox-Addons unterjubeln will. Auf der anderen Seite hatten wir ja auch schon genügend signierte bösartige Firefox-Addons. Mozillas Lösungsvorschlag ist, dass ihr alle Mozilla die Erlaubnis erteilt, Studien bei euch durchzuführen, und dann kommt innerhalb der nächste 6 Stunden hoffentlich diese eine magische Studie bei euch vorbei, die das fixt.
Zur Erinnerung: Google hat auch mit Youtube Edge gekillt.
Man vergleiche das mal mit dem Geheule bei Google, als Microsoft mit der Windows-Marktmacht Chrome zu bekämpfen versucht hat.
Mozilla has told BleepingComputer that they will be enabling the tracking feature called hyperlink auditing, or Pings, by default in Firefox. There is no timeline for when this feature will be enabled, but it will be done when their implementation is complete.Dass die Leute aber auch alle nie den Hals voll kriegen können! Wieso müsst ihr eigentlich wissen, auf welche Links ich klicke? Go fuck yourself!
Browsers such as Chrome, Edge, Safari, and Opera enable hyperlink auditing by default and most allow you to disable it. As we reported last weekend, future versions of these browsers will no longer allow users to disable hyperlink auditing at all.Das ist ja super, dieses Chrome!Oh, und falls ihr euch fragt, wieso Chrome das nicht abschaltbar machen will:
While not as common as JS and redirect tracking, this feature is used in the Google search results in order for Google to track clicks on their links.
Als Gegenstelle zum Spielen eignet sich Youtube, wo man das anschalten kann. Und beim Rumspielen kamen in der Tat schon einige Videos in AV1, als ich das angeschaltet habe.
Der Encoder ist aber noch vergleichsweise unakzeptabel langsam gewesen bei meinen Tests — es gibt andererseits einen Alternativ-Encoder in Rust, der angeblich schneller ist. Ich denke mal, von AV1 werden wir in Zukunft noch mehr hören.
Chrome kann schon länger AV1, aber wer benutzt schon Chrome.
Ich hoffe mal inständig, dass Firefox da nicht nachzieht. Da haben wir den Salat mit der Browser-Monokultur. Ich hätte ja bei solchen Dingen gerne häufiger Unrecht mit meinen apokalyptischen Vorhersagen.
I very recently worked on the Edge team, and one of the reasons we decided to end EdgeHTML was because Google kept making changes to its sites that broke other browsers, and we couldn't keep up. For example, they recently added a hidden empty div over YouTube videos that causes our hardware acceleration fast-path to bail (should now be fixed in Win10 Oct update). Prior to that, our fairly state-of-the-art video acceleration put us well ahead of Chrome on video playback time on battery, but almost the instant they broke things on YouTube, they started advertising Chrome's dominance over Edge on video-watching battery life. What makes it so sad, is that their claimed dominance was not due to ingenious optimization work by Chrome, but due to a failure of YouTube. On the whole, they only made the web slower.Now while I'm not sure I'm convinced that YouTube was changed intentionally to slow Edge, many of my co-workers are quite convinced - and they're the ones who looked into it personally. To add to this all, when we asked, YouTube turned down our request to remove the hidden empty div and did not elaborate further.
And this is only one case.
Gut, man kann jetzt argumentieren, dass dann wohl die Videobeschleunigung von Edge nicht so geil war, wenn sie sich von einem leeren div-Tag verwirren lässt. Aber das ist ja nicht der Punkt hier. Das ist genau das, wovor die Leute immer warnen, wenn sie vor einem Google-dominierten Web warnen.Übrigens, am Rande: Das "we couldn't keep up" liegt daran, dass Microsoft sich entschieden hat, solchen Browser-Updates nur mit neuen Windows-Releases rauszukloppen. Das ist sozusagen derselbe Mechanismus wie beim Patch Day. Einen Tag nach dem Patch Day sind Exploits für alle gefixten Sicherheitslöchen draußen. Und genau so ist dann halt einen Tag nach dem neuen Edge-Release ein Workaround da, wie man ihn Scheiße aussehen lässt. Die Lösung wäre häufiger shippen, nicht Umstieg auf Chrome. Aber hey. Was weiß ich schon.
Update: Youtube ist übrigens ein ergiebiges Stichwort an der Stelle.
Hat sich am Ende doch Open Source durchgesetzt im Browsermarkt auf Windows. Wer hätte das gedacht.
Hoffen wir mal, dass Microsofts Präsenz im Chromium-Projekt dazu führt, Googles Dominanz dort zurückzufahren. Google macht mit Chrome gerade genau dasselbe, wofür wir früher Microsoft gehasst haben. Entscheidungen nach Gutsherrenart, Einführen von "Features", anch denen nie jemand gefragt hat, Entscheiden über den Kopf der User hinweg. Ich bin daher seit Jahren Firefox-User, auch auf dem Smartphone. Leider ist der Marktanteil von Firefox gerade unter 10% gefallen — auf dem Desktop. Insgesamt ist es noch weniger, da die Plattformbetreiber alle alles in ihrer Macht stehende tun, um Firefox auf ihren Plattformen zu behindern, damit es ihrem Durchmarsch gegen die User nicht im Wege steht. Leider hat Firefox auch gefühlt jede Gelegenheit genutzt, ihren Usern das Gefühl zu geben, bei ihnen sei das alles dasselbe in Grün. Ich sagen nur: Werbung auf dem Startbildschirm, Tonnen von Tracking-Bullshit, und jetzt auch noch "Pocket".
Und dieser ganze dauernde Ärger verhindert dann, dass man an dem Rest Spaß hat. Mozilla macht ja eine Menge coole Scheiße, so ist das nicht. Rust zum Beispiel ist ein Lichtblick für die ganze Software-Entwicklungs-Branche. Es ist ein Wunder, dass das so weit gekommen ist, wie es ist. Da hätte ich dagegen gewettet, wenn mich jemand gefragt hätte.
Und es kann nicht darüber hinwegtäuschen, dass Firefox es nicht packt, unter Linux Hardware-Video-Playback hinzukriegen. Das verdoppelt mal eben den Stromverbrauch. Kriegt auch Chrome nicht hin unter Linux, übrigens. Aber wisst ihr, wer das hinkriegt? Ja richtig! Edge!
Update: Habt ihr eigentlich schon gehört? QUIC soll HTTP/3 werden! Ein weiteres beschissenes Google-Komplexitäts-Monster, nach dem keiner gefragt hat. Bei Microsoft haben die Leute wenigstens noch gemerkt, dass sie mit Microsoft Network gearbeitet haben und nicht mit dem Internet. Bei Google fahren alle Chrome und benutzen Google-Infrastruktur mit Google-Protokollen in der Google-Cloud, am besten noch über Google Fiber.
Mich betrifft das nicht, weil ich mich weder bei Chrome noch bei Google einlogge, und im Übrigen Firefox benutze. Aber ich sehe das inhaltlich ähnlich. Das ist ein Vertrauensbruch, und eine gute Gelegenheit, Chromes Marktanteil mal ein bisschen zu senken.
Um die Benutzer zu verwirren.
Oh, ähm, ich meine, um sie NICHT zu verwirren!1!!
Jetzt kann ich endlich mit dem Kernel-TLS herumexperimentieren, den sie frisch eingebaut haben. Das ist m.E. ein zentraler Baustein, um ordentlich TLS-Privilege-Separation zu implementieren, ohne dabei krass Performance zu verlieren. Könnte sogar besser werden, die Performance.
So, bleibt nur noch ein Problem. Wieso das olle Chromebook einen Suspend wie ein Ausschalten behandelt. Das nervt schon ziemlich. Das ist die einzige PC-Hardware hier im Haus, auf der ich Suspend wirklich mal benutzt habe.
Bei mir war "benutzt Electron" von Anfang an ein Ausschlusskriterium und ich kann das nur jedem von euch empfehlen, das auch so zu handhaben.
Mir ist ja völlig schleierhaft, wie Signal Desktop, das auf einer vergleichsweise soliden Plattform aufbaute, als es eine Chrome-Extension war, dann zu Electron wechseln konnte. What were they thinking!?
Wenn ihr Linux benutzt, dann ist die Antwort wahrscheinlich: Ja. Firefox und Chrome basieren darauf.
Cairo ist anscheinend in keinem guten Zustand. Money Quote:
My immediate problem with Cairo is that it explodes when called with floating-point coordinates that fall outside the range that its internal fixed-point numbers can represent. There is no validation of incoming data, so the polygon intersector ends up with data that makes no sense, and it crashes.Das ist immer voll super, wenn man mit ungültigen Eingaben crasht. Das ist gute Alzheimer-Vorbeugung. Man muss die Leute in Bewegung halten.Money Quote 2:
Cairo has a very thorough test suite… that doesn't pass.Ja prima!
Update: An der Stelle sei auch an den Sony-BMG-Rootkit-Skandal erinnert.
Lange nicht mehr las ich etwas so herzzerreißendes wie dieses tränendrüsenstimulierende Winsel-Posting des "founder and chairman of MPEG", die die Welt über die letzten 35 Jahre mit ihrer Patent-Scheiße in Geiselhaft genommen haben. Und die gerade merken, dass ihr Businessmodell tot ist, denn bei Audio gibt es was besseres und lizenzfreies (Opus) und bei Video demnächst auch, denn Google und Mozilla haben die Schnauze genauso gestrichen voll gehabt wie alle anderen.
Google hat daraufhin die Firma hinter VP8 gekauft und VP9 gestartet, und Mozilla hat den Leuten hinter Xiph.org (denen wir Vorbis und Opus zu verdanken haben!) finanziell unter die Arme gegriffen, und Cisco ist dann auch noch aufgesprungen und jetzt gibt es die "Alliance for Open Media", und deren Codec AV1 soll demnächst rauskommen. Ich kann es kaum erwarten. Der wird open source und frei benutzbar und für die Implementation fallen keine Patentgebühren an. Und von der Qualität soll es besser als HEVC werden — was übrigens so gut wie tot ist, falls ihr das nicht mitgekriegt habt. Chrome spielt es nicht ab, Microsoft hat den Codec aus Windows 10 geschmissen (kann man wohl noch über den Store nachinstallieren), und dass Nvidia an Bord ist, zeigt, dass die bei ihren Grafikkarten auch keinen Bock haben, diesen unerträglichen Patenttrollsumpf um die MPEG-LA zu finanzieren, nur damit ihre Grafikkarten HEVC beschleunigen dürfen.
Technisch ist HEVC ziemlich cool eigentlich. Wenn AV1 wirklich besser als das wird, dann ist das eine enorme Errungenschaft.
As we detailed in a deep-dive blog post last year, privacy reasons make it basically impossible to load the page from the publisher’s server. Publishers shouldn’t know what people are interested in until they actively go to their pages.Nein, natürlich nicht. Nur Google sollte das sehen können. Google schützt eure Privatsphäre!Der Lacher ist, dass die Leute das aus irgendwelchen Gründen voll doof fanden, dass jetzt alle Inhalte von google.com kommen. Vereinzelt wollten die sogar noch ein Web außerhalb von Google haben. Wie altmodisch. Aber fürchtet euch nicht, denn es gibt Hoffnung!
As recommended by the W3C TAG, we intend to implement a new version of AMP Cache serving based on the emerging Web Packaging standard. Based on this web standard AMP navigations from Google Search can take advantage of privacy-preserving preloading and the performance of Google’s servers, while URLs remain as the publisher intended and the primary security context of the web, the origin, remains intact.Ja, genau! Sie haben einen neuen "Web-Standard" erfunden und durch die W3C geprügelt, damit sie behaupten können, es sei ein Standard. Und bauen das in Chrome ein. Und der weicht dann anscheinend die Sicherheitsmechanismen des Origin auf. Weil, äh, YOLO!!We have built a prototype based on the Chrome Browser and an experimental version of Google Search to make sure it actually does deliver on both the desired UX and performance in real use cases.
Hier ist ein Talk, den das Team kürzlich gehalten hat (Folien dazu, Video dazu)
In den Chromebooks benutzen sie Coreboot, das hier ist ein anderer Ansatz.
Ich bin ja ein Freund davon, wenn Firmen Bugs in Software finden, und nicht bloß Bug Bounties ausschreiben und hoffen, dass ihnen die Bugs schon von außen gemeldet werden. Das ist eine Unsitte, weil es das Bugfinden zu einer Finanztransaktion macht und einen Markt schafft, in dem Geheimdienste einfach mehr zahlen können und dann kriegen die halt die Bugs und nicht der Hersteller.
Aber ich muss mich an der Stelle wundern, wenn die so tolle Mechanismen haben da (und der Hauptzweck des Artikels ist offensichtlich das Protzen, was sie für tolle Möglichkeiten haben), wieso verwenden sie sie dann nicht, um ihren eigenen Gammelbrowser besser zu machen?
Lasst euch von dem ganzen Mitigation-Gelaber nicht blenden. Das ist sowas wie eine Bankrotterklärung. "Wir versuchen gar nicht mehr, alle Bugs zu finden. Wir machen Mitigations rein". Das ist wie "Wir müssen unsere Dienste nicht absichern, wir haben ja eine Firewall".
Außerdem: Habt ihr euch mal gefragt, wieso die so viele Mitigations haben? Wieso hat der Less Privileged App Container nicht gereicht? Weil jede Mitigation umgehbar ist. Manchmal dauert das ein bisschen, manchmal geht es flott. Alles, was das tut, ist die wohlmeinenden Forscher behindern. Die Geheimdienste nehmen dann halt mehr Geld in die Hand.
Wenn ich Mitigation höre, dann denke ich mir immer: Je mehr Geld in Mitigations fließen, desto weniger Geld ist offensichtlich in das Finden und Schließen von Bugs geflossen. Das ist aus meiner Sicht ein Antipattern.
Im Übrigen möchte ich noch kurz darauf hinweisen, dass der Bugtracker von Chrome offen ist, da können wir alle reingucken, und uns davon überzeugen, wie schlimm der Zustand des Produktes ist. Das traut sich Microsoft bei ihrem Browser nicht (aber es gibt immerhin bei Chakra auch einen externen Bugtracker). Warum wohl?
Ein cheap shot, diese Aktion. Wirft kein gutes Licht auf Microsoft.
Ich habe ja noch nie unter einer Seite kommentiert, die ihre Kommentarfunktion an Disqus outgesourced hat. Ein Cloud-Startup aus den USA? Das mich site-übergreifend tracken kann? Ja nee klar, da tu ich meine Daten hin!1!! GANZ sicher nicht.
Und wo wir gerade bei Enttäuschungen waren: Firefox kommt jetzt mit Cliqz-Datenmalware. Die haben echt den Schuss nicht gehört bei Mozilla. Euer Browser ist groß, lahm, bloated, feature-arm, euren Add-On-Vorteil habt ihr euch gerade mit dem Umstieg auf Webextensions weggeschossen, und in Sachen Codequalität und Security hinkt ihr Chrome hinterher. Gerade als es anfing, nach Hoffnung zu riechen, weil sie Browserteile in Rust nachbauen und die Servo-Engine kommt, da zerschießen sie sich wieder alle gesammelten Karmapunkte, indem sie ihren Kunden ungefragt diesen Pocket-Cloud-Bullshit reindrücken. Und jetzt das.
Ich versuche ja wirklich immer und immer wieder, Firefox ihren Scheiß zu verzeihen. Ehrlich! Aber DAS? Wenn ich eine Branche nennen sollte, der ich weniger als allen anderen Branchen traue, wenn es um meine persönlichen Daten geht, noch weniger als den üblichen Unterdrückungs-Regierungsprojekten mit Kameras und Flugdatenweitergabe, dann sind es die fucking Verlage! Cliqz ist von Burda. BURDA! WTF?!
Die NSA bemüht sich ja wenigstens noch nach Kräften, die erhobenen Daten nicht wegkommen zu lassen. Aber die Verlage? Zero fucks given! Was da an Werbe- und Tracking- und Optimierungsnetzwerken eingebunden wird, da qualmt der Adblocker! Und weil das immer noch nicht unseriös genug ist, versucht uns die Burda-"Publikation" "Focus" gerade auf der Hauptseite windige Investment-Tipps überzuhelfen. Und DENEN soll ich trauen, dass sie meine Daten schützen?! GANZ sicher nicht!
Update: Warum nenne ich Cliqz Datenmalware? Habe ich mir das näher angesehen? Nein.
Es kommt per Drive-By-Download. Das reicht schon. Dazu kommt: Es lädt meine Suchanfragen in die Cloud hoch, während ich sie tippe, bevor ich Return drücke. Das alleine würde auch schon reichen. Und in dem Bug-Eintrag bei Mozilla verteidigt das jemand damit, dass es ja nicht alle Mausbewegungen aufzeichne sondern bloß wie weit man die Maus bewegt hat. Das alleine hätte auch gereicht.
Das Pixelbook scheint das alles zu haben. Kennt jemand andere Geräte mit vergleichbaren Features? Mir wäre wichtig, als CPU mindestens Kaby Lake zu haben, damit der HEVC in Hardware abspielen kann. Viele Nachteile kann ich da gerade nicht sehen, außer dass das Gerät nicht in Deutschland auf den Markt kommt und ich daher mit US-Tastaturlayout leben müsste. Ich habe im Wesentlichen zwei Anwendungsszenarien, für die ich das Gerät haben wollen würde. Erstens aufm Bett liegen und Filme gucken, ohne alle halbe Stunde nervös auf die Akkuanzeige zu gucken. Zweitens zu Veranstaltungen mitnehmen und damit im Publikum sitzen, ohne alle halbe Stunde nervös auf die Akkuanzeige zu gucken.
Chromebooks haben den großen Vorteil, dass die Hardware perfekt von Linux unterstützt wird, und dass der Bootloader ein Coreboot ist. Da kann man auch was anderes booten, wenn man Lust hat. Früher musste man noch ein Hardware-Siegel brechen, um in den Developer-Mode zu kommen, das ist seit Jahren nicht mehr nötig. Das könnte das ideale Linux-Gerät sein. Oh und lüfterlos ist es auch noch. Ich sehe gerade nur zwei Dinge, die für mich praktisch ein Nachteil wären: Nur noch Type-C USB (Maus anschließen bräuchte also einen Adapter) und keinen SD-Card-Reader mehr. Den habe ich bei meinem aktuellen Gerät immer benutzt, um die abzuspielenden Mediendateien aufs Gerät zu bringen.
$999 ist natürlich eine Menge Holz für einen glorifiziertes Videoabspielgerät. Auf der anderen Seite zahlen andere Leute soviel für ihre Telefone. In Europa kann man das dann wohl in UK ordern, aber hat dann mal eben 45% Preisaufschlag. Als ob es den Briten nicht schlecht genug ginge! Schäm dich, Google!
Ein Fuzzer ist ein Stück Code, das mehr oder weniger zufälligen Müll generiert. Dann lässt man den zu testenden Code drüber laufen und guckt, ob er abstürzt. Eine fürchtlich primitiv klingende Methode, aber sie ist immer wieder erschütternd effektiv. So auch dieses Mal.
Sie fanden in allen Browsern Bugs. In Chrome waren es 2, in Firefox 4, in IE 4, in Edge 6 und in Safari 17 (!!).
Apple wird also mal wieder ihrem in langen Jahren harter Arbeit erworbenen Ruf gerecht.
I stupidly fell for a phishing attack on my Google accountDie Witze über die Kompetenz von Web-Entwicklern könnt ihr euch ja selber dazudenken. (Danke, Patrick)
Daher jetzt auch mal was Konstruktives. Eine Einsendung von Kris Köhntopp, wie man Rollout und Testing richtig macht.
Victim Blaming: »Patching is hard? Yes—and every major tech player, no matter how sophisticated they are, has had catastrophic failures when they tried to change something. Google once bricked Chromebooks with an update. A Facebook configuration change took the site offline for 2.5 hours. Microsoft ruined network configuration and partially bricked some computers; even their newest patch isn't trouble-free. An iOS update from Apple bricked some iPad Pros. Even Amazon knocked AWS off the air.«Ein Canary ist ein Kanarienvogel im Kohleminen-Sinn. Man schiebt die neue Version nicht gleich auf das ganze Rechenzentrum, sondern erstmal nur auf ein paar Kisten, und da routet man nur ein paar User hin. Und guckt, ob es platzt. Das ist an sich eine gute Praxis, aber man muss aufpassen, dass man das nur kurzzeitig macht. Ich habe schon Firmen gesehen, die praktisch permanent diverse Versionen parallel ausgerollt hatten. Das ist nicht gut.Wo ich arbeite haben wir dieselbe Beobachtung gemacht. Wir haben ein Outage Budget, d.h. wir messen die tatsächlichen Einnahmen und vergleichen mit den vorhergesagten Einnahmen. Ist durch einen mißglückten Rollout ein Einnahmeausfall zu verzeichnen, buchen wir das vom Outage Budget ab.
Wir versuchen das so gut als möglich zu treffen. Wenn wir mehr Outage als geplant haben, ist das zu viel Risk Taking, wenn wir zu wenig Outage hatten, ist das nicht genug Risk Taking und wir sind zu langsam und complacent.
Häufige Rollouts sind kleine Changes und die sind viel besser zu kontrollieren als große unübersichtliche Changes. Daher versuchen wir, so oft als möglich einen Rollout (== Patch) zu machen und so die Patches möglichst klein zu halten.
Wenn wir Rollout-Probleme haben, dann meist in den Subsystemen, die wir nicht oft genug ausrollen und in denen dann sekundäre Changes (== Library Changes, die mit sich schneller ändernden Systemen geteilt werden) den Rollout zerknallen. Die Lösung ist für uns, so was auch dann auszurollen wenn sich im Code selbst nix geändert hat (also Dependency-Änderungen auszurollen).
Alles in allem ist das eine sehr anschauliche Darstellung von Technical Debt: Je größer der Diff zwischen ausgerollt und trunk ist, um zu wahrscheinlicher ist es, daß Trunk in Production explodiert.
Um Patching sicher zu machen, muß man es oft tun.
Wenn man oft patchen möchte, müssen Patches und deren Rollouts ein Operativer Prozeß und kein Upgrade-Migrationsprojekt sein.
Wenn Rollouts ein operative Prozeß sein sollen, dann muß man Testen in der Produktion sicher und überlebbar machen.
Um Testen in der Produktion sicher zu machen, muß man:
- das Austeilen von Code und die Aktivierung von Code trennen, also Feature Flags und Experiments einführen,
- sich ändernde persistente Datenstrukturen doppelt führen (alte und neue Version gleichzeitig und parallel aktualisieren, sodaß alter und neuer Code coexistieren können).
- Reporting und Monitoring exzessiv ausbauen und den Monitoring Lag (Event Timestamp vs. Timestamp in dem das Event im Monitoring auf dem Operator Screen sichtbar wird) mitloggen und Anzeigen ("Monitoring Framerate einblenden")
- und den Leuten klar machen, daß es wichtig ist, eine Fehlerkultur zu etablieren ("blameless postmortem" einführen und durchsetzen).
- Canaries
- Overcapacity
- nur 2 Versionen aktiv zur Zeit (also nicht drei- oder mehrphasige Rollouts laufen haben)
Alles kein Hexenwerk eigentlich.
Overcapacity heißt einfach, dass man nicht am Limit fährt mit seiner Hardware, damit man eine Performance-Regression zur Not mal kurzzeitig abfangen kann.
Stört euch bitte nicht an dem Denglisch, das ist in der Ops-Abteilung von internationalen Firmen durchaus normal :-)
Update: Kris hat das auch in sein Blog getan und verlinkt dort auch ein paar Vorträge, die er in dem Bereich gehalten hat.
Update: Lutz Donnerhacke, der über X.509 schon mehr vergessen hat, als ich weiß, erklärt:
Sie haben Recht mit der Vorgehensweise.
Der relevante RFC 2818 sagt, dass wenn SubjectAltName existiert, man ihn nehmen MUSS.
Sie haben unrecht mit der Behauptung, der RFC erkläre den CN für obsolet.
An der betreffenden Stelle wird die Praxis der CAs, einen CN statt SubjectAltName zu verwenden für obsolte erklärt.Der eigentliche Grund für die Vorgehensweise ist die Vorschrift in X.509 dass SubjectAltName für v3-Zertifikate Pflicht ist.
Update: Weil jemand nachfragte: Nein, Lutz und ich duzen uns. Das Sie bezieht sich auf das Chrome-Team.
Unacceptable ad types would be those recently defined by the Coalition for Better Ads, an industry group that released a list of ad standards in March. According to those standards, ad formats such as pop-ups, auto-playing video ads with sound and “prestitial” ads with countdown timers are deemed to be “beneath a threshold of consumer acceptability.”OH FUCK YEAH, DANKE!!! Wenn ich nie wieder ein "bitte liken Sie uns auf Facebook und subscriben Sie" Popup sehen muss, steigt meine Lebensqualität deutlich.
udp.c in the Linux kernel before 4.5 allows remote attackers to execute arbitrary code via UDP traffic that triggers an unsafe second checksum calculation during execution of a recv system call with the MSG_PEEK flag.Das klingt jetzt schlimmer als es ist, denn MSG_PEEK wird selten benutzt, UDP wird selten benutzt, und MSG_PEEK bei UDP wird noch seltener benutzt. Mir ist persönlich kein Fall bekannt.Ich habe dieses Flag in meiner Laufbahn 1-2 Mal benutzt. Man nimmt es, wenn man von einem Socket ein paar Bytes lesen will, ohne die zu lesen (d.h. wenn man danach nochmal read aufruft, kriegt man die Bytes wieder). Ich benutze das in gatling, um zu sehen, ob Daten auf einer SSL-Verbindung wirklich wie ein SSL-Handshake aussehen — allerdings auf einem TCP-Socket.
Kurz gesagt: Ich mache mir da jetzt keine großen Sorgen. Die DNS-Implementationen von glibc, dietlibc und djb benutzen jedenfalls nicht MSG_PEEK, und wenn es um UDP geht, ist DNS der übliche Verdächtige.
Ich will das nicht kleinreden, das ist ein ganz übler Bug und die sollten sich was schämen. Aber es ist kein "OMG die NSA hat mich gehackt, ich reinstalliere und mache alle Keys neu"-Bug. Außer ihr fahrt auf eurem Server irgendwelche UDP-basierten Protokolle.
Update: Im OpenVPN-Code findet grep auch kein MSG_PEEK. VPN und VoIP wären die anderen in Frage kommenden Codebasen.
Update: Ein paar Leser haben bei Debian und Gentoo mal ein bisschen rumgesucht und fanden als potentiell verwundbare Pakete dnsmasq und VNC-Implementationen. dnsmasq läuft praktische allen Plasteroutern. Das wäre in der Tat potentiell katastrophal.
Update: Einsender weisen darauf hin, dass systemd angeblich MSG_PEEK benutzt, und dass möglicherweise noch Chrome in Frage kommt als Angriffspunkt, wegen QUIC.
Begründung: Firefox setzt jetzt zwingend auf pulseaudio auf.
Ist bestimmt mein pulseaudio 8 braun, installiere ich mal pulseaudio 10. Der Daemon kommt ohne Fehlermeldung nicht hoch. Stellt sich raus, dass es da ein Consolekit-Modul gibt, das der reinlädt, und der failed anscheinend unklar, und damit kommt das ganze Ding dann nicht hoch. Modul gelöscht, Daemon kommt hoch. Findet kein Audio.
Nee, warum auch. Chrome findet Audio, Alsa findet Audio, Mplayer findet Audio, ffplay findet Audio, mpg123 findet Audio. Skype findet Audio. SKYPE! Das stinkende Flash-Plugin findet Audio! Gute Arbeit, Herr Pöttering. Flash findet Audio, dein Code nicht. Großartig. Das muss man erst mal hinkriegen, schlechter als Flash zu sein.
Nach ein bisschen Debugging stellt sich raus, dass es keine Fehlermeldungen gibt. pulseaudio findet ein Null Sink. That's it.
Gibt es eigentlich irgendwas, was der angefasst hat, das nicht als Totalschaden endete? Der Michelangelo der kritischen Infrastruktur! Was er anfasst, wird ein Gesamtkunstwerk! Kann nicht debuggt werden, nur bewundert. Der Midas der Middleware! Was er anfasst, wird zu … nunja.
Dann halt kein Firefox mehr. Die sind von der Security her eh nicht mit Chrome mitgekommen. Und das alleine ist ja schon ein Totalschaden, wenn man mal drüber nachdenkt.
Ich könnte mich ja über die FAQ von pulseaudio stundenlang amüsieren. Auf wie viele Arten das bei den Leuten da draußen nicht geht. Und an keiner Stelle kommt jemand auf die Idee, dass vielleicht Pulseaudio einfach noch nicht bereit ist für eine verantwortungsvolle Rolle.
Ach nee komm, da bauen wir noch eine dynamisch nachladende Modulschnittstelle an. Und eine IPC-Bus-Schnittstelle, die dann failed, wenn der Bus nicht da ist. Und eine Schnittstelle für Consolekit (was übrigens "not actively maintained" ist, KLAR dependen wir auf sowas!!1!). Ich würde ja einen CORBA-Joke machen, wenn Gnome nicht auch schon mal darauf eine Abhängigkeit gehabt hätte. Es ist alles so traurig.
Update: Ein Einsender weist darauf hin, dass jemand einen Pulseaudio-Emulator geschrieben hat. Wie krass.
There is little consensus within the security community on whether HTTPS interception is acceptable. On the one hand, Chrome and Firefox have provided tacit approval by allowing locally installed roots to bypass key pinning restrictionsWait, what?! Wahrscheinlich weil sonst das Schlangenöl alles kaputtmachen würde, oder wie? Hey macht ja nichts, wenn wir damit Malware Tür und Tor öffnen, Hauptsache Schlangenöl schlängelt schön!
Die Funktionalität ist jetzt nur noch über die Developer Tools benutzbar. F12 -> Security Tab -> View Certificate
Was die sich wohl dabei gedacht haben!?
Das erste, was bei Rust auffällt: Man kann es nicht aus den Sourcen bauen. Ich möchte immer gerne vermeiden, anderer Leute Binaries auszuführen. Das ist eine Policy bei mir. Wenn ich es nicht selbst gebaut habe, will ich es nicht haben. Es gibt nur wenige Ausnahmen, bei denen der Buildprozess zu furchtbar ist, oder so fragil, dass das selbstgebaute Binary am Ende nicht so gut funktioniert wie das "offizielle", weil die auf irgendwelche speziellen Compilerversionen setzen oder so. Die einzigen Sachen, die ich hier nicht selber baue, sind im Moment Chrome, Libreoffice (falls ich das so einmal pro Jahr mal brauche) und ripgrep. Und ripgrep wollte ich mal ändern. Außerdem finde ich Rust von den Konzepten her spannend und will mal damit rumspielen.
Erste Erkenntnis: Die neueren Versionen von openssl-rust können OpenSSL 1.1. Allerdings kann man Rust nicht aus den Sourcen bauen, ohne schon eine Version von Rust zu haben. Das finde ich sehr schade. Das ist ein Spannungsfeld, das viele Programmiersprachen betrifft. Programmiersprachen haben Angst, erst ernst genommen zu werden, wenn sie self-hosting sind. Die Download-Seite von Rust will einem erstmal Binärpakete aufdrücken, was ich immer ein schlechtes Zeichen finde. Binärpakete ist der schlechte Kompromiss für Leute, die zu doof sind, aus den Sourcen zu bauen. Und die sind bei Rust nicht Zielgruppe. Dafür ist die Lernkurve zu steil bei Rust.
Aber wenn man runterscrollt, kriegt man auch die Quellen. Und wenn man da configure und make aufruft, dann … zieht der ungefragt ein Binärpaket einer älteren Rust-Version, installiert das, und baut dann damit. Das vereint die Nachteile von "aus Binärpaket installieren" mit der Wartezeit von "aus Quellen bauen" und weicht etwaigen Vorteilen weiträumig aus. Völlig gaga. Aber es gibt eine configure-Option, dass man das installierte Rust haben will.
Aus meiner Sicht ist der perfekte Kompromiss, was Ocaml macht. Da kommen die Quellen mit einem kleinen C-Bootstrap-Interpreter, und der baut dann den Compiler, und der baut sich dann nochmal selber. So muss das sein. Ist es aber bei Rust leider nicht. Bei Go auch nicht mehr, übrigens.
Anyway. Wenn man das über sich ergehen lässt und Rust aus den Sourcen baut, dann kriegt man eine Version ohne cargo. cargo ist das Packaging-Tool von Rust. Ohne cargo kann man nichts bauen. Insbesondere kann man nicht cargo ohne cargo bauen. Und da muss ich sagen: WTF? Selbst GNU make kann man ohne make bauen! Das ist ja wohl absolut offensichtlich, dass man solche Henne-Ei-Probleme vermeiden will!?
Insgesamt muss ich also meine Kritik zurückziehen, dass Rust immer noch nicht mit OpenSSL 1.1 klarkommt. Tut es, nur halt anscheinend nicht in der stable-Version. Aber diese cargo-Situation finde ich ja noch schlimmer als die OpenSSL-Situation war. Meine Güte, liebe Rust-Leute! Bin ich ernsthaft der erste, der über das Bootstrapping nachdenkt?!
Oh ach ja, ripgrep. ripgrep kann man nicht mit der Stable-Version von Rust kompilieren. Und auch nicht mit der Beta-Version. Das braucht die Bleeding-Edge-Version.
Nun ist Rust eine relativ frische Sprache und sie haben daher eine Familienpackung Verständnis für so Kinderkrankheiten verdient. Aber dann nennt euren Scheiß halt nicht Version 1.irgendwas sondern 0.irgendwas.
Update: Wie sich rausstellt, lässt sich ripgrep doch mit älteren Rust-Versionen kompilieren, allerdings dann ohne SIMD-Support. Wenn ich ripgrep ohne SIMD-Support haben wollen würde, könnte ich auch grep -r benutzen oder silver surfer. Was ich versucht habe, um ripgrep zu bauen: git clone + cd ripgrep + ./compile. Mir erklärt jetzt jemand per Mail, dass das gar nicht der offizielle Build-Weg ist unter Rust. Das hat sich mir als Rust-Neuling so nicht erschlossen. Und es wirft die Frage auf, wieso der Autor von ripgrep dann ein configure-Skript beliegen muss und das dann auch noch was anderes tut als der Standard-Buildweg. Ist der Standard-Weg kaputt und man kann die zusätzlichen Flags, die er da benötigt, nicht einstellen?
Update: Ein paar Leute fragen jetzt rhetorisch, wie ich denn meinen C-Compiler gebootstrappt habe. Das Argument könnte man gelten lassen, wenn es von Rust aus möglich wäre, einen C-Compiler zu bootstrappen. Ist es aber nicht. Aber mit einem C-Compiler kann man diverse andere Sprachen bootstrappen, u.a. Go, Lisp, Forth, Scheme, Ocaml, C++, Javascript, Java, .... Aber um kurz die rhetorische Frage zu beantworten: Meinen C-Compiler habe ich cross-compiled. :-)
Update: Bei Ocaml ist es auch nicht so rosig, wie ich es geschildert habe. Der in C geschriebene Interpreter ist bloß ein Bytecode-Interpreter, und ein vor-gebauter Bytecode liegt dann halt binär bei. Ist auch nicht ideal. Das ist halt auch ein schwieriges Problem. Ich frage mich halt, ob man bei sowas wie Rust nicht trennen kann. Mein Verständnis war, dass die Sprache Rust schon ziemlich final ist und die Dynamik eher in der Laufzeitumgebung und den Libraries ist. Dann könnte man ja beispielsweise einen Minimal-Interpreter oder Nach-C-Übersetzer bauen, der sich die komplizierten Dinge wie Borrow-Checker, Solver und Optimizer spart.
In other news: Windows 7 und 8 haben mysteriöserweise mehr Neuinstallationen als Windows 10.
Ein Javascript-nach-Root-Sandbox-Ausbruch auf ChromeOS, wie sich rausstellt!
Update: Chrome hat ähnliche Probleme (24GB/Tag).
Das schöne an dem Gerät ist, dass man da auf relatig gut dokumentierte Art und Weise eine größere SSD einbauen und Linux parallel installieren kann, und dann hat man ein nahezu vollwertiges Linux-Netbook. Nachteil: Hat nur 2GB RAM, damit muss man halt klarkommen. Aber war in der Praxis nie ein Problem.
Ich dachte mir gerade, ich kauf da noch einen von, aber die sind wohl ausgelaufen und nur noch hie und da gebraucht verfügbar.
Hat zufällig jemand einen Überblick über die anderen aktuellen Chromebooks, ob es ein Modell mit ähnlichen Rahmenbedingungen gibt?
Das war so ein guter Kauf, dass ich mich rückblickend echt ärgere, nicht gleich zwei gekauft zu haben.
Ich hatte da übrigens zum Testen ein Arch-Linux draufgetan, um das mal irgendwo im Einsatz zu haben, und kann die Distro auch nur empfehlen. Ich fahre sie modifiziert, mit eigenem Kernel und ohne systemd, dafür mit minit. Aber so das Paketierungs- und Update-Konzept überzeugt mich bisher.
Update: OK also es stellt sich raus, dass das C720 Nachfolger-Modelle hat. Das C730 sollte man vermeiden, aber das aktuelle heißt C740 und ist vergleichbar. Das gibt es auch in einer 4GB-Variante, aber nicht in Europa. Überhaupt muss man sagen, dass die Chromebook-Auswahl in Europa nur so ein Drittel bis die Hälfte dessen ist, was man in den USA kriegen kann (nur halt mit US-Keyboard dann; manche stehen auf das US-Keyboard-Layout, ich habe lieber das DE-Layout, fürs Bloggen will ich Umlaute haben). Und dann die Preisunterschiede. Hier in den USA $149.99, hier in Deutschland 380 €. Was für eine Frechheit. Und dann wundern die sich immer, dass der Chromebook-Markt in Deutschland schwächelt.
Update: Jemand weist darauf hin, dass das 720 einen core-Prozessor hat, das 740 einen Atom. Vielleicht gibt es da verschiedene Modelle? Ich sah hier was von Celeron 3205U, und das ist ein Broadwell, kein Atom.
Update: Der eine Amazon-Vergleichslink geht offenbar zu dem falschen Produkt. Seufz.
Heilige Angriffsoberfläche, Batman! Fehlt ja nur noch eingebettetes Flash!
Ich verweise dafür auf dieses Blogposting von 2008. Schlangenöl funktioniert nicht und verarscht die Benutzer. Und ihr merkt es gerade am eigenen Körper.
Nein, ich werde 42.zip nicht löschen. Das bleibt als Furunkel am Arsch der Schlangenölindustrie kleben, bis es nicht mehr nötig ist. Und solange die sich zum Stück Brot machen, indem sie dann meine Site blocken, ist es noch nötig.
Mich würde mal interessieren, wieviel davon ein reines Windows-Problem ist, und wie doll Chrome plattformübergreifend stinkt an der Stelle. Von Apple-Usern hört man ja auch, dass ein Laptop im Akku-Modus mit Safari deutlich länger durchhält als mit Chrome.
Ich habe das bisher nicht gemessen, aber mir ist unter Linux aufgefallen, dass die Videocodecs in Firefox schlecht sind (wobei das vermutlich vp9 ist). Youtube in Fullscreen (4k) flutscht mit Chrome, aber mit Firefox ruckelt und wackelt es.
Nur mal so als Datenpunkt muss ich aber sagen, dass ich die längste Batteriezeit beim Webklicken bisher mit Chromebooks erlebt habe.
Value range propagation now assumes that the this pointer of C++ member functions is non-null. This eliminates common null pointer checks but also breaks some non-conforming code-bases (such as Qt-5, Chromium, KDevelop). As a temporary work-around -fno-delete-null-pointer-checks can be used. Wrong code can be identified by using -fsanitize=undefined.Hach das merkt doch eh keiner, wenn Qt und Chrome nicht mehr gehen! Wer benutzt schon Qt oder Chrome? Niemand!1!!
Wer das nicht lustig findet, dem kann ich versichern, dass es hervorragendes Entertainment ist, wenn man nicht selbst betroffen ist. Einfach mal probieren!
Und nun stellt euch meine Überraschung vor, als der Rant in genau die Gegenrichtung geht.
Ich zitiere mal:
Chrome has had such a problem with performance they formed a special group just to work the problem, but in nearly two years time that group has yet to produce anything tangible.Wait, what? Chrome ist ihm zu langsam!?Ja gut, Chrome ist in der Tat gelegentlich langsam. Wenn so Leute wie dieser Vollpfosten monströse "Anwendungen" in Javascript zu machen versuchen. Guckt euch nur mal seine Beschwerdeliste an:
keep your JS/HTML/CSS payload under 1MB- Keeping the JS payload below 750kb seems to be the key point for Android, but keeping below 500kb is more ideal.
- Mobile Safari can honestly handle 2-4MB apps without blinking, yes, the parse and compile performance differences are that severe.
- complicated, verbose CSS is just as bad as complicated verbose JS
No Shit, Sherlock! "Complicated, verbose" irgendwas ist Scheiße. Auch ohne verbose ist complicated schon Scheiße!You want to keep a fairly low DOM node count, I target <5k nodes, ideally peak at <10k nodes and I make heavy use of occlusion and recycling to achieve that.Oder, alternativ, könnte man auch Sites mit weniger als 1k nodes machen. Ihr werdet lachen, das geht!Aber diese Javascript-Deppen gehen ja inzwischen dazu über (die Google-Ratschläge sind an der Stelle großartige Unterhaltung), Bilder nicht im HTML zu laden, sondern im HTML Platzhalter zu haben und die Bilder dann per Javascript später zu laden. Weil, äh, dann rendert die erste Seite schneller. Oder so.
Leute, wenn ihr euren Misthaufen immer größer werden lasst, dann könnt ihr am Ende nicht mit dem Finger auf Google zeigen, wenn der Gestank zu groß wird! Es ist euer Misthaufen, der hier stinkt, nicht Chrome!
Der Vollständigkeit halber hier meine früheren Ausführungen zum Thema "schnell landende Webseiten".
Darauf haben damals, als Chrome mit dem Auto-Update-Kram anfing, einige Paranoide hingewiesen. Heute erinnert sich da kaum noch jemand dran.
Schön formuliert:
So when Apple says the FBI is trying to "force us to build a backdoor into our products," what they are really saying is that the FBI is trying to force them to use a backdoor which already exists in their products. (The fact that the FBI is also asking them to write new software is not as relevant, because they could pay somebody else to do that. The thing that Apple can provide which nobody else can is the signature.)Ich ärgere mich ja inzwischen mehr darüber, dass Firefox keine Diffs für ihre Quellcode-Tarballs anbietet, aber für die Binaries irgendwelche schrottige Bindelta-Technologie haben. Die wollen schlicht gar nicht mehr, dass jemand den Quellcode anguckt oder selber aus den Quellen seine Pakete baut. Das ist nur noch ein PR-Argument, kein inhaltliches mehr.
Der Nachteil von Silbentrennung ist, dass der Browser wissen muss, in welcher Sprache der Text ist. In gemischtsprachigen Umgebungen wie meinem Blog muss ich das pro Blockquote-Umgebung einstellen. Das Blog hat dafür jetzt eine gammelige Heuristik, die auf den ersten Blick ganz gut zu funktionieren scheint. Mal schauen. Betrifft euch eh nur, wenn ihr ein CSS verwendet, das Silbentrennung aktiviert. Und einen Browser, der das kann.
In typo3.css habe ich auch ein paar Vorschläge eingearbeitet, wie man die Schrift skalierbar macht und das auch auf Mobiltelefonen funktionierend hält.
Die ganze Schönheit von typo3.css kriegt ihr aber nach wie vor nur, wenn ihr auch Source Serif installiert.
Update: Ein Einsender kommentiert:
Subject: Chrome Cleanup-Tool..
..geklickt. Wird von Windows Defender als Schadsoftware erkannt und entfernt :(
m(
Und noch ein E-Mail-Kommentar:
Noch schlimmer als die Toolbars sind falsche Chrome Versionen. Wenn jemand in der Verwandtschaft oder dem Freundeskreis einen neuen PC hat wird man ja stets gefragt was installiert werden muss. Das erste was ich hab so einem Anruf sage ist "Chrome herunterladen". Die Person am anderen Ende gibt das dann meist einfach in die Adressleiste des IEs ein und landet hier:
http://www.bing.com/search?q=chrome+herunterladen
(AdBlocker deaktivieren um zu sehen was der normale Nutzer sieht)
Die ersten 2 Links sind Webseiten die behaupten Chrome anzubieten, aber ihren eigenen verseuchten Browser anbieten. Sieht aus wie Chrome, ist es aber nicht.Nach der Installation kann man eigentlich nur noch eine Sachen machen, zum "Kunden" fahren und PC neu aufsetzen.
Das Zeug nistet sich so tief im System ein das es einfach leichter und schneller ist von vorne anzufangen.
SNI ist eine TLS-Erweiterung, bei der als Teil des Handshakes der Name des Servers überträgt. Vor SNI konnte man pro IP-Adresse nur einen Server per SSL hosten. Meines Wissens unterstützen alle Browser SNI. Dachte ich jedenfalls.
Ich trug also das Letsencrypt-Cert per SNI ein, testete und alles war gut.
Aber es sieht aus, als war das Zufall, denn alle Nase lang kriegte jemand noch das Fallback-Cert zu Gesicht.
Beim Debuggen kam raus, dass das SNI-Callback auch später in der Verbindung nochmal kommen konnte, nicht nur während des Handshakes am Anfang. gatling macht virtuelles Hosting über Unterverzeichnisse, d.h. die Daten für "blog.fefe.de" sind in den Unterverzeichnissen "blog.fefe.de:80" und "blog.fefe.de:443", je nach dem wie der Client reinkommt. Nach dem initialen Handshake ist gatling dann in dem jeweiligen Unterverzeichnis und findet im SNI-Callback das Zertifikat nicht mehr.
Ich habe das dann als kurzer Hack so gefixt, dass ich die Zertifikate mit dem vollen Pfad öffne. Aber im Moment bei meinem Testen habe ich den Effekt, dass Firefox das Letsencrypt-Cert sieht, aber Chrome das CACert-Cert. Ich habe ehrlich gesagt keine Theorie, wieso das so sein könnte. Ich debugge mal weiter.
Update: Nach Shift-Reload zeigt auch Chrome das Letsencrypt-Cert an. Die werden doch nicht ernsthaft die Cert-Daten cachen!? Nee, so blöde kann keiner sein!
Update: Doch, so blöde können die sein.
Update: Et tu, Firefox?
Wer mir auf einen Rant, wie Scheiße der Python-Client von Letsencrypt ist, mit einem "aber es gibt doch andere Clients" oder "aber das ist doch eigentlich das Protokoll" antwortet, verplempert seine und meine Zeit.
Wenn ich über das Protokoll oder andere Clients reden wollte, dann hätte ich das getan.
Der Blogpost war über den Client, den diese Leute da verteilen. Niemand hat je in Zweifel gezogen, dass man den Client auch wegwerfen und das Protokoll reversen oder verstehen oder die Spec lesen und das nachimplementieren kann. Wir sind ja hier schließlich unter Unix und nicht hilflos.
Wenn ich hier Internet Explorer kritisiere, ist "aber das Protokoll ist doch offen, man kann einen anderen Browser schreiben" auch keine weiterhelfende Antwort. Und IE ist auch nicht weniger schlecht, weil es jetzt Chrome gibt.
Aber das Argument, das ich am wenigsten von allen leiden kann, ist "aber die Sourcen sind doch offen, das kannst du doch fixen". Ich will das mal an einer Analogie illustrieren.
"Hey, Fefe, das Trinkwasser ist giftig!" "Na und? Du kannst es doch filtern!"
Das ist Grundlage, dass die Quellen offen sind und man das reparieren kann. Das ist Voraussetzung dafür, dass ich mir das überhaupt angucke. Das ist kein Pro-Argument für irgendwas. Das ist kein Argument gegen Kritik daran, dass jemand gammeligen Gammelranz ausliefert. Und überhaupt: Wie viele von euch haben denn schon mal tatsächlich was bei einem Open Source-Projekt in den Quellen gefixt? I call bullshit.
Wenn du bei IKEA nen Möbel kaufst, und da fehlt ein Bein, dann würde ja auch niemand "man kann sich doch selber ein Ersatzteil zurechtsägen" bringen.
"Ja aber Fefe, das ist doch nur ne Beta!" Ja, und wofür ist eine Beta da? Damit man sich das angucken und Feedback geben kann. Das habe ich getan.
Man tut an die externe Referenz im HTML im Wesentlichen noch einen Hashwert über den Inhalt der externen Ressource dazu, und wenn da was mit anderem Hashwert kommt, wird es verworfen.
Damit das tatsächlich sicher ist, sollte man natürlich die Webseite dann auch per HTTPS ausliefern.
Update: Wobei, eigentlich ist das ja auch wieder bescheuert. Wenn man die Webseite per HTTPS ausliefert und Hashwerte für die externen Ressourcen mitliefert, dann gibt es keinen Grund mehr, die Javascript-Libraries von externen CDNs noch per HTTPS zu laden. Aber wenn man es nicht tut, wird der Browser rumheulen. Oder haben die das abgeschafft für Ressourcen mit Subresource Integrity? Denn das könnte Webserver massiv entlasten, wenn man für die ganzen verlinkten Unterressourcen nicht mehr https nehmen müsste, nur noch für die Hauptseite. Und dann warum bei Skripten aufhören, warum das nicht auch gleich für die Bilder und Multimedia-Inhalte machen?
So gesehen müssen wir Microsoft dankbar sein, dass sie das so auf die Agenda gesetzt haben — und dass ihre Datenschutzbedingungen so verständlich sind, dass Leute sie gelesen haben! Über Apples Kleingedrucktes werden Witzchen gerissen, bei Microsoft lesen die Leute das und verstehen danach, was da passiert. Und sind empört.
Ich freue mich da sehr drüber, dass die Leute jetzt aufwachen. Aber ich finde es sehr ungerecht, dass sich der Zorn gegen Microsoft richtet, die beim Datenmissbrauch geradezu der Nachzügler sind, Jahre später dran als die Konkurrenz!
Wieso ist Cortana auf dem Desktop plötzlich schlimmer als OK Google oder Siri?
Vielleicht sollte ich diesem geschenkten Gaul nicht zu tief ins Maul schauen und mich einfach freuen, dass endlich jemand Interesse am Datenschutz hat.
Aus Sicht von Microsoft, Google und Apple sind die Zeiten vorbei, in denen man ein Gerät einfach nur so am Internet betreiben kann, ohne dass es ständig nach Hause telefoniert. Und selbst Linux-Distributionen telefonieren ja heutzutage nach Hause, und sei es nur zum Nachgucken, ob es Updates gibt.
O tempora, o mores!
Ich für meinen Teil glaube nicht, dass Windows 10 so viel schlimmer ist als vorherige Windows-Versionen, mal abgesehen von Cortana natürlich, und dafür kann man Microsoft nur partiell die Schuld geben. Da sahe sie sich halt durch Siri und Google Now unter Zugzwang gesetzt. Wenn man Cortana und Wifi Sense ausmacht, dann bleiben hauptsächlich Dinge übrig, die schon bei Windows 8 und früher ein Problem waren, wie der ganze Browser-Kram, der während der URL-Eingabe de facto ein Keylogger ist. Aber das macht Chroma ja auch und warnt da weniger klar vor.
Ich finde diese Grafik vor allem deshalb wichtig, weil die meisten Dinge davon Apple-User z.B. schon die ganze Zeit betreffen, nur regt sich von denen keiner drüber auf, weil die alle nicht die mentale Kapazität haben, um das Problem zu erkennen, bzw. um das als Problem zu erkennen. Und Android natürlich genau so. Was war bei Chrome neulich die Hölle los, als die Leute merkten, dass Google da unter Linux Google Now implementiert hat. Und die Aufregung kam auch dort initial nicht von Privatsphäre-Seite sondern von religiösem Fundamentalismus, weil Debilianisten fanden, das sei ein binärer Blob und gehöre nicht in ihre Distribution. Als ob so eine Funktion irgendwie vertretbarer wäre, wenn der Quellcode für die Clientseite offen liegt!
Wir können hier gerade live und in Farbe beobachten, wie die Welt den Bach runter geht. Das ist wie mit der Umweltverschmutzung, Klimawandel und Massentierhaltung. Alle sehen es, alle wissen, dass es uns alle umbringen wird, aber keiner hält es auf.
ENDLICH sind wir weg von diesem Flash-Binärkack und von Binaries für irgendwelche speziellen Plattformen und haben Skriptsprachen für eine gemeinsame Plattform. Endlich kann man einfach Ctrl-U machen und sich angucken, was da passiert. Kaputte Skripte zur Not selber debuggen. Selbstgehackte DRM im Web ist endlich weg (abgesehen von diesem Chrome-Netflix-Zeugs).
Und was machen diese Schwachmaten da? Erfinden ein neues Binärformat fürs Web. Und sagen explizit an, dass das ein Compiler-Target sein soll. JA SUPER! Ich sage gleich mal an, dass es eine Industrie geben wird, die auf Basis davon DRM baut, die "Obfuscation"-Technologien verkaufen wird, und wir werden eine neue dunkle Ära für geschlossenes Web einleuten. Und das alles so völlig ohne Not! Und dann werden wir wieder "works best in Internet Explorer" haben. Eine Frage der Zeit, bis Microsoft oder Apple spezielle proprietäre APIs für ihre "Web-Binaries" exportieren. DirectX für WebAssembly! Und am Ende haben wir dann ein verkapptes .NET für Arme im Browser. Hint: Hatten wir schon. Hieß Silverlight. Ist gefloppt.
Ich habe ja mein SSH schon vor einer Weile auf djb-Krypto umgestellt (hier hatte ich das beschrieben). Es ist leider auffallend schwierig, mit regulären Browsern djb-Krypto im TLS hinzukriegen. Firefox supported das noch nicht (warum eigentlich nicht?), Chrome supported es angeblich, aber ich kriege das nicht negotiated. OpenSSL kann es nicht (es gibt einen alten Patch, der aber nicht auf aktuelle Versionen passt), PolarSSL kann es nicht, BoringSSL kann es zwar, aber die Knalltüten haben das Buildsystem auf cmake umgestellt, und da krieg ich die dietlibc nicht reingepfriemelt. Das muss mir auch noch mal jemand erklären, wieso heutzutage jedes gammelige Hipsterprojekt sein eigenes Buildsystem braucht. Bei autoconf ist wenigstens dokumentiert, wie man da von außen eingreifen kann. Aber dieses cmake ist in der Beziehung nur für den Arsch, ich komm aus dem Fluchen gar nicht raus.
Und so bleibt mir im Moment nur LibreSSL, das kommt in der portablen Version mit autoconf und funktioniert mit dietlibc, und da taucht das auch in der Cipherliste auf, und wenn ich mit openssl s_client die Verbindung aufmache, kriege ich auch ECDHE-ECDSA-CHACHA20-POLY1305, aber mit Chrome? Kein Glück.
Und, mal unter uns, solange man da nicht von Hand noch eine ordentliche Kurve konfiguriert, ist das auch Mist. Von den Kurven, die OpenSSL unterstützt, scheint nur secp256k1 akzeptabel.
This configuration very quickly yielded a fair number of additional, unique fault conditions, ranging from NULL pointer dereferences, to memory fenceposts visible only under ASAN or Valgrind, to pretty straightforward uses of uninitialized pointers (link), bogus calls to free() (link), heap buffer overflows (link), and even stack-based ones (link).Das ist ziemlich krass schlimm, denn sqlite wird von echt viel Software verwendet, u.a. Firefox und Chrome. Das wäre richtig unangenehm, wenn eine SQL Injection-Lücke einen Stack Overflow im SQL-Backend auslöst und man so das System übernehmen kann.Übrigens:
PS. I was truly impressed with Richard Hipp fixing each and every of these cases within a couple of hours of sending in a report. The fixes have been incorporated in version 3.8.9 of SQLite and have been public for a whileDaran erkennt man gute Software. So und jetzt entschuldigt mich kurz, ich muss mal ein paar Softwarepakete upgraden.Update: Übrigens, wer seinen Firefox neu baut: --enable-system-sqlite. Sonst nimmt Firefox seine eigene mitgelieferte alte Version und ist immer noch verwundbar. JA SUPER, liebe Firefox-Leute!1!!
Update: Öhm, ich habe gerade mit --enable-system-sqlite kompiliert, und da liegt am Ende immer noch ein libmozsqlite3.so herum mit einer älteren Version. WTF?!
Bonus: Es hat mit out-of-band TCP data zu tun. Damit haben wir schon in den 80ern Netzwerkdienste abgeschossen *schwelg*
Oh und es wird noch besser:
Impact: A local application may escalate privileges using a compromised service intended to run with reduced privileges.Description: setreuid and setregid system calls failed to drop privileges permanently. This issue was addressed by correctly dropping privileges.
Apple, fuck yeah!
MCS Holdings hat dann mit dem Zertifikat ein paar gültige Zertifikate für ein paar Google-Domains erstellt. Das ist aufgeflogen, weil Chrome und Firefox inzwischen Certificate Pinning betreiben, d.h. die haben hart einprogrammiert: Wenn für diese Domain (die Liste umfasst eine handvoll "wichtige Domains" wie halt u.a. die von Google) irgendwo ein falsches Zertifikat auftaucht, dann telefonieren die nach Hause und petzen. Und so konnte Google das sehen und hat dann CNNIC zur Rede gestellt. Und die haben gesagt:
they had contracted with MCS Holdings on the basis that MCS would only issue certificates for domains that they had registered.Klar haben wir diesem Kind eine geladene Schusswaffe verkauft, Euer Ehren! Aber wir haben ihm ganz deutlich gesagt, dass es damit keinen Scheiß machen darf!1!!Diese Art von Versagen ist übrigens kein Alleinstellungsmerkmal der Chinesen.
Auf der einen Seite ist es natürlich schön, dass sowas heutzutage auffliegt. Certificate Pinning ist keine doofe Idee. Microsoft macht das auch, und die eine oder andere ranzige App tut das inzwischen auch. Damit hat so eine App dann einen handfesten Vorteil gegenüber dem Webbrowser, außer es handelt sich um eine Google-Domain oder so.
Aber, der Punkt, über den ihr an der Stelle mal nachdenken solltet: Was ist denn, wenn CNNIC/MCS nicht für eine Google-Domain so ein Zertifikat ausgestellt hätte, sondern für banking.postbank.de oder so? Das würde doch keine Sau merken! Euer Browser würde jedenfalls nicht meckern. Dabei wäre das eigentlich kein Ding, allgemeines Certificate Pinning zu implementieren. Ich hab sowas 2009 schon mal vorgeschlagen. Aber auf mich hört ja immer keiner, und dann sind danach alle ganz furchtbar betroffen, wie es soweit kommen konnte. Wobei, es gibt inzwischen Browser-Addons, die sowas machen (googelt mal Certificate Patrol). Immerhin. Aber eigentlich will man das im Browser selbst implementiert haben, finde ich.
Update: Es gibt da übrigens ein allgemeines Certificate Pinning, aber da muss die Webseite aktiv mitmachen und (in meinen Augen sinnlos) redundante Informationen im HTTP-Header übertragen.
Secure Connection Failed.An error occurred during a connection to blog.fefe.de. SSL received a record that exceeded the maximum permissible length. (Error code: ssl_error_rx_record_too_long)
Mein Blog hat ja schon seit einer Weile SSLv3 deaktiviert, aber jetzt hatte ich auch openssl ohne SSLv3-Support gebaut. Vielleicht ist es das. Mann ist das immer eine Freude mit diesen ganzen Hochtechnologien!Update: Ich habe die Gelegenheit genutzt, mal den PolarSSL-Support in gatling zu updaten. Mal gucken, ob das jetzt stabil läuft hier.
drwx------ root/root 0 2014-10-02 02:53:49 ./ drwxr-xr-x root/root 0 2014-10-02 02:53:49 ./usr/ drwxr-xr-x root/root 0 2014-10-02 02:53:49 ./usr/share/ drwxr-xr-x root/root 0 2014-10-02 02:53:49 ./usr/share/man/ drwxr-xr-x root/root 0 2014-10-02 02:54:04 ./usr/share/man/man1/ -rwxr-xr-x root/root 4840 2014-10-02 02:54:04 ./usr/share/man/man1/google-chrome-unstable.1u.s.w.
Fälle jemandem was auf? Wenn man das in / auspackt, dann ist danach / nur noch für root les- und ausführbar.
Einmal mit Profis arbeiten!
Das ist das hier:
-rw-r--r-- 1 leitner users 47942700 Oct 3 03:24 google-chrome-unstable_current_amd64.deb
Update: Und um die Apokalypse perfekt zu machen, gab es auch in der von Chrome und Firefox verwendeten SSL-Library einen RSA-Signatur-Bypass. Ja super! Sonst noch was?
Update: Ah, Busybox ist doch nicht betroffen, höre ich gerade, sondern nur Geräte mit Cyanogenmod, die bash statt der Shell von Busybox nehmen.
Update: Es gibt schon die erste Malware damit.
Update: Mein Freund Andreas hat mal einen Patch gemacht, der das ganze kaputte Feature wegoperiert. Wer will schon Shell-Funktionen im Environment haben!? Das ist relativ zu bash-4.3.24 (nicht .25).
Update: Das scheint neu in der Beta-Version zu sein.
Die Idee ist, dass ein Prozess Seccomp anschalten kann, das ist dann auch nicht revidierbar, und ab dann kann er nur noch read, write, exit und sigreturn machen, und read und write geht auch nur auf vorher schon geöffnete Deskriptoren. An sich keine doofe Idee, mal abgesehen von dem Verkaufen-Aspekt, aber hat sich m.W. nie in der Realität für irgendwas durchsetzen können. Es war doch ein bisschen zu restriktiv. Das Original-Seccomp war von 2005.
Und wo wir gerade bei Geschichtsstündchen sind, erzähle ich euch auch mal was von BPF, dem Berkeley Packet Filter. Wenn man unter Unix Netzwerktraffic sniffen will, nimmt man im Allgemeinen libpcap, die das schön abstrahiert. Die kann auch filtern. Man kennt die Syntax von tcpdump:
# tcpdump -s0 host 10.0.0.1 and tcp and not port 22Wenn man so einen Filter hat, dann will man ja nicht, dass der Kernel einem alle Pakete gibt und man selber filtert, sondern man will dem Kernel das mitteilen und der gibt einem dann nur die passenden Pakete raus. Der Mechanismus dafür heißt BPF und ist aus Programmsicht ein Array mit Bytecode-Instruktionen drin. Die haben alle eine fixe Länge, insofern eher RISC als Bytecode, aber der "Instruktionssatz" ist wunderschön archaisch. Da gibt es zwei Register, den Akkumulator und das Index-Register. Es gibt Load und Store, ALU-Operationen und Vergleiche mit Sprüngen. Ganz krude Geschichte. Hier ist mal ein Stück Beispielcode:
struct bpf_insn BPFAcceptIPSource[] = {
// Check Ethernet Protocol Word At Offset 12
BPF_STMT(BPF_LD+BPF_H+BPF_ABS, 12),
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, ETHERTYPE_IP, 0, 3), // Check Source IP address At Offset 26
BPF_STMT(BPF_LD+BPF_W+BPF_ABS, 26),
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, 0x01020304, 0, 1),//Source == 1.2.3.4
BPF_STMT(BPF_RET+BPF_K, (UINT)-1), // Accept.
BPF_STMT(BPF_RET+BPF_K, 0 )
};
Wer da keine feuchten Finger kriegt, ist kein echter Hacker! Und ich meine jetzt nicht nur wegen des Endianness-Problems. :-)Jedenfalls, wieso ich das erwähne: Eines Tages hat sich ein Schlaufuchs überlegt, hey, wir haben seccomp im Kernel, und wir haben BPF im Kernel, wir könnten doch einfach BPF statt auf ein Netzwerkpaket auf eine wohldefinierte Struct loslassen, wo die Syscall-Daten drinstehen, und dann kann sich der Userspace seine Regeln selbst definieren, welche Syscalls erlaubt sein sollen und welche nicht. Und genau das gibt es jetzt seit ein paar Jahren (?), und es heißt "Seccomp Filter" oder "Seccomp Mode 2".
Ich blogge das hier, weil ich sowas seit vielen Jahren haben will. Die Leute dahinter sind von Google und arbeiten an Chrome OS. Mir ist das überhaupt nur aufgefallen, dass es das jetzt gibt, weil aktuelle Versionen von Portable OpenSSH das als Sandboxing-Mechanismus benutzen — sehr cool!
Heute ergab sich erstmals für mich eine schöne Gelegenheit, das selber mal einzusetzen. Ich arbeite gerade in einem Kundenprojekt an Monitoring. Eines der in dem Projekt entstandenen Tools macht grob das selbe wie "vmstat 1", aber gibt das Ergebnis als CGI als text/event-stream aus, und auf der anderen Seite sitzt dann eine Webseite mit ein bisschen Javascript, das aus den Events SVG-Visualisierungen erzeugt. Dieses vmstat-CGI-Tool ist ein perfekter Kandidat für Seccomp-Filter, fand ich. Es öffnet turnusmäßig ein paar Dateien unter /proc und /sys, macht ein bisschen malloc, ein bisschen gettimeofday, und ruft dann write auf, um die Daten rauszuschreiben. Syscalls wie fork, execve, socket, kill oder connect muss der nie aufrufen. Also sage ich dem Kernel: Wenn dieser Prozess das doch tut, dann kille ihn sofort.
Als ich darauf per Seccomp-Filter eine Selbstbeschränkung programmiert habe, fiel mir auf, dass die bisherigen Codestücke nur auf die Syscallnummer gucken, weil das alles war, was die Chrome-OS-Leute in die Dokumentation getan haben. Aber die Struct beinhaltet auch die Syscall-Argumente. Das ist nur für den Fall nützlich, wo das keine Pointer auf Strings sind, denn denen kann man nicht hinterherlaufen aus dem BPF-Code heraus, aber man kann z.B. sowas machen wie: open() geht nur mit O_RDONLY. Dafür habe ich keinen Code gefunden, daher habe ich ihn selber geschrieben, und dachte mir, das tu ich mal in mein Blog, damit es andere Leute finden können, die möglicherweise auch mal in dieses Problem laufen. Die grobe Codestruktur von so einem Seccomp-Filter-Programm ist:
Hier ist mein Code für open():
/* we need a special case for open.
* we want open to succeed, but only if it's O_RDONLY */
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, __NR_open, 0, 4),
/* it's open(2). Load second argument into accumulator (first
* argument is filename, second is mode). We want to check if mode
* is O_RDONLY and only allow the syscall through if it is. */
BPF_STMT(BPF_LD+BPF_W+BPF_ABS, offsetof(struct seccomp_data, args[1])),
/* if it's O_RDONLY, skip 1 instruction */
/* slight complication: on 32-bit platforms we also pass O_LARGEFILE */
#if __WORDSIZE == 64
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, O_RDONLY, 1, 0),
#else
BPF_JUMP(BPF_JMP+BPF_JEQ+BPF_K, O_RDONLY|O_LARGEFILE, 1, 0),
#endif
/* "return SECCOMP_RET_KILL", tell seccomp to kill the process */
BPF_STMT(BPF_RET+BPF_K, SECCOMP_RET_KILL),
/* "return SECCOMP_RET_ALLOW", tell seccomp to allow the syscall */
BPF_STMT(BPF_RET+BPF_K, SECCOMP_RET_ALLOW),
Möge er von Hackern gefunden werden, die dieses Problem lösen möchten :-)
Diesmal im Futex-Syscall. Das sind die Art Bugs, mit denen man aus einer Sandbox ausbricht. Z.B. der von Chrome.
Ich an Microsofts Stelle hätte da sofort gefixt, denn so sieht es nach "die NSA hat um noch ein paar Wochen Zeit gebeten" aus.
Ich persönlich halte DSA in allen Ausprägungen inzwischen für eine NSA-Hintertür und rate von der Verwendung ab. Der Grund ist, dass DSA so ausgelegt ist, dass man einen Zufallswert nimmt pro Operation mit dem geheimen Schlüssel, und wenn man zweimal den gleichen verwendet, dann fällt auf der anderen Seite der geheime Schlüssel aus einer vergleichsweise einfachen arithmetischen Umformung heraus. Das ist offensichtlich völlig unakzeptabel. Wie DSA überhaupt jemals soweit kommen konnte, dass es ein internationaler Standard wurde, erläutert djb in seinem Blog.
Kommen wir zu GCM. GCM ist der Galois Counter Mode. TLS hat einen Geburtsfehler, der seit vielen Jahren bekannt ist, und uns in letzter Zeit vermehrt auf den Fuß fällt. Nehmen wir mal an, Alice schickt Bob eine verschlüsselte Nachricht. Dann will man nicht nur, dass die Nachricht nicht von jemandem auf dem Weg gelesen werden kann, sondern auch, dass sie nicht verändert werden kann. Deshalb machen Protokolle wie TLS immer zwei Schritte: Verschlüsseln und eine Integritätssicherstellung. Dafür verwendet man sogenannte Message Authentication Codes, oder MAC. Dafür verwendet man häufig eine kryptographische Hash-Funktion mit einem beiden Seiten bekannten Geheimnis, aber man kann sowas auch anders konstruieren.
So, wenn man verschlüsseln will, verschlüsselt man dann erst und macht dann den MAC? Oder macht man erst den MAC und dann verschlüsselt man? Das war lange Jahre nicht so klar, ob das eine oder das andere besser ist. TLS macht erst MAC und verschlüsselt dann. Das hat über die Jahre zu einem Haufen an Bugs und Problemen geführt, so dass heute klar ist, dass man das besser anders herum machen sollte. Die IETF-Arbeitsgruppe zu TLS weiß das seit vielen Jahren, aber (u.a. durch Sandsack- und Betoniertätigkeiten der NSA) konnte sie sich noch nicht durchringen, da was zu tun. Das ist eine Schande für alle Beteiligten und sollte zu einem fetten Arschtritt für die NSA-Abgesandten führen — tat es aber bisher nicht.
Warum erzähle ich das alles? Weil jemand auf die Idee kam, "aus Performance-Gründen" Verschlüsselung und Authentication in einem zu machen, und zwar mit einem Verfahren namens Galois Counter Mode. Ein Mode ist eine Art, wie man einen Block Cipher wie AES aufruft. Das heißt Block Cipher, weil es nicht auf einem Bytestrom arbeitet, sondern auf Blöcken von Daten. Wenn die Daten keinen ganzen Block füllen, muss man am Ende mit sogenanntem "Padding" auffüllen. Da gab es schon Stress in TLS. Man kann jeden Block mit dem selben Schlüssel verschlüsseln ("ECB"), aber das ist eine ganz schlechte Idee. Wikipedia hat eine schöne Visualisierung anhand eines Pinguin-Bildes. Welchen Modus man benutzt ist also wichtig. ECB ist offensichtlich doof, daher haben wir halt alle immer CBC genommen. Das flog uns dann mit BEAST um die Ohren.
Übrig blieben Cipher-Suites auf Basis von RC4 (von dem wir inzwischen wissen, dass die NSA es in Echtzeit entschlüsseln kann) und GCM.
Warum ich das jetzt hier alles ausführe: GCM ist auch Scheiße. Das Paper dazu kommt von Niels Ferguson. Es sei noch angemerkt, dass man GCM in Software schon mal gleich so gut wie gar nicht ohne Timing-Probleme implementieren kann. Intel hat in ihren neueren CPUs Hardware-Support für GCM eingebaut, damit geht das dann. Aber fühlt sich damit jemand wohl?
Was können wir denn jetzt überhaupt noch tun? Wir können entweder warten, bis die TLS Working Group mal ihren Arsch hochkriegt und den offensichtlich notwendigen Schritt geht. Es gibt da Bemühungen, aber das kann sich noch um Jahre handeln. Die Situation ist gänzlich unakzeptabel.
Bleibt die Einsicht, dass uns gerade nur djb-Krypto überhaupt noch realistisch retten kann. djb hat als Konkurrenz zu ECDSA ein Verfahren namens ed25519 gemacht, das könnte den public key Teil abdecken. ed25519 wird u.a. in der neuesten Version von openssh unterstützt. Und als Ersatz für AES mit irgendwelchen grottigen Modi könnte man ChaCha20 einbauen. Das ist in Chrome schon eingebaut, aber hat es m.W. in noch keine einzige öffentlich verfügbare TLS-Library geschafft. Es ist alles zum Heulen.
Ich habe ja jahrelang nicht verstanden, wieso djb nie versucht hat, TLS zu fixen. Ich glaube, so langsam kann ich es nachvollziehen.
Update: CBC ist nicht an sich unsicher, sondern wie TLS 1.0 es angewendet hat. Ein Upgrade auf TLS 1.2 galt damals noch als unrealistisch, inzwischen ist es weitgehend vollzogen.
In short, it doesn't work and you are no more secure by switching it on.Und falls das jemand nicht auf dem Radar hatte: Er hat natürlich völlig Recht. Deshalb ist Revocation Checking bei Chrome per Default ausgeschaltet.
Völlig klar! Da hilft nur eins: Mehr Virtualisierung. Und ab in die Cloud mit den Daten. Virenscanner dranpappen. "Verschlüsselung" ausrollen.
Alternativ ein Zertifikat vom TÜV SÜD kaufen.
Oder wir hören einfach mal mit diesem ganzen Security-Bullshit-Theater auf. Das funktioniert schon an Flughäfen nicht.
Oh, was sagt ihr? Der ganze Chrome stürzt ab, nicht nur das eine Tab? Tja, äh, … hätte uns doch nur mal jemand gewarnt, dass Sandboxing Schlangenöl ist! Da hilft nur Virtualisierung!1!! (via) (Danke, Stefan)
Die Sicherheit ihres Rechners wird durch ein Firefox Add-on eingeschränkt. [Sicherheit wieder herstellen]Wenn man da drauf klickt, kommt man bei browsersicherheit.info raus, das ähnlich wie gelbe Balken eben auch nach dem Rezeptbuch der Malware-Mafia so designed wurde, dass es optisch wie die Chrome-Einstellungen aussieht. Dort wird dem Leser dann suggeriert, er habe sich ein Malware-Addon eingefangen und müsse das dringend wegmachen.
Sowas kennt man sonst nur von Botnet-Betreibern und Schlangenöl-Resellern. Ihr wisst schon, diese Scareware-Popup-Leute. "YOUR PC IS INFECTED!"
Lustigerweise haben sie dann da eine Liste von gefährlichen Addons, die man dringend mal deinstallieren sollte. Die Hälfte davon sind Adblocker.
Wow, GMX. Ernsthaft? Ihr spielt jetzt auf dem Niveau und mit den Methoden von Malware-Verbreitern? Na dann wundert euch aber auch nicht, wenn euch eure Kunden in Scharen weglaufen.
Update: Das selbe in Grün bei web.de, ist glaube ich auch die selbe Firma. (Danke, Andreas)
Sehr beachtlich ist auch die Fülle an Euphemismen und Weasel Words, mit dem sie zu vermeiden suchen, das Werbung-Einblenden als Werbung-Einblenden zu bezeichnen. Die erste Hälfte des Artikels ist reines Abwehr-Füllwort-Bingo, damit keiner bis zu der Stelle durchhält, wo dann die Werbung erwähnt wird.
Ich prüfe da nicht viel, im Wesentlichen will ich, dass das Opcode-Byte sagt, dass es ein Handshake ist, und dass die TLS-Version gültig aussieht, und dass die Länge des Handshake-Paketes nicht größer als 256 ist. Warum 256? Weil das nach damaligen Verhältnissen exorbitant viel war und weil 256 in Binärdarstellung ein 1-Byte in der höherrangigen Hälfte des Längenfeldes war, was sich dann leicht testen ließ.
Was jetzt passiert ist, ist dass Chrome so viel Bloat mitschickt, dass bei denen 0x200 als Länge im Header steht, also 512. Wir erinnern uns: Chrome, das waren die Leute, die wegen des angeblichen HTTP-Header-Bloats ein eigenes Konkurrenzprotokoll namens SPDY erfunden haben, das so super toll optimiert ist, dass für die zwei e kein Platz mehr im Namen war. DIE Leute haben jetzt ihr SSL-Handshake soweit aufgebläht, dass es in meinen Sanity-Check rannte.
SPDY basiert übrigens auch auf SSL.
Einmal mit Profis arbeiten!
Update: Vier der Extensions sind so neu (oder Google-proprietär?), dass Wireshark sie noch nicht kennt.
Update: Es gibt eine Erklärung, wieso der SSL-Header so groß ist. Das ist kein Bloat, sondern die machen das absichtlich, um um eine ranzige F5-Firmware herumzuarbeiten. m(
Inhaltlich geht es natürlich um die NSA, aber wir haben uns gedacht, wir sollten da nicht bloß "HAHA HABEN WIR JA GLEICH GESAGT" bringen, sondern die Gelegenheit für einen Überblick über die Geschichte von Abhören und Verschlüsselung und Brechen von Verschlüsselung nutzen.
Übrigens hat Chrome in der Zwischenzeit Support für Opus eingebaut, aber es ist nicht standardmäßig aktiviert. Öffnet mal ein Tab mit "about:flags" und sucht da nach Opus. Wenn ihr das anschaltet, reduziert sich die Downloadgröße deutlich.
Die Sendung ist mit fast drei Stunden recht lang geworden. Wir fanden, dass wir nach der langen Pause lieber eine etwas längere Sendung machen sollten als eine normal lange. Es gibt ja auch viel zu sagen zu dem Thema.
Viel Spaß beim Anhören!
Update: Man kann das Apps-Dingens doch abschalten. Rechtsklick, dann ganz unten ein Häkchen wegmachen. Ändert nichts an der Aussage, dass ich mir nicht von anderen Leuten Bookmarks setzen lasse.
Die schlechte: RSA BSAFE benutzt das als Default-RNG. Und nicht nur die, NIST hat eine Liste. Cisco, Apple, Juniper, McAfee, Blackberry, … bei den meisten wird das allerdings nicht Default sein.
Die gute Nachricht: BSAFE wird von keiner freien Software eingesetzt. Wenn ihr also Firefox unter Linux einsetzt, seid ihr sicher.
Ich bin mir gerade nicht sicher, wie das unter Windows ist. Da gibt es ein TLS vom System namens "SChannel". Das wird meines Wissens u.a. von IE und Chrome verwendet. Benutzt der BSAFE? Vermutlich. Es gab mal eine Zeit, da konnte man RSA und co gar nicht ohne BSAFE legal einsetzen in den USA, aus Patentgründen. Das müsste mal jemand herausfinden, wie das ist, und ob Windows den NSA-RNG einsetzt.
OpenSSL ist auch auf der Liste, aber die haben schon angesagt, dass sie das nur implementiert haben, weil ihnen jemand dafür Geld gegeben hat, und das ist nur an, wenn man den FIPS-Modus aktiviert, von dem sie im Übrigen dringend abraten und was nicht der Default ist.
Ich habe also ein paar Abhilfen implementiert, um das zu beschleunigen. Die selben Dinge, die ich auch im Blog implementiert habe, im Wesentlichen. Ich sende einen Date-Header, einen Last-Modified-Header, und beantworte If-Modified-Since-Header. Chrome war unbeeindruckt. Ich habe dann zum Testen einen Expires-Header in der Zukunft eingefügt, und das hat auch nichts gebracht. Jetzt glaube ich, die Erklärung gefunden zu haben: Chrome cached keine Seiten über SSL mit "ungültigem" Zertifikat. Dazu gehören alle Zertifikate, bei denen die rote Warnseite kommt, die man wegklicken muss. Aber selbst wenn man die wegklickt, schmeißt Chrome alle Daten nach dem Anzeigen weg und cached nichts, auch nicht temporär nur im RAM.
Wenn also einer von euch bei meinem Blog aus Faulheit (nicht aus anderen, möglicherweise validen Gründen) das Root-Zertifikat von cacert.org nicht importiert hat, und stattdessen immer die rote Warnseite wegklickt, dann erzeugt das bei meinem Blog unnötigen Traffic. Ich bitte diejenigen, lieber das Root-Cert zu importieren. Und wenn einer von euch bei Chrome mitarbeitet, fände ich es prima, wenn ihr da mal Stunk machen könntet. Das Verhalten ist nicht akzeptabel. Das nicht auf Platte zu speichern ist OK, aber das nicht mal in der History im RAM zu halten ist in meinen Augen nicht zu verteidigen.
Was für eine grandiose Idee. Full Circle.
Der Lacher ist ja, dass die Leute alle lieber mit ihren Mobilgeräten webklicken gerade, weil man da nicht dauernd mit Werbung penetriert wird. Auf den Desktop-Sites wird man ja nur noch mit Interstitionals und Javascript-Popups mit Newsletter-Abo- und Facebook-Like und Paywall-Spenden-Aufforderungen bombardiert. Klar hat da keiner Bock drauf, daher klicken die alle mobil. Und dann wundern sich die Sites, dass immer mehr Leute mobil klicken!1!!
Und jetzt klicken die Leute halt auch auf ihrem Desktop "mobil". Und die ganzen ranzigen Webseiten werden reagieren, indem sie auch die Mobilversionen unbenutzbar machen. Und dann werden sie sich alle wundern, wieso jetzt gar keiner mehr bei ihnen klickt.
Und lustigerweise sind die alle selber Schuld. Früher gab es ein Banner oben. Das war es. Ein Banner. Das hat die ganze Site finanziert. Aber die mussten ja alle gierig werden und noch ein Skyscraper-Banner an die Seite machen, und noch eines in die Mitte, und ihre Artikel auf 15 Seiten aufteilen, damit überall noch mehr Werbung hingetan werden kann, und dann noch an die andere Seite eine Werbung, dann noch unten eine Werbung drunter, dann noch ein Interstitional davor — natürlich zahlt dann kein Werbetreibender mehr den vollen Preis pro Banner. Das ist ja völlig lächerlich. Die haben sich selbst den Werbemarkt kaputtgemacht mit ihrer Gier. Und ihre Leser vergrault oder in die Arme von Adblockern getrieben. Aber das ist ja ein Kampf, bei dem es auf Dauer nur Verlierer gibt. Ich glaube ja, wenn die die Anzahl der Werbebanner auf 1-2 reduzieren, die ganze überflüssige Navigationsscheiße wegmachen, und den Social Networking Bullshit rausnehmen würden, dann würden die Leute wieder gerne auch auf dem Desktop klicken, und sie würden pro Werbebanner auch wieder richtige Preise nehmen können.
Blink, falls es jemand noch nicht gehört hat, ist der Name für Googles neuen Webkit-Fork. Wer sich gefragt hat, wieso man Webkit forken wollen würde, wenn man eh schon der dominierende Kontributor und Nutzer ist, dem sei obiger Link empfohlen, der das aufklärt. (Danke, Ralph)
Meine Theorie ist, dass das der Versuch ist, den Leuten Google+ überzuhelfen.
Meine Nummer 1 Anwendung von Chrome ist, dass ich in einem xterm ne URL habe, die markiere, und das dann mit der mittleren Maustaste in Chrome paste.
Geht nicht mehr.
Weil irgendein elender Marodeur entschieden hat, dass Chrome nur noch Paste ala Ctrl-V entgegennimmt, und die mittlere Maustaste nicht wie in allen anderen X-Anwendungen pasten soll, sondern als hätte man Ctrl-V getippt.
Und puff, weg mit Chrome. Zurück zu Firefox. Nervig genug, dass sie nie URL-Paste mit dem mittleren Mausknopf in dem HTML-Bereich implementiert haben.
Update: Die letzte Zeile bezog sich auf Chrome, nicht Firefox. Lest doch mal ordentlich vor den Mailen bitte!
Und die Terminologie ist da bei X krude. Middlere Maustaste benutzt nicht Cut&Paste sondern der Mechanismus heißt "Selection". Das unterstützt Chrome jetzt nicht mehr.
Update: Aha, geht doch in Chrome, aber man muss mit der mittleren Maustaste auf das favicon klicken. Wissenschon, das winzige Icon. Ein Hoch auf offensichtliche Benutzerführung. Dann wird die URL auch direkt geladen. Wer (wie ich) URLs häufig umgebrochen kriegt in Mails und in Teilen pasten wollte, hat bei Chrome verloren. Ich bleibe bei der Rückmigration zu Firefox.
Update: Wo ich gerade beim über Chrome ranten war: die haben Pasten auch in die Gegenrichtung kaputtgemacht. Im Chrome was markieren, im xterm daneben pasten — kommt als UTF8 an, egal ob das xterm im UTF8-Modus ist oder (wie bei mir gerne mal) nicht. So kamen in letzter Zeit diverse kaputte Umlaute im Blog zustande. Chrome war Schuld. Früher ging das mal.
Update: Das Chrome-Update von heute kann auch wieder Mittelklick im URL-Balken.
Aber das ist noch nicht der Hammer an der Meldung. Der Hammer ist, dass Google innerhalb von 10 Stunden (!) eine gefixte Version von Chrome in ihrem Autoupdater verfügbar hatte.
Zum Vergleich: Oracle sitzt schon mal Jahre auf Sicherheitslücken, Apple, Microsoft und Adobe Monate. Da kann sich der Rest der Industrie mal eine Scheibe von abschneiden.
In the case of Pinkie Pie’s exploit, it took a chain of six different bugs in order to successfully break out of the Chrome sandbox.Wer sich jetzt denkt, hey, 6 Bugs in Reihe exploiten, das ist bestimmt eher die Ausnahme:In an upcoming post, we’ll explain the details of Sergey Glazunov’s exploit, which relied on roughly 10 distinct bugs.OMGWTF :-)
Daher sage ich mal voraus: ein paar Geeks werden daran arbeiten, das so zu machen. Im Großen und Ganzen ist das bloß ein weiteres Argument für HTML5 und gegen Flash. Flash ist ja eh am Sterben. Good Riddance.
Haben sie am Ende doch gemacht. Jetzt kommen dazu spannende Details heraus, und zwar soll Microsoft ein Gegenangebot gemacht haben an Mozilla, damit die Bing als Default-Suchmaschine einbauen, und das soll so hoch gewesen sein, dass Google jetzt dreimal so viel an Mozilla zahlt wie letztes Mal. Bwahahaha, also Wirtschaftskrieg will man gegen Microsoft echt nicht führen müssen, die wissen schon was sie da tun.
Theorien und Vorschläge nehme ich gerne per Email entgegen. Im Moment tendiere ich zu "die haben ihre LI-Software von Digitask gekauft und die spackt jetzt halt herum" :-)
Update: Bei diversen Leuten geht es offenbar problemlos.
Update: Es gibt einen Schuldigen. CACert hat offensichtlich gerade einen OCSP-Fuckup. Wenn Firefox bei denen eine OCSP-Anfrage für mein Cert stellt, kriegt er ein "403 Access Forbidden" zurück. Mit anderen Worten: Chrome macht kein OCSP. m( Man kann OCSP auch in Firefox ausschalten (security.OCSP.enabled = 0), aber an sich will man ja OCSP haben. Dieses SSL ist echt ein Haufen Sondermüll. Macht Firefox bei jedem Zugriff einen OCSP-Request oder nur einmal pro Tag? Man fragt ja ein spezifisches Zertifikat an, das hieße ja, dass CAcert ein Bewegungsprofil erstellen kann. Mann ist das alles für den Fuß.
Update: Mir mailt gerade jemand: Firefox prüft einmal pro Session, und Chrome macht doch OCSP aber macht daraus keinen Timeout sondern zeigt dann ein kleines gelbes Dreieck als Warnung an.
Zu "der WebGL-Lücke" habe ich nichts gesagt, weil das keine Lücke ist, sondern eine Idee der Größenordnung "lasst uns im Winter Russland angreifen". Ich versuche das mal kurz zu erklären. Prozessoren haben heutzutage eine MMU drin. Die MMU erlaubt es, Speicherschutz zu implementieren. Das Betriebssystem kann damit z.B. verhindern, dass irgendwelche Prozesse Speicherbereiche anderer Prozesse oder des Betriebssystems selber kaputtmachen.
Hardware hat sowas nicht. Insbesondere haben Grafikkarten sowas nicht. Früher war das nicht so schlimm, weil auf der Grafikkarte kein Code lief, also jedenfalls kein hochgeladener Code, sondern man konnte halt aus ein paar Operationen auswählen, die dann auf der Grafikkarte ausgeführt werden. Heute haben Grafikkarten eigene Programme, die Shader. Die können u.a. auf den Hauptspeicher des PCs zugreifen. Lesend und schreibend.
Mit anderen Worten: wer Shader auf die Grafikkarte hochladen kann, hat Schreibzugriff auf das Betriebssystem.
Das hat sich noch nicht weit genug herumgesprochen, dass die Malware-Toolkits das regulär benutzen. Aber alle, die sich mit der Technologie mal beschäftigt haben, wissen das. Grafikkarten sind da nicht alleine. Jede Hardware am PCI-Bus kann das. Und PC-Card und ExpressCard sind im Wesentlichen auch nur herausgeführte PCI-Busse. Wer also ein Notebook mit solchen Slots hat, der gibt jedem mit physischem Zugriff auf das Gerät auch softwaretechnisch Vollzugriff auf das Gerät, und zwar ohne dass derjenige rumschrauben müsste.
Und dann gibt es natürlich noch schlechte Ideen wie Firewire, was kein PCI-Bus ist, aber wo man über den Stecker trotzdem Schreibzugriff auf den Hauptspeicher im Rechner hat. Das selbe in Grün. Es sah ja eine Weile so aus, als hätte man aus dem Firewire-Debakel gelernt, aber nein, Intels neueste Technologie, Thunderbolt, führt gleich einen ganzen PCI-Express-Bus per Stecker raus aus dem Gehäuse. SUPER!
Aber zurück zu den Grafikkarten. Wenn man das einmal verstanden hat, dass Shader-Zugriff auf Grafikkarten sicherheitstechnisch Game Over ist, verstehen man auch plötzlich diverse andere Dinge als die schlechte Idee, die sie sind. Z.B. … in "virtuellen Maschinen" 3d-Grafik zu machen. Oder … 3d-Grafik über Netz forwarden! Game Over.
Es gibt eine Hoffnung im dem ganzen Jammertal. IOMMU. IOMMU ist eine MMU für I/O-Zugriffe. Damit könnte man also z.B. einschränken, welche Speicherbereiche die Grafikkarte überhaupt sehen kann. AMD hat sowas schon länger, Intel hat kürzlich nachgelegt. Leider … gibt es da auch schon Angriffe drauf.
Solange es hier keine funktionierende und erprobte Schutz-Technologie gibt, muss man alle 3d-Software (und natürlich erst Recht OpenCL/Cuda/Stream-Kram) so betrachten, als habe man ihr gerade Vollzugriff auf das System erteilt. Denn im Wesentlichen hat man das.
Vielleicht versteht jetzt der eine oder andere, wieso man keinesfalls irgendwelchen Webseiten Shader-Zugriff auf seine Grafikhardware geben will.
Update: Hier kommen gerade ein paar Mails von Leuten rein, die es besser/genauer wissen als ich. Die beiden Haupteinwände sind: a) man kann per WebGL nur GLSL hochladen, nicht binäre Shader, und b) die Grafikkarte kann nicht auf den kompletten Speicher im PC zugreifen, sondern nur auf die Bereiche, die der Treiber eingestellt hat. Soweit ich weiß ist das generell beides richtig.
Allerdings sind ja die Treiber nicht Open Source (Ausnahmen bestätigen die Regel; Benutzer der Open Source GL-Treiber unter Linux können hier möglicherweise ruhiger schlafen). Und Kontextwechsel kosten. Und Grafikkartentreibern geht es um Performance, sogar mehr noch als um Korrektheit. Ich bleibe daher bei meiner Einschätzung. Zumindest bis jemand kommt und es mir noch anders erklärt :-)
Sein neuester Streich: Ein x86-Emulator in Javascript. Im Emulator läuft ein Linux-Kernel, und das ganze emuliert einen Ranz-x86 mit Ramdisk und Serialport für die Ausgaben. Spannenderweise performt das in Firefox doppelt so gut wie in Chrome schreibt er. Auf jedenfall mal wieder ein echter Fabrice Bellard-Kracher.
Nanu? Wo kommen denn die ganzen Apple-User her? Bashe ich noch nicht genug auf denen rum? :-)
Ich bin erstaunt, dass Chrome so einen geringen Marktanteil hat. Ich hätte den höher geschätzt.
Der Effekt ist, dass ausser Youtube und Enthusiasten wie mir niemand webm ausgerollt hat. Und Firefox sah im Vergleich zu Chrome schlecht aus, weil sie sich geweigert haben, H.264 zu unterstützen.
Und jetzt kommt dieser Paukenschlag: Google kündigt an, H.264-Unterstützung aus Chrome zu entfernen. Kurzfristig ist das natürlich schlecht für die Chrome-User, weil damit einige Early Adopter des Video-Tags nicht mehr gehen. Langfristig ist das aber die richtige Entscheidung, um webm nach vorne zu bringen. Denn Firefox 4 kann auch webm, und damit ist die klare Mehrheit der wichtigen Browser webm-fähig.
Es ist auch eine gute Gegenaktion zu Microsofts Subversionsversuch, Firefox unter Windows H.264-Support zu geben, damit die Leute lieber Firefox als den Browser des Erzkonkurrenten benutzen und damit webm nicht vom Boden wegkommt.
Viele Leute hatten webm schon zu den Akten gelegt, weil die MPEG-Lizensierungsmafia als Reaktion auf webm verkündet hat, das H.264-Streaming im Internet bleibe lizenzkostenfrei. Das haben viele Leute so interpretiert, als sei H.264 jetzt generell lizenzkostenfrei, aber das folgt daraus halt nicht. H.264 ist nach wie vor eine Patenthölle, und jeder Schritt, um diesen Leuten das Wasser abzugraben, ist ein Schritt nach vorne für die Menschheit. Scheiß Patentscheiß immer, beschissener.
Update: Übrigens, spannendes Detail: Auch Adobe will webm in Flash unterstützen. D.h. man wird H.264 auch nicht mehr als Flash-Fallback brauchen. Nur noch als Apple-Fallback. Und Apple spricht ja eh nicht H.264 sondern je nach Gerät nur Baseline-Profil und kann auch von AAC nur eine Teilmenge des Standards, d.h. webm muss qualitätsmäßig gar nicht mit dem H.264 High Profile konkurrieren und kann da mithalten. Für mich als Webseitenbetreiber sieht es dann also plötzlich so aus, dass ich mit webm mal eben über 90% des Browsermarktes abdecken kann, und nur für Apple eine Extrawurst braten müsste. Das wird sich der eine oder andere Webseitenbetreiber dann vermutlich schlicht sparen.
Aus fundamentalistischen Gründen gibt es das Video nur per video-Tag und nur per Ogg Theora oder WebM. Nein, kein Flash, keine Krücken für IE- und Appleuser. Gewöhnt euch dran. Das kennt ihr ja eh schon, dass auf euren Geräten Dinge dann halt nicht gehen. Oder installiert euch halt Firefox oder Chrome.
Wem die Ironie der Aussage in dem Video nicht klar ist, der sei darauf hingewiesen, dass es in den USA gar keine Vorratsdatenspeicherung gibt. Auch "ab und zu mal einen Fingerabdruck" gibt es da nicht, insbesondere nicht im Personalausweis, denn es gibt überhaupt keinen Personalausweis dort.
Update: Mhh, hier stand ursprünglich auch Opera, aber Opera spielt das bei mir auch nicht ab. Suuuuper technologie. Also lade ich es doch auch nochmal als mp4 hoch. Hey, Opera, da könnt ihr ja mal echt stolz auf euch sein!
Update: Für Leser mit kurzer Aufmerksamkeitsspanne sei auch nochmal hierauf verwiesen.
I went to check the website using my default browser (Firefox 4 Beta 6) and noticed it was at 3.5%.[…]
I tried to use their little payment calculator but the flash based widget wouldn't work properly in the Firefox Beta so I loaded up Safari to try and funny enough the rate offered was 2.7%.
I checked in Chrome and Opera to see if it was maybe just something wrong with the Firefox beta and Chrome's rate was 2.3% while Opera's was 3.1%.
Ich hätte jetzt gedacht, dass Safari-User die höchsten Raten zahlen müssen, die haben ja schon im Vorfeld ihre Unzurechnungsfähigkeit bewiesen :-)
Update: Übrigens, wenn ihr Chrome habt, ist es auch sehr spannend, mal nicht die englischsprachigen Meldungen zu lesen, weil die ja uns und die Amis als Zielgruppe haben, sondern die Farsi-Meldungen. Chrome bietet dann an, das zu übersetzen. Das ist natürlich eher Babelfish-Qualität, aber es liest sich alles ausgesprochen spannend, teilweise fast wie nordkoreanische Verlautbarungen:
The Islamic Iran has always wake fields Due to the stability of policies and arrogant evil superpower domination of the world's great until the end of history is always good endurance peaks will shine
Neben IRNA gibt es auch noch ISNA, da scheinen die Meldungen aber weniger propagandistisch aufgeladen zu sein.
Update: Das ehemalige Nachrichtenmagazin liest (aus der selben Statistik) das Gegenteil heraus:
aber auch sonst gerät sein Regime immer stärker unter Druck. Deutsche und andere Großkonzerne ziehen sich reihenweise aus seinem Land zurück, sogar Russland weist Teheran in die Schranken.
Dass die Fonts in jedem Browser eine subtil andere Größe haben, das ist glaube ich mein Fehler. Falls jemand weiß, wie man das ohne Browserweiche besser macht, nehme ich Hinweise gerne entgegen.
Update: Ach wie schön, der Vollkorn-Autor hat vor ein paar Tage eine neue Version mit besserem Hinting veröffentlicht. Gleich mal updaten :-)
<img src="logo.svg">und alles wird gut, aber weit gefehlt! Stellt sich raus, dass Chrome das kann, Firefox aber nicht. Firefox erwartet ein object-Tag. Was für ein Hirnriss!
Aber das ist noch nicht alles. Stellt sich raus, dass Safari SVG kann (ist ja auch Webkit wie Chrome, damit war zu rechnen), aber NICHT auf dem Iphone oder Ipad. WTF?! Gerade das Ipad haben sie doch als Browser-Device verkauft!
An der Safari-Version kann man es nicht festmachen. Die Plattformstrings werden schnell unübersichtlich, es gibt da auch noch irgendein webtv-Zeugs, kenn ich alles nicht. Also ist da jetzt eine Javascript-Browsererkennung drin. Wie furchtbar ist DAS denn alles?! Ich dachte, die Zeiten seien vorbei im Web?
Also aus meiner Sicht: Schande über Apple und Firefox.
Und zur Krönung des Tages kommt hier auch noch einer an, der benutzt Epiphany mit Webkit, und das gibt sich als Safari unter Linux aus. Das bau ich da jetzt nicht ein. Was für ein Müll dieses Web doch ist.
Oh und bei Firefox ist offenbar das UI für das audio-Tag kaputt und man kann da nicht die Lautstärke regeln. Na suuuuuper. Bin ich wirklich der erste, der das Audio-Tag benutzt?! Ist das echt noch keinem aufgefallen?!?
Angefangen hat damit IE8, dann kam Chrome, und jetzt Reader.
Ach und wo kommt der Sandbox-Code her? Von MS Office! Von "MOICE". Dazu könnte ich jetzt eine großartige Geschichte zum Besten geben, darf aber nicht. Scheiß NDAs immer. Aber ihr könnt euch ja selbst fragen, ob aus eurer Sicht MS Office als sicher gelten kann oder nicht.
Ich frage mich ja, wenn sie schon ein PDF-Plugin machen, wieso sich PDF-Seiten dann nicht genau so anfühlen wie HTML-Seiten. Das fühlt sich alles noch … anders an. Rechtsklick gibt es gar nicht, Mittelklick auf einen Link im PDF tut auch nicht das selbe wie bei HTML… da geht noch was.
Jetzt müssen sie nur noch den nächsten Schritt gehen und Adobe-Code da rauskanten und den Render-Code selber schreiben. Im Moment klingt das mehr nach Plugin-API-Erweiterungen.
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-1297).
Note: There are reports that this issue is being actively exploited in the wild.This update resolves a memory exhaustion vulnerability that could lead to code execution (CVE-2009-3793).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2160).
This update resolves an indexing vulnerability that could lead to code execution (CVE-2010-2161).
This update resolves a heap corruption vulnerability that could lead to code execution(CVE-2010-2162).
This update resolves multiple vulnerabilities that could lead to code execution (CVE-2010-2163).
This update resolves a use after free vulnerability that could lead to code execution (CVE-2010-2164).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2165).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2166).
This update resolves multiple heap overflow vulnerabilities that could lead to code execution (CVE-2010-2167).
This update resolves a pointer memory corruption that could lead to code execution (CVE-2010-2169).
This update resolves an integer overflow vulnerability that could lead to code execution (CVE-2010-2170).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2171).
This update resolves a denial of service issue on some UNIX platforms (Flash Player 9 only) (CVE-2010-2172).
This update resolves an invalid pointer vulnerability that could lead to code execution (CVE-2010-2173).
This update resolves an invalid pointer vulnerability that could lead to code execution (CVE-2010-2174).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2175).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2176).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2177).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2178).
This update resolves a URL parsing vulnerability that could lead to cross-site scripting (Firefox and Chrome browsers only) (CVE-2010-2179).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2180).
This update resolves an integer overflow vulnerability that could lead to code execution (CVE-2010-2181).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2182).
This update resolves a integer overflow vulnerability that could lead to code execution (CVE-2010-2183).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2184).
This update resolves a buffer overflow vulnerability that could lead to code execution (CVE-2010-2185).
This update resolves a denial of service vulnerability that can cause the application to crash. Arbitrary code execution has not been demonstrated, but may be possible. (CVE-2010-2186).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2187).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2188).
This update resolves a memory corruption vulnerability that could lead to code execution (CVE-2010-2189).
Note: This issue occurs only on VMWare systems with VMWare Tools enabled.
This update resolves a denial of service issue (CVE-2008-4546).
Ich habe "code execution" mal hervorgehoben, weil das die Totalschaden-Kategorie ist. Schon EIN Bug dieser Kategorie ist Totalschaden. Selbst Apple braucht mehr Pakete, um so viele Totalschaden-Bugs anzuhäufen. Ich komme aus dem Stand nur auf eine Firma, die jemals eine derartige Totalschaden-Dichte erreicht hat. Oracle.Update: Oh toll und 64-bit-Support haben sie offenbar heimlich, still und leise gecancelt. Tja, dann halt kein Flash mehr.
Aber das Video dort funktioniert nicht. Warum? Weil Apple es absichtlich kaputtgemacht hat. Klickt mal auf die Video-Demo drauf. Spielt nicht. Rechtsklickt mal auf das Video und lasst euch die URL ausgeben. Ist bei mir diese hier. Wenn man sich diese Datei per HTTP holt, kriegt man eine MOV-Datei. MOV, das wissen vielleicht nicht alle, ist die Basis von MP4, nicht zuletzt auf Apples Drängen hin. Dass das .mov heißt, ist also nicht der Grund, wieso Chrome das nicht spielt. Auch nicht der MIME-Type.
Wenn ich mir die Datei per wget hole und mal reingucke, ist die bloß 359 Bytes groß, und beinhaltet einen Redirect auf diese Datei. Leider ist der Redirect relativ, da steht also nur der Dateiname drin, nicht die komplette URL. mplayer kann das übrigens, wenn ihr auf der Kommandozeile
mplayer http://movies.apple.com/media/us/html5/showcase/2010/demos/apple-html5-demo-tron_legacy-us-20100601_r848-2cie.moveingibt, spielt der den Trailer. Bei mir zumindest. Hängt vermutlich auch von der mplayer-Version ab. Aber Chrome unterstützt das halt nicht. Nun, erzeugen wir doch mal eine kleine Datei, die das Video-Tag mit der Ziel-URL des Redirects benutzt: hier. Das spielt Chrome dann plötzlich.
Da der Redirect relativ ist und nicht auf einen anderen Server verlinkt, hat das auch mit CDN-Optimierung o.ä. nichts zu tun. Der Redirect erfüllt genau keinen Zweck (außer Chrome auszuschließen). Für den Benutzer ergibt es einen zusätzlichen HTTP Round Trip, für Apple bedeutet es einen HTTP-Zugriff mehr, d.h. mehr Netzwerkkosten und mehr Serverlast. Nicht viel, aber doch vorhanden.
Also, liebe Apple-Apologeten. Dann erklärt mir doch mal, wieso Apple das macht. Außer natürlich, um uns alle zum Installieren von Quicktime zu zwingen? Na? Fällt euch auch nichts ein? Na sowas.
Das gilt übrigens für die gesamte Apple-Trailer-Site. Wieso benutzt das noch Quicktime und nicht HTML5-Video, wenn Apple angeblich so ein Verfechter offener Standards ist? Weil es da nie um die Trailer ging. Sondern um Quicktime-Installationsbasis.
Update: Oh übrigens, ein besonders zynischer Leser hat mir dieses hilfreiche Schaubild gemailt :-)
Update: Eine Sache will ich auch mal sagen: die Demos sind visuell ziemlich geil, die Apple da gemacht hat.
Ich muss ja sagen, das ist in der Tat der eine große Nachteil von Chrome gegenüber Firefox. Bei Firefox kann adblock auch das Laden von Javascript-Dateien blocken. Bei Chrome kann man nur die Bilder selbst blocken, da müsste man einen Proxy nehmen oder gleich im DNS die ganze Domain blocken. Ich muss echt mal ein Chromium Buildsystem aufbauen und dann hack ich mir da halt einen Regex-Filter in die HTTP-Engine rein, der eben 404 simuliert, wenn die URL einer der Regexen matcht.
Es ist gar nicht überzubewerten, was das für ein wichtiger Schritt für uns alle ist. Google als Betreiber von Youtube weiß ja auch, dass bis 2012 eine Übergangsfrist läuft, in der sie auf Lizenznerv verzichten können. Und bis dahin muss mal eine Alternative her. Und Google sitzt nicht nur wegen Chrome, sondern auch wegen Youtube am fettesten Hebel im Internet. Wenn die umstellen, dann werden die Browser-Hersteller alle folgen. Und tatsächlich haben sie zum Launch schon Firefox und Opera als Partner gewonnen. IE kann man mit Chrome Frame abbügeln. Bleibt nur Safari, und die paar Apple-Spacken fallen in der Statistik ja eh nicht weiter auf, wenn die keine Videos mehr kriegen. Merken die eh nicht, die haben ja auch nicht gemerkt, wie scheiße der Quicktime-H264-Encoder ist.
Rein technisch gesehen ist natürlich nicht alles Gold, was glänzt. Aber ich hoffe trotzdem, dass die x264-Leute das übernehmen und daraus einen Goldesel für uns alle bauen. Vor allem haben die auch das Knowhow, um die Spec so zu ändern, dass sie Patente vermeidet.
Update: Microsoft will in IE9 auch WebM supporten (WebM ist der Marketingname für VP8)
Nun, die haben ihre erste erfolgreiche Löschung vorzuweisen: sich selbst :-)
Ich habe nur mit Chrome probiert, mit Opera kommt angeblich das gleiche, Firefox bringt auch "No pages found". Mit elinks (Textmode-Konsole) kriegt man allerdings noch Inhalt. (via)
Update: Mir mailt gerade jemand, dass es noch geht, wenn man als Browsersprache Deutsch eingestellt hat.
Und das ist auch wieder so eine überflüssige Steilvorlage für Microsoft, wieder was von Wettbewerbsverzerrung zu faseln wegen Silverlight. Moan Google, bisher sah das bei euch halbwegs so aus, als habe eure Strategie Hand und Fuß. Seufz.
Irish? Ernsthaft? Ich dachte, die sprechen da Englisch. Oder hält Chrome das für Gälisch?
Und so sehr ich ein Freund von Theora und vor allem Vorbis bin… Theora hat noch Probleme. Das kann man ganz gut an diesem Test-Clip sehen, den ich mal aus dem Fernsehen aufgenommen und damit encoded habe. Diese unscharfen Hintergrundschlieren bringen einen Theora-Bug zum Vorschein. Ich habe das damals auch bei Theora ins Bugtracking-System gekippt, aber keine Rückmeldung gekriegt.
Meine Hoffnung ist, dass Theora das fixt, dass Youtube dann Theora supported, und alles gut wird. Bis dahin würde ich mir wünschen, dass Firefox eine (von mir aus inoffizielle) Plugin-Schnittstelle für andere Codecs kriegt, damit man da ffmpeg anschließen kann.
Jedenfalls: der H.264 Decoder in Chrome ist deutlich schneller als der im Flash-Plugin. Wer also bisher keine HD-Videos von Youtube gucken konnte, kann es ja jetzt mit HTML5-H.264 nochmal probieren. Wenn der Rechner schnell genug ist, spart man sich womöglich gar einmal Lüfter-Hochtakten.
Update: Kriege gerade eine Mail mit einem Screenshot eines Chrome 0day :-)
Update: Und noch ein BBS-Design, das mir dankenswerterweise Simon eingeschickt hat. Sehr, sehr geil.
The Windows Sandbox is very "hardcoded" on the OS structure and native function prototypes. It would require significant work to make 64-bit safe.Äh WTF? Was für Verlierer! Mann Mann Mann.
Da gehörte schon ganz schön Anstrengung dazu, noch schlimmer als Microsoft auszusehen mit den EULAs und dem Nach-Hause-Telefonieren. Gratulation, Google, das kann nicht einfach gewesen sein. Wieso wollen eigentlich alle großen Firmen über kurz oder lang das größe Arschloch am Markt sein? Ist das inhärent?
{kind=link}
{kind=link}
{kind=link}
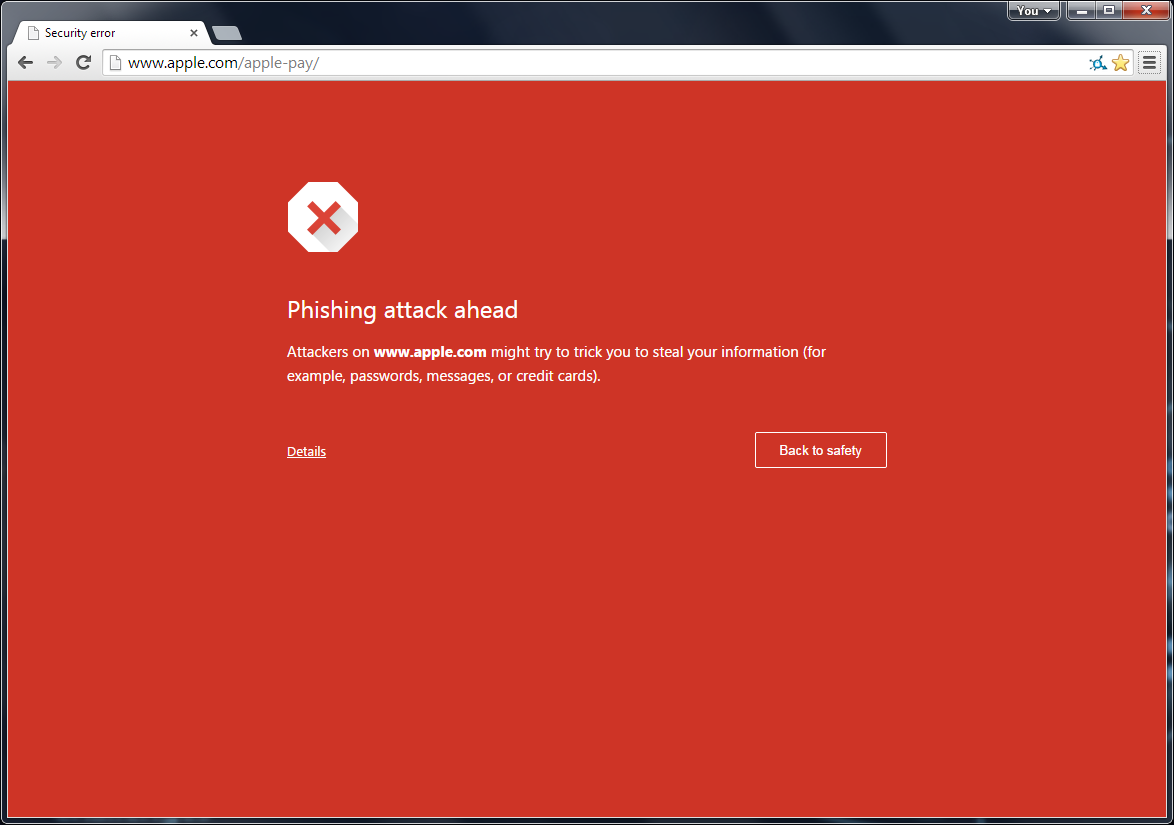{kind=link}
{kind=link}
{kind=link}
{kind=link}