Das klingt erst mal schlau, bis man sich näher mit HTTP auseinandersetzt. Denn da ist das so, dass die externen Referenzen hauptsächlich statisch sind, während sich das HTML auf der Seite ändert. Der Stylesheet ändert sich vielleicht einmal im Jahr, wenn es hochkommt, die Javascript-Library ändert sich, wenn mal wieder ein neuer Browser auf den Markt kommt, und die Inline-Bilder ändern sich einmal am Tag. HTTP hat das erkannt und bietet dafür eine Optimierung an, If-Modified-Since. Hier ist ein typischer HTTP-Request:
GET /rss.xml?html HTTP/1.1Der Client sagt hier also: ich war zuletzt um 19:07:32 GMT hier. Der Server sieht sich das an und antwortet:
Host: blog.fefe.de
Connection: Keep-Alive
User-Agent: Akregator/1.5.1; syndication
If-Modified-Since: Thu, 12 Nov 2009 19:07:32 GMT
Accept: text/html, image/jpeg;q=0.9, image/png;q=0.9, text/*;q=0.9, image/*;q=0.9, */*;q=0.8
Accept-Encoding: x-gzip, x-deflate, gzip, deflate
Accept-Charset: utf-8, utf-8;q=0.5, *;q=0.5
Accept-Language: en-US, en
HTTP/1.1 304 Nix NeuesDas ist das HTTP-Modell, um unnütze Daten nicht zu übertragen. Für RSS ist dieser Fall häufig, aber noch viel häufiger ist er für Stylesheet, favicon.ico, Inline-Bilder und externe Javascript-Dateien (gut, die habe ich ja sowieso gar nicht bei mir). Das ist ja gerade der Grund, wieso man Javascript-Bibliotheken in eigene Dateien auslagert. Weil die sich eben nicht ändern und dann nicht bei jedem Zugriff neu übertragen werden sollen.
Google schlägt jetzt vor, der Server soll bei der Anfrage nach der Webseite auch gleich ungefragt die ganzen (ungeänderten) Dateien mitschicken. Das mag zwar im Benchmark die Latenz senken, aber es würde das Web-Verkehrsaufkommen im Internet mal eben verdoppeln. Beim ehemaligen Nachrichtenmagazin würde dann bei jedem Webseitenklicken das Spiegel-Logo mitübertragen. Wenn ihr mal sehen wollt, was das ausmacht, dann geht einmal zu spiegel.de, löscht einmal den Cache, startet den Browser neu, und geht nochmal zu spiegel.de Das dauert gleich fünfmal so lange!
Daher glaube ich, dass es Google hier um was anderes geht. Die wollen nicht wirklich die Stylesheets als Server Push machen. Die wollen die Google Ads als Server Push machen. User werden nämlich ungehalten, wenn eine Webseite langsam lädt, weil die Werbung so lange braucht. Und wenn wir das erst mal so machen, dann ist auch der zentrale Vorteil von Werbeblockern weg. Weil die Seite dann eben nicht schneller lädt mit Werbeblocker. Es flimmert nur nicht mehr so.
Oh und völlig unabhängig davon: der Server müsste, damit das überhaupt funktioniert, die Webseiten parsen und die Abhängigkeiten analysieren können. Das ist eine immense Komplexität, die man nicht im Webserver haben will. Schon aus Sicherheitsgründen nicht. Je komplexer, desto angreifbarer.
Oh und wenn ihr euch mal den HTTP-Request da oben anguckt: über die Hälfte davon ist vollständig überflüssig. Das sollte man nicht komprimieren, sondern einfach mal den überflüssigen Mist rausnehmen.

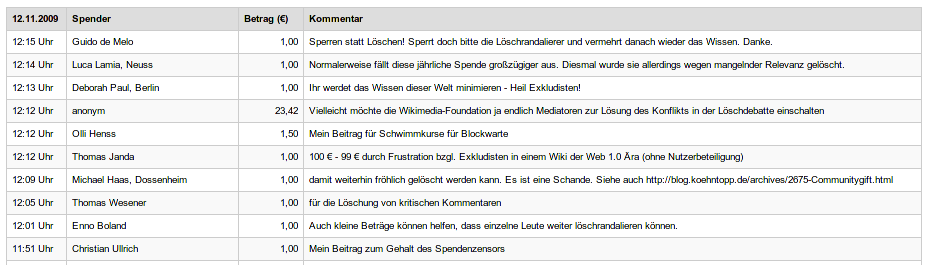
Das lässt ja mal wieder tief blicken, wie unsouverän Wikimedia hier mit Kritik umgeht. Tilos Spende ist weg. Fast so unsouverän wie das Treffen neulich.
Update: Interessanterweise hat sich Wikimedia damit in die Wikipedia-Schußlinie gebracht, was sie ja bisher nach Kräften vermieden haben. Das wird sich vermutlich als wenig schlaue Entscheidung herausstellen.
Update: Wow, da platzt gerade ein Knoten. Ich bin ja an sich nicht dafür, denen auch nur einen Euro zu spenden, aber was da gerade passiert hat auch gute Seiten. Zum Einen stehen da echte Namen dran, im Gegensatz zu den Kindergarten-Pseudonymen, hinter denen sich in der Wikipedia die User verstecken. Zum Anderen entkräftet das das Argument, das wir zuletzt noch auf dem Wikimedia-Whitewash-Treffen gehört haben, Wikimedia habe kein Mandat für den Betrieb einer Deletionpedia für WP:DE, weil die Spenden ja nach wie vor reinkämen, also würden sie ja das richtige tun. Vielleicht passiert ja jetzt doch auch mal was Positives in dieser ganzen WP:Sickergrube. Übrigens, eine positive Sache gibt es ja abgesehen hiervon zu berichten: der Admin 32X verliert gerade seine Admin-Wiederwahl. Das war der mit dem "völkischen Beobachter", falls ihr euch erinnert. Vielleicht gibt es da ja doch so etwas wie Selbstheilungskräfte, und wir haben die nur noch nicht genug stimuliert.
Update: Es gibt jetzt auch eine (lahme) Stellungnahme von Wikimedia. "Wir beziehen […] keine Position in der aktuellen Relevanzdebatte", nee klar, "Unser Spendenticker ist […] die falsche Plattform".
Update: Au weia, lest euch mal die Kommentare durch, die sich der Wikimedia-Pavel mit der Stellungnahme eingefahren hat. Da kriegt man ja fast Mitleid. Käpt'n, wir haben Wassereinbruch! *gluck* *gluck* *gluck*
Update: Mir mailt gerade jemand folgendes:
Proaktiv der Hinweis, daß es beim Spenden nicht reicht, den Betrag auf "1 Euro" zu drehen, man muss auch noch ein Häkchen umsetzen - ansonsten ist der Betrag plötzlich 20 Euro. Ohne weitere Vorwarnung, die eigentlich überall woanders übliche Seite mit "Überprüfen Sie Ihre Angaben" fehlt.
Jetzt mailen mir andere, dass das doch nicht so ist, und man auch eine Mail kriegt, über die man sich auch beschweren kann. Ich geb das mal alles nur so weiter. Könnt ihr ja selber gucken. Ich vermute mal, dass derjenige Javascript ausgeschaltet hatte. Aber ein-zwei 20 Euro Spenden sind ja dazwischen gerutscht, also könnte da ja doch was dran sein.
Update: Mit dem "Blockwart" habe ich ja offensichtlich ins Mark getroffen, wie man auf diesem mir zugemailten Screenshot gut sehen kann. Ich verstehe gar nicht, was deren Problem dabei ist. Ich habe ja nirgendwo geschrieben, Wikipedia bestünde nur aus Blockwarten, oder die Admins seien alles Blockwarte. Im Gegenteil habe ich sie aufgerufen, die Blockwarte rauszuschmeißen. Es läßt tief blicken, dass offenbar auch der Herr Geschäftsführer der Wikimedia sich da persönlich angesprochen fühlt und da jetzt mit eiserner Hand durchgreift, nicht nur an der Eingangstür, wenn er persönlich den Heise-Reporter rausschmeißt, sondern auch bei den Kommentaren in seinem Hausblog. Tja, so ist das eben, wenn die Vorstellungen von PR-Funktionären ("Müller, wir brauchen auch so ein Blog, da können wir dann unsere PR-Botschaften verbreiten") auf die Realität treffen. Oh und ich bin entzückt, wie viele Vandalen sich öffentlich beschweren, dass ich keine Kommentarfunktion habe. Besser könntet ihr mich gar nicht in meiner Entscheidung bestätigen!
 (etwas älteres Bild)
(etwas älteres Bild){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}