Fragen? Antworten! Siehe auch: Alternativlos
Ein Typ meldet zum Testen einen S3-Bucket an. Spielt ein bisschen rum. Lädt keine Dateien hoch oder runter. Erledigt seinen eigentlichen Auftrag, guckt sicherheitshalber nochmal, dass er im Free Tier geblieben ist mit seinen paar Bytes Testtraffic.
Findet eine Rechnung über $1300 vor.
Stellt sich raus: Irgendein versifftes Open-Source-Projekt hat eine Backup-zu-S3-Funktionalität eingebaut, und in der Konfigdatei das Äquivalent von "example.com" eingetragen, und das war genau sein Bucket.
Ja aber er hat denen ja keine Permissions gegeben, da wurde also nichts hochgeladen!
Stimmt, aber AWS berechnet auch Fehlermeldungen. Wenn du also einen Bucket hast, und jemand den Namen raten kann, dann ist egal, wie geil deine ACLs gesetzt sind. Solange der aus dem Internet erreichbar ist, kann dir jemand die Trafficrechnung explodieren.
Aber was hat das mit einer Supply-Chain-Apokalypse zu tun, fragt ihr? Nun, er hat dann mal testweise für ein paar Minuten Upload-Permissions gesetzt, um zu gucken, wer da zugreifen wollte.
I opened my bucket for public writes and collected over 10GB of data within less than 30 seconds.Ja geil ey! Früher musste man noch wo einbrechen, wenn man die Daten klauen wollte!Oh und natürlich hat Amazon auch schon herumgetrickst, um die Kosten hochzutreiben.
Another question was bugging me: why was over half of my bill coming from the us-east-1 region? I didn’t have a single bucket there! The answer to that is that the S3 requests without a specified region default to us-east-1 and are redirected as needed. And you pay extra for that redirected request.Da willst du doch Kunde werden, bei so einer Firma!!1! (Danke, Dietz)
Eine ähnliche Kategorie von "da krieg ich Gewaltfantasien"-Neusprech ist "-scale". Was die alle immer rumgefurzt haben, wie geil ihr Scheiß skalieren würde! Und dann guckst du mal vorbei und wartest 20 Sekunden auf das Laden der Homepage.
Und jetzt ist alles "internet scale" oder zumindest "cloud scale", man sagt nicht mehr "Cloud-Drückerkolonne" sondern "Hyperscaler" (das einzige, was da skaliert, sind die Rechnungen). Furchtbar.
Höchste Zeit also, dass sich ein Depp findet, der mit "AI-native" und "AI-scale" Werbung macht.
Was soll ich euch sagen? Cisco liefert! Ja, DAS Cisco, das mit den ständigen apokalyptischen Sicherheitslücken. Die mit den Dutzenden von versehentlich hart einkodierten Admin-Account-Passwörtern. DIE. Die erzählen uns jetzt nicht nur was von Security sondern machen gleich noch die volle Familienpackung "AI" dran. Vorsicht: Wenn man irgendwas von irgendwas versteht, kriegt man von der Lektüre direkt Ganzkörper-Juckreiz. Das Produkt heißt "Hypershield". Wie Hypeshield aber mit r. Damit man assoziiert, es sei für Hyperscaler (und damit BESTIMMT SICHER GUT GENUG FÜR UNS HIER).
Eine Sache glaube ich ihnen. Dass die Presseerklärung direkt aus einer "KI" fiel. Das ist alles so falsch, dass nicht mal das Gegenteil stimmt.
Auf der anderen Seite kann man Punkte für alle Schlangenöl-Tropes in der IT-Security-Werbung vergeben. Das checkt alle Boxen.
DOCH! Das geht! In der unseriösen Werbung einer anderen Firma: Nvidia. Ihr seht wahrscheinlich schon kommen, was als nächstes passiert:
Cisco [blahsülz] with NVIDIA, is committed to building and optimizing AI-native security solutions to protect and scale the data centers of tomorrow.Und schwupps, mit einer kleinen Handbewegung, ist was eben noch ein Nachteil war (nämlich dass hier ohne Domain Knowledge eine "KI" Dinge halluziniert, die darauf trainiert ist, dass das plausibel aussieht, nicht dass es funktioniert) ein Vorteil! Weil, äh, "AI-native"!!1!Ja aber Moment, Fefe, da stand ja noch gar nicht "empower"! Ohne "empower" geht sowas doch gar nicht!!
"AI has the potential to empower the world's 8 billion people to have the same impact as 80 billion.Das hingegen finde ich ein tolles Zitat. Er sagt hier also: Wenn die Leute alle "KI" machen, dann werden sie zehnmal so viel Ressourcen verbrauchen, ohne einen Vorteil daraus zu ziehen. Glaubt mir, wenn das Vorteile brächte, hätte er die hier erwähnt.Wo wir gerade bei Warnungen waren:
The power of Cisco Hypershield is that it can put security anywhere you need it – in software, in a server, or in the future even in a network switch.Du brauchst dann halt in jedem Ethernetport eine Nvidia-GPU. Das wird das Power-Budget geringfügig senken, das für tatsächliches Computing übrig bleibt in einem Data Center, aber für Nvidias Aktienkurs wird es großartig werden!When you have a distributed system that could include hundreds of thousands of enforcement points, simplified management is mission critical. And we need to be orders-of-magnitude more autonomous, at an orders-of-magnitude lower costBeachtet das "autonomous" her. Eine "KI", die keiner versteht, weil sie nicht programmiert sondern trainiert wurde, soll autonome Entscheidungen darüber treffen, welche Netzwerkpakete erlaubt sind und welche nicht. Oh und wie immer bei "KI" gibt es auch kein Debugging, nur "nach-trainieren", was dann andere Stellen kaputtmacht. Das wird ja eine tolle Zukunft!So, jetzt kommen wir zum technischen Teil. Weiter unten, damit er die Deppen nicht mit Fakten verwirrt.
AI-Native: Built and designed from the start to be autonomous and predictive, Hypershield manages itself once it earns trust, making a hyper-distributed approach at scale possible.Cisco sagt also selbst, dass man dem nicht trauen kann, bis es sich Vertrauen erarbeitet hat. Wenn wir es hier mit denkenden Kunden zu tun hätten, wäre die logische Folge, dass man das nicht einsetzen kann. "manages itself" sollte natürlich auch alle Alarmlampen angehen lassen, genau wie "hyper-distributed" und "at scale", aber vermutlich nicht bei Leuten, die Cisco kaufen. Das ist eine Vorselektion vom unteren Rand des Spektrums.Cloud-Native: Hypershield is built on open source eBPF, the default mechanism for connecting and protecting cloud-native workloads in the hyperscale cloud. Cisco acquired the leading provider of eBPF for enterprises, Isovalent, earlier this month.Langsam zeichnet sich ein Bild ab. Irgendein Sprallo bei Cisco sah die Firma mit der Überflüssigkeit konfrontiert, die aus Software Defined Networking einhergeht (ach, man kann Switches in Software machen? Man braucht gar keine Hardware mehr, von Cisco oder sonstwem?), dann haben sie schnell einen Panikkauf von einer eBPF-Klitsche gemacht und mit einem Hype-Überperformer (am Aktienmarkt, nicht bei den Produkten) geredet, also Nvidia, und sagen jetzt den Investoren: We heard you like AI! We put Nvidia in you eBPF so you can hallucinate while you kernel panic!Ich ruf gleich mal den Notarzt. Wenn DAS keinen Herzinfarkt oder Schlaganfall auslöst, dann bin ich möglicherweise schon tot und werde hier gerade bloß von einer "KI" weitersimuliert. Das kann niemand überleben, der mehr als zwei Hirnzellen übrig hat.
Das lohnt sich bei Text (könnt ihr im Browser in den Developer Tools sehen, da steht aktuell sowas wie 6,56KB übertragen, Größe war 12,46KB). Bilder und Videos sind schon komprimiert, da ist das Zeitverschwendung.
Wenn ihr also mein Blog aus der Bahn oder im Handy ladet, dann halbiert Kompression eure Wartezeit. Umso bedauerlicher, dass sich da in den Browsern seit Jahren nicht mehr viel getan hat.
Vor einer Weile hat Chrome Brotli-Support in Chrome eingebaut. Brotli komprimiert geringfügig besser als gzip, aber nicht überzeugend viel besser und es ist auch deutlich langsamer dabei.
Kompression hilft übrigens auch gut bei Font-Dateien, die man per Web einbindet.
Ich erzähle das, weil es ein relativ neues Kompressionsverfahren gibt, zstandard. Ich habe das hier im Blog 2016 zum ersten Mal erwähnt. zstd deckt das ganze Spektrum ab (von "schnell aber nicht so effektiv" bis "langsam und hocheffektiv"). Es hat aber zwei wichtige Vorteile gegenüber Brotli:
"Schnell und dafür nicht so effektiv" ist so schnell, dass man es viel leichter verargumentiert kriegt, das in Protokolle einzubauen. Mein Blog hat im Moment keine Brotli-Kompression, aber wenn die Browser zstd könnten, würde ich sofort zstd-Kompression einbauen. Da kriege ich für den gleichen Aufwand, den ich im Moment bei gzip schon abgenickt habe, deutlich bessere Kompression, bzw. kriege die Kompression, die ich im Moment von gzip kriege, für deutlich weniger CPU-Last im Blog. Das ist also quasi ein No-Brainer, dass man das im Browser will.
Nun, ... hier ist der Firefox-Bug. Der ist von "8 years ago". Immer noch offen. Denn bei Firefox gibt es keine Innovation mehr. Die bauen Dinge erst ein, wenn Chrome sie einbaut. Wenn Chrome etwas ausbaut, baut Firefox es auch aus, wie zuletzt bei jpeg-xl passiert, völlig hanebüchen.
Jetzt wo Chrome zstd hat, wird das hoffentlich auch bald Firefox kriegen, und dann haben wir alle gewonnen.
Update: Heutzutage macht man Webfonts als woff oder woff2 und das ist dann im Wesentlichen ein ttf mit brotli. Es ist immer schlauer, Dateien vorzukomprimiert abzulegen, als sie beim Rausgehen im Webserver zu komprimieren.
New hotness: Honest Don's Used Cars and Certificates! (Danke, Johannes)
Hey, das ist doch genau der Chiphersteller, dem du ein paar Steuermilliarden hinterherwerfen willst, oder? Nachdem sie neulich schon im Compiler zu bescheißen versucht haben, und seit zehn Jahren durch falsche Versprechen und Security-Bugs in ihren Prozessoren auffallen.
Update: Achtet übrigens mal auf die Multiplikatoren. RAD schlägt vor, den Performance Core Multiplier von x55 auf x54 zu senken. Intel hat hier also für 1.8% Performancegewinn ihre Prozessoren falsch rechnen lassen. So mit dem Rücken zur Wand stehen die!
Sagt mal, habt ihr eigentlich Windows Defender laufen, um euch vor Malware zu schützen?
Heute so: Kritisches Securityproblem in Ivanti!
The flaw (CVE-2024-22024) is due to an XXE (XML eXternal Entities) weakness in the gateways' SAML component that lets remote attackers gain access to restricted resources on unpatched appliances in low-complexity attacks without requiring user interaction or authentication.Hey, von denen willst du doch deine Enterprise-VPN-Lösung kaufen!1!!Ivanti VPN appliances have been targeted in attacks chaining the CVE-2023-46805 authentication bypass and the CVE-2024-21887 command injection flaws as zero-days since December 2023.The company warned of a third actively exploited zero-day (a server-side request forgery vulnerability now tracked as CVE-2024-21893) that's now also under mass exploitation by multiple threat actors, allowing attackers to bypass authentication on unpatched ICS, IPS, and ZTA gateways.
Ja gut, bei so vielen apokalyptischen Totalschaden-Sicherheitslücken kann man schon mal die Übersicht verlieren.Endlich nimmt das mal jemand ernst mit "die Zukunft ist passwordless" *wieher*
Wieso verbreiten die jetzt diesen Schwachsinn mit den DDoS-Zahnbürsten? Ich weiß es auch nicht. Aber ich habe Vermutungen.
Erstens mal, der Vollständigkeit halber. Nein, es gab da keinen DDoS. Das war ein hypothetisches Szenario. Muss wohl bei der Übersetzung verloren gegangen sein.
Zweitens: Die hatten noch nie einen guten Ruf. Die hatten damals behauptet, sie hätten ein eigenes Realtime-OS gehackt, was sich dann als ein Linux herausstellte, wenn man das Image gegen den hartkodierten Wert XORt. Aber das sind ja alte Kamellen. Neuer ist "FortiSIEM - Multiple remote unauthenticated os command injection". Ah, die Königsklasse! In der "oh Mann ist das peinlich"-Liga!
Aber warte, Fefe, das war doch letztes Jahr. Das haben die doch bestimmt schnell gefixt.
Klar! Microsoft-Style! Der Patch war rottig und jetzt mussten sie für dieselben Bugs neue Patches machen.
Wer kauft bei solchen Leuten?!
Überlegt mal, wie einfach sich das BSI das machen könnte! Einfach gucken, was Gartner empfiehlt, und jeweils direkt eine Warnung raushauen. Fertig!
Update: Die Aargauer Zeitung sieht sich übrigens als Opfer und bestätigt, dass es sich um ein hypothetisches Szenario gehandelt habe. Das war bestimmt mit "KI"-Hilfe übersetzt. Softwarefehler. Kann man nichts machen.
Oder nehmen wir an, ihr kennt euch mit Computer-Architektur aus. Ihr wisst, dass es einen Kernel gibt, und der kann Userspace-Programme laufen lassen, und stellt denen virtuellen Speicher zur Verfügung und Syscalls und so weiter. Natürlich wisst ihr, dass der Kernel grundsätzlich in den Speicher der Prozesse reingucken kann.
Wenn ihr also, sagen wir mal, curl benutzt, und der spricht SSL mit einem Gegenüber, dann kann der Kernel grundsätzlich in den Speicher gucken und die unverschlüsselten Daten sehen. Da wird jetzt niemand wirklich überrascht sein, dass das so ist, hoffe ich.
Aber die Details waren bisher nicht so attraktiv. Das war mit Aufwand verbunden. OK, du kannst gucken, welche SSL-Library der benutzt, und da stattdessen eine Version mit Backdoor einblenden als Kernel. Oder du könntest die Offsets von SSL_read und SSL_write raussuchen und dann da Breakpoints setzen, wie bei den Debugging-APIs, und dann halt reingucken. Du hättest potentiell auch mit Races zu tun. Du müsstest wissen, wie man aus einer Shared Library die Offsets von Funktionen rausholt.
Gut, aber dann denkst du da ein bisschen drüber nach, und plötzlich sieht das gar nicht mehr so schwierig aus. curl lädt openssl als dynamische Library.
$ ldd =curlDa sieht man schon, dass die Adressen irgendwie krumm aussehen. Das ist ASLR. Wenn du nochmal ldd machst, kriegst du andere Adressen. OK aber warte. Die Daten hat der Kernel ja, und exponiert sie sogar an den Userspace:
linux-vdso.so.1 (0x00007ffff7dd2000)
libcurl.so.4 => /usr/lib64/libcurl.so.4 (0x00007f1df4c66000)
libssl.so.3 => /usr/lib64/libssl.so.3 (0x00007f1df4b6f000)
[...]
$ cat /proc/self/mapsUnd innerhalb des Adressbereichs, an den so eine Library gemappt wird, bleibt das Offset von SSL_write ja konstant. Wie finden wir das? Nun, da gibt es Tooling for:
[...]
7f846a8d2000-7f846aa27000 r-xp 00028000 00:14 5818768 /lib64/libc.so.6
$ nm -D /usr/lib64/libssl.so.3 | grep SSL_writeGut, also grundsätzlich könnte man den Kernel so umbauen, dass er beim Mappen von libssl.so.3 immer bei Offset 35660 einen Breakpoint setzt, und dann könnte man da die Daten abgreifen. Das ist aber eine Menge Gefummel und Kernel-Space-Programmierung ist sehr ungemütlich. Der kleinste Ausrutscher kann gleich die ganze Maschine crashen.
0000000000035660 T SSL_write@@OPENSSL_3.0.0
Warum erzähle ich das alles? Stellt sich raus: Muss man gar nicht. Ist alles schon im Kernel drin. Nennt sich uprobes und ist per Default angeschaltet. Da kann man über ein Config-File im /sys/-Tree dem Kernel sagen, man möchte gerne hier einen Breakpoint haben. Dann kann man per eBPF ein über Kernelversionen portables Kernelmodul hacken, das sich an die uprobe ranhängt und die Daten kopiert. Dann gibt es ein standardisiertes Interface dafür, wie man von dem eBPF-Modul die Daten wieder in den Userspace kopiert, wenn man das möchte.
Was hat man dann? Ein Tool, das in alle SSL-Verbindungen via OpenSSL auf der Maschine reingucken kann. Der Aufwand ist so gering, dass man das im Handumdrehen mit nur ein paar Zeilen Code auch auf gnutls erweitern kann, und auf NSS (die Mozilla-Library). Auch den TLS-Code von Go oder von Java kann man abfangen (Java ist etwas fummelig, da würde man vermutlich einen gemütlicheren Weg nehmen).
Gut, für das Eintragen der uprobe und für das Laden von dem eBPF muss man root sein. Es ist also kein Elevation of Privilege im herkömmlichen Sinne.
Aber es immanentisiert das Problem, das bis dahin bloß theoretisch war. Aus meiner Sicht heißt das, dass man ab jetzt keinem Kernel trauen kann, den man da nicht selbst hingetan hat. Mit anderen Worten: In jemand anderes Container laufen geht nicht.
Das war schon immer klar, aber jetzt ist es immanent. Was sage ich jetzt. Die Tools gibt es sogar schon seit mehreren Jahren. Ein SSL-Abgreif-Tool war das 2. Projekt, das auf diesen Frameworks gebaut wurde. Es sind sogar mehrere Tutorials und Beispielanwendungen online, wie man das macht.
Das nimmt mich gerade mehr mit als es sollte. Wir haben die Vertrauensfrage in der IT auf jeder Ebene verkackt. Der Hardware kann man schon länger nicht mehr trauen. Anderer Leute Software kann man schon länger nicht mehr trauen. Dass man Hypervisoren und Containern nicht trauen kann, ist auch schon immer klar, daher machen die ja dieses Affentheater mit "memory encryption", damit ihr euch in die Tasche lügen könnt, das sei schon nicht so schlimm. Doch. Doch, ist es.
Das könnte mich alles im Moment noch kalt lassen. Ich hacke alle meine Software selber (bis auf den Kernel), OpenSSL ist bei mir statisch reingelinkt (d.h. der Kernel sieht nicht, dass ich da eine Library lade, von der er die Offsets kennt). Man kann mit uprobes und ebpf immer noch meine Anwendungen ausspähen, aber dafür muss man die erstmal reverse engineeren und pro Anwendung die OpenSSL-Offsets raussuchen und eintragen. Das nimmt einem im Moment das Framework noch nicht ab. Aber ihr merkt hoffentlich selber, wie gering die Knautschzone hier ist. Meine Software läuft auf einer physischen Maschine, keinem vserver. Sagt der ISP. Ihr könnt euch mal mal selber fragen, wie sicher ihr euch seid, das selber nachprüfen zu können, wenn euch euer Dienstleister das verspricht.
Ich spoiler mal: Könnt ihr nicht.
Ich glaube, da muss ich mal einen Vortrag zu machen. Das ist alles sehr deprimierend, finde ich.
Die Älteren unter euch werden sich noch an den tumblr "Kim Jong-Il looking at things" erinnern.
Hier haben wir die moderne Variante davon. BSI looking at things.
Ich kann mir gerade gar keine Maßnahme vorstellen, die noch offensichtlicher noch weniger für die Sicherheit tun würde.
Der Verfassungsschutz beobachtet seit Jahrzehnten mit wachsender Intensität die Nazis. Jetzt sitzen die in Landesparlamenten.
Und das hat dann plötzlich Aktivitäten ausgelöst, wo man das ansonsten unter den Teppich gekehrt hätte. Unter anderem dieses bemerkenswerte Aktivität, wo der Hersteller der kaputten Software, die für die Entlassung und juristische Verfolgung von Post-Mitarbeitern verantwortlich war, plötzlich eine "moralische Verpflichtung" sieht, die Opfer seiner verkackten Software zu entschädigen. Ach. Das sind ja GANZ neue Töne!
Aber wartet, geht noch weiter.
He added that the Post Office knew about "bugs and errors" in its Horizon accountancy software early on.Oh aber natürlich, mein Herr! Alle wissen immer vorher, dass sie gerade einen riesigen Fehler begehen! Das war noch nie anders, und ist auch bei allen Cloud-Migrationen so. Niemand wusste jemals nicht, dass das ein riesiger Fehler ist. Aber man macht es trotzdem, weil irgendein windiger Finanzjongleur die Zahlen unter Annahmen aus der Kategorie "Lack gesoffen" so frisiert kriegt, dass die Projektion nach Geld Sparen aussieht.Daher finde ich ja: Natürlich sollten die Hersteller der kaputten Software in den Knast. Aber genau so die Leute, die die wissentlich und vorsätzlich eingesetzt haben.
Da haben ein paar Kaspersky-Mitarbeiter auf ihren Telefonen Malware gefunden. Es waren Apple-Telefone. Sie haben die Exploit-Chain mitgeschnitten und bei uns öffentlich verbrannt.
Die Exploit-Chain (und hier müsst ihr möglicherweise meiner professionellen Einschätzung trauen) war insgesamt mindestens 8stellig Dollar wert. Die haben da einmal die aktuelle Toolbox der NSA verbrannt, oder des GCHQ. Das war der Hammer, was die da für 0days hatten.
Es ging los mit einer Memory Corruption im Truetype-Interpreter (bis hier noch nicht so spektakulär). Von da aus hatten sie einen Kernel Exploit, der aus interpretiertem Javascript heraus ging.
Und am Ende schrieben sie dann ein paar magische Werte in eine undokumentierte MMIO-Adresse und dann überschrieb irgendeine Hardware an allen Schutzmechanismen vorbei physischen Speicher ihrer Wahl mit Werten ihrer Wahl.
Der Adressbereich liegt in der Nähe der GPU und ist in älteren Geräten drin, aber auch in M1 Apple Silicon. Das ist ja schon der Hammer, aber um dieses Operation auszulösen, muss man auch einen undokumentierten Hashwert des Requests in ein undokumentiertes MMIO-Register schreiben. Den Hash haben sie jetzt halt reversed und veröffentlicht.
Aber damit scheiden aus meiner Sicht alle gutartigen Erklärungen für diese Funktionalität aus. Für Debug-Funktionanlität braucht man keinen "geheimen Hash".
Sie haben das an Apple gemeldet und Apple hat dann den Adressbereich gesperrt. In der Konfigdatei für gesperrte Bereiche steht normalerweise das Gerät dran, um das es geht. Hier steht: "DENY".
Da werden gerade einige Geheimdienste sehr unglücklich sein.
Diese Liste war schon immer unfassbar lang und beinhaltet so Entitäten wie "e-commerce monitoring GmbH" (wat!?) und natürlich Konzerne und staatliche Stellen aus aller Herren Länder. Ich sage nur: GUANG DONG CERTIFICATE AUTHORITY.
Nehmen wir mal an, ihr klickt zu https://blog.fefe.de/ und euer Browser baut eine TLS-Verbindung auf. Dann meldet sich die Gegenstelle (hoffentlich, aber nicht unbedingt, mein Server!) mit einem mit meinem Public Key signierten Handshake, und mein Public Key ist signiert von Let's Encrypt, und Let's Encrypt ist in der Liste in eurem Browser. Daher weiß euer Browser, dass er mit meinem Server redet und nicht mit der NSA.
Aber weiß er das wirklich? Was wenn sich da jemand anderes meldet, sagen wir mal der chinesische Geheimdienst fängt die Verbindung ab und leitet die zu sich selbst um, und da kommt dann ein gültig aussehendes Handshake, das aber von einer anderen CA in eurer Browserliste signiert wurde! Zum Beispiel von "Hong Kong Post". Dann würde euer Browser das auch akzeptieren.
Die Telekom hat auch eine CA in der Liste.
Das ist ein fundamentales Problem bei der ganzen TLS-Nummer, für die es auch keine wirklich tolle Lösung gibt. Bisherige Ansätze sind, dass ich in meinem DNS einen Eintrag haben kann, dass nur Let's Encrypt CAs ausstellen darf. Andere CAs sollten sich dann weigern, wenn der Geheimdienst kommt und ein Cert ausgestellt haben will. Das nimmt aber gutmeinende, nicht kompromittierte und nicht an gesetzliche Vorgaben gebundene CAs an.
Der nächste Ansatz ist, dass alle CAs sich zu Transparenz verpflichtet haben, und alle ausgegebenen Zertifikate automatisiert in eine gemeinsame öffentlich einsehbare Liste eintragen. Das nimmt leider auch eine gutmeinende, nicht kompromittierte CA an.
Warum erzähle ich das alles? Erstens um noch mal Honest Achmed's Used Cars and Certificates zu verlinken. :-)
Aber der dringendere Grund ist, dass die EU gerade an der eIDAS-Verordnung arbeitet, bei der es um digitale Identitäten für die EU geht. Das hehre (und gute!) Ziel ist, "Login via Google" kaputtzumachen. Ihr Plan ist, ein eigenes System zu bauen, ein staatliches System, und das hat dann natürlich eine eigene CA, und die kommt in alle Browser und jedes Mitgliedsland bietet eine Wallet-App an, die dann auf alle Smartphones kommt, und Behörden und Google und Facebook und co werden dann gezwungen, Logins via dieser Wallets zu ermöglichen. Schlimmer noch: dafür kriegt dann jeder Bürger endlich einen Barcode auf den Vorderarm tätowiert (Deutschland ist endlich wieder Technologieführer!!1!), äh, einen lebenslang gültigen eindeutigen Identifier zugewiesen, mit dem der Staat dann schön alle Bürger tracken kann.
Ich würde ja von der Benutzung von sowas immer grundsätzlich abraten, weil man damit Google staatlich validierte Daten gibt, die deren Datensätze massiv aufwerten.
Aber der Punkt, wieso ich das hier alles überhaupt ausrolle, ist ein anderer. Die CAs sollen dann in die Browser, und zwar per Verordnung, d.h. staatlich erzwungen. Im Moment kann man im Browser CAs als unvertrauenswürdig markieren. Das darf der Browser dann bei diesen staatlichen CAs nicht erlauben.
Mit anderen Worten: Hier kommt per EU-Verordnung eine TLS-Hintertür in alle eure Browser. Die erlaubt Polizeien und Geheimdiensten das Ausstellen von Zertifikaten für jede Webseite, bei der sie das gerne haben wollen, und damit können sie dann einen Man-in-the-Middle-Angriff gegen jeden fahren, und zwar nicht nur innerhalb der EU, und deren Verbindungen mitlesen oder auch manipulieren und sich als Server ausgeben. Die EFF warnt da seit Jahren vor. Aktuell gibt es einen offenen Brief von hunderten von Experten dagegen. Ist alles ganz traurig, insbesondere weil sich die EU damit hinter Ländern wie Kasachstan und Indien einreiht, die ihren Bürgern bereits Zwangs-CAs oder "digitale ID"-Systeme aufgedrängt haben.
Update: Jetzt kommt ein Klugscheißer und weist darauf hin, dass das Handshake natürlich mit dem Private Key signiert ist, nicht mit dem Public Key. Der Klugscheißer hat völlig Recht. Was ich sagen wollte: Das ist mit meinem Private Key signiert, aber der Public Key wird als Teil des Handshakes übertragen und ist von der CA signiert.
RSA digital signatures can reveal a signer’s secret key if a computational or hardware fault occurs during signing with an unprotected implementation using the Chinese Remainder Theorem and a deterministic padding scheme like PKCS#1 v1.5.Der Angriff ist mächtig genug, dass ein einziger beobachteter Fehler reicht.Dann fiel jemandem auf, dass es solche Fehler auch "natürlich" vorkommen, weil Hardware kaputt geht oder vielleicht ist es zu heiß an dem Tag oder irgendein Softwarebug triggert das. Tja und in diesem Paper haben sie mal passiv Verkehr mitgeschnitten und nach solchen Fehlern gesucht, und ... das hat geklappt.
Nun macht SSH aber nicht rohes RSA sondern hat einen Diffie-Hellman-Schritt darüber, und man nahm an, dass es deshalb gegen diesen Angriff immun ist. Ist es aber nicht, sagt dieses Paper jetzt.
In this paper, we show that passive RSA key recovery from a single PKCS#1 v1.5-padded faulty signature is possible in the SSH and IPsec protocols using a lattice attack described by Coron et al. [16 ]. In this context, a passive adversary can quietly monitor legitimate connections without risking detection until they observe a faulty signature that exposes the private key. The attacker can then actively and undetectably impersonate the compromised host to intercept sensitive data.Das ist eines dieser Papers aus der Kategorie "vielleicht doch lieber Rosenzüchter werden?"Der Angriff betrifft SSH und IKE (Schlüsselaustausch für IPsec). Sie haben dann geguckt, was für Geräte betroffen waren, und das waren ein paar alte Cisco und Zyxel Appliances, und dann noch Geräte von Hillstone Networks und Mocana (beides nie gehört), die sie nicht kontaktieren konnten. Cisco und Zyxel meinten, das betrifft nur Versionen, die seit Jahren out of service sind. Immerhin.
Die Prävalenz dieser Fehlerart ist aber bestürzend groß finde ich:
Our combined dataset of around 5.2 billion SSH records contained more than 590,000 invalid RSA signatures. We used our lattice attack to find that more than 4,900 revealed the factorization of the corresponding RSA public key, giving us the private keys to 189 unique RSA public keys.
Die haben für ihre Aufnahme Halluzinationen vorgetäuscht oder ähnliche Dinge getan, aber dann ab der Aufnahme nur noch völlig normales, gesundes Verhalten gezeigt.
Jeder von denen hat eine Diagnose erhalten, dass er krank sei, und wurde mit Medikamenten ruhiggestellt.
As a condition of their release, all the patients were forced to admit to having a mental illness and had to agree to take antipsychotic medication. The average time that the patients spent in the hospital was 19 days. All but one were diagnosed with schizophrenia "in remission" before their release.Es gab dann noch ein Nachexperiment, das fast noch großartiger war. Da hat Rosenhan angekündigt, sein Experiment wiederholen zu wollen, um zu gucken, ob sich die Lage gebesser hat. Daraufhin haben mehrere Krankenhäuser ihnen untergeschobene Patienten erkannt und entlassen. Nur dass Rosenhan dann meinte, er habe noch gar keine geschickt.An dieses Experiment musste ich denken, als ich die Meldung las, dass lauter Online-AI-Fake-Detektoren echte Bilder aus dem Gazastreifen als Fake "erkannt" haben.
Hey, wie funktioniert denn euer Detektor?
Keine Ahnung, das ist eine KI. Debuggen geht auch nicht.
Ja geil! Ein Schildbürgerstreich! Am Ende sitzen wir alle im Kreis wie bei Warten auf Godot, und keiner weiß, worauf wir eigentlich konkret warten, oder woran wir erkennen würden, dass es da ist. Wäre lustig, wenn es nicht so traurig wäre.
Versteht jemand, wieso wir diese Spezies eigentlich retten wollen?
Wer sich jetzt denkt: Ich mache keine Hardcore Mathe und Bitcoins mine ich auch nicht, das betriff mich nicht! Für den habe ich schlechte Nachrichten. Schon simple String-Funktionen wie strlen benutzen heutzutage Vektorregister. Sogar dietlibc.
Allerdings benutzt dietlibc nicht AVX2, daher wird zumindest dieser Exploit keine Strings leaken. AMD hat einen Microcode-Patch veröffentlicht. Hoffentlicht macht der nicht alles langsamer wie damals die Spectre-Microcode-Patches von Intel.
Rückblickend muss man noch mal festhalten, dass Komplexität der Feind ist. Auch hier wurden die Algorithmen in den CPUs wegen der Spekulation so komplex, dass die Ingenieure sie nicht mehr völlig durchschaut haben. Und so haben sich Hard- und Software angenähert. Alle setzen Dinge ein, die sie nicht verstehen, und selbst die ursprünglichen Entwickler verstehen den Scheiß nicht mehr.
Update: Die Patches sind nur für EPYC verfügbar. Consumer-CPUs müssen bis Ende des Jahres warten. Ja geil, AMD. So macht man sich Freunde. (Danke, Björn)
Da wissen die Admins, was sie tun, haben sie gesagt!
Hidden within this pull request was a typo bug in the snapshot deletion job which swapped out a call to delete the Azure SQL Database to one that deletes the Azure SQL Server that hosts the database. The conditions under which this code is run are rare and were not well covered by our tests.Dieser Tippfehler hatte eine gewaltige kriminelle Energie, müsst ihr wissen. Der hat sich geschickt in einem selten genommenen Codepfad getarnt!!1!
Vor ca. 3 Tagen haben alle Videobrillen des kroatischen Herstellers Orqa zeitgleich den Betrieb komplett eingestellt und keiner wusste bisher, warum das so ist und wie man das behebt.Diese Videobrillen werden als Videoempfänger und Bildausgabegerät für (Hobby-) Drohnen und Flugmodelle genutzt, um die Flugmodelle aus der Pilotenperspektive zu steuern.
Für die Besitzer dieser (recht teuren, ca 600€) Geräte hieß das, dass diese an einem Sonntagnachmittag - zur besten Hobbyzeit - plötzlich gar nicht mehr fliegen konnten. Quasi die Apokalypse für den Hersteller der Videobrillen, da dieser ausschließlich von diesem einem Produkt lebt.Der Hersteller sprach erst von einem Softwarebug, der mit Zeit/Datum zusammenhängen sollte.
Mittlerweile hat sich aber herausgestellt, dass ein ehemaliger contractor von Orqa vor einigen Jahren schon eine Firmware-"Zeitbombe" in den Bootloader eingebaut hatte, die gezielt an diesem Sonntag die Hardware weltweit funktionsunfähig gemacht hat, um Lösegeld von Orqa zu erpressen - ganz unter dem Vorwand von "Lizenzkosten".
Offensichtlich wurde hier Entwicklung outgesourced und nicht weiter überprüft.Der Vorfall wurde mittlerweile von Orqa auf deren Webseite exakt so bestätigt.
Das Problem wurde bisher noch nicht behoben und die Hardware ist nach wie vor für alle Kunden funktionsunfähig.
Das dürfte außerdem meines Wissens nach einer der ersten dokumentierten Fälle von Ransomware auf Consumerhardware sein.(Unabhängig von dieser Story werden diese Videobrillen - wie viele änhliche Modelle anderer Hersteller - auch aktuell im Ukrainekrieg eingesetzt, um dort mit Sprengladungen bestückte Drohnen zu fliegen. Die Piloten dort werden von dem gleichen Problem betroffen sein, der Ransomwareangriff hat damit aber keinen direkten Zusammenhang)
"Bei KI muss die Geheimformel geprüft werden können"
Hier nochmal für alle zum mitmeißeln: Bei "KI" gibt es keine Formel. Auch keine Geheimformel. Es gibt eine lange, lange Liste von Zahlen (Gewichte in einem neuronalen Netz). Ob die veröffentlicht werden oder nicht spielt keine Rolle.
Also doch, spielt eine Rolle. Wenn die veröffentlicht werden, und die Struktur des Netzes auch, dann kann jeder eine Kopie davon selbst betreiben.
Aber es legt halt nichts offen im eigentlichen Wortsinne. Mit oder ohne Zahlen kannst du nicht wissen, was rauskommt, außer durch Ausprobieren. Es gibt keinen Algorithmus, den man verstehen oder debuggen kann.
Eine Formel wird konstruiert oder von mir aus gefunden. Eine "KI" wird trainiert. Während des Trainings ändern sich (je nach Verfahren) die Gewichte im Netz und/oder die Struktur der Vernetzung. Es gibt keine Formel.
Viel Sachkenntnis braucht es bei den Grünen offensichtlich nicht, um sich "Digital-Experte" nennen zu dürfen.
"Für die Zukunft ist eine Zertifizierung von KI denkbar, eine Art Prüfsiegel. Unabhängige Aufsichtsbehörden, auch und gerade auf EU-Ebene, werden sehr genau hinschauen müssen."*facepalm*
Es ist egal, wie genau die auf die Liste mit den Zahlen schauen! Durch Hinschauen gelangt man da zu keinen Erkenntnissen! Nicht nur die Behörde nicht. Auch die nicht, die das Training durchgeführt haben.
"Solange wir nicht wissen, auf welcher Basis Informationen gefiltert und zusammengestellt werden, ist das Risiko von Manipulation und Desinformation groß."Au weia. Das ist so falsch, dass nicht mal das Gegenteil stimmt. Ob du einen Sprachgenerator für Manipulation und Desinformation nutzen kannst, hat wenig bis gar nichts damit zu tun, wie es trainiert wurde. Das Bedrohungsszenario bei "KI" ist doch nicht, dass der Hersteller da absichtlich einen manipulativen Spin einbaut. Das Bedrohungsszenario ist, dass Leute wie von Notz nicht verstehen, was ein Language Model ist und was es nicht ist, und was von Desinformation in die Kamera faseln.
I have been writing about the threat of AI to free speech. Then recently I learned that ChatGPT falsely reported on a claim of sexual harassment that was never made against me on a trip that never occurred while I was on a faculty where I never taught. ChapGPT relied on a cited Post article that was never written and quotes a statement that was never made by the newspaper.Ja gut, das sind diese ChatGPT-Leute. GPT-4 ist bestimmt viel besser!!1!When the Washington Post investigated the false story, it learned that another AI program “Microsoft’s Bing, which is powered by GPT-4, repeated the false claim about Turley.”Turley ist der Autor von dem verlinkten Blogeintrag.Ich hab ja schon ein paar Mal erklärt, dass eines der Probleme bei "KI" ist, dass das trainiert und nicht konstruiert wird, und man das daher auch nicht debuggen kann, wie man regulären Code debuggen würde, und man kann auch nicht Bugs fixen, weil der Kram aus Gewichten in einem neuronalen Netz o.ä. kommt, statt aus Code.
Man hat dann genau drei Optionen: Neu trainieren, nachtrainieren, oder einen Filter davor tun, der genau das Problem erkennt und wegmacht. Alle drei Optionen sind Mist. Auch das neuronale Netz weiß nicht, welche Gewichte wofür zuständig sind. Nachtrainieren wird also eine Lavine aus anderen Änderungen bewirken, alle völlig unklar. Vielleicht wird es dadurch sogar schlimmer.
Neu trainineren wird vermutlich dasselbe Problem wieder haben, denn wir haben ja keinen Weg, das beim Training zu verhindern.
Und der Filter wird nicht funktionieren. Das versuchen Zensoren seit Jahrzehnten und dann reden die Chinesen halt von Winnie the Pooh. Die erfolgversprechenste Implementation eines Filters würde selber auf Machine Learning basieren, was das natürlich direkt ad absurdum führt.
Kurz gesagt: "KI" ist ein Schuss in den Ofen. Lasst euch mal nicht aufschwatzen, dass das a) neu oder b) besser oder c) die Zukunft ist. Die Zukunft, die das wäre, in der würdet ihr nicht leben wollen.
Die Trustpid-Sache scheint schon länger zu gehen.Ist euch mal aufgefallen, dass alle Dinge mit "Trust" im Namen immer die am wenigsten vertrauenswürdigen sind?Auf deren Webseite (trustpid.com) kann man sich den aktuellen Zustand anzeigen lassen. Laut der Webseite habe ich (scheinbar ausversehen) schon am 25.11.2022 n-tv mein Einverständnis erteilt (Screenshot).
Auf der Seite kann man angeblich auch dieses Einverständnis zurückziehen und ein zukünftiges Einverständnis entfernen. Bei mir funktioniert aber beides nicht. Die Seite behauptet, meine Änderungen seien gespeichert, aber nach Löschen der Browser-Cookies ist alles wieder wie vorher.
Und man beachte, dass mein Consent bei n-tv auch schon abgelaufen sein müsste, aber immer noch angezeigt wird... Also wie immer -- Consent funktioniert, der Rest ist kaputt.
Bei Mozilla gab es mal einen legendären Antrag zur Aufnahme in die Liste der vertrauenswürdigen CAs. An den muss ich bei solchen Gelegenheiten immer denken.
Ähnliche Assoziationen habe ich auch immer bei Exzellenzinitiativen, "demokratischen" oder "Volks"-"Republiken" und "Premium"-Produkten. Wenn du das ranschreiben musst, stimmt es wahrscheinlich nicht.
Der Einsender hat auch einen Screenshot mitgeschickt, aber das könnt ihr ja alle mal selber ausprobieren, ob die euch schon irgendwo ein "Einverständnis" untergejubelt haben. Im Privat-Modus des Browsers, versteht sich.
Ja ist ja komisch! Ist ja fast als wäre Code Signing bloß Schlangenöl!?
Also das ist ja wohl mal ein klarer Fall, wo wir jemanden gebraucht hätten, der uns da rechtzeitig warnt!
Ist doch immer dasselbe. Es wurden schon alle Fehler gemacht, nur noch nicht von jedem. Erfahrung ist, wenn du die Fehler wiedererkennst, die du machst.
Der Bug ist ein Stack Overflow, der über das Netz ausnutzbar ist.
Eigentlich wäre dieser Bug so der übelste Fall von Sicherheitsproblem, aber er eignet sich auch zur Illustrierung von Sicherheitsmaßnahmen über die Jahre.
ping droppt als erstes seine Privilegien, nachdem es den raw socket geholt hat. Damit kriegt der Angreifer nicht mehr Root-Rechte wie früher sondern die Rechte des aufrufenden Users, hat allerdings auch Zugriff auf den offenen raw socket.
Außerdem hat FreeBSD einen Self-Sandboxing-Mechanismus eingeführt.
The ping process runs in a capability mode sandbox on all affected versions of FreeBSD and is thus very constrainted in how it can interact with the rest of the system at the point where the bug can occur.Das heißt konkret, dass ein Angreifer z.B. keine anderen Prozesse aufrufen kann, um beispielsweise eine Reverse Shell zu installieren.Auch wenn es sich häufig nicht so anfühlt, haben wir doch eine Menge erreicht über die Jahre. Nur halt nicht beim Entfernen der Bugs. Nur beim Ausnutzen-Verhindern.
Bei den zulässigen Fahrzeuggewichten auf Brücken geht man in der Planung vom worst case aus: Stau. Autos und noch schlimmer LKW mit hohen Achslasten dicht aneinander gereiht. Dabei immer wieder Anfahren und Bremsen, was sich logischerweise auf den Brückenoberbau und somit auch deren Unterbau überträgt. Beim regulären Befahren der Brücke schieben Fahrzeuge, insbesondere LKW eine Art Lastbugwelle vor sich her. Je schneller, desto schlimmer.Das ist ja mal geil! Mitten im Berliner Sumpf ist am Ende die CSU mitverantwortlich. HARR HARR HARRWenn eine Brücke nun etwas in die Jahre gekommen ist und die Tragstruktur deutliche Ermüdung zeigt, ist entweder eine Sanierung oder ein Neubau erforderlich. Da dies aber mitunter etwas dauert, werden entsprechende Sofortmaßnahmen umgesetzt. Die einfachste ist zunächst die Verringerung der Geschwindigkeit und im nächsten Schritt die Verringerung der Spurenanzahl, bzw. die Verringerung des zulässigen Fahrzeuggewichts.
Im konkreten Fall sind wir schlussendlich bei letzterem angekommen (wobei ich gerade nicht weiß, ob dort die Geschwindigkeit herabgesetzt wurde). Will man jetzt über besagte Brücke ein Fahrzeug schicken, das über 3,5t auf die Waage bringt, könnte man es wie zuvor geschehen per Ausnahmegenehmigung einfach fahren lassen. Das liegt daran, dass die Sofortmaßnahmen relativ frühzeitig ergriffen werden und die Brücke auch bei einzelnen höheren Belastungen nicht sofort Schaden nehmen würde. Zusätzlich werden bei der Planung von Brücken die Lasten ohnehin noch mit Sicherheitsaufschlägen versehen, sodass hier in der Regel auch noch Luft ist. Will man auf Nummer sicher gehen, sperrt man die Brücke, lässt das Fahrzeug einzeln drüber fahren und gibt sie danach wieder frei. Ist aber m.E. aus oben genannten Gründen in diesem Fall unnötig.
Ungeachtet dieser Ergänzung finde ich hier übrigens noch erwähnenswert, dass u.a. für Erhalt der Autobahnen und Gewährlleistung des Winterdienstes die im Artikel ebenfalls erwähnte Autobahn GmbH verantwortlich ist. Die Anstalt hatte vor einiger Zeit mal einen schönen Beitrag zu diesem weiteren Premiumprojekt unser aller Lieblingsverkehrsministers der letzten Legislatur.
Nun, keine Sorge. Dafür braucht Berlin keine Klimaaktivisten. Das schaffen wir ganz alleine mit gutem alten institutionellen Totalversagen!
Grund für die Sperrung im Autobahndreieck Funkturm ist, dass die Überfahrt auf die Avus nur für Fahrzeuge bis zu einem Gewicht von 3,5 Tonnen zulässig ist, teilte die Polizei dem rbb auf Anfrage mit. Da Streu- und Räumfahrzeuge der Berliner Stadtreinigung (BSR) schwerer sind, könne es auf dem Streckenabschnitt zu Glätte kommen, was die Sperrung erforderlich mache.Ja gut, klar hätte man die Überbrückung reparieren oder in guten Zustand versetzen können, aber wo wäre denn da dann der Spaß im Winter?
Wenn wir schon keine richtigen Berge zum rodeln haben, dann rodeln wir halt auf Autobahnauffahrten und -überführungen.
Der Grund, wieso Berlin kein Geld für sowas hat, ist übrigens die letzte CDU-Regierung unter Herrn Diepgen und sein Bankenskandal mit Herrn Landowsky: Die haben SO krass verkackt, dass die CDU in Berlin bis heute keinen Fuß mehr auf den Boden kriegt.
Aber warte, nicht nur die CDU sind Totalversager. Ihr fragt euch jetzt vielleicht, wieso das jetzt erst auffällt. Nun, tut es nicht. Die SPD-Regierung war informiert und hat einfach nichts getan.
Auf Nachfrage des rbb konkretisierte die BSR am Dienstagnachmittag, die Autobahn-Winterdienstfahrzeuge hätten ein zulässiges Gesamtgewicht "von mindestens 18 Tonnen", daher dürften sie die Brücke nicht befahren. "Eine Ausnahmeregelung für unsere Winterdienstfahrzeuge, die wir in den vergangenen Jahren regelmäßig erhalten haben, wurde uns in diesem Jahr nicht mehr gewährt." Da aber keine leichteren Fahrzeuge zur Verfügung stünden, sei der Winterdienst nicht möglich. "Auf diese Problematik haben wir im Vorfeld hingewiesen."Wartet, die Brücke hat eine zulässige Maximallast von 3,5 Tonnen und die BSR-Fahrzeuge wiegen 18 Tonnen und die Regierung hat bisher einfach eine Ausnahmegenehmigung erteilt!?!?
Das ist ja wie der LKW-Fahrer, der das Höhenlimit bei einer Tunneleinfahrt ignoriert, weil er gerade keinen Polizisten in der Nähe sieht!
Mann Mann Mann
Aber seid mal nicht zu stinkig mit Frau Giffey. Die hatte wahrscheinlich gerade die Hände voll. Mit Clankriminalität.
Update: Leute mit mehr Behördenerfahrung als ich erklären mir gerade, dass "mindestens 18 Tonnen zulässiges Gesamtgewicht" nicht heißt, dass du da nicht weniger Gesamtgewicht haben kannst, wenn du weniger lädst. Aber die Vorschrift geht halt über das zulässige Gesamtgewicht, nicht über das tatsächliche Gesamtgewicht.
Die BSR hat übrigens natürlich auch leichtere Räumfahrzeuge, das sind so voll cool aussehende Mondbuggys, die normalerweise für Bürgersteige eingesetzt werden. Aber die sind dann vermutlich nicht schnell genug um die Mindestanforderungen für Autobahnbefahrung zu erfüllen.
Update: Oooooh, stellt sich raus: Die Straßenverkehrsordnung sieht Sonderrechte für die Straßenreinigung vor:
6) Fahrzeuge, die dem Bau, der Unterhaltung oder Reinigung der Straßen und Anlagen im Straßenraum oder der Müllabfuhr dienen und durch weiß-rot-weiße Warneinrichtungen gekennzeichnet sind, dürfen auf allen Straßen und Straßenteilen und auf jeder Straßenseite in jeder Richtung zu allen Zeiten fahren und halten, soweit ihr Einsatz dies erfordert
Juristisch spräche also nichts gegen den Einsatz von Mondbuggys auf der maroden Autobahnauffahrt. (Danke, Jens)
Als ich eh ran musste, hab ich auch gleich mal die ganzen Compilerwarnungen angeschaltet und mal ein bisschen aufgeräumt, und siehe da: Eine der Warnungen hat einen echten Logikbug enttarnt. Da hab ich ein Statement dupliziert und für IPv6 angepasst, aber der überliegende Kontext war ein if-Statement, und offensichtlich sollte der kopierte Teil in das if-Statement rein, war aber nicht, weil da keine Klammern waren.
In diesem Sinne: Immer schön alle Compilerwarnungen anschalten! Wer weiß, ob euch das mal den Arsch rettet.
Das hat jetzt offensichtlich keine schlimmen Auswirkungen gehabt, die jemand beobachtet hätte, denn der Patch ist ja seit vielen Jahren im Produktiveinsatz. Aber das hätte auch was ganz fieses sein können. Immer schön Compilerwarnungen auf max!
Update: Ja aber Fefe, wieso waren die Compilerwarnungen denn nicht die ganze Zeit schon auf max? Waren sie. Aber das Projekt habe ich vor Jahren zuletzt angefasst, da war der Compiler noch nicht so weit wie heute.
Die gibt er dann mit einem magischen setsockopt dem Kernel, und dann kann man mit dem Socket einfach wie früher read, write und sendfile machen und der Kernel übernimmt die symmetrische Krypto und die TLS-Paketierung.
Warum würde man das machen wollen? Nun, es gibt zwei Gründe. Erstens kann man so wieder sendfile machen. sendfile kriegt einen Socket, einen File Descriptor, ein Offset und eine Länge, und schickt dann das Segment aus der Datei über den Socket raus. Im Gegensatz zu traditionellem read und write spart das einmal eine Kopie der Daten. Das Google-Stichwort ist dann auch Zero-Copy.
Nun, zero copy macht Kernel-TLS natürlich auch nicht draus, der muss ja die Daten verschlüsseln und das macht ja auch eine Kopie. Allerdings gibt es Netzwerk-Karten, die TLS Offload beherrschen. Ich habe sowas nicht, aber es existiert, und dann kann der Kernel die Krypto direkt durchreichen an die Hardware, und kann es möglicherweise gar einrichten, dass die Netzwerkkarte sich die zu schickenden Daten direkt per DMA vom NVMe holt, oder halt aus dem RAM, ohne dass der Kernel die anfassen muss.
Naja gut, denkt ihr euch jetzt vielleicht, aber macht das wirklich so viel aus? Nicht bei Fast Ethernet und Gigabit geht auch noch ohne. Aber bei 10 und 100 GBit kriegt man die Leitungen ohne Zero Copy nicht saturiert. Und natürlich hat man mehr Ressourcen für andere Arbeit auf dem Server, je weniger man mit sinnlosem Hin- und Herkopieren von Daten verbraucht.
gatling habe ich damals explizit mit dem Ziel geschrieben, mich mal in Zero-Copy-TCP einzuarbeiten, aber das ist mit TLS erstmal wertlos. Bis jetzt.
Zu meiner großen Freude unterstützt OpenSSL seit Version 3 das zumindest auf dem Papier. Allerdings konnte ich das nicht funktionieren sehen. Heute habe ich das mal debugged. Auflösung: Die Kernelheader in /usr/include/linux waren zu alt :-)
Heute habe ich das zu Laufen gekriegt, und hatte bei wget einer 1 GB-Datei über das Loopback-Device sowas wie 1 GB/sec Durchsatz.
Das war mit dem alten TLS-Code, der mmap+SSL_write machte. Da hat man dann kein sendfile. Daher hat OpenSSL 3 eine Funktion namens SSL_sendfile nachgereicht. Die konnte man in meiner Abstraktion in libowfat nicht benutzen, daher hab ich die heute ein bisschen erweitert und dann in gatling per Callback SSL_sendfile eingebaut, und dann hatte ich im selben Test 1,9 GB/sec Durchsatz.
Fand ich sehr beeindruckend, muss ich euch sagen. Schön zu sehen, dass sich die Technologie auch ein bisschen weiterentwickelt.
In der Praxis wird das bei meinem Blog oder so nicht viel bewirken, weil der Großteil der CPU-Zeit da für das Handshake draufgeht, nicht für die symmetrische Krypto. Trotzdem. Hocherfreulich, wenn in der IT mal was schneller wird, und nicht immer nur langsamer und bloatiger.
Update: Richtig konsequent zuende getrieben hat das Netflix, wobei die allerdings FreeBSD und nicht Linux verwenden. Die haben dazu einen ziemlich sehenswerten Vortrag gehalten: Folien, Video.
Update: Oh und natürlich hilft Kernel-TLS mit Offloading auch auf schwachbrüstigen Embedded-SOCs, die auf Kosten- und Stromsparen ausgelegt werden, nicht auf CPU-Power.
Wegen, äh, *papierraschel* zu wenig Nachfrage.
Die User so: Das war hinter einem Experimental-Switch, von dessen Existenz der Normaluser nichts wusste.
Ja aber Fefe, wieso interessierst du dich denn für Chromium? Du benutzt doch Firefox! Nun ja, immer wenn Chrome etwas verkackt, verkackt Firefox es noch krasser. Bei Firefox gibt es auch JPEG XL, aber es ist auch hinter einen Experimental-Switch, von dem die meisten Leute nichts wissen, und jetzt der Teil, den Firefox noch krasser verkackt als Chrome: Den anzumachen hilft nicht. Man muss auch die Nightly-Version von Firefox einsetzen. Die Normal-Version hat den Switch aber er bewirkt nichts.
Ach naja, wer braucht denn JPEG XL, es gibt doch noch AVIF und HEIC!
Ja schon, aber HEIC kann kein Browser und AVIF wird zwar weitgehender unterstützt aber es wo man ein 1080p JPEG nach JPEG XL in einer Sekunde umwandeln kann, braucht AVIF eher so eine Minute (natürlich je nach Hardware, die man drauf wirft).
In diesem Sinne war JPEG XL tatsächlich der Hoffnungsträger. Der klare Gewinner unter den Formaten. HEIC hat auch noch ein Patentproblem übrigens.
HEIC kommt von der Patentmafia, JPEG XL kommt von den Leuten hinter JPEG, und AVIF kommt von Google.
Wir haben hier also mal wieder einen klaren Fall von Monopolmissbrauch. Wisst ihr, was wir mal bräuchten? Eine Behörde, die sowas verhindert! Ihr wisst schon, sowas wie die Inder haben.
In a labyrinthine case, Mitsotakis' center-right government admits that the intelligence service conducted this legal wiretapping, but is denying any involvement with what it calls separate illegal cases, in which Androulakis and journalists were bugged with spy software called Predator.Nein, nein, Herr Richter, das war ein völlig anderer illegaler Abhörskandal mit den Journalisten!!1!OK, äh, das überzeugt jetzt noch nicht auf Anhieb, die Ausrede. Was hat er denn sonst so vorzubringen?
“I'm well aware that there are interests that want weak governments, because they believe that this increases their ability to exert influence,” he said. He added that everyone should calm down because Greece's neighbors, referring to Turkey, “remain unpredictable.”Nichts. Er hat nichts zu seiner Verteidigung vorzubringen.Oh warte, doch, eine Sache bringt er vor:
Mitsotakis defended the workings of the country’s national intelligence service (EYP), saying its operations were essential to the country’s security, despite the misstep of tapping an opposition leader's phone, in what he said was a legal but "politically unacceptable" operation.Und das ist der eigentliche Skandal, nicht nur in Griechenland. Es war legal.
Die Go Leute können mal schön kacken gehen, und endlich mal SHA1 abschaffen, bevor sie mir was über post-quantum erzählen.Ich für meinen Teil würde eh empfehlen, grundsätzlich von RSA auf Ed25519 umzusteigen bei SSH. Das aktuelle SSH macht außerdem auch noch einen Post-Quantum-Keyexchange oben drüber.Go Cypto sind ganz spezielle Saboteure, die uns seit einem dreiviertel Jahr zwingen, RSA nur mit SHA1 (bekanntermaßen broken) einsetzen zu können, weil RSA-SHA2-256 und RSA-SHA2-512 bzw deren negotiation in Go kaputt sind.
Du updatest also deine Workstation auf eine aktuelle openssh Version, die SHA1 deprecated, und dann kannst du nicht mehr von deinen git repos auf self-hosted Gitea pullen. Keyexchange failed weil Go Crypto (Gitea ist in Go geschrieben) kein RFC-8303 kann.
Dann musst du erstmal SHA-deprecation an deinem client ausschalten, damit du wieder an dein git kommst.
Und mit dem Workaround gammelt SHA1 weiter vor sich hin.
Auf der einen Seite will ich nicht nur schreiben, wie kaputt alles ist. Auf der anderen Seite will ich aber auch nicht dafür sorgen, dass Leute länger bei Windows bleiben, weil sie dank irgendwelcher Konfigurationsratschläge den Eindruck haben, sie könnten das schon irgendwie absichern. Zu guter Letzt bin ich Code Auditor, nicht Admin. Was man da alles konfigurieren kann ist nicht mein Spezialgebiet. Am Ende verbreite ich noch Unfug?
Daher haben meine Zero-Trust-Folien am Ende eine eher allgemeine Vision.
Allerdings kam ein Leserbrief mit konkreten Ratschlägen rein, den ich jetzt mal veröffentlichen möchte. Nehmt das aber bitte nicht als abzuarbeitendes Howto sondern als Grundlage für eigene Recherchen. Ziel der Übung sollte sein, dass ihr ein bisschen mehr verstanden habt, wie die Dinge funktionieren.
zu deiner Zero Trust Präsi möchte ich mal etwas zur Windows Security einwerfen. Sorry, ist etwas länglich geworden.Anmerkung von mir: Die ct hatte dazu mal ein Tool veröffentlicht, da könnt ihr damit mal herumspielen.Wir sind IT Dienstleister und übernehmen in der Regel den Service einer bestehenden IT Landschaft die entweder vorher durch den Kunden oder durch einen anderen Dienstleister betreut wurde. KMU 1 bis 500 MA.
Dahin zu gehen und den Kunden Windows und Outlook wegzunehmen wird in der Regel nicht gelingen. Wenn es möglich ist einen neuen Server auf Linux hoch zu ziehen könnte man das vorschlagen und umsetzen, da hört es aber dann auch schon auf.Der Satz "Das geht, weil Sie Outlook und Office benutzen" stimmt leider in den meisten Fällen, obwohl das nicht so sein müsste.
MS liefert schon seit Windows 2000 allerhand Techniken mit die genau das alles verhindern. Wir haben aber noch nicht einen Kunden bekommen bei dem irgendwas davon aktiv war und holen das alles schleunigst nach. Das schlimmste was uns als Dienstleister passieren kann, ist ein Ransomwarebefall eines Kunden bei dem wir die Schuld tragen, weil deren Systeme nicht sicher sind, obwohl man es *ohne* Anschaffung zusätzlicher Software hätte besser machen können. Der Kunde verlässt sich darauf dass wir ihm eine sichere Arbeitsumgebung geben. Es ist ein Unding, dass ein aktueller Windows Server bei einer frischen Active Directory Installation immer noch fast die gleichen Sicherheitsdefaults verwendet wie es in 2000 eingeführt wurde und so kommt es, dass von all dem was nun kommt in freier Wildbahn oft nichts zu sehen ist.1: Software Restriction Policies (SRP), ja ich weiß ist deprecated, läuft aber selbst auf Win 11 noch. MS wollte das durch Applocker ersetzen. Ist aber auch deprecated. MS will das durch Defender Application Control ersetzen, geht aber nur per XML oder und nur in Enterprise oder so. Wir bleiben bisher bei SRP, weil das keine Enterprise Lizenzen braucht und seit Win 2000 unverändert läuft. Muss man halt nach jedem größerem Update testen ob es noch geht.
Was tut es? Windows führt nur noch EXE, CMD/BAT, PS1, sonstwas aus Pfaden aus die der Admin per GPO festgelegt hat. Outlook kopiert den Anhang aus der Mail in ein Temp Verzeichnis und will es dort starten. Das darf es dann nicht mehr. Admins installieren nach c:\program files\. Das ist erlaubt. Ein User darf da nicht schreiben.GPO ist ein Group Policy Object, oder in deutschen Versionen: Gruppenrichtlinien.
MS torpediert es aber selbst mit Programmen die sich unter AppData\Local installieren. Teams z.B. und andere Hersteller sind da auch keine Vorbilder. Muss man sehr enge Ausnahmen setzen und das Risiko in kauf nehmen.2: Makros. Ja, der gelbe Balken bringt nix. Per GPO hart ganz abschalten. Brauchen ohnehin die wenigsten Anwender. Die die es brauchen, kann man geziehlt auf die Dokumente einschränken für die es gehen soll. Was machen die Malware Makros? VBS oder Powershell Script ausführen und Payload nachladen und starten. Geht eigentlich durch SRP schon nicht mehr, aber es soll ja Bugs geben die vielleicht um SRP drum rum kommen.
3: Beschafft sich lokale Admin-Rechte und übernimmt den Domain Controller.In meinen Folien hatte ich gesagt, dass Lateral Movement nicht Teil des Threat Models ist. Ich bin mir unsicher, inwieweit man das verallgemeinern kann. Ich unterhalte mich zu Ransomware mit Kumpels, die weiter oben auf der Eskalationsskala sitzen, die sehen dann praktisch ausschließlich Fälle, bei denen der AD übernommen werden konnte. Ich habe leider keine Zahlen, wie hoch der Prozentsatz der Ransomware-Angriffe ist, die man verhindern könnte, wenn man Lateral Movement unterbindet. ALLERDINGS: Wenn man durch andere Maßnahmen dafür sorgt, dass der Sprung zum Domain Admin nicht geht, dann wird die Verhinderung von Lateral Movement plötzlich eine wichtige Maßnahme. Genau das spricht der Leserbrief hier an.
Wenn 1 und 2 versagt hat kommen wir dahin. Nächste Verteidigungslinie ist Lateral Movement zu verhindern.Es gibt genug GPOs zum härten der Systeme, aber man klemmt halt damit alten Legacy ab, was ich aus technischen Sicht eigentlich ganz gut finde. NTLM Auth weg, Credential Caching für Admins und generell Server abschalten, Debugging Rechte global abschalten und nur im Einzelfall erlauben. LAPS benutzen, auch für Server. Das macht es Mimikatz schon ganz schön schwer an verwertbare Daten zu kommen.
Mit ESAE hat MS schon lang ein Konzept die Admin Ebenen voneinander zu trennen. Man muss auch nicht zwingend mehrere Domänen betreiben um den wichtigsten Teil davon umzusetzen.Ich hab das in einem Nebensatz irgendwo erwähnt, dass man die Admin-Accounts aufteilen soll, und dass der Domain Admin nicht an die Datenbanken können soll. Der Leser hier hat völlig Recht, das kann und sollte man noch mehr auftrennen. Dann hat man tatsächlich etwas getan, um im Threat Model ein Bedrohungsrisiko zu senken.
Bei uns darf ein Domain Admin nicht mal PCs in Domänen aufnehmen. Niemals sollte sich ein Domain Admin an einem Client anmelden und das lässt sich auch per GPO verhindern.
Der darf auch nur an Domain Controller, die CA und ähnliche Systeme. Ein Server Admin darf da nicht hin und der darf auch nicht an Clients. Ja, der Domain Admin hat dann halt 4 User Accounts. User, Client Admin, Server Admin, Domain Admin. Natürlich mit Grundverschiedenen Passwörtern. Kommt man mit klar.
Selbst ein Keylogger auf dem Client bekommt dann höchstens den Admin für die Clients, aber kann immer noch nicht auf Server oder gar Domain Controller.Dazu sei angemerkt, dass auch mit Smart Cards im Hintergrund immer noch Kerberos läuft mit Kerberos-Tickets, die abgreifbar sind. Aber die laufen wenigstens nach einer Weile aus.4. Benutz Smart Cards für die Admins und lass nur Anmeldungen per Smart Card zu. In dem Fall kann ein Keylogger auf dem PC auch das Kennwort nicht einfach mal mitlesen.
USB Smart Cards sind nicht teuer. Die Menge an Admins überschaubar.
Für RDP gibt es dann noch den Restricted Admin Mode mit entsprechenden Komforteinbußen.
In Enterprise Editionen noch Credential Guard, usw.
5. Exchange kann Split Permissions. Nutzt das. Es entfernt die Berechtigungen dass der Exchange Server Domain Admin Rechte hat. HAFNIUM war damit nur halb so schlimm.Für die BMC und Hypervisoren würde ich dringend zu physisch getrennter Verkabelung raten, statt zu irgendwelchen Software-Geschichten.
Server müssen auch nicht überall ins Internet dürfen. Verhindert dass Malware auf euren Servern ganz bequem per HTTPS ihren Payload laden können.Erweitert das noch mit VLANs und Firewalls. Kein Anwender muss auf die ESXi Infrastruktur, einen Switch oder das BMC vom Server. Die müssen auch auf die wenigsten Ports für die Anwendungsserver. Da reichen oft ACLs auf dem Core Switch um zumindest bei Line Speed zu bleiben.
Backupserver aus der AD nehmen. Per Firewall/ACL einschränken, dass der an die Server darf, aber die Server nicht zum Backupsserver.Das ist ein guter Ratschlag!
All diese Dinge die ich beschrieben habe gehen mit Bordmitteln. Da ist nicht ein Anti-Virus, SIEM oder sonst eine 3rd Party Lösung beteiligt.Nur ein Nachsatz noch von mir: Der Feind ist Komplexität. Es ist zwar schön, dass man bei Microsoft eine Menge konfigurieren kann, so dass es weniger schlimm ist, aber am Ende des Tages überblickt niemand mehr den ganzen Softwarehaufen, und alle sind nur an der Oberfläche am Herumkratzen. Das betrifft glücklicherweise auch die meisten Angreifer. Wirklich sicher fühlen würde ich mich da nicht. Und wenn man erstmal diese Art von Knowhow aufgebaut hat, dann wird man wahrscheinlich nie wieder von Windows wegmigrieren wollen.
Wir setzen das meiste davon bei Firmen ein die keine 10 Mitarbeiter haben. Das kann man mit Routine an einem Tag umsetzen. (Den Windows Teil zumindest) Testet das selbst mit Mimikatz, Bloodhound und was auch immer. Hackt euch selbst und danach oder wenn ihr das generell nicht könnt, holt euch noch einen Pen Tester um die offensichlichen Lücken weg zu machen.Am Rande: Domain Joined Device Public Key Authentication muss man nicht einschalten. Das ist per Default an. Man muss es aber erzwingen wenn man das Fallback nicht haben will. Ist fast das gleiche, aber doch nicht ganz und geht erst mit Server 2016.
Am weiteren Rande: Patchmanagement. Es wäre schön, wenn MS nicht Patches raus bringen würden die großflächig zu Boot Loops auf Domain Controllern, Druckproblemen oder 802.1X/802.11X Problemen führen würden. Dann hätte man auch mit Auto-Updates weniger schmerzen. So muss man eigentlich schon zwangsweise ein paar Tage warten, wenn man nicht vor einem Totalausfall am nächsten Tag stehen möchte. Beides verfahren sind somit schlecht.
Ich gehe nicht davon aus das danach das System unhackbar sicher ist. Wir sprechen hier immer noch von Software und von Microsoft, aber zumindest hat man etwas in die richtige Richtung getan und die offenlichtlichen Scheunentore geschlossen.
Wer nun mit dem erhöhten Supportaufwand argumentiert, dem sei gesagt dass er bei uns gesunken ist, weil die Anwender eben nicht mehr alles ausführen können was bei 3 nicht auf den Bäumen ist und die Computer dadurch so bleiben wie der Admin es sich mal vorgestellt hat.
Entwicklungsabteilungen können zusätzlich Nicht-Domain Computer oder VMs bekommen um ihre systemnahe Arbeit durchzuführen.
Aus meiner Sicht ist der Vorteil von Linux und co, dass es da keine natürliche Schranke gibt, wie viel Verständnis man von dem Gesamtsystem aufbauen kann.
Update: Einer der Gründe, wieso ich solche Tipps ungerne gebe, ist weil das alles furchtbar komplex ist, und es da immer wieder Untiefen gibt, die man halt nicht kennt, wenn man nicht nach ihnen sucht. SRP und UAC sind da exzellende Beispiele für. Seufz. Siehe auch hier und hier.
Das funktioniert so:
www.evil.com kann natürlich kein TLS-Zertifikat für mein Blog vorweisen, insofern argumentiert Mozilla jetzt, das sei gar kein Bug.
Haha! Super luschtig! Bis euch auffällt, dass der Hersteller das Feature nicht für den Ukrainekrieg programiert haben wird, sondern gegen reguläre Bauern. Das ist DRM. Wenn die das mit den Russen machen können, können sie das auch mit euch machen. Da ist nichts lustig dran. Das ist eine fucking Dystopie!
Cory Doctorow hat den Finger in der Wunde.
Money Quote 1:
Why are John Deere tractors kill-switched in the first place?Here’s a hint: the technology was not invented to thwart Russian looters.
No, it was invented to thwart American farmers.
Mir ist ja absolut unklar, wieso irgendjemand irgendwo auf der Welt irgendwas von dieser Firma kaufen würde. Das ist nun seit langer Zeit bekannt, wie die ticken. Als die einmal versehentlich eine Debug-Firmware geliefert haben — ironischerweise in die Ukraine! —, hat sich ein weltweiter Schwarzmarkt für Kopien dieser Firmware gebildet. Wie viele rote Warnlampen brauchen die Farmer, bevor sie bei einer solchen Firma nicht mehr kaufen?!Aber Cory Doctorow geht weiter. Wieso haben die überhaupt einen Netzwerk-Zugang, fragt er? Er gibt auch gleich die Antwort: Weil die die Bauern totalüberwachen und die Daten abschnorcheln und das ist die eigentliche Cash Cow bei denen. Money Quote 2:
In the 2017 edition of these exemption hearings, John Deere filed a stunning brief with the Copyright Office: in it, they explained that farmers do not own the tractors they spend hundreds of thousands of dollars on.In fact, the farmers can’t own these tractors, because the software that animates these tractors (and enforces VIN locks and restrictions on using your own data) belongs to John Deere for the full term of copyright — 90 years — and the farmers merely license that code, and they are bound by the terms of service they have to click “OK” on every time they switch on their ignitions.
Those terms specify that even if a farmer repairs their own tractor, swapping a broken part for a working one, they must pay hundreds of dollars and wait for days for an authorized Deere technician to come out to the end of their lonely country road to key in an unlock code.
This is the system that let the Ukrainian Deere dealership brick those tractors between Melitopol and Chechnya.
So sieht das nämlich aus.Willkommen in der Dystopie.
Update: Lacher am Rande: "Aber Fefe, kann man da nicht bei der Konkurrenz kaufen?" Nee, die steht gerade wegen Ransomwarebefall still.
Der einmal rumlaufen und überall zlib updaten-Tag!
Fix a deflate bug when using the Z_FIXED strategy that can result in out-of-bound accesses.Schreibzugriffe. Und das geht auch ohne Z_FIXED.Das betrifft die Kompression mit zlib, nicht die Dekompression. Trotzdem gilt wie immer: Alles updaten. Sofort. Auch wenn ihr glaubt, ihr seid nicht betroffen.
Update: Wenn ihr Software herstellt, dann geht mal bitte in Ruhe durch alles sorgfältig durch. zlib wird gerne mal von wohnmeinenden Pfuschern statisch reinkompiliert. Bei Firefox, der Qualitätssoftware aus dem Hause Mozilla, sind beispielsweise direkt zwei Kopien von deflate.c im Repository. Bei gcc ist auch ein deflate.c dabei. Im Linux-Kernel ist auch ein deflate.c im Tree. Seufz. Das wird ein Blutbad, das alles zu updaten.
Update: zlib ist in Browsern, in allen Programmen, die mit PNG umgehen, in allen Programmen, die mit ZIP-Dateien umgehen, auch versteckt wie Office oder Java, ... zlib ist eine der am häufigsten verwendeten Bibliotheken. Kernelmodule werden gerne mit zlib komprimiert, Man Pages, das ist auch sonst in irgendwelchen Dateiformaten implizit drin. Einmal alle Skriptsprachen. Das ist echt Worst Case in Sachen Abhängigkeitshölle, wenn in zlib was kaputt ist.
Hat sich da bei OpenSSL 3.0.1 was am API geändert, das ich übersehen habe?
Update: Ah nee, war nichts mit OpenSSL. War meine eigene Schuld :-)
Blue Screen, my ass! Diese Zeiten sollten überwunden sein!
Aber fürchtet euch nicht. Abhilfe ist in Sicht. Apple hat jetzt einen Pink Screen.
Der Standard-Linker unter Linux ist GNU ld von den binutils. Das ist ein uraltes Fossil von einer Codebasis, weil die eben nicht das konkrete Problem gelöst haben, sondern ein allgemeineres Problem lösen. Der Linker ist parametrisierbar und kann zur Compilezeit mitgeteilt kriegen, ob man ELF, COFF oder gar Windows EXE Files damit linken will. Kann glaube ich auch MACH-O von Apple, bin mir aber nicht sicher gerade.
Jedenfalls ist das Teil schnarchlangsam. Spielt in den meisten Fällen keine Rolle. Ich hab damit jahrzehntelang prima arbeiten können, ohne dass mir jemals aufgefallen wäre, wie langsam das Teil ist. Meine Programme sind aber auch alle relativ überschaubar.
Wenn man mal, sagen wir, Firefox linkt, dann ist die Link-Pause merkbar. Spielt im Vergleich zur Compilezeit keine Rolle, aber ist nicht gar nicht da.
Also haben sich über die Jahre Projekte gegründet, um mal einen schnelleren Linker zu bauen. Der erste, den ich gesehen habe, ist GNU gold, der ist auch Teil von den binutils. Ist in C++ geschrieben und direkt ... doppelt so groß wie ld. War zwar ein bisschen schneller aber linkte bei mir mal Firefox nicht und konnte auch kein link-time optimization und war daher direkt draußen.
Das nächste Projekt, das antrat, war LLVM lld. Der hat erstmals ein bisschen Multithreading am Start, aber nur für einige Teile. mold will jetzt alle Teile auf alle Cores verteilen.
Ich habe mal testweise das Erstellen von libavcodec.so gemessen:
GNU ld: 1.21s user 0.26s system 99% cpu 1.463 totalDas war jeweils noch mit Debug-Symbolen. Gut, unterhalb einer Sekunde ist das jetzt alles nicht sonderlich aussagekräftig, und die %CPU-Spalte bei mold ist offenbar damit überfordert, wie flott das Ding fertig war :-)
GNU gold: 0.83s user 0.10s system 99% cpu 0.928 total
LLVM lld: 0.69s user 0.17s system 258% cpu 0.333 total
mold: 0.03s user 0.00s system 13% cpu 0.247 total
Aber ich finde das ein interessantes Ergebnis und wollte direkt mal dietlibc damit linken, um zu gucken, ob das geht. Ging nicht, weil ich eine obskure Spezialoption von GNU ld benutze, -z noseparate-code. ld hat vor ein paar Jahren angefangen, nach SPECTRE bei den Segmenten Padding auf Page-Größe zu machen. Hintergrund ist, dass die Hardware Speicherschutz mit Page-Granularität macht. Wenn also in einem Binary Code und Datensegment nebeneinander im Binary liegen, dann war früher auf der letzten Page des Datensegmentes (das read-write gemappt ist!) auch die ersten Bytes des Codesegments, und man hätte da also reinschreiben können in einem Exploit oder so. Jetzt bläst der Linker das mit Null-Bytes auf. Ist an sich eine gute Idee, aber bei dietlibc will ich halt winzige Binaries haben. Da ist das Binary für rm sowas wie 9k groß. Wenn der Linker da Padding einfügt, dann ist das mal eben 50% größer. Daher möchte ich das bei der dietlibc gerne selektiv ausschalten können, und obiges wäre die Option dafür gewesen.
Die konnte mold nicht. Also hab ich vor zwei Tagen einen Bug aufgemacht. Heute war die Mail in der Inbox, dass er das eingebaut hat.
Ich muss sagen: Hut ab. So stellt man sich das in seinen Fieberträumen vor, dass Software-Entwicklung so abläuft. Erstens natürlich dass der Typ überhaupt reagiert, dann dass er mir nicht erklärt, meine Anforderung sei Scheiße, dann dass er das implementiert, und dann dass er das quasi über Nacht implementiert. Sehr beeindruckend.
Ich wünsche euch allen, dass ihr eure Codebasen auch so in Schuss habt, dass ihr auf so eine Anforderung mal eben so flott reagieren könntet. :-)
mold hat bei mir jetzt auf jeden Fall mehrere Schritte auf der Treppe genommen.
Update: Äh, jetzt habe ich den Link vergessen. Ist auf Github. Hat m.W. keine separate Homepage.
Threat Intelligence, falls das hier jemandem nichts sagt, ist der Austausch von "bösen IPs", von denen aus angeblich Angriffe kommen. Ja, richtig gelesen. Ihr macht nicht etwa eure Systeme sicher. Nein, nein! Ihr macht lieber Cyber Identity Politics und nehmt keine Verbindungen mehr aus Himmelsrichtungen an, die einem Kumpel schonmal negativ aufgefallen sind.
Ich lache ja diese ganze Threat Intelligence-Nummer seit Jahren aus. Was für eine monumentale Geldverbrennung.
Aber stellt sich raus: Zwei Dinge sind unendlich, und es finden sich nicht nur Käufer für diesen Mist, die argumentieren dann auch mit den abgewiesenen Verbindungen, als ob das Angriffe gewesen wären. "Diesen Monat: 10 Mio Angriffe abgewehrt!1!!"
Eher 1 Mio Kunden abgewehrt, und 9 Mio Spammer und Hintergrundrauschen.
Jetzt kommen auch noch Bugs dazu:
Microsoft warned customers today to patch two Active Directory domain service privilege escalation security flaws that, when combined, allow attackers to easily takeover Windows domains.Ach. Ach was. Na sowas.Das liest sich ja fast, als seien Windows + Office + Active Directory grundsätzlich ein hohes Risiko!!1!
Aber keine Sorge, ihr müsst einfach diese Patches hier bei Vollmond über eure Server sprenkeln, und ab dann werdet ihr wieder über triviale Fehlkonfigurationen hopsgenommen statt über Bugs.
Habt ihr schön gepatcht? Oder habt ihr diese eine Konfig-Änderung eingespielt, die rumging?
Nach der Vuln ist vor der Vuln!
It was found that the fix to address CVE-2021-44228 in Apache Log4j 2.15.0 was incomplete in certain non-default configurations. [...] Note that previous mitigations involving configuration such as to set the system property `log4j2.noFormatMsgLookup` to `true` do NOT mitigate this specific vulnerability.Gutes Zeichen, wenn die Leute, die den Code gerade warten, nicht in der Lage sind, einen weltweit Katastrophenalarme auslösenden Bug im ersten Anlauf zu fixen. Was sagt euch das über die Komplexität und Wartbarkeit des Codes? Seid ihr sicher, dass ihr da nicht lieber komplett drauf verzichten wollt?Oh, ich vergaß. Könnt ihr gar nicht. "Geht gar nicht mehr". Habe ich gehört. Von Java- und Javascript-Leuten. Komischerweise geht das bei anderen Sprachen wunderbar.
Und überhaupt: Diese Art von "den Bug kann man nicht debuggen" kennt man sonst nur von Programmiersprachen mit Speicherkorruption. Ihr wisst schon, die Art von Programmiersprache, über die sich Java-Leute gerne lustig machen.
On 4 November, Romanian authorities arrested two individuals suspected of cyber-attacks deploying the Sodinokibi/REvil ransomware. They are allegedly responsible for 5 000 infections, which in total pocketed half a million euros in ransom payments.Ransomware ist so gut wie besiegt!Wie die wohl reingekomemn sind? Über "unintentional debugging credentials" vielleicht?
Nein, nein, keine Sorge. Diesmal waren es keine hartkodierten Backdoor-Passwörter. Diesmal waren es "unintentional debugging credentials". Das ist was GANZ anderes!!1!
Diesmal war es keine Absicht!1!!
So glaubt uns doch!
Oh, warte, das war noch nicht alles!
The other critical hole is CVE-2021-40113, which can be exploited by an unauthenticated remote attacker to perform a command injection attack on the equipment's web-based management portal, thanks to insufficient validation of user-supplied input.Einmal mit Profis!"A successful exploit could allow the attacker to execute arbitrary commands on an affected device as the root user."Was macht die Security-Abteilung bei Cisco eigentlich beruflich?
About $162 million is up for grabs after an upgrade gone very wrong, according to Robert Leshner, founder of Compound Labs.DeFi, wir erinnern uns, ist das Rebranding von Cryptocurrencies, nachdem den ersten potentiellen Opfern aufgefallen ist, dass die Szene vor allem aus Blendern und Scammern zu bestehen scheint.Hey, da willste doch dein Geld investieren!!1!
Wollte ich eigentlich nicht ins Blog tun, weil ich die nicht zu Infrastruktur zählen wollte. Aber irgendwie ist das auch nichts, das gar nicht zu erwähnen.
Vielleicht brauchen wir eine neue Kategorie für sowas. Unterdrückungsinfrastrukturapokalyse oder so.
Update: Wir sollten mal einen Wettpool eröffnen, ob Facebook genug Arsch in der Hose hat, einen ordentlichen Postmortem zu veröffentlichen.
Update: Mir mailte jemand, dass gestern sein Huawei-Telefon warnte, dass das Internet nicht geht. Das Internet ging, aber Facebook ging nicht.
Update: Facebook hat ein Postmortem veröffentlicht. Sie sagen, ein Admin habe auf einem Router auf dem Backbone zwischen ihren Rechenzentren ein Kommando gefatfingert, was den gesamten Backbone runterfuhr. Money Quote:
Our systems are designed to audit commands like these to prevent mistakes like this, but a bug in that audit tool didn’t properly stop the command.
Das klingt ein bisschen konfus, denn Auditing heißt normalerweise, dass man ein Log der Befehle führt, nicht dass man irgendwas stoppt. Aber egal. Sie haben DNS-Server, die über ihren Backbone mit den autoritativen DNS-Servern für Facebook reden, und die über BGP announced werden. Anycast vermute ich? Jedenfalls haben sie da einen Fail-Beschleuniger eingebaut, dass wenn der DNS-Server den autoritativen DNS-Backend-Server nicht erreichen kann, dass er dann aufhört, sich über BGP zu announcen. Das führte dann dazu, dass Facebook nicht mehr per DNS erreichbar war, obwohl die Server selbst eigentlich noch liefen. Money Quote:
And as our engineers worked to figure out what was happening and why, they faced two large obstacles: first, it was not possible to access our data centers through our normal means because their networks were down, and second, the total loss of DNS broke many of the internal tools we’d normally use to investigate and resolve outages like this.
Mit anderen Worten: Das Szenario hat bei denen noch nie jemand mal durchgespielt. Aber wartet, kein Problem ist so schlimm, dass man es nicht mit wohlgemeinten Security-Barrieren noch schlimmer machen könnte. Sie haben also Ingenieure zu den Rechenzentren geschickt.
But this took time, because these facilities are designed with high levels of physical and system security in mind. They’re hard to get into, and once you’re inside, the hardware and routers are designed to be difficult to modify even when you have physical access to them. So it took extra time to activate the secure access protocols needed to get people onsite and able to work on the servers. Only then could we confirm the issue and bring our backbone back online.
Gestern ging schon der Witz herum, dass dringend Leute mit fünf Jahren Erfahrung in PHP, C++ und Seitenschneidern gesucht würden. :-)
Alles in allem bin ich mit dem Postmortem zufrieden. So muss das aussehen. Wirkt für mich nicht so, als hätten sie irgendwas zu beschönigen versucht. Lessons learned. So wie das sein muss.
Gucken wir doch mal, was der so zu sagen hat. Transkript ist von mir und kann Fehler beinhalten. Checkt lieber die verlinkte Quelle als mein Transkript.
Da haben wir ein weiteres Ereignis, das will ich kurz schildern, weil ich glaube geheim ist das nicht. In Äthiopien sind ... Äthiopien ist die Heimat von Tedros, wohlgemerkt, ne, der wegen Völkermordes gesucht wird ... und der ist der Chef der WHO.An dieser Stelle entgleitet dem Interviewer ein bisschen die Zurückhaltung und er fazialpalmiert im Hintergrund.In Äthiopien sind wohl 5 Millionen Kinder faktisch verkauft worden. Gelder, wohl über den World Monetary Fund, werden dem Land gegeben, aber nur als Gegenleistung dafür, dass die Kinder sich auf einem besonderen Training unterziehen lassen. Warte mal, ich hab hier *kramt herum* die, äh, Bezeichnung. Das nennt sich ... was da passiert mit den Kindern, nennt sich Impact Investment.
Also das Training ist Google Goggles ... also nicht Google aber irgendwelche Goggles haben die auf, also so Brillen, werden da mit blauem Licht beschienen. Blaues Licht! Und das soll dann zu einer besonderen Form des Lernens führen. Die werden dann geblockchaint. Fünf Millionen Kinder. Geblockchaint. Äh. Gechaint. Da wird das pineal gland, ich glaub das heißt deutsch Zirbeldrüse, mit diesem blauen Licht beschienen. Das soll ziemlich böse Folgen haben!
Aber offiziell soll das die Kinder dazu bringen, dass sie wesentlich lernfähiger sind.
So und jetzt kann man sich dann über Goldman Sachs, sind das, die das alles machen, kann man dann sagen: So ich wette jetzt auf die 20000 oder auf die 100000, so wie Put und Call Optionen im Finanzgeschäft. Call heißt ich wette darauf, dass die ihr Lernziel erreichen. Wenn das dann passt, dann kriege ich Geld dafür. Put sagt, nee, die schaffens nicht. Dann krieg ich Geld, wenn sie das Lernziel nicht erreichen.
Am Ende soll das Training aber dazu führen, dieses Lernen, dass sie in der Lage sind, selber zu programmieren. Auch im transhumanistischen Bereich zu programmieren.
Das bringste natürlich nur fertig, wenn du keine Empathie mehr hast. Das könnte sein, dass das das Ziel dieser Aktion ist.Ein Glück, dass das mal jemand erklärt hat!Jedenfalls das wird auch Bestandteil dieser Class Action sein. Das wird wie gesagt eine internationale Class Action, und man kann es nicht deutlich genug wiederholen: Wenn eine solche Class Action, auch wenn es "nur" für Kinder ist, durchkommt, und die dann Schadensersatz kriegen, dann kriegt jeder andere auch Schadensersatz, weil die Ursache ist immer dieselbe, nämlich der Drosten-PCR-Test.
Da lag ich ja an einigen Punkten völlig daneben!!
.oO( Und dann macht Drosten mit dem Papst in Wuppertal eine Herrenboutique auf! )
“You are in our prayers today. We are grateful for your support and prayer. When situations arise where individuals might not have honorable intentions, I pray for them,” Monster added. “I believe that what the enemy intends for evil, God invariably transforms into good.”Wer ist EPIK? Nie gehört?Nun, das ist einer dieser schleimigen "Free Speech"-Hoster in den USA, der den Stein anbietet, unter dem sich die ganzen Reichsbürger, Antivaxxer, QAnons und Trumpisten verkriechen können.
Deren Dienstleistung ist im Wesentlichen, dass sie den echten Namen der Domain-Eigentümer nicht verraten.
Jetzt sind sie aber gehackt worden, und die Ergebnisse sind ... naja, sagen wir so. Diese Art von Digitalisierungskompetenz würde man ansonsten bei der CDU vermuten.
“They are fully compromised end-to-end,” they said. “Maybe the worst I’ve ever seen in my 20-year career.”The engineer pointed the Daily Dot to what they described as Epik’s “entire primary database,” which contains hosting account usernames and passwords, SSH keys, and even some credit card numbers—all stored in plaintext.
Ach naja komm, cancelst du halt die Kreditkarte und erzeugst neue SSH-Keys!The data also includes Auth-Codes, passcodes that are needed to transfer a domain name between registrars. The engineer stated that with all the data in the leak, which also included admin passwords for WordPress logins, any attacker could easily take over the websites of countless Epik customers.Äh, ja, ... das ist schon ein größeres Problem für Epik-Kunden.Der ganze Datenreichtum bereichert jetzt als Torrent-Datei das Internet.
Gut, viel mehr als Beten und auf eine göttliche Intervention hoffen bleibt dem CEO da jetzt auch gar nicht.
Mich belustigt ja die Ironie, dass die Deppen, die bei Covid lieber an einen unsichtbaren Mann im Himmel als an die Wissenschaft glauben, dass die dann bei einem Typen hosten, der auch lieber an einen unsichtbaren Mann im Himmel glaubt als an ordentliche Arbeit.
Die Einzigen in diesem ganzen Kuhfladen, die an ordentliche Arbeit glauben, sind die Zahlungsdienstleister :-)
Aber aber aber da haben doch die ganzen superschlauen Google-Ingenieure dran gearbeitet!!1!
Stellt sich raus: Komplexität verursacht Bugs. Völlig überraschend, seit es in den 1970er Jahren herausgefunden wurde.
–CVE-2021-33742, a remote code execution bug in a Windows HTML component.Und was tut es noch? Es gibt dir im Taskbar eine Wetteranzeige mit einer Windows HTML component.Genau mein Humor!
Sonst noch bemerkenswert:
–CVE-2021-31201, an elevation of privilege flaw in the Microsoft Enhanced Cryptographic Provider
–CVE-2021-31199, an elevation of privilege flaw in the Microsoft Enhanced Cryptographic ProviderDas ist aus einer bereits in der Wildbahn angewendeten Exploit Chain. Klickst du auf die Links, kriegst du … keinerlei weiterhelfende Informationen. MSRC veröffentlicht nicht mal mehr wie früher sinnfreie Textbausteine. Da sieht man ein CVSS-Score und einen Disclaimer. Das war alles. Den Link hätten sie sich auch sparen können.Elevation of Privilege in einer Crypto-Komponente ist in meinen Augen der Totalschaden. Das ist die Art von Problem, bei der du das Rechenzentrum kontrolliert sprengst und ein neues aufbaust. Das ist die eine Komponente, bei der man annehmen würde, dass die mit Sorgfalt entwickelt, ordentlich getestet, zu Tode auditiert und zuverlässig ist. Die hat EINE Aufgabe: Elevation of Privilege verhindern. Das ist die Aufgabe davon.
Ich finde es erschütternd, dass das jetzt so als Fußnote einer Randnotiz vorbeisegelt.
Update: Achtet mal darauf, was das CVSS ist für eine elevation of privilege in der zentralen krypto-komponente. CVSS geht von 1 bis 10. Diese Lücken haben ein Score von ... 5. Da sieht man mal schön anschaulich, was für ein Bullshit dieses Scoring ist. Eine 10 hätte die Lücke nur gekriegt, wenn sie direkt Code Execution erlaubt hätte. Wenn sie Code Execution in der anderen Komponente erlaubt, die sich auf diese Krypto-Komponente verlassen hat, dann ist es bloß eine 5. Ja nee, klar.
Was für Arschkrampen ey. Klar hab ich euer Trinkwasser vergiftet, aber das war für die Forschung!!1!
Der Cloudflare-Timeout gestern? Das war mein Aprilscherz.
Aber das Niveau an Paranoia unter meinen Lesern empfinde ich in diesen schweren Zeiten als sehr positiv. :-)
Und keine Sorge. Ich habe keinen von euch tatsächlich zu Cloudflare geschickt, auch nicht für Ressourcen auf der Timeout-Seite.
Sie sind ja auch in einem fetten Interessenkonflikt. Sie können den Leuten ja nicht beibringen, Dinge im Internet nicht mehr einfach zu glauben. Denn das ist ja deren eigenes Geschäftsmodell: Die Quelle der Wahrheit zu sein.
Ich hab mich da gerade über diesen Test der SNV aufgeregt. SNV sagt euch nichts? Klingt unseriös? Nach Neue Soziale Marktwirtschaft? Ein weiteres Industrie-U-Boot? Guckt selbst. Ist nicht ganz so furchtbar wie INSM aber so richtig überzeugen tut mich das nicht.
Aber eigentlich geht es mir gerade nicht darum, wer das sagt, sondern was sie sagen.
Und damit sind wir gleich doppelt auf dem Punkt, um den es mir ging, denn dieser "Test" bringt im Wesentlichen dieselben Talking Points wie man generell von Pressevertretern kriegt. Im Wesentlichen der Verweis auf Autoritäten statt auf inhaltliche Aussagen.
Ich hätte ja gesagt: Fragt euch, ob das inhaltlich plausibel ist, und wie ihr das prüfen könntet. Dann prüft es.
Die sagen: Vergesst den Inhalt. Wichtig ist, wer es sagt. Identity Politics 3.0 sozusagen.
Ja aber Fefe, fragt ihr jetzt, woran erkenne ich denn, dass eine Quelle vertrauenswürdig ist?
Der Test geht hier rein nach Äußerlichkeiten. Ist ein Banner dran, dass das Werbung ist? Dann nicht. Ist ein Banner dran, dass das Fake News ist? Dann nicht. Ist ein Banner dran, dass der Autor bei einer Firma kauft, die Geld damit macht, was er dir gerade aufschwatzen will? Dann nicht.
Kurz gesagt: Du bist ein Dummchen. Probier gar nicht erst irgendwas selbst zu verstehen. Traue lieber dem Boten. Bekannte Boten sind besser. Außer, äh, außer "bekannt" heißt "hat viele Likes / Subscriber / Follower". Äh, außer das ist jemand von uns seriösen Journalisten, da sind viele Follower gut!1!!
Das führt am Ende immer in den Ruin, solche Geschichten. Was genau ist die Bedeutung des blauen Häkchens bei Twitter? Heißt das, dass der vertrauenswürdig ist? Wer entscheidet denn, wer vertrauenswürdig ist?
Wer macht eigentlich die Fake News-Banner auf Facebook? Sind die eigentlich vertrauenswürdig? Wer entscheidet denn, wer vertrauenswürdig ist? Facebook?!
Tja und dann kommen wir beim denkwürdigen Teil mit Russia Today raus, die man laut dieses Tests aus zwei Gründen ablehnen soll: Erstens weil es ein Staatssender ist, und zweitens weil da ein Wikipedia-Banner drunter ist unter dem RT-Video, dass die vom russischen Staat finanziert werden. Ja, äh, die Deutsche Welle ist auch ein Staatssender. Bleibt als Kriterium die Wikipedia-Banner.
Wer tut die da eigentlich hin? Wikipedia ja wohl nicht, oder? Oder ist Wikipedia jetzt für die Beurteilung der Glaubwürdigkeit von Nachrichtenquellen zuständig? Die kriegen ja nicht mal bei ihren eigenen Artikel hin, für hohe Glaubwürdigkeit zu sorgen! Vergleicht mal RT und Radio Free Europe bei der Wikipedia. Fällt euch was auf?
Aber mehr als "Staatssender" und "Wikipedia-Banner" fällt denen da halt nicht ein.
Es gibt da auch noch eine Sektion, wo man Meinung von Nachrichten unterscheiden soll. Lasst mich das mal ergänzen. "RT ist doof aber ARD ist glaubwürdig" ist eine Meinung, keine Nachricht. Glaubwürdigkeit ist subjektiv. Die kriegt man nicht per Fiat sondern die muss man sich erarbeiten. Indem man propagandafreien Journalismus macht. Jahrelang.
Aber selbst dann kann es sein, dass man unterliegt. Die wesentlichen Optionen sind:
Beide haben Vor- und Nachteile. Der zweite Ansatz ist attraktiv, weil man da weiß, dass man belogen wird, aber sich zutraut, das auf seiner Seite wieder rauszurechnen. Das ist in der Praxis aber leider häufig ein Fehlschluss. Eine Schwachstelle im Menschen. Menschen, die sich in einem System aufhalten, nehmen grundsätzlich an, dass sie in der Lage sind, das System zu beurteilen und Probleme zu kompensieren.
Juristen glauben an das Rechtssystem, und dass sie wenn es hart auf hart kommt gewinnen können. Programmierer glauben an die Software, und dass sie wenn es hart auf hart kommt debuggen können. Und wir alle glauben an die Nachrichten, und dass wir wenn es hart auf hart kommt Fake News erkennen können.
Ist alles eine Fehleinschätzung, aber möglicherweise in der Praxis immer noch besser als irgendeinem "vertrauenswürdigen" Sender einfach zu glauben.
Update: Oh und was ich ganz vergaß: In dem Test soll man auch WDR und ZDF als öffentlich-rechtlich erkennen, man kriegt vermittelt, dass öffentlich-rechlich = unabhängig, vertrauenswürdig und gut, und sie wollen als Antwort haben, dass das ehemalige Nachrichtenmagazin unabhängigen Journalismus macht.
Oh, und: "Ich leite grundsätzlich keine Nachrichten weiter" wollen sie nicht als Begründung dafür haben, dass man eine Falschmeldung nicht weiterleitet. Auch "Ich glaube, dass meine Freund:innen das Thema nicht interessiert" akzeptieren sie nicht. Insofern ist das weniger ein Test und mehr eine Konditionierung auf unkritischen Medienkonsum der "guten" Medien in meinen Augen.
Das klingt jetzt erst mal nicht gut, aber bisher gibt es zu wenig Informationen, um das wirklich sagen zu können. Es gibt ja auch Instruktionen, mit denen man aus einem Userspace-Programm heraus Kernelspeicher schreiben kann. Aber das darf man halt nicht und alles was das dann tut ist einen Fehler werfen.
Das wird hier auch so sein.
Insofern würde ich mir das aus Anwendersicht erstmal noch keine Sorgen machen, zumindest bis nähere Details veröffentlicht werden.
Das ist nicht die erste undokumentierte Instruktion, die bei Intel gefunden wird. Solche Instruktionen sind im Allgemeinen fürs interne Testen gedacht und dann vergessen worden. Es gibt da eine ganz legendäre namens LOADALL, die es zu 80286-Zeiten mal gab (auf 80386 gab es auch eine LOADALL-Instruktion, die aber subtil anders war). Damit konnte man dann zum Beispiel ohne Wechsel in den Protected Mode auf Speicher jenseits des 1. Megabytes zugreifen.
Nach undokumentierten Instruktionen zu suchen ist nicht sonderlich schwer und der Suchraum ist auch nicht so groß, insofern laufen da seit vielen Jahren Leute herum und probieren Opcodes aus. Manchmal finden sie was, manchmal nicht. Es gibt da z.B. eine undokumentierte Breakpoint-Instruktion.
Jedenfalls ... dass es da Wege geben würde, den Microcode-State zu ändern, war ja irgendwie klar. Intel shippt seit einer Weile Microcode-Updates und BIOS-Updates, die ihre Bugs im Feld fixen sollen. Das leuchtet ein, dass es da also einen Mechanismus geben wird.
#UD heißt Undefined Instruction, das ist der Fehler, den man kriegt, wenn man einen nicht existierenden Opcode auszuführen versucht. Die CPU muss also in einem bestimmten Debug-Zustand sein, um die Instruktion überhaupt als gültig zu erkennen, und in den kommt man normalerweise nicht. Die Management Engine könnte den Zustand herbeiführen, schätze ich mal, aber da haben du und ich ja keinen Zugriff drauf. Ähnlich ist das bei dieser Breakpoint-Instruktion auch. Die funktioniert nur, wenn die CPU in einem ICE läuft (oder vielleicht kann man das auch auf normalen CPUs anschalten aber ich weiß nicht wie).
Seit dem rollt eine Welle an Hausdurchsuchungen und Festnahmen über Europa.
Und jetzt sagen sie, sie hätten auch einen weiteren Dienst hopsgenommen und die Nachrichten entschlüsselt. Dieser Konkurrenzdienst heißt "Sky ECC". Da wird es jetzt ein bisschen spannend, denn Sky ECC dementiert das nachdrücklich. Sie sagen niemand habe ihren Scheiß gehackt, da sei bloß eine Phishing-Anwendung mit ihrem Logo unterwegs da draußen. Und im Übrigen hätten sie ja 5 Mio Dollar Prämie ausgelobt für den ersten, der ihre Nachrichten unautorisiert entschlüsseln kann.
Das ist ja schon mal interessant, aber wartet, geht noch weiter!
Die belgischen Behörden pullen einen Trump und machen einen Double Down:
The Belgian federal prosecutor's office, in charge of the investigation, said Sky ECC's claims were "bullshit."[...] So confident were the police that they broke Sky ECC's code, they said they sent the firm their bank account details to claim a $5 million (€4.2 million) bug bounty Sky ECC promised to pay out to security researchers that had managed it.
TROLOLOLOAlso schonmal Popcorn kaltstellen!
Wer sich jetzt wundert, dass die belgischen Behörden das geschafft haben sollen, die ja bisher international nicht gerade durch Innovation, Kompetenz oder Aktivität aufgefallen sind: Keine Sorge, das waren die Holländer, und zwar vermute ich mal, dass es der holländische Geheimdienst war, nicht deren Polizei. Die Belgier machen jetzt nur die Pressearbeit.
Hunderte von Gefängnisinsassen in Arizona konnten wegen eines Softwarefehlers nicht entlassen werden.
Tja. Softwareproblem. Kann man nichts machen.
Es handelt sich um einen Bug in der Logik von libowfat. Ich habe einen Fix eingecheckt. Mal gucken, ob das hilft.
libowfat stellt ja ein API zur Verfügung, um sich Events auf Sockets geben zu lassen. Das läuft im Wesentlichen so:
io_fd(3); // ich bin an deskriptor 3 interessiert
io_wantread(3); // und zwar will ich lesen
io_wait(); // warten, bis ein angemeldetes Event eintritt
while ((fd = io_canread())) { // alle read events durchlaufen
...
}
while ((fd = io_canwrite())) { // alle write events durchlaufen
...
}Leider ergibt sich aus dieser einfachen API hinter den Kulissen eine bemerkenswerte Komplexität. io_wait ruft ein Low-Level-API des Betriebssystems auf, das (hoffentlich!) mehr als ein Event auf einmal melden kann.
io_wait hat pro mit io_fd angemeldetem Deskriptor ein bisschen State, und in dem State gibt es next-Membervariablen, einmal für den nächsten Deskriptor mit read-Event und einmal für den nächsten Deskriptor mit write-Event. Diese Liste traversieren io_canread und io_canwrite dann.
Nehmen wir mal an, jemand trägt auf einen Deskriptor sowohl Lese- als auch Schreib-Interesse ein. Dann kommen auf denselben Deskriptor gleichzeitig Lese- und Schreib-Events rein. Bei der Behandlung des ersten davon passiert ein Fehler.
Der Code schließt den Deskriptor.
Aber der State zu dem Deskriptor ist noch in der verketteten Liste für den anderen Event-Typ eingetragen!
Klingt jetzt nicht so schlimm. Der andere Event-Handler macht dann halt read oder write und kriegt einen Fehler, weil der Deskriptor geschlossen ist.
Leider kann aber der read-Event auch auf den Listen-Socket sein, und der Handler dafür ruft accept() auf, und accept() gibt einen neuen Deskriptor zurück. Das könnte derselbe sein, auf den in der Datenstruktur noch ein Write-Event eingetragen ist!
Um dieses Szenario zu verhindern, hat libowfat ein io_close(), das man statt close() aufruft. Wenn der sieht, dass da noch ein Event offen ist, dann markiert er den Deskriptor als geschlossen aber schließt ihn nicht wirklich.
Jetzt will man diese halboffenen Deskriptoren aber auch mal irgendwann loswerden. Dafür gibt es zwei Stellen, die sich anbieten.
Erstens: In io_canread und io_canwrite. Die müssen ja sowieso checken, ob der Deskriptor geschlossen wurde, und das Event aus der Liste dann verwerfen. Die könnten dann auch den Deskriptor ganz schließen.
Zweitens: In io_wait. Das ruft man ja erst wieder auf, nachdem man alle ausstehenden Events abgearbeitet hat. Der könnte dann alle als geschlossen markierten Deskriptoren final schließen.
Ich hatte Code in beiden drin, und der Bug ist glaube ich, dass die sich gestört haben. Mal laufen lassen und gucken, ob es das war.
Kurzfassung: GnuPG benutzt als Kryptolibrary aus religiösen, äh, Lizenzgründen nicht OpenSSL oder etwas anderes existierendes, sondern "libgcrypt", eine eigene Krypto-Library, die im Allgemeinen langsamer als andere ist und deren API noch übler ist als die von OpenSSL. Ich kenne kein Argument dafür, die gegenüber einer Alternative zu bevorzugen.
Da ist kürzlich eine neue Version released worden, 1.9, in der Assembler-Optimierungen für einige Funktionen neu dazu kamen. Unter anderem für Hashing-Verfahren. Hashing ist eine der wichtigsten Funktionen in einer Krypto-Library und spielt z.B. eine Rolle beim Validieren von Signaturen in GnuPG.
Wenn man Daten hasht, gibt es normalerweise drei Schritte. Man hat einen "Kontext", d.h. eine Datenstruktur mit dem internen Status, die initialisiert man (Funktion 1), dann ruft man so oft man es braucht "hash mal auch diese Daten hier" auf (Funktion 2), und am Ende holt man sich den Hashwert über alle bisherigen Daten (Funktion 3). Je nach Hashfunktion, für die man das macht, beinhaltet das Finalisieren noch ein mehr oder weniger abstoßendes Padding-Verfahren, denn die Hashes arbeiten normalerweise auf Blöcken von Bytes, nicht auf einzelnen Bytes.
Bei libgcrypt heißt der letzte Schritt "finalize". Der Assembler-Code nahm an, dass niemand so blöd sein würde, nach einem finalize nochmal weitere Daten hashen zu wollen, weil das nie gültige Ergebnisse liefern kann, denn da ist ja schon Padding reingeflossen.
Stellt sich raus: GnuPG macht genau das. Das sollte wohl ein halbherziger Versuch sein, einen Timing-Seitenkanal zu schließen.
Da hätte wohl der Autor von GnuPG mal mit dem Autor von libgcrypt reden sollen, denkt ihr euch jetzt vielleicht? Das ist dieselbe Person. Werner Koch.
Was heißt das? Anscheinend reicht das Öffnen einer verschlüsselten Mail mit GnuPG, um Speicherkorruption herbeizuführen und damit eventuell Remote Code Execution.
Ich habe den Bug nicht analysiert, aber wenn das stimmt, ist das auf der Krassheitsskala ungefähr so weit oben wie Heartbleed bei OpenSSL war, denn GnuPG hat keine Privilege Separation und kein Sandboxing. Die gute Nachricht ist: Das betrifft euch nur, wenn euer GnuPG so neu ist, dass er schon gegen die neue libgcrypt linkt, die vor ner Woche oder so erst rauskam.
Kann man diese Art von Bug verhindern?
Ja, kann man.
Diese Art von Bug wäre aufgefallen, wenn GnuPG eine Testsuite hätte, die z.B. mit valgrind oder dem Address Sanitizer automatisch durchläuft, bevor er eine Version released. Noch beunruhigender als dass das offensichtlich nicht stattfindet, finde ich Werner Kochs Reaktion, als Hanno Böck genau das vorschlägt. Er schließt den Bug als "invalid". Das ist selbst für Werners Verhältnisse ausgesprochen unprofessionell, aber leider nicht überraschend.
Hey, Werner, wenn du keinen Bock auf die Verantwortung hast, die der Maintainer von GnuPG tragen muss, dann übergib das Projekt doch am besten der Apache Software Foundation oder so. Jetzt wäre jedenfalls der richtige Zeitpunkt für zerknirscht Besserung geloben gewesen, nicht für close as invalid.
Ich muss dann wohl doch mal meinen OpenPGP-Code fertig machen. So geht das jedenfalls nicht weiter.
Update: Ich hatte meinen OpenPGP-Code prokrastiniert, weil ich dachte, fürs reine Signatur-Prüfen ist mein Ansatz mit der Prozessisolation vielleicht nicht nötig. Wer verkackt denn schon eine Hashfunktion, dachte ich mir.
Update: Leserbrief von Hanno Böck:
libgcrypt hat eine testsuite, und die hat den bug nicht gefunden. Müsste man jetzt genauer analysieren warum und ob das ein mangel bei der testabdeckung ist und sie den bug hätte finden sollen.
Der Punkt den ich aber kritisiert hab: Es gibt einen anderen bug in libgcrypt 1.9.0 in der testsuite, der durch asan gefunden wird. Es ist "nur" eine selbsttestfunktion, insofern ist der bug nicht so relevant, aber daraus kann man halt schließen: libgcrypt wird offenbar nicht regelmäßig vor einem release (oder via CI)mit asan getestet, sonst hätte das ja merken müssen.
Und achso, noch was: Valgrind hätte diesen Bug (also den in der testsuite) nicht gefunden. Das ist ein buffer overread in einem predefinierten array, sowas kann valgrind nicht. Siehe beispiel im Anhang.
Ich predige seit jahren dass die leute asan nutzen sollen und nicht glauben valgrind sei ein vergleichbar mächtiges tool. Ist es nicht.
A serious heap-based buffer overflow has been discovered in sudo that is exploitable by any local user. [...] The bug can be leveraged to elevate privileges to root, even if the user is not listed in the sudoers file. User authentication is not required to exploit the bug.Das sendmail unter den Zugriffskontrollsystemen!
Ich frage mich, wie ähnlich das zu so Weltuntergangssekten ist, wenn dann der angesagte Tag ohne Weltuntergang verstreicht.
Vielleicht erinnert sich der eine oder andere Leser noch an früher, als beim Booten nach unsauberem Runterfahren erstmal ein CHKDSK anlief und Dinge reparierte. Für Konsumenten-Rechner war das nicht so schlimm, aber auf Servern mit mehreren Terabyte großen Dateisystemen dauerte so ein CHKDSK schon mal Stunden bis Tage.
Daher hat Microsoft eines Tages entschieden, das Checking wegzumachen und stattdessen NTFS "self healing" zu machen. Ich hab ihnen damals davon abgeraten, weil so self-healing Kram Heuristiken fährt und nicht den Überblick hat, den CHKDSK haben kann. Möglicherweise macht der die Dinge sogar schlimmer.
Daher dachte ich, als ich das hier las, als erstes an das self-healing NTFS. Der Bug klingt ein bisschen danach, als würde da ein Sonderfall nicht bedacht und der self-healing Repariercode springt an und macht das Filesystem erst korrupt.
Das ist aber alles Spekulation. Einblick habe ich da keinen.
Tracked as CVE-2021-1647, the vulnerability was described as a remote code execution (RCE) bug that allowed threat actors to execute code on vulnerable devices by tricking a user into opening a malicious document on a system where Defender is installed.War das nicht die Software, die man einsetzt, damit man geschützt ist und auf Dokumente draufklicken kann, weil das Schlangenöl die Malware rausfiltert?Frage für einen Freund.
Daher lese ich sehr gerne Post-Mortems. Hier hat Netflix einen schönen publiziert. Der hat mich ziemlich aus der Bahn geworfen.
Ich fasse mal grob zusammen. Die hatten da Abspiel-Ruckeln auf einem Gerät, und beim Debuggen haben sie rausgefunden, dass ihre Softwarearchitektur schlecht war. Die hat bei einem Scheduler-Framework von Android einen Callback in 15 Millisekunden beantragt, und hat dann Audiodaten für einen Frame rausgeschrieben.
Im Allgemeinen kam der Callback auch nach 15 ms, aber halt nicht immer. Manchmal kam der auch erst nach 55 ms.
Das war ein Bug in Android. Das will ich auch gar nicht schönreden.
Aber was mich daran irritiert: Wenn du beim System oder sonstwo einen Callback beantragst, dann musst du immer davon ausgehen, dass der zu spät kommt oder einer ausfällt. Wir haben es hier mit Best Effort zu tun, im ganzen System. Es könnte z.B. sein, dass das Gerät heißläuft und daher den CPU-Takt runterschraubt und dann für deine beantragten Events nicht genug Luft war. Oder es könnte sein, dass der Speicher knapp wurde, weil eine andere App irgendwas krasses gemacht hat, und das System dann Speicher von deiner App rausgeschmissen hat, um den Bedarf zu befriedigen. Der kann dann wieder reingeladen werden, aber das dauert halt Zeit.
Kurz gesagt: Wenn du dem System sagst, du willst jetzt 15 ms Pause machen, dann hast du genau eine tatsächliche Zusage: Es sind mindestens 15 ms. Nicht höchstens. Mindestens!
Mit anderen Worten: Dein Handler muss immer davon ausgehen, dass da ein Event verlorengegangen ist und in dem Fall dann halt mehr Audiodaten rausschreiben, um nicht ins Stocken zu geraten.
Und das führt dann dazu, dass man auch den Fall abhandeln muss, wo man ein Event zweimal kriegt, denn möglicherweise kommt das erste Event zu spät, schreibt dann zwei Frames raus, und dann kommt direkt das Event für den nächsten Frame, den man jetzt aber schon rausgeschrieben hatte.
Ich bin einigermaßen irritiert, dass Netflix ihre Software nicht so designed hat, dass sie mit dieser Art von Unvorhersehbarkeit klarkommt und das on the fly kompensiert. Ich hätte gedacht, dass das absolute Mindestanforderung an solche Systeme ist. Mir wäre das gar nicht in den Sinn gekommen, ein System zu bauen, was das nicht tut.
Die Lektion ist, dass man bei der API-Dokumentation auch offensichtliche Dinge immer explizit hinschreiben muss. Nur weil du das für offensichtlich hältst, heißt das nicht, dass es auch alle anderen für offensichtlich halten. Als Beispiel will ich hier mal die Man Page von nanosleep(2) zitieren:
If the interval specified in req is not an exact multiple of the granularity underlying clock (see time(7)), then the interval will be rounded up to the next multiple. Furthermore, after the sleep completes, there may still be a delay before the CPU becomes free to once again execute the calling thread.Ich kenne jetzt diese Android-API nicht, weil ich noch nie Android programmiert habe, aber ich vermute mal, wenn das da so klar dokumentiert gewesen wäre, hätten die Netflix-Leute ihren Dienst nicht auf der Annahme fußen lassen, dass das immer alles perfekt genau wie beantragt reinkommt.
Wartet, hört mir zuende zu!
Nehmen wir mal an, du gehst davon aus, dass es bald eine Impfung gibt. Aber es wird nicht genug Dosen für alle geben. Du willst unbedingt als einer der ersten geimpft werden.
Dann musst du dich doch irgendwie in die größte Risikogruppe des Landes bugsieren!
Und welche Gruppe hat ein höheres Risiko als die Covidioten!
Scheiße, Bernd, sie haben uns ausmanövriert!
Pass uff, Fefe, wir machen jetzt Secure Boot in der Cloud! Was genau soll da am Ende die Aussage sein?
Ihr versteht schon, dass das per Design eine virtualisierte Umgebung ist, oder? Du glaubst, du redest mit der Hardware, aber tatsächlich redest du mit einem Stück Emulator-Software, die von jemandem betrieben wird, um deine Software zu verarschen. So zu verarschen, dass sie glaubt, sie liefe auf nicht-virtualisierter Hardware.
Wer die Umgebung betreibt, in der deine Software läuft, kann auch einfach so tun als gäbe es da Hardware-Security und dir genau die Hashwerte geben, die du gerne hören wolltest!
Nicht nur das: Einer der Gründe für die Cloud ist, dass man von Hardware-Ausfällen abstrahieren kann. Deine virtuelle Maschine wird einfach auf eine andere physische Hardware umgezogen! So und jetzt denken wir alle nochmal scharf nach, was das für Remote Attestation heißt, wenn sich nach dem Booten die Hardware ändern kann, auf der der Code läuft, aber niemand sagt dem Code Bescheid. Oh, was sagt ihr? Ist alles Bullshit! Bingo! 100 Punkte für die Kandidaten!
Und was war die Antwort der Sales-Kokser? Wir machen einfach Remote Attestation durch den Hypervisor hindurch!!1! Ja, äh, ... tolle Idee! Aber woher weißt du, dass du mit dem TPM redest und nicht mit einem Emulator? Woher weißt du, dass es überhaupt ein TPM in Hardware gibt?!
Ich kläre mal auf. Das erkennst du daran, dass deine Hardware eine Hintertür-Hardware drin hat, die Management Engine, und die kann dir mit einem nur Intel bekannten Private Key signierten Kram geben. Die Signatur kannst du checken, und dann weißt du: Es war Intel. Gut, außer jemand anderen hat den Key auch. Vielleicht die US-Regierung, die übrigens der dickste Kunde ist, den ein Cloud-Provider haben kann, und um den sich gerade AWS und Azure vor Gericht streiten, so wichtig ist der. Interessenskonflikt much?
Ich bin ja auch immer wieder fasziniert, dass die Leute annehmen, wenn sie bei Amazon einen Secure Key Store klicken, dass das dann ein HSM ist. Die Leute hören, was sie hören wollen. Amazon musste ihnen nichtmal ins Gesicht lügen! Sie mussten nur einfach die Details weglassen oder ins Kleingedruckte schieben. Das reichte.
Besser noch! Amazon konnte dann als Zusatzdienstleistung ein Cloud-HSM anbieten (ein HSM ist ein Hardware Security Modul, eine Art Safe mit einem Computer drin, der unextrahierbar den Private Key hat). Ja, richtig gelesen. Ein Cloud-HSM. Mit anderen Worten: Der andere Service ist gar kein HSM. Und glaubt ihr da hätte mal einer der Kunden Fragen gestellt? Nix da!
Dieses Cloud-HSM ist natürlich auch kein HSM. Wozu die Kosten auf sich nehmen. Deine Software läuft auf einer Hardware, die jemand anderes betreibt. Ob da ein HSM dran ist oder nicht ist völlig wurscht. Und das ist eh alles virtualisiert. Woran würde deine Software also erkennen, dass das HSM nur emuliert ist?
Wieso ich hier ewig lang herrumrante? Weil ich gerade über zwei Neusprech-Bomben gestolpert bin. Erstens: Azure Sphere. Zweitens: Der "Pluton"-Chip (*fremdschäm* DER RÖMISCHE GOTT HEISST PLUTO NICHT PLUTON IHR BARBAREN)
So, Trinkspiel. Setzt euch mal hin und lest die beiden Seiten und dann erklärt mir, was die da konkret anbieten. So wie ich das sehe bestehen beide Seiten praktisch vollständig aus nichtssagenden Worthülsen.
Ich zitiere mal zwei Paragraphen von diesem Pluton-Dingens:
Today, Microsoft alongside our biggest silicon partners are announcing a new vision for Windows security to help ensure our customers are protected today and in the future. In collaboration with leading silicon partners AMD, Intel, and Qualcomm Technologies, Inc., we are announcing the Microsoft Pluton security processor. This chip-to-cloud security technology, pioneered in Xbox and Azure Sphere, will bring even more security advancements to future Windows PCs and signals the beginning of a journey with ecosystem and OEM partners.Our vision for the future of Windows PCs is security at the very core, built into the CPU, where hardware and software are tightly integrated in a unified approach designed to eliminate entire vectors of attack. This revolutionary security processor design will make it significantly more difficult for attackers to hide beneath the operating system, and improve our ability to guard against physical attacks, prevent the theft of credential and encryption keys, and provide the ability to recover from software bugs.
Ich hab mal deren peinlichen PR-Fettdruck-Formatierungsscheiß weggemacht. Der eigentlich wichtige Punkt ist im letzten Halbsatz. Das ist, worum es geht. Wir, Microsoft, sehen uns nach 30 Jahren der Investition völlig außerstande, auch nur perspektivisch daran zu denken, jemals Software ohne Sicherheitslöcher ausliefern zu können. Daher haben wir aufgegeben und zwängen euch jetzt einen Chip auf, den ihr nicht kennt, den niemand von euch haben wollte, und dem ihr ab jetzt vertrauen müsst. Glaubt uns am besten einfach, dass wir niemals nie nicht NSA-Backdoors ausliefern würden oder so. Wir sind hier die Guten!1!! Das dient alles der Sicherheit! (Genau wie die ganzen NSA-Programme übrigens)Wie, ihr wollt ein Opt Out? Nee, gibt es nicht. Wir packen den Scheiß direkt in die CPU rein. Damit ihr möglichst keine Wahl habt, haben wir das direkt Intel, AMD und Qualcomm übergeholfen. HAHAHAHA DA BLEIBT NICHT VIEL ANDERES ÜBRIG HAHAHAHA IHR KÖNNT JA BEI APPLE KAUFEN HAHAHAHAHA
Im Hintergrund denkt euch einen Bill Gates, der eine fette Langhaarkatze streichelt.
Wobei. Ich bin da vielleicht ein bisschen vorschnell. Es ist nicht so, dass die Seiten gar nichts sagen. Eine Sache sagen sie: Vertraut uns. Wir arbeiten dran. Was ihr alles an grundsätzlichen fundamentalen unreparierbaren Gründen gegen die Cloud gehört habt, das betrifft nicht unsere Cloud, denn wir haben magischen Feenstaub drübergesprenkelt.
Eines Tages werden wir mehr wissen. Wenn ihr mich fragt: Bestimmt was mit Blockchain und Machine Learning.
Update: Hahaha jetzt kommen hier lauter Einsendungen zu dem Begriff "Pluton". Stellt sich raus: Es gab auch Pluton im Griechischen als Synonym für Hades, dessen Namen man nicht auszusprechen wagte, weil er ja für Tod stand. Wikipedia dazu:
Platon beispielsweise meint, Pluton/Plutos sei durchwegs positiv zu sehen als der Spender von Reichtum
Passt doch perfekt, findet der Einsender. Ein anderer Einsender fand noch eine andere Wortbedeutung, aus der Geologie, wo es für eine besonders tiefe Intrusion geht. Das meint zwar aber eine Intrusion im geologischen Sinne, aber der andere Einsender fand, das passe auch prima für einen "Security-Chip".
Wer nicht genau hinguckt, der könnte glauben, dass die Lücken alle von den Guten gefunden und gemeldet werden.
Das stimmt aber nicht. Erstens gab es gerade eine Flut aus Fixes für in der freien Wildbahn beobachteten Sicherheitslücken.
Zweitens, und das ist mir wichtig, dass ihr das alle versteht: Hersteller stehen unter keinerlei Druck, gefixte Sicherheitslücken überhaupt öffentlich anzusagen. Hersteller melden auch im Allgemeinen intern gefundene Lücken nicht, selbst wenn die in der freien Wildbahn gefunden wurden.
Woher weiß der Hersteller von Sicherheitslücken in der freien Wildbahn, fragt ihr euch jetzt vielleicht? Nun, Crash Reporting. Dr Watson hieß das früher. "This program has stopped working …"
Ihr seht hier also nur die Spitze des Eisbergs. Fixes für Lücken, die von Externen gefunden wurden, die möglicherweise schlechte PR verursachen könnten, wenn man die Bugs gar nicht oder verdeckt im nächsten Update fixt.
Nehmt mal bitte nicht für eine Sekunde an, dass das schon alles ist. Die Software da draußen ist auf so vielen Ebenen kaputt, das glaubt man gar nicht, wenn man nicht regelmäßig Bugtracker von Open Source-Projekten durchguckt und ein Gefühl dafür entwickelt.
Dass diese Lücken bekannt wurden, liegt daran, dass Google Project Zero die gefunden hat, und die haben so einen Ehrenkodex und melden auch Lücken in Google-Produkten öffentlich. Das war der Preis dafür, dass Google da so ziemlich die Besten der Besten gekriegt hat. Die hatten keinen Bock, sich als Waffe gegen Dritte missbrauchen zu lassen.
The big problem with this feature is that it is highly vulnerable to injection attacks. As the runner process parses every line printed to STDOUT looking for workflow commands, every Github action that prints untrusted content as part of its execution is vulnerable. In most cases, the ability to set arbitrary environment variables results in remote code execution as soon as another workflow is executed.Ach kommt, da muss man Verständnis haben. Das ist Microsoft. Die hatten noch nie Injection als Bugklasse!1!! Daher ist auch das Repo von Visual Studio Code betroffen.Niemand kann erwarten, dass die sich vorher existierende Bugklassen angucken. Wir sind hier in der Devops-Ära. Da wird erst implementiert, und danach guckt man, ob Fehler drin sind. Planen macht man nicht mehr. Das erinnert zu sehr an Wasserfall.
Und komm schon, wann hat Wasserfall jemals funktioniert? Gut, es hat uns als Spezies auf den Mond gebracht. Es hat die Entwicklung von Datenbanken und von Programmiersprachen und Finanzsoftware ermöglicht. Aber sonst? NICHTS hat es uns gebracht!!1! Heute pfuschen wir lieber und gehen dann pleite, wenn die Fehler offenbar werden. Oder wir fangen an, von "responsible disclosure" zu faseln.
Ich find das ja immer geil, dass die gleichen Leute, die uns eben noch erzählt haben, Wasserfall sei zu teuer, jetzt ein Abomodell für ihre Pfusch-Schrottware aufschwatzen wollen.
This could have included your name, email address, telephone number, billing address, and payment card details (card number, CVC/CVV and expiration date).Eigentlich müsste Warner jetzt direkt aus dem Payment-Verkehr gezogen werden, denn die CVC-Nummern darf man extra nirgendwo speichern, auch nicht zum Debuggen. Wer es doch macht, dem drohen auf dem Papier saftige Strafen. Allerdings passiert in der Praxis natürlich nichts, denn die Payment-Mafia schneidet sich doch nicht den Ast ab, auf dem sie sitzt.Wenn die Contentmafia mal halb so viel Energie in die Sicherung ihrer Infrastruktur investiert hätte wie in Bullshit-"Kopierschutz"-Gängelscheiße für den Krieg gegen ihre Kunden, dann hätten wir das Schlamassel vermeiden können.
Hier gibt es einen schönen Fall von Leuten, die auf mich hätten hören sollen.
Kommt ihr NIE drauf!
They killed [the] entire threat management team. Mozilla is now without detection and incident response.Mozilla ist ja jetzt schon eine Katastrophe, wenn es um Security geht. Guckt euch nur mal die Fixes in Firefox 79 ein. Ach komm, Fefe, sind doch nur 4 high!1!! Ja schon, aber scrollt mal runter, da haben sie einen use after free memory corruption bug als "moderate" klassifiziert. Scrollt mal noch weiter runter. Oh gucke mal, ganz am Ende ist ja noch ein "high"! Na sowas! Ist gar nicht sortiert, haben sie nur vorgetäuscht, damit du nicht siehst, dass sie 5 statt 4 highs haben!Das ist der Zustand, in dem die Security bei Mozilla vor der Entlassung des Security-Teams war.
Aber war ja klar, dass das so kommen wird. Wenn eine große Organisation mit 80% Wasserkopf in finanzielle Not gerät, wurde noch nie der Wasserkopf verkleinert. Da werden immer die letzten paar Ingenieure gefeuert.
Update: Sie haben nicht die ganze Security-Abteilung zugemacht. Das Gecko-Team gibt es noch. Ohne die jetzt mit Scheiße bewerfen zu wollen: Gecko ist der Legacy-Kack-Teil von Firefox. Der, der durch Rust-Komponenten und Webrender ersetzt werden sollte, damit wir endlich weniger Sicherheitlücken haben.
Update: Die Rust-Engine, die Gecko ersetzen sollte, heißt Servo. Die wird offenbar auch gerade plattgemacht. Das ist furchtbar, geradezu katastrophal. Das war unsere eine Hoffnung auf eine nicht 100% von Google kontrollierte Browser-Zukunft. Gecko hat keine Zukunft.
Und das MDN-Team ist auch weg. MDN ist fast noch wichtiger als Firefox, das ist die Dokumentation der ganzen Web-Standards bei Mozilla.
"The quality assurance of Skylake was more than a problem," says Piednoël during a casual Xplane chat and stream session. "It was abnormally bad. We were getting way too much citing for little things inside Skylake. Basically our buddies at Apple became the number one filer of problems in the architecture. And that went really, really bad."When your customer starts finding almost as much bugs as you found yourself, you're not leading into the right place."
Schade dass das nur B2B funktioniert. So viele Qualitätsprobleme wie es mit Apple-Software gibt...Der Typ, der das sagt, war übrigens früher bei Intel fürs Engineering zuständig. (Danke, Ralph)
Timothy Palmer, a professor in climate physics at Oxford University and a member of the Met Office’s advisory board, said the high figure initially made scientists nervous. “It was way outside previous estimates. People asked whether there was a bug in the code,” he said. “But it boiled down to relatively small changes in the way clouds are represented in the models.”
A very specific software bug made airliners turn the wrong way if their pilots adjusted a pre-set altitude limit.Wait, what?!Warte mal ... gab es da nicht Anfang des Jahres diese Meldung mit den IC-Zügen, die die Bahn nicht abnehmen wollte? Auch irgendein Problem mit Richtungswechseln. Ach gucke mal, das war auch Bombardier!
Da scheint wohl ein Ingenieur den Namen zu wörtlich genommen zu haben.
Bonus: Der empörte Forbes-Reporter ist selber Gründer einer Firma, die "advanced surveillance solutions" herstellt.
Update: Dieser Angriff betrifft die Server-Seite im pppd, d.h. eher die Access-Konzentratoren bei den ISPs. Außer euer Router hat einen VPN-Modus, bei dem er mehr als Client ist.
Update: Ilja schreibt mir gerade:
So it affects the server and client. Both eap_request() and eap_response() are vulnerable (and have the exact same bug). Further more, there is no check to see if you’ve actually configured eap and are using eap prior to hitting the parser. So even if it’s not configured, you’re still vulnerable. Oh, and it’s pre-auth.
Es trifft also doch alle eure Plasterouter. UND die Access-Konzentratoren. Und man kann es ausnutzen, ohne einen gültigen Account zu haben, und ohne dass EAP konfiguriert sein muss. Das ist der perfekte Sturm.
Oh und wenn euer Unix pppd setuid root installiert hat, ist das auch eine local privilege escalation.
Der Vortrag von Andy über die Überwachung in der Botschaft von Ecuador hat Überwachungsvideos aus deren Kameras gezeigt. Und zwar hatte Ecuador ja eine spanische Firma mit der Security der Botschaft beauftragt, und die hat sich dann nebenher von der CIA bezahlen lassen, um die Überwachungserkenntnisse zeitnah den Amerikanern zu geben. Das ging soweit, dass die die zuständige Behördenleiterung in Ecuador bestochen haben, um einen Vorwand für das Nachrüsten von Wanzen zu erreichen. Das ist jedenfalls wohl der aktuelle Stand der Ermittlungen in dem Verfahren in Spanien, in dem aber bisher noch nicht mal Anklage erhoben wurde. Der Chef hat aber die CIA-Kohle nicht mit seinen unterbezahlten Schergen geteilt, woraufhin ein paar von denen spontan ein Gewissen entwickelten und zu Whistleblowern wurden. Da kommen diese Aufnahmen jetzt her.
Julian Assange hat in der Botschaft mit Abhörversuchen gerechnet und daher im Konferenzraum einen Rauschgenerator installiert. Die Lautsprecher von dem Teil waren dann u.a. direkt neben dem Fenster montiert, woraufhin das CIA-Team im Haus gegenüber, die per Laser den Schall von den Fenstern abnehmen wollten, keine brauchbaren Aufnahmen bekamen. Die haben dann die spanische Firma beauftragt, nach geeigneten Plätzen für eine Innenverwanzung zu suchen und die Wanzen zu montieren. Am Ende haben die im Fuß des Feuerlöschers eine Aushöhlung mit einer Wanze angebracht.
Für die sensibleren Gespräche ist Julian mit Anwalt dann zum Badezimmer gegangen und hat die Dusche laufen lassen. Daraufhin ließ die CIA eine Wanze hinter dem einen Schrank dort anbringen. Es war wohl einigermaßen erheiternd, die fluchenden Amis in den Anfragen an die Spanier zu lesen, weil sie nicht weiterkamen.
Das Ende war dann weniger lustig. Über die Wanze im Feuerlöscher haben die Amis ein Gespräch zwischen Julian und der Geheimdienstchefin von Ecuador belauscht, die Julian einen ecuadorischen Pass beschafft hatten, ihn zum Diplomaten ernannt hatten, und eine offizielle Abberufung in eine Botschaft in einem anderen Land eingetütet hatten. Am nächsten Morgen lag dann überraschend ein internationaler Haftbefehl der USA vor. Überwachen hat also ernsthafte Folgen.
Es gab leider technische Probleme beim Streaming und der Aufzeichnung am Anfang. Ich hoffe mal, das ist trotzdem was geworden. Andy hat extra später angefangen.
Danach saß ich im Archimedes-Vortrag drin, der war auch echt großartig. Wer sich ein bisschen für Computerarchitektur interessiert, für den ist das ein Fest.
Nach diesem Vortrag war ich bei "Von Ich zu Wir", wo sie u.a. gezeigt haben, dass Klimakatastrophe kein Neusprech ist, sondern Klimawandel ist der Neusprech. Klimakatastrophe war im aktiven Gebrauch während der Ozonloch-Geschichte, und das hat gewirkt, wenn ihr euch erinnert. FCKW war schnell verboten und das Ozonloch hat sich deutlich gebessert. Maha rief mich dann öffentlich dazu auf, in meinem Blog überall Klimawandel durch Klimakatastrophe zu ersetzen. Ich sehe mein Blog auch als Archiv und werde das daher nicht tun, aber ich werde versuchen, ab jetzt immer Klimakatastrophe zu sagen. Wörter haben Macht.
Der PSD2-Vortrag war dann doch weniger Rant und mehr Katastrophentourismus. Der rote Faden war eine gewisse ... sagen wir mal Abneigung gegen Sofortüberweisung, die ja auch bei mir im Blog nie gut weggekommen sind. Am Ende stand dann in der QA-Session jemand auf und meinte, er arbeite ja für Sofort, und sie seien ja alle gemeinsam daran interessiert, dass das besser würde. Das ist für mich der Balls of Steel Award diees Congresses.
Plundervolt war so ein bisschen zu klamaukig für meinen Geschmack aber inhaltlich haben sie schon eine Wunde gerissen. Und zwar kann man bei Intel-CPUs per MSR per Software Undervolting aktivieren. Wenn man das gezielt macht, kann man Glitches erzeugen. So haben sie die Intel-Secure-Enclave-Technologie angegriffen und u.a. Crypto-Keys extrahiert. Die tatsächlichen Auswirkungen werden glaube ich eher gering sein, weil m.W. so gut wie niemand diesen Enclave-Kram tatsächlich verwendet. Aber für Intel ist das halt ein weiterer Messerstich. Praktisch alles, was in den letzten 10 Jahren von Intel kam, hat sich seit dem als Katastrophe herausgestellt.
Danach saß ich im Vortrag über die Intel Management Engine, der aber ein bisschen unorganisiert wirkte. Wenn man vorher nicht verstanden hatte, worum es da ging, hat man es nachher auch nicht verstanden. Inhaltlich hat der Typ vor allem Exploits der Forscher von Positive Technologies veröffentlicht und seine Eigenleistung war dann, einen Loader zu hacken, mit dem man Management-Engine-Code unter Linux in einem Prozess "emulieren" kann, dann wenn man möchte in einem Debugger. Das ist schon geile Scheiße, ich will das nicht kleinreden. Aber das kam in dem Vortrag erst so gegen Ende und weil der Vortragende das Zeitmanagement verkackt hatte, musste die Vorführung davon dann auch noch gestrichen werden. Schade.
Fortinet products, including FortiGate and Forticlient regularly send information to Fortinet servers (DNS: guard.fortinet.com) on - UDP ports 53, 8888 and - TCP port 80 (HTTP POST /fgdsvc) This cloud communication is used for the FortiGuard Web Filter feature (https://fortiguard.com/webfilter), FortiGuard AntiSpam feature (https://fortiguard.com/updates/antispam) and FortiGuard AntiVirus feature (https://fortiguard.com/updates/antivirus). The messages are encrypted using XOR "encryption" with a static key.
Stellt sich raus: Wenn man das Testing an Freiwillige crowdsourced, sind die Teilnehmer nicht aus dem Enterprise-Bereich. So segelte der Code ohne Probleme durch Monate des Testens.
Und jetzt merken plötzlich alle, wie sehr sie sich von Chrome abhängig gemacht haben.
"This has had a huge impact for all our Call Center agents and not being able to chat with our members," someone with a Costco email address said in a bug report. "We spent the last day and a half trying to figure this out.""Our organization with multiple large retail brands had 1000 call center agents and many IT people affected for 2 days. This had a very large financial impact," said another user.
"Like many others, this has had significant impact on our organization with our entire Operations (over 500 employees) working in a RDS environment with Google Chrome as the primary browser," said another system administrator.
"4000 impacted in my environment. Working on trying to fix it for 12 hours," said another.
"Medium sized call center for a local medical office lost a day and a half of work for 40-60 employees," added another.
Auf der anderen Seite muss man sagen, dass bei Chrome erstaunlich wenig schiefgeht. Wenn man das mal mit den ganzen verkackten Windows-Patches vergleicht, ist Chrome geradezu ein Anker der Stabilität und Verlässlichkeit.Update: Zur Klarstellung: Die Firmen haben das getestet und Chrome war erfolgreich im Einsatz, aber der Autoupdater von Chrome hat halt eines Tages diesen Experimentalcode ausgerollt, und ein "mach mal das letzte Update rückgängig" gibt es bei Chrome nicht.
Aber die Begründung ist bemerkenswert:
This is expected, and works the same way in other browsers."This is expected" hätte ich ja an deren Stelle aus taktischen Gründen lieber als "I was just following orders" formuliert. Damit man in Zukunft nicht mit heruntergelassenen Hosen dasteht, sollte man wenigstens so tun, als sei man nur widerwillig gefolgt.Aber "die anderen machen das auch so" finde ich an der Stelle bizarr. Ich weiß ja nicht, wie es euch geht, aber wenn ich mal zurückdenke, wieso ich Firefox einsetze, dann sind das alles Dinge, bei denen Firefox die Spec gebrochen und Dinge anders gemacht hat als die anderen Browser.
Firefox hatte als erster Browser einen Popup-Blocker. Erinnert man sich heute kaum noch dran. Früher haben Webseiten ungefragt weitere Browserfenster aufgemacht, im Allgemeinen mit Werbung drin. Das folgte auch der (schlechten) Spec und alle haben es so gemacht.
Dann hat Firefox mir einen Weg gegeben, 3rd party cookies zu blocken. 3rd party cookies folgen auch der Spec und die anderen Browser machen es auch so.
Dann hat Firefox ein API für Browser-Erweiterungen gebaut, mit dem ich einen Adblocker installieren konnte. Werbung war auch Spec-konform und alle anderen Browser haben auch Werbung angezeigt.
Dann hat Firefox einen Tracker-Schutz eingebaut. Web-Tracker entsprechen auch der Spec und die anderen Browser machen das auch so.
Mir ist echt nicht klar, was die sich bei Firefox denken, wenn die so eine Ausrede zu Protokoll geben. Ich vermute: Nicht viel.
Anfang des Jahres hatte uns ein Nutzer mitgeteilt, dass sein Browser, Firefox, meinte, Gentoo’s Installationsmedium würde Malware beinhalten.Erinnert an gmail. Da könnt ihr ja mal einen von Google ausgehenden Spam zu melden versuchen. Wenn ihr auf Kafka-Geschichten steht.Leider hatte der Nutzer den Download nicht beendet bzw. gleich wieder gelöscht (die Warnung sieht halt auch gefährlich aus!). Es stellte sich dann schnell heraus, dass zumindest zum Zeitpunkt unserer Prüfung, alle Mirrors die gleichen Dateien ausgespielt haben (Checksummen stimmen überein) und diese sauber waren (ja, wir haben unsere Images mit verschiedenen Schlangenöl-Lösungen geprüft).
Was war dann der Grund? Die Herkunft! Gentoo nutzt noch Mirrors, kostenlos bereitgestellt von Dritten und kein zentrales CDN. Einer dieser Spiegelserver, mirrors.kernel.org, ist in Google’s SaferBrowsing System gelistet. Aber nicht generell, nein, nur für das *gesamte* "/gentoo"-Unterverzeichnis.
Das schließt eben auch unser Installationsmedium in "/gentoo/releases/amd64/..." mit ein.
Wir haben dann irgendwann durch unsere Kontakte die Information bekommen, dass die Ursache im *Quellcode*-Archiv zu "Shadowinteger's Backdoor" (http://tigerteam.se/dl/sbd/) einem netcat-Klon stecken würde.
Was wir bis heute nicht wissen:
- Da Google’s SafeBrowsing offenbar in der Lage ist auf Verzeichnisebene zu flaggen, wieso haben sie dann die Warnung nicht zumindest auf /gentoo/distfiles beschränkt?
- Warum ist nur mirrors.kernel.org betroffen? Die Datei liegt auf allen unseren Spiegeln. Wenn nun also wirklich Gefahr von dieser Datei ausgehen sollte müsste der gemeine User, der sich auf SaferBrowsing verlässt, doch erwarten können, dass die gleiche Datei immer und überall erkannt und geblockt werden würde.
- Aktuell (das war vor paar Wochen noch anders) scheint tatsächlich die Quellcode-Datei von allen Quellen blockiert zu werden (also wirklich nur sbd-1.37.tar.gz), was Browser, die gegen das SafeBrowsing Download-API prüfen, verhindern.
Seit dieser Zeit kämpfen wir jetzt mit Google um eine Korrektur der Einstufung. Selbst mit unseren noch immer guten Kontakten zu Google (Hallo ChromeOS!) ist da nicht viel zu machen denn bekanntlich ist Google ein technisches Unternehmen: Die wissen, dass Menschen Geld kosten. Also tun die alles um Probleme technisch zu lösen und den Einsatz von Menschen zu minimieren, so auch im "Support": Erst wenn die Error-Rate zu einem gemeldeten Problem eine bestimmte Prozentschwelle überschritten hat, schaut sich ein Mensch den Sachverhalt an... :/
The security expert and bug-hunter John “hyp3rlinx” Page discovered an arbitrary code execution vulnerability, tracked as CVE-2019-9491, in the Trend Micro Anti-Threat Toolkit.Hey, ich habe eine Idee. Wir installieren einfach noch eine zweite Packung Schlangenöl! Die schützt uns dann vielleicht vor den Lücken, die das erste Schlangenöl aufgerissen hat!Wie wäre es mit Avast! Oder Norton! Gut, Norton hat den Nachteil, dass dann mein Blog nicht mehr geht. Aber für die Sicherheit muss man manchmal halt Kompromisse eingehen!1!!
Und zur Abrundung was von Cisco!
Und wenn ihr ganz sicher gehen wollt, dann nehmt Kaspersky. Die laden das in ihre Cloud und prüfen dort noch manuell!
Da wird sich der eine oder andere gedacht haben: Ach komm, Fefe, erzähl uns doch keinen vom Pferd, die Leute wären doch nicht so blöde und setzen Machine Learning ein, wenn das so fundamentale Probleme hat.
Daher präsentiere ich heute: Microsofts Schlangenöl mit Machine Learning hält den Updater von Dolphin für Malware. Und zwar nicht die Software auf eurem Rechner, nein, das Machine Learning in deren Cloud. Weil das Machine Learning ist, kriegen sie das nicht debugged, und das Nachtrainieren macht mehr kaputt als es heile macht. Also … hat Microsoft jetzt manuell eine Whiteliste für alle Dolphin-Entwicklerversionen, die sie gesehen haben. Und pflegen das immer schön von Hand nach.
Ich persönlich fände es ja ganz angenehm, wenn mir die Leute meinen Scheiß beim ersten Mal glauben würden, aber … not gonna lie, das ständige "told you so" ist auch ganz angenehm :-)
There is a logic error in Signal that can cause an incoming call to be answered even if the callee does not pick it up.
Ich baue da ja absichtlich keinen Watchdog mit Autorestart ein, damit es einen Leidensdruck gibt, das Problem mal zu debuggen und zu fixen.
Wenn ich König wäre, würde diese Firma sofort zerschlagen und die Mitarbeiter bekämen alle lebenslang Computerverbot. Aber micht fragt ja keiner.
Aber ihr erwartet jetzt vielleicht, dass Palo Alto wenigstens sofort ein CVE beantragt und das öffentlich gemacht hat, um ihre Kunden zu schützen. Nein, haben sie nicht.
Palo-Alto have now created a security bulletin for this and requested a CVE (cve-2019-1579 pending assigning). The issue is over a year old and absolutely critical as a 100% reliable preauth RCE VPN exploit using format strings, highly recommend you patch.Ein Jahr! Sportlich!!Zum Vergleich: Die Sowjetunion brauchte weniger lange, um Tschernobyl zuzugeben.
Ich reagiere da so bissig, weil das eine Security-Firma ist. Angeblich. Also ... Schlangenöl, natürlich. Aber die haben den Leuten die Kohle aus der Tasche gezogen mit dem Versprechen, sie vor Würmern zu beschützen. Und tatsächlich haben sie den Würmern einen praktisch idealen Installationsvektor in die Hand gegeben.
Update: Die heißen übrigens nur Palo Alto, die kommen nicht aus Kalifornien. Der Gründer ist Israeli und war vorher bei Checkpoint. Nicht dass das irgendeine Rolle spielt, aber wenn die Firma dich schon mit ihrem Namen belügt, ... (Danke, Axel)
Wenn euer Blutdruck wieder runtergekommen ist: Hört mir kurz zu!
Die Idee ist, dass irgendein inkompetenter Idiot aus einer Behörde oder der Politik von irgendeinem IT-Dienstleister "Distributed Ledger"-Bullshit ordert, weil das gerade so hip und geil ist. Aber eigentlich geht es in dem Projekt darum, deren Buchhaltung und Prozesse überhaupt soweit zu kriegen, dass man da überhaupt auch nur in die Nähe von digitaler Verarbeitung kommt. Und ob dann der Blockchain-Bullshit was wird oder nicht, das spielt dann keine Rolle mehr. Der Dienstleister kriegt den Job wegen Blockchain-Humbug. Die Behörde kriegt Digitalisierung. Der Dienstleister kriegt Geld. Und auch ohne Schlangenöl-Hypetech haben dann alle einen Vorteil.
Vielleicht sollte ich meine Fundamentalopposition nochmal überdenken.
Update: Könnte sich um diesen Fall aus dem letzten Jahr handeln. Das wäre ja eher peinlich, wenn Whatsapp da nen Jahr drauf sitzt.
Völlig unvorhergesehen und überraschend stellt sich nämlich heraus, dass Zertifikate ablaufen. Tsja, Mozilla, und DAS ist die Hölle, die ihr mit Letsencrypt einmal auf die ganze Welt rausgehauen habt. Nur halt nicht alle paar Jahre mal sondern alle paar Wochen mal. Wegen … uh … Yolo!!1!
Das Zertifikat, das hier abgelaufen ist, ist ein Intermediate Cert, das im Prozess des Signierens aller Add-Ons beteiligt ist. Denn Add-Ons müssen ja neuerdings signiert sein. Damit, wenn man sie über eine signierte Verbindung von Mozilla lädt, und da Malware drin ist, Mozilla sagen kann: Haha, nicht unsere Schuld!1!!
Ich frage mich ja, wie häufig Code Signing noch komplett versagen muss, bevor dieser unsägliche Bullshit-Trend mal endlich geerdet wird.
Mozilla hat jetzt jedenfalls Add-Ons komplett abgeschaltet.
Das Problem hat den schönen Namen "armagadd-on-2.0" gekriegt :-)
Update: Solange bei Firefox die Addons nicht gehen, würde ich lieber Chrome mit ublock/umatrix nehmen als Firefox ohne.
Update: Ein Leser meldet, dass man bei Firefox Nightly in about:config Addon-Signaturprüfung deaktivieren kann (Key xpinstall.signatures.required). Das hat natürlich andere Nachteile, wenn ihr nicht ausschließen könnt, dass euch freidrehende Software Firefox-Addons unterjubeln will. Auf der anderen Seite hatten wir ja auch schon genügend signierte bösartige Firefox-Addons. Mozillas Lösungsvorschlag ist, dass ihr alle Mozilla die Erlaubnis erteilt, Studien bei euch durchzuführen, und dann kommt innerhalb der nächste 6 Stunden hoffentlich diese eine magische Studie bei euch vorbei, die das fixt.
Protokolle wie die von Citrix und Remote Desktop sind hochkomplex und die Implementationen müssen daher schon von der Statistik her praktisch zwangsläufig noch üble Sicherheitsbugs haben, bei der Codemenge, die man für eine Implementation braucht. Auch von "wir haben zentrale Terminalserver", die nur innerhalb der Firma zugreifbar sind, würde ich aus dieser Überlegung heraus eher abraten.
A buffer overflow vulnerability was found in GNU Wget 1.20.1 and earlier. An attacker may be able to cause a denial-of-service (DoS) or may execute an arbitrary code.wget ist so eines der Tools, bei denen sowas eher unangenehm ist. (Danke, Alexander)
Security fixes found by an EU-funded bug bounty programme:- a remotely triggerable memory overwrite in RSA key exchange, which can occur before host key verification
- potential recycling of random numbers used in cryptography
- on Windows, hijacking by a malicious help file in the same directory as the executable
- on Unix, remotely triggerable buffer overflow in any kind of server-to-client forwarding
- multiple denial-of-service attacks that can be triggered by writing to the terminal
Other security enhancements: major rewrite of the crypto code to remove cache and timing side channels. Das ist mal so ziemlich ein Totalschaden.
Und tatsächlich ist Vorsicht geboten. Wer das Teil im Debug-Modus startet, öffnet einen Debug-TCP-Port — nicht an localhost sondern ins ganze Netz! Und über den Port geht by design Remote Code Execution.
Ja super, liebe NSA!
you can call somebody via FaceTime and listen to their phone’s microphone regardless of whether the person you’re calling picks up.Das passiert wohl, wenn man während des Verbindungsaufbau auf Konferenz-Modus umschaltet.Klingt wie ein feuchter Traum der NSA, nicht wahr?
Danach bin ich rübergeeilt zum Cyberstalking-Vortrag von Anne Roth, bei dem ich leider den Anfang verpasst habe. Inhaltlich war das eine Anklage an das System, dass es nicht mehr tut, um Frauen vor gewalttätigen Männern zu schützen. Dass es nicht mal Geld für ordentliche Statistiken gibt, die Bundesregierung weiß von nichts, und die Polizei ist überarbeitet und uninteressiert. Fand ich jetzt nicht so weiterführend. Ich war auch ein bisschen enttäuscht von den Statistiken und dem Fokus auf Frauen als Opfer und Männer als Täter. In der Mitte gab es eine Statistik (ich glaube die war von der Uno?), wo Menschen befragt wurden, ob sie betroffen sind, und da waren mit deutlicher Mehrheit Männer in der Überzahl bei Opfern -- außer halt bei Stalking und sexuell motivierten Nachstellungen. Sogar bei "langfristige Nachstellungen" als Kategorie lagen Männer vorne. Und Anne hat das auf den Projektor gelegt und dann daraus gefolgert, dass man ja wohl endlich mal mehr für die Frauen tun müsste. Ich habe ja im Leben gute Erfahrungen dait gemacht, Leute, von denen du Hilfe willst, nicht zu antagonisieren.
Der nächste Vortrag war Hackerethik von Frank, dem ich am Ende mit dem Saalmikro die Frage stellen wollte, wann es mal wieder eine Alternativlos-Folge gibt, aber der olle Feigling hat keine Fragen genommen!1!!
Ich hörte unterdessen Gutes von dem wallet.fail-Vortrag gehört, den guck ich mir dann auf Video an. Und für mich war als nächstes der jährliche Starbug-Biometrie-Zertrümmer-Talk, diesmal über Venenerkennung. Das war bisher das Highlight der Veranstaltung, lasst euch den nicht entgehen!
Ich hatte übrigens einen Vortrag eingereicht, aber der ist nicht angenommen worden. Beim CCC wird das über ein Kommittee ausgewählt, um Vetternwirtschaft auszuschließen. Daher kommen halt manchmal auch echt gute Einreichungen wie dieser von mir unter die Räder. Ich werde mal gucken, ob ich mich noch reinwurmen kann, weil irgendwo anders einer abspricht oder so. Aber ich glaube eher nicht, und ich bin ja in guter Gesellschaft. Mein Kumpel Steini ist auch nicht reingekommen, was eine verdammte Schande ist. Guckt euch seine Vorträge auf früheren Congressen an, wenn ihr mir nicht glaubt!
Ein Bug in SQLite ist ziemlich apokalyptisch, das hat ähnliche Ausmaße wie zlib und libpng. Da sind einmal alle Browser von betroffen, und noch ein Haufen mehr. Ich wollte da nicht drauf linken, bis es mehr als Geraune gibt, und das gibt es jetzt.
Das interessante daran ist, dass SQLite eigentlich eine der Produktionen mit der größten Test-Suiten ist. Und trotzdem rutscht da sowas durch.
Ich muss also noch irgendwas im Startup-Code machen oder vielleicht in eine ELF-Sektion schreiben, das ich nicht kenne. Ich bin mir aber auch nicht sicher, in welchem Dokument das dokumentiert ist. Langfristig würde ich natürlich gerne gucken, ob ich nicht den ganzen Kram ersetzen kann, denn nur den Support für throw/catch und Stack Unwinding reinzuladen, das kostet im Moment mal eben 100k Binary. Zum Vergleich: Der Rest der dietlibc zusammen ist ~150k. Für das Unwinding muss man unter Linux leider vergleichsweise viel Aufwand treiben, inklusive Parsen von DWARF-Debuginformationen, soviel habe ich schon herausgefunden. Aber 100k Code erscheint mir so vom Bauchgefühl her nicht angemessen.
Update:Zum Vergleich:
-rwxr-xr-x 1 leitner users 74840 Dec 10 22:08 tinyldap
Update: Auflösung: Ich muss im Start-Code __register_frame_info aufrufen.
they leveraged an out-of-bounds write bug affecting WebAssembly to achieve code execution via NFC.Das war das Xiaomi. Das selbe Team hat auch das S9 exploitet, via Heap-Overflow im Baseband. Und ein Iphone X haben sie über Wifi über einen JIT-Bug übernommen.Ein zweites Team hat das Xiaomi über Wifi gehackt.
resulted in a photo getting exfiltrated from the targeted phone. ZDI says the exploit involved 5 different logic bugs, including one that allowed the silent installation of an app via JavaScript.und das Samsung-Phone über ein gehacktes Captive-Portal, und ein dritter Teilnehmer hat einen Type-Confusion-Bug im Browser benutzt, um auf dem Xiaomi Code auszuführen.Und das war nur Tag 1.
Spannend an dem finde ich vor allem den Teil hier:
[Feel free to send this to the FreeBSD lists or whatever to get it fixed. I honestly can't be bothered making a throwaway email and going through the subscription process, nor do I want "TheGrandSchlonging" to appear in FreeBSD commit logs.]TheGrandSchlonging is sein Reddit-Username.Und inhaltlich geht mir das ja ähnlich. Ich ärgere mich jedes Mal, wenn ich irgendwo einen Bug melden will, und die mich erstmal durch irgendeine Account-Prozedur durchtrichtern wollen. Das ist ja nicht so, als bin ich hier der Bittsteller, der was von euch will. Im Gegenteil. Ihr wollt was von mir. Nämlich dass ich euch von dem Bug erzähle, den ich gefunden habe. Also hört mal bitte auf, mir künstliche Barrieren in den Weg zu legen.
Ich hab eh schon vor Jahren völlig aufgehört, nach Bugs in kommerziellen Produkten zu suchen, außer ich werde dafür bezahlt. Und dieser Account-Bullshit und wie die Leute in den Bugtrackern dann teilweise mit ihren Usern umgehen, das ist echt abschreckend und führt nicht zu mehr gemeldeten Bugs.
Aktuelles Beispiel, auch wenn das kein Security-Bug ist, war für mich mpv. mpv ist das Nachfolge-Projekt von mplayer. Mit mplayer oder mpv spiele ich seit gefühlt 20 Jahren meine Video-Dateien ab und hören mir meine mp3-Sammlung unter Linux an. Das Programm ist für mich also eher wichtig. Ich hatte mir ja kürzlich einen Acer Swift 1 gekauft, weil der besonders gute Akkulaufzeit hat und sich besonders gut zum Video-Abspielen eignet dank Hardware-Decoding von H.264, H.265 inklusive 10-Bit Farbtiefe, und VP9. Linux unterstützt das. mpv unterstützt das. Ich spiele also mit mpv ein Video ab und kriege massives Stottern und Frame Dropping. Das habe ich sehr vielen Jahren nicht mehr erlebt, dass ein Player Frames droppt, weil die Performance nicht reicht. Da kommt dann noch so eine von-oben-herab-Fehlermeldung, dass dann wohl das System kacke sei, auf dem man gerade arbeitet, oder zumindest die Treiber, die man verwendet.
Ich habe also vlc probiert, und das flutscht. Da stottert nichts. Stellt sich raus: mpv hat zwar -vo vaapi und -vo xv (dekodiert mit CPU aber macht Farbraumkonvertierung und Skalierung in Hardware) und kann damit stotterfrei dekodieren, aber besteht per Default auf -vo gpu, und der macht irgendwelchen Shader-Kram, der auf Gamer-Hardware prima tut und womöglich auch bessere Qualität liefert (nicht dass ich das hätte beobachten können), und zusätzliche Filter erlaubt, die ich noch nie benutzt habe. Aber auf dem Gemini Lake Atom-Derivat in dem Swift 1 flutscht das halt nicht. Ich habe also einen Bug gefiled, dass sie in der Fehlermeldung möglicherweise auf -vo vaapi hinweisen könnten statt dem Benutzer die am wenigsten hilfreiche Meldung aller Zeiten zu geben ("du hast wohl Scheiß Hardware").
Es gibt auch ein mpv-Wiki, wo drinsteht, dass niemand jemals etwas anderes also -vo gpu nehmen soll, weil das so geil ist, und andere Alternativen werden dort auch gar nicht erwähnt.
Nun kann mir das ja eigentlich alles egal sein. Ich hab ja die Lösung gefunden, nämlich -vo vaapi (damit spielt das Gerät auf Akku über 10h am Stück Video ab und hat dabei eine CPU-Auslastung von unter 5%). Aber das Projekt liegt mir halt am Herzen. Schreiben die zurück: Deine Hardware ist kacke, nein wir ändern das nicht, und wenn wir da ranschreiben, dass vaapi weniger Strom verbraucht als gpu, dann benutzt ja niemand jemals gpu.
Ich kommentierte dann noch, dass wenn sie das nicht fixen, dass die Kunden dann halt zu vlc abwandern, wenn mpv "zu lahm" ist, was es ja nicht wirklich ist, aber es sieht halt so aus. Und sie sollen mal lieber ehrlich sein mit ihren Kunden. Daraufhin meinte dann jemand, ich könne ja gehen, wenn mir mpv nicht gefällt, und machte den Bug zu.
Liebe Leser, wenn ihr jemals in der Situation seit, einen Bugtracker zu pflegen, dann macht lieber gar nichts als euch so zu verhalten. User verprellen ist so das schlechteste, was man tun kann. Fragt euch mal selbst, ob ihr einem Projekt helfen wollen würdet, das euch beim ersten Versuch so den Stinkefinger ins Gesicht hält.
Ich erwähne das, weil FreeBSD so das Gegenteil davon ist. FreeBSD, PostgreSQL und LLVM sind Projekte, die mit Bugreports professionell, zeitnah und sauber umgehen, und wenig überraschend sind die auch echt erfolgreich am Ende. Projekte wie gcc, bei denen auf dem Bugtracker häufig eher User-Abwehr statt Bug-Beseitigung betrieben wird, geraten halt ins Hintertreffen. Und mpv, wenn es sich so verhält, wird als Privatprojekt von irgendeinem Frickel-Nerd in seinem Keller enden, das niemand kennt und niemand benutzt. Schade eigentlich, denn die verspielen da über Jahre aufgebautes Karma.
Update: Ein Einsender kommentiert:
es wird deutlich darauf lhingewiesen (https://www.freebsd.org/security/), dass security-related Krams per Mail an secteam@ berichtet werden soll/kann. Der Link steht auch im Default-motd, sollte also jeder FreeBSD-User mal gesehen haben :)
Oh das wusste ich nicht. Dann gibt es in der Tat nicht so viele Ausreden, den Bug auf reddit zu posten statt den FreeBSDlern zu mailen.
Update: mpv hat den Bug nicht nur geschlossen sondern als "too heated" gelockt, womit weitere Kommentare von Externen nicht mehr erlaubt sind. Gute Arbeit, Jungs. So strahlt man Souveränität aus.
Update: Haha, geil, jetzt werde ich da auch noch als Lügner bezeichnet. Natürlich schön nachdem man mir die Kommentiermöglichkeit weggenommen hat. Tolles Projekt, dieses mpv. Da will man doch mithelfen!1!!
Aber ein Detail noch: In der Zwischenzeit hat sich gezeigt, dass auch -vo gpu flutschen kann, wenn man bloß auch noch --hwdec=auto macht. Ja, ich bin genau so belustigt wie ihr. Die haben eine auto-Option für den Hardware-Decoder und machen die dann nicht an. Der Lacher ist ja, dass -vo xv auch Software-Decoding macht und bei weitem schnell genug ist. Wir wissen also zwei Dinge jetzt: Die CPU ist schnell genug für Software-Decoding, und das OpenGL ist schnell genug fürs Rendering. Aber in Kombination verkackt mpv es. Ich hätte ihnen ja beim Debuggen geholfen. Aber ich helfe nur Projekten, die ihren Usern Menschenwürde zugestehen.
Nun, es ist soweit. Hier sind die Folien von CppCon2018:
Better C++ using Machine Learning on Large ProjectsUnd was tun die da konkret?
- Identify buggy commits from the past
- Match some code contributions with past bugs
- Use ML to predict the riskiness of a commit
Ja super!
While the check at (A) tries to ensure that the buffer has enough space left to store the IA option, it does not take the additional 4 bytes from the DHCP6Option header into account (B). Due to this the memcpy at (C) can go out-of-bound and *buflen can underflow in (D) giving an attacker a very powerful and largely controlled OOB heap write starting at (E). (Danke, Ilja)
libssh versions 0.6 and above have an authentication bypass vulnerability in the server code. By presenting the server an SSH2_MSG_USERAUTH_SUCCESS message in place of the SSH2_MSG_USERAUTH_REQUEST message which the server would expect to initiate authentication, the attacker could successfully authenticate without any credentials.
Nein, kein Scherz. Einige von euch benutzen Google+. Tut nicht so, als sei es nicht so!1!!
Nun, die hatten da einen Datenreichtum.
It said a bug in its software meant information that people believed was private had been accessible by third parties.Google said up to 500,000 users had been affected.
Also … alle? Jeder zweimal? :-)Google wusste das im März und hat nichts gesagt. Weil, äh,
The WSJ quoted an internal Google memo that said doing so would draw “immediate regulatory interest”.Und wo kämen wir da hin!Immerhin ziehen sie jetzt Konsequenzen und machen Google+ zu.
Update: Brian Krebs fällt noch auf, dass man sich ja mit Facebook-Logindaten anderswo einloggen kann, und er hat mal bei Facebook nachgefragt. Die Antwort:
A Facebook spokesperson confirmed that while it was technically possible that an attacker could have abused this bug to target third-party apps and sites that use Facebook logins, the company doesn’t have any evidence so far that this has happened.
Klar hat jemand dein Geld gestohlen, aber wir haben noch keine Beweise dafür, dass er es auch ausgegeben hat!!1! Tolle Logik.
Ein Ansatz dafür war C++. In C++ ging es natürlich auch um einen Haufen anderer Dinge, aber es ging eben auch darum, Dinge, die häufig auf die Fresse fallen, wegzuabstrahieren. Man arbeitet nicht mehr mit C-Strings, die mit in-band-Signaling arbeiten (0-Byte = Stringende), sondern man hat eine String-Klasse, und die kennt die Länge. Niemand muss mehr mit strlen über alle Bytes iterieren, um die Länge zu finden.
Aber das ist ja nicht das einzige Problem in strings. Nehmen wir mal an, du hast einen String s, und willst das 100. Zeichen davon haben.
Dann machst du in C oder C++ s[99].
Was aber, wenn der String bloß eine Länge von 10 hat?
Tja, das ist dann ein Bug. Nun könnte man, wenn man eine Klasse in C++ hat, den operator[] überladen, und wenn der Index negativ oder größer als die Stringlänge ist, dann könnte man das erkennen und beispielsweise eine Exception werfen. Dafür sind die da. Für genau sowas.
Aber ... macht C++ das? Nein, machen sie nicht! Der Standard lässt das offen, ob die Implementation das abfangen soll oder nicht. Und dreimal dürft ihr raten, was die Implementationen da draußen folgerichtig alle machen! Richtig! Nicht checken.
Diese Art von Nachlässigkeit ärgert mich auf einem sehr fundamentalen Level. Da krieg ich Pickel und Bluthochdruck von. Wenn du schon den Aufwand auf dich nimmst, eine Abstraktion einzuziehen, dann gibt es echt keine Ausrede, da nicht auch gleich eine Fehlerklasse auszuschließen.
Nun nimmt man in C++ im Allgemeinen Iteratoren und nicht Index. Hat C++ also die Iteratoren richtig gemacht? Nein, auch nicht! Der Iterator ist unabhängig von der Basisklasse. Sagen wir mal, die Basisklasse ist ein Baum, und man hat einen Iterator, der beim 3. Element ist. Und man löscht jetzt dieses Element. Dann ist der Iterator ... ungültig. Warum eigentlich? Der Iterator ist doch eine Abstraktion. Die Abstraktion hätte man so machen können, dass der Container alle offenen Iteratoren in einer Liste hat, und wenn er Iteratoren invalidiert, dann sagt er den Iteratoren Bescheid. Und wenn dann jemand einen von denen verwenden will, dann platzt das Programm. So hätte man das machen sollen. Hat man aber nicht. Stattdessen ist das jetzt halt ein Bug, wenn jemand so einen Iterator verwendet. Und die Regeln dafür, wie man als Programmierer erkennen soll, ob ein Iterator noch gültig sind, sind obskur und weitgehend unbekannt. In typischem Code da draußen gilt das Prinzip Hoffnung.
Ich ärgere mich darüber, weil das unnötig war, und der Grund ist, wieso wir jetzt Rust haben. Rust kann noch mehr als ich hier skizziert habe. Rust verhindert auch Data Races. Ich will Rust nicht kleinreden. Aber man hätte den Bulk von der Zusatzleistung von Rust auch in C++ implementieren können. Nicht mal in der Sprache. In der Library. Mit bestehenden Compilern. Aber wir stehen ja anscheinend auf Schmerzen in der C++-Community.
Warum rante ich hier so lange über diesen alten Punkt rum? Weil es gerade einen Versuch gibt, für C++ ein paar Richtlinien zu erarbeiten. Arbeitet ab jetzt so, dann wird das alles besser. Dieses Projekt wird von einigen der wichtigsten Namen in der C++-Community gemacht. Es liegt offen auf github rum, man kann es dort auch direkt lesen, und es gibt eine Referenzimplementation, auch auf Github, von Microsoft. Ein Großteil von diesem Code arbeitet um Unzulänglichkeiten in irgendwelchen MSVC-Versionen herum, daher ist das so groß, und daher verwaltet Microsoft das auch. Es gibt auch alternative Implementationen.
Einer der Vorschläge aus dieser Library ist so genial wie einfach: span. span ist sowas ähnliches wie std::array -- es schafft einen STL-Container um einen Speicherbereich fester Länge herum. Der Unterschied ist, dass span einen existierenden Speicherbereich nimmt und als Container zugänglich macht, ohne die Ownership davon zu übernehmen. Das kann man also wunderbar z.B. fürs Parsen von einem Byteklumpen verwenden, der gerade über Netzwerk reinkam. Die Abstraktion weiß, wie groß der Speicherbereich ist, und kann dann ein für alle Mal alle Range-Checks unter der Haube erledigen beim Zugriff. Kein Inline-Rumgemurkse mehr mit irgendwelchen halbgaren Checks. Das macht die Abstraktion für dich. Geil!
So geil, dass das in C++20 Einzug erhalten soll. cppreference.com hat es schon dokumentiert. Es gibt zwei Arten von Range Check, die man da so braucht. Erstens: "Gib mir Byte 15" soll explodieren, wenn es nur 14 Bytes sind. Zweitens: "Gib mir mal den String von Byte 15 bis Byte 30" soll explodieren, wenn das nicht vollständig innerhalb des äußeren span liegt. Insbesondere auch dann, wenn Offset und Offset+Länge innerhalb des span liegen, aber es einen Integer Overflow bei der Addition gibt. Und tatsächlich: std::span bietet so eine Operation an. Gib mir den Teil von hier bis da als Unter-Span. Die Methode heißt std::span::subspan. So und was sehen meine entzündeten Augen da?
The behavior is undefined if either Offset or Count is out of range.ARE YOU FUCKING KIDDING ME?! Wieso überhaupt diesen Scheiß anbieten, wenn der nichts prüft!?!?Meine Güte, C++, so wird das nichts mehr mit euch. Es ist fast so, als WOLLTEN die, dass das immer alles kacke bleibt. Damit man mehr Consulting verkaufen kann oder so? Ich verstehe es nicht. Und dann wundern sich am Ende alle, wieso es so viele Sicherheitsprobleme gibt immer.
Ist nicht alles scheiße hier. Die GSL von Microsoft prüft ordentlich. Die GSL Lite prüft auch (aber nicht ordentlich, ich file gleich mal nen Bug). Aber wenn der Standard es nicht vorschreibt, hilft das ja alles nichts.
Es ist echt zum Heulen.
Gut, auf der anderen Seite werde ich nie arbeitslos mit meiner Security-Firma.
Update: Leser weisen darauf hin, dass man Bounds Checking auch von string und vector kriegen kann. Man muss nur nicht s[10] sondern s.at(10) schreiben. Das stimmt. Es tut nur in der Praxis niemand. Vielleicht weil es keiner weiß. Vielleicht weil Programmierer häufig der Meinung sind, sie brauchen keine Zusatzchecks, weil sie so genial sind. Wer weiß. Ich tippe: Weil es Scheiße aussieht.
Update: Ich freue mich sehr, dass jemand gemerkt hat, dass ich schrieb, das 100. Zeichen im String sei bei s[100]. Ist es nicht. Es ist hinter s[99]. In C und C++ fängt die Zählung bei 0 an. Vielleicht ist doch noch nicht alles verloren. :-)
Update: Ein Leser merkt an, dass Microsoft das Iteratoren-Problem erkannt hat und eine Lösung anbietet. Mal wieder. Microsoft waren auch die ersten, die den inhärenten Integer Overflow in operator new gefixt haben (nachdem ich sie darauf hinwies). Als ich bei clang den entsprechenden Bug gefiled habe, haben die das innerhalb von einem Tag gefixt. g++ brauchte Jahre, bis sie sich durchringen konnten. Wenn wir unsere digitale Infrastruktur so verkommen lassen, dann wird die Zukunft aber trübe aussehen für Open Source!
Update: Eine erschreckende Anzahl von Lesern schreibt mir jetzt, dass Range Checks ja Laufzeit kosten und C++ hat halt versprochen, da neutral zu bleiben. Ich habe vor über zehn Jahren einen Vortrag über Compiler-Optimizer gehalten. Was damals Stand der Technik war, nicht Science Fiction. Und da gibt es eine Sektion über Range Checks. Wisst ihr, was da steht? Guckt selbst! Ist auf meiner Homepage verlinkt. Ich warte solange. Fertig? Da steht: Range Checks kosten nichts. Warum? Zwei Gründe. Erstens kann der Compiler unnötige Range Checks wegoptimieren. Kann nicht nur, tut es. Die bleiben also überhaupt nur in den unoffensichtlichen Fällen da. Und wenn der Range Check im Code landet, dann spielt das auch keine Rolle, weil die CPU im Wesentlichen die ganze Zeit auf den Speicher wartet. Ein einziger L2-Cache-Zugriff dauert lange genug, um gleich mehrere Range Checks in der Latenz komplett zu verbergen. Und wir reden hier von einem Iterator, den du dereferenzieren willst. D.h. da ist garantiert ein Speicherzugriff. So und jetzt Hausaufgabe: Baut mal einen eigenen Vector mit Range Check und tut damit ein paar Dinge. Und dann guckt, ob der Compiler die Range Checks rausoptimiert. Und wenn nicht, dann macht mal einen Benchmark und versucht die Kosten für die Range Checks zu messen. Und DANN könnt ihr zurückkommen und mir Dinge zu erzählen versuchen.
Um die Benutzer zu verwirren.
Oh, ähm, ich meine, um sie NICHT zu verwirren!1!!
In this paper, we introduce a new defensive technique called chaff bugs, which instead target the bug discovery and exploit creation stages of this process. Rather than eliminating bugs, we instead add large numbers of bugs that are provably (but not obviously) non-exploitable.NNEEEEIIIIINNNN!!! Nicht noch mehr schlechte Ausflüchte für Leute, sich nicht zu bemühen, den Code bug-frei zu kriegen! (Danke, Ralph)
Jetzt kann ich endlich mit dem Kernel-TLS herumexperimentieren, den sie frisch eingebaut haben. Das ist m.E. ein zentraler Baustein, um ordentlich TLS-Privilege-Separation zu implementieren, ohne dabei krass Performance zu verlieren. Könnte sogar besser werden, die Performance.
So, bleibt nur noch ein Problem. Wieso das olle Chromebook einen Suspend wie ein Ausschalten behandelt. Das nervt schon ziemlich. Das ist die einzige PC-Hardware hier im Haus, auf der ich Suspend wirklich mal benutzt habe.
Auf der einen Seite ist das natürlich schockierend, dass ext4 so einen Bug hat. Nach all den Jahren sollte man denken, dass die Filesystem-Leute verstanden haben, dass man Längen in Strukturen nicht einfach trauen kann. Besonders ext4, denn das ist im Wesentlichen der Grund, wieso die Leute (auch ich) ext4 verwenden: Dass die einen fsck haben, der auch verlässlich funktioniert und die Lage nicht schlimmer macht.
Auf der anderen Seite war die Reaktion der Linux-Kernel-Leute innerhalb 24h, den Bug öffentlich zu machen in ihrem Bugtracker. Die machen also kein Security-Geheimhaltungs-Brimborium. Das ist schonmal gut. Und wenn man nach dem Problem googelt, findet man heraus, dass dieses Codestück als stinkend bekannt ist und da schon drei-vier Patches durchiteriert wurden, um das zu fixen. Ich frage mich, wieso man das Feature dann nicht wieder rausgeschmissen hat, wenn klar war, dass der Code stinkt.
BadMatch (invalid parameter attributes)ab. Ich habe den vim-Leuten einen Bug gemeldet, aber die konnten das auf ihren 32-bit-Systemen nicht nachvollziehen. Das scheint auch nur mit gtk+3 aufzutreten. Mein Verständnis von X11 ist, dass die Fehlermeldung asynchron reinkommt. Früher konnte man per Environment-Variable die Verarbeitung von asynchron auf synchron umstellen und dann kracht es direkt bei der Operation, die den Fehler verursacht. Das scheint aber nicht mehr zu gehen. Und jetzt weiß ich nicht, wie man sowas am geschicktesten debuggen würde. Falls das jemand weiß, würde ich mich über eine Mail freuen.
Vim: Got X error
Vim: Finished.
Update: Es kamen mehrere Tipps rein. Eine Empfehlung war xtrace, aber das hat bei mir zwar gvim gestartet aber keinen Trace ausgegeben. Eine andere Empfehlung war xtruss, damit kommt gvim aber gar nicht erst richtig hoch sondern failed mit einer "not supported" GDK-Fehlermeldung irgendwo wegen Shared Memory nehme ich an. Dann empfahl jemand xscope, und damit habe ich in der Tat einen Dump extrahiert gekriegt. In dem Dump sieht man, dass der X-Server dem gvim einen ungültigen Event-Typen zurückliefert. Ich vermute, dass das von fvwm kommt. Um diese Hypothese zu testen, habe ich twm genommen, wo das nicht passiert, aber twm unterstützt auch keine pixmaps mit Transparenz, also habe ich auch nochmal jwm installiert, und damit geht Minimieren und Restaurieren von gvim. Ich glaube jetzt also, dass das ein fvwm-Bug ist und habe bei denen einen Bug gefiled. Danke für die Hilfe!
Update: Oh und ich habe rausgefunden, dass man per gdb eine globale Variable setzen kann, um aus synchron zu schalten. Wenn ich das tue, tritt der Fehler nicht auf :-(
Also so langsam hab ich echt keinen Bock mehr auf diese ständige Terrorpanikmache bei Securitybugs. Heise besteht ja gefühlt auch nur noch aus Spectre-Geraune. Kommt mal bitte alle wieder runter. Unglaublich.
Brought to you by Debian! Money Quote:
I performed a full-upgrade on a system with little space on the root filesystem. This failed part way through due to running out of space. A while after resolving this and completing the upgrade, I found that: 1. The GNOME screensaver was no longer password locked
2. sudo and su failed
3. I could log in on a VT as any user without a password
Ach komm, Platte voll kommt sooo selten vor, das müssen wir doch nicht prüfen! Damit konnte niemand rechnen!Beachtet auch den zeitlichen Unterschied zwischen der Meldung des Bugs und dem "Me Too"-Posting unten. Hey, wieso würde Debian so einen Bug fixen? Betrifft doch nur Leute, deren Platte voll ist!
Die sind alle recht lustig, aber die Zweite ist episch:
Because of an implementation bug the PA-RISC CRYPTO_memcmp function is effectively reduced to only comparing the least significant bit of each byte.Are you fucking kidding me?!?
Der Fall zeigt aber auch sehr schön, dass du mit Obfuscation nur Amateure aufhältst. Player wie Microsoft haben dann halt genug Kohle und Manpower liquide, um deinen Scheiß zu reversen. Aber als Beobachter von außen, der sich für Malware-Details normalerweise nicht die Bohne interessiert, ist es schon beeindruckend, was die da alles an Bullshit eingebaut haben, um Reversing teurer zu machen. Die haben da unter dem ersten Jump-Obfuscation-Layer eine VM mit 33 Opcodes implementiert. Und MS hat die halt alle reversed. Die nächste Schicht war dann eine Sandbox- und Debugger-Detection. Dahinter kommt dann … noch eine andere VM mit 16 eigenen Opcodes.
Microsoft war übrigens durchaus beeindruckt von der Professionalität von Finfisher:
In the past, we have seen other activity groups like LEAD employ a similar attacker technique named “proxy-library” to achieve persistence, but not with this professionalism. The said technique brings the advantage of avoiding auto-start extensibility points (ASEP) scanners and programs that checks for binaries installed as service (for the latter, the service chosen by FinFisher will show up as a clean Windows signed binary).Oh na sowas, Code Signing hat uns nicht beschützt?! Hätte uns doch nur jemand gewarnt!!1!
To estimate the severity of this bug, we developed an exploit targeting SMTP daemon of exim. The exploitation mechanism used to achieve pre-auth remote code execution is described in the following paragraphs.Exim hat anscheinend von Anfang an einen off-by-one in ihrem Base64-Dekoder.
This bug has existed since before curl 6.0. It existed in the first commit we have recorded in the project. (Danke, Rene)
An older version of PHP in the vulnerable varieties had a use-after-free bug that opens a remote code execution vector. (Danke, Richard)
Hier ist DragonflyBSD dazu. Money Quote:
Unfortunately, the only mitigation possible is to remove the
kernel memory mappings from the user MMU map, which means that every single
system call and interrupt (and the related return to userland later) must
reload the MMU twice. This will add 150ns - 250ns of overhead to every
system call and interrupt. System calls usually have an overhead of only
100ns, so now it will be 250nS - 350nS of overhead on Intel CPUs.[…]
I should note that we kernel programmers have spent decades trying to
reduce system call overheads, so to be sure, we are all pretty pissed off
at Intel right now. Intel's press releases have also been HIGHLY DECEPTIVE.
[…]
These bugs (both Meltdown and Spectre) really have to be fixed in the CPUs
themselves. Meltdown is the 1000 pound gorilla. I won't be buying any new Intel chips that require the mitigation. I'm really pissed off at Intel.
OpenBSD macht drei Kreuze, dass sie zumindest auf ARM nicht betroffen sind.Und von FreeBSD hört man, dass Intel ihnen einen Tag vor Weihnachten (!) Bescheid gegeben hat. Hey, äh, Jungs, öhm, ihr müsst da mal kurz euren Code ein bisschen umschreiben!1!! Ja super!
Update: Hier ein Statement der Linux-Leute, die auch eher unzufrieden wirken.
Glaubt ihr nicht? Hier:
Is this a bug in Intel hardware or processor design?No. This is not a bug or a flaw in Intel products. These new exploits leverage data about the proper operation of processing techniques common to modern computing platforms, potentially compromising security even though a system is operating exactly as it is designed to. Based on the analysis to date, many types of computing devices — with many different vendors’ processors and operating systems — are susceptible to these exploits.
Das ist eine dreiste Lüge. Erstens sind andere Prozessoren nur von einem Bruchteil des Problems betroffen, Intel sind die einzigen, die das so richtig mit Anlauf verkackt haben. Zweitens ist das natürlich keine akzeptable Begründung, wieso das kein Bug ist, wenn Intel das genau so haben wollte. Das heißt eher, dass Intel zu inkompetent ist, um Prozessoren zu bauen. Dass sie uns das jetzt so in schwarz auf weiß als Zertifikat ausstellen und in die Hand drücken, das haut mich jetzt ziemlich vom Hocker. Man würde denken, dass die aus den ganzen bisherigen Bugs gelernt haben. Vielleicht hat der Rest auch ihre Aktien abgestoßen und scheißen jetzt auf den Rest der Geschichte? Das ist mal echt krass.Ein Glück, dass AMD Ryzen rechtzeitig fertig gekriegt hat. So hat man jetzt eine Ausweich-Option. Weia.
Die Maßnahmen, die sie da gerade durchführen, um das zu bekämpfen, sind potentiell mit sehr großen Performanceeinbußen verbunden (weil pro Syscall-Kontextwechsel ein TLB-Flush notwendig wäre).
Ich mache mir keine Sorgen. ASLR ist eh kein Schutz sondern nur eine Mitigation, d.h. es verhindert keine Sicherheitslücken, es macht sie nur schwerer auszunutzen. Ein Sicherheitskonzept, dessen Sicherheit auf ASLR basiert, ist also eh wertlos. Das schaltet man an, weil es da ist und nichts kostet.
Wir werden mal sehen müssen, wie stark die Performanceeinbußen in der Praxis sind. Die werden am Schlimmsten bei Workloads mit vielen Syscalls sein, d.h. Netzwerkservices und sonstige I/O-intensive Geschichten. Und natürlich Virtualisierung, klar. Aber wer das macht, erwartet ja eh keine gute Performance.
Ich mache mir da jetzt jedenfalls keine schlaflosen Nächte deswegen. Andere Maßnahmen wie Seccomp-Sandboxing und W^X sind viel wichtiger als ASLR. Und eigentlich war ASLR ja auch bloß eine weitere Ausrede dafür, unsere Software weiterhin nicht ordentlich zu auditieren. Wir haben ja ASLR!1!! Ich sehe das also sogar verhalten optimistisch. Vielleicht fangen die Leute jetzt mal an, auf Security zu achten. Wenn die Mitigations öffentlichkeitswirksam wegbrechen.
Update: Es sieht so aus, als sei das mehr als ASLR-Bypass, als könne man so vom User Space aus Kernel Memory lesen. AMD ist nicht betroffen, wie es aussieht.
Ist das schlimm? Ja, ist es. Der Kernel hat beispielsweise der Buffer Cache im Speicher, und da könnten Inhalte aus irgendwelchen Dateien stehen, die der User sonst nicht lesen könnte, ich sage mal Krypto-Schlüssel oder so. Oder vielleicht die letzten Tastendrücke, und so könnte man die Passphrase auslesen. Das ist ein Riesenproblem. Das ist schlimm genug, dass Intel ein Recall droht, wenn wir sie da jetzt nicht um irgendwelchen Performance-killenden Maßnahmen drumherummogeln lassen.
Update: Das erinnert inhaltlich stark an das "Ach du Kacke"-Paper vom August.
Update: Hier ist ein Blogpost über Intel-CPU-Bugs von Anfang 2016 als Kontext.
Einmal mit Profis arbeiten!
Sex toy company admits to recording users' remote sex sessions, calls it a 'minor bug'Ach komm, wollen wir mal nicht päpstlicher sein als der Papst!1!!
Das USB-Subsystem scheint in beklagenswertem Zustand zu sein. Hier sind die Bugs, die das Tool gefunden hat. Ja, das ist ein Fuzzer. Ja, der Code ist so beschissen, dass man mit einem Fuzzer Bugs findet.
Das gab übrigens, wie ihr euch sicher vorstellen könnt, einige interessante Gespräche mit Microsoft-Mitarbeitern, als ich da beruflich vor Ort war :-)
Jedenfalls hätte ich mir damals nicht träumen lassen, wenn ich meine Software nicht nach Windows portiere, dass Microsoft dann halt Windows zu meiner Software portieren würde. Das Windows Fall Creators Update kommt mit dem "Windows Subsystem for Linux". Das habe ich gerade mal ausprobiert und darin eines meiner dietlibc-Binaries gestartet, das ls von embutils. Das erste Binary, das ich probiert habe, segfaultete direkt. Also habe ich nochmal alles make clean gemacht, neu gebaut, das neue Binary mit Debug Info rüberkopiert, aufgerufen, und es tat einfach.
Jetzt bin ich ja doch ziemlich geflasht, muss ich euch sagen.
Das muss ich erstmal verdauen.
Der Bug ist so blöde, das kannste dir gar nicht ausdenken. Setzt euch mal stabil hin:
“The problem is, the RSA private key that belongs to the public pair that was used for the signature checking, could be found on the internet as part of an example application of a software library,” according to his research.Das ist ja NOCH geiler als seinen Private Key bei Github hochladen! Jemand anderes Private Key von Github nehmen! Hey, bei so einem Hersteller will man doch seine Infrastruktur einkaufen!1!!Übrigens, mal am Rande:
Rad said the vulnerabilities were discovered on May 10 and initial disclosure of the bugs to Lenovo was May 14. Ten days later Lenovo confirmed the vulnerabilities with coordinated public disclosure occurring on Oct. 5.Die haben ernsthaft seit Mai auf dem Problem gesessen. Wenn die Lösung war, einen neuen Key zu erzeugen und auszurollen. SEIT MAI.Oh und die Auswirkung? Remote Code Execution natürlich!
Der Intel Compiler kommt mit neueren glibc Versionen nicht zurecht, da diese einen Bug im Intel Compiler exponieren, der zu "unpredictable system behaviour" führt. Bei uns auf dem HPC Cluster hat sich das so manifestiert, dass unsere Benutzer nach dem Update von CentOS 7.3 auf CentOS 7.4 (dieses Update der glibc exponiert den Intel Bug) bei Simulationen (z.B. mit Kommerziellen "Finite Element" Applikationen wie ANSYS CFX, 3DS Abaqus etc.) falsche Resultate bekamen:Und weil das so grandios ist, kommt hier die technische Erklärung, was da vor sich geht:
- Simulationen die vor dem Update konvergierten tun dies nicht mehr
- Simulationen brechen ab, weil an verschiedenen Stellen NaN's raus kommen wo das nicht sein sollte.
- Bei Simulationen kommen andere Zahlen raus als vor dem Update
Der Bug betrifft potenziell alle mit Intel (Versionen älter als 17.0 Update 5) kompilierten Binaries und Bibliotheken auf Systemen mit Intel CPUs, welche AVX unterstützen.
According to x86-64 psABI, xmm0-xmm7 can be used to pass functionKeine weiteren Fragen, Euer Ehren!
parameters. But ICC also uses xmm8-xmm15 to pass function parameters
which violates x86-64 psABI. As a workaround, you can set environment
variable LD_BIND_NOW=1 by# export LD_BIND_NOW=1
Update: Ich sollte vielleicht mal erklären, was hier vor sich geht. Das ABI ist die Spezifikation dafür, wie man auf einer gegebenen Plattform auf Maschinencode-Ebene Argumente an Funktionen übergibt, und welche Registerinhalte Funktionen überschreiben dürfen, welche sie sichern müssen. Intel hat die Spec gesehen und gesagt "Hold my beer! Die Register dahinten benutzt keiner! Die nehm ich mal!" Das ABI hat aber ganz klar gesagt, dass die eben nicht frei sind.
Das Szenario hier ist: Der Compiler generiert Code für einen Funktionsaufruf. Nun könnte man sagen, hey, wenn der Intel-Compiler beide Seiten erzeugt hat, dann kann ja nichts schiefgehen. Aber es kann halt doch was schiefgehen. Wenn man ein dynamisch gelinktes Binary hat, dann geht der Funktionsaufruf eben nicht zur Funktion, sondern zum Wert in einer Tabelle. Die Einträge in der Tabelle zeigen initial auf ein Stück Code in der glibc, der dann die Adresse für das Symbol herausfindet und in die Tabelle einträgt und dann dahin springt. Die Idee ist, dass so eine Tabelle mehrere Zehntausend Einträge enthalten kann bei großen Binaries, und wenn man die alle beim Start von dem Binary auflöst, dann ergibt das eine spürbare Verzögerung. Denkt hier mal an sowas wie Firefox oder clang von LLVM. Daher löst man erst beim ersten Aufruf auf. Mit LD_BIND_NOW=1 kann man der glibc sagen, dass er bitte alles am Anfang auflösen soll, nicht erst später.
Was hier also passiert ist, ist dass der glibc-Code, der die Symbolauflösung macht, sich an das ABI gehalten hat und die u.a. für ihn reservierte Register benutzt hat. Und da hatte der Intel-Compiler aber Argumente reingetan. Die hat der Code zum Symbolauflösen dann mit Müll überschrieben. Die glibc wäscht hier ihre Hände in Unschuld (und ich hätte nicht gedacht, dass ich DAS nochmal sagen würde). (Danke, Samuel)
Und ironischerweise im neuen DNSSEC-Support des DNS-Clients bei Windows. Auf mich hört ja immer keiner, wenn ich sage, dass Komplexität der Feind ist. Ach komm, das ist doch ein Security-Feature! Da kloppen wir noch ein paar metrische Tonnen Code drum herum, ist doch für die Security!1!!
New hotness: Code Execution in MS Word ohne Makros und ohne Memory Corruption. Per DDE!
Aber keine Sorge, das ist kein Bug. Das soll so.
26/09/2017 – Microsoft responded that as suggested it is a feature and no further action will be taken, and will be considered for a next-version candidate bug.
Der Typ, der mruby anbietet, hat gerade eine Bug-Lavine von biblischen Ausmaßen abgekriegt, nachdem eine Firma eine Bug Bounty für eine auf mruby basierende Webplattform gemacht hat. Die Firma dachte sich, sie legt man $20k zurück. Am Ende waren es eher so $500k, die sie auszahlen mussten.
Und der Maintainer sagt dazu was? Na klar!
Ruby is a complicated language which makes every Ruby implementation complex and likely to contain bugs. As a matter of fact I notice at least one of the bugs which was found in mruby to be also applicable to standard C Ruby (MRI). […] C sucks as a language to write stable code in a simple manner.Ist halt schwierig! Und im Übrigen ist C Schuld! Nicht etwa ich, nein mein Herr! Ich bin hier das Opfer!1!! (Danke, Daniel)
Jetzt muss man den Kernel updaten, wenn es mal wieder ein TLS-Update gibt!? Ein Bug im TLS-Code liefert jetzt Kernel-Privilegien?! Der Kernel macht X.509 und ASN.1?! Womit so ziemlich jeder andere auf die Fresse geflogen ist, der das probiert hat?!?
Daher dachte ich mir, ich gebe mal zu Protokoll, dass ich das für eine tolle Idee halte. Und zwar ist nicht das Handshake im Kernel (das ist der komplexe Teil am Anfang, der mit den ganzen Protokollunwägbarkeiten), sondern der Kernel übernimmt lediglich die Transportverschlüsselung, nachdem der Schlüssel ausgetauscht ist. Ein bisschen Einkapseln, symmetrische Krypto drüberlaufen lassen, fertig. Da kann man immer noch was falsch machen, klar, aber das ist, von der Angriffsoberfläche her, sowas wie 1% von TLS. Da mache ich mir wenig Sorgen.
Und auf der anderen Seite steht der Vorteil. Wenn man im Moment einen Client hat, der irgendwas verkackt, dann kann man da mit beim System beliegenden Tools wie strace die System Calls tracen lassen. Da steht dann sowas wie:
write(3,"GET /foo.txt HTTP/1.1\r\nHost: example.com:80\r\n\r\n",47)Da kann man sehen, was der Client zu tun versucht hat. Und man kann die Antwort des Servers sehen. Wenn der Client TLS benutzt, dann sieht man bei strace nur noch die verschlüsselten Daten.
Wenn ich den Zugriff habe, den strace benötigt, kann ich natürlich auch die unverschlüsselten Daten abgreifen. Das ist also kein Schutz gegen jemanden mit diesem Level an Zugriff. Aber es macht Debugging und Tracing halt sehr schwierig. Mit TLS im Kernel würde man wieder den Klartext in read und write sehen.
ALLEINE DAFÜR ist das schon eine Sache, die ich haben will.
Es gibt noch einen weiteren Vorteil, der ist mir aber nicht so wichtig. Der Webserver kann dann wieder zero-copy TCP mit sendfile() machen. Das ist dann nicht wirklich zero copy, weil der Kernel ja verschlüsselt. Der kann also nicht einfach DMA aus dem Buffer Cache machen. Aber immerhin, eine Kopie weniger. Das war auch der Grund, wieso dieser Patch überhaupt gemacht wurde.
Und der andere Vorteil ist, dass man mit Debugging-Zugriff im System dann auch die Daten im Transit verändern kann. Das ist wichtig für Pentesting, aber auch für automatisiertes Testing kann das nützlich sein. Im Moment muss man dann einen Proxy aufsetzen und im System dessen Zertifikat als Trusted eintragen und so weiter.
Diese Eingriffe gehen wohlgemerkt auch jetzt schon alle mit Debugging-Rechten. Sie sind nur viel anstrengender umzusetzen.
Irgendeinen Grund muss es doch geben, egal auf welcher Seite der Barrikaden man jetzt persönlich steht, dass die Projekte anscheinend alle von fiesen weißen Misogynisten und Schwulenhassern geleitet werden.
Meine Projekte sind bisher zu klein, als dass ich da eine Welle aus Troglodyten hätte, gegen die ich Schutzwälle aufbauen müsste, aber zu meinen Usenet-Zeiten erinnere ich mich noch gut an die Wagenburg-Mentalität, die sich von ganz alleine aufbaute, weil gefühlt immer und immer wieder immer neue Idioten reinkamen und ganz selbstverständlich die selbe Scheiße von sich gaben, die vorher schon hundert und tausend Mal widerlegt wurde. Kommt natürlich auf die Gruppe an. Ich rede jetzt von technischen Gruppen.
Auf Mailinglisten war das ähnlich. Ich erinnere mich da an bugtraq und linux-kernel, die ich mal eine Weile abonniert hatte. Das war nicht auszuhalten. Die eine Hälfte der Regulars haben dann halt die Idioten alle ins Killfile getan, aber das hilft nur gegen Idioten, die länger da bleiben, nicht gegen eine Flut von unfähigen Newbies und "bringt mir mal kurz Hacken bei"-Klappspaten. Aus dieser Erfahrung kann ich mir gut vorstellen, dass sich bei größeren Projekten entweder ein Gleichgewicht einstellt, weil die Umgebung eben so lange unfreundlicher und abstoßender wird, bis das Flutproblem weg geht. Oder das Projekt stirbt halt. Oder vielleicht stirbt auch nur die Mailingliste und der einsame Wolf popelt noch insgeheim an seinem Projekt weiter. Oder der einsame Wolf hat unendlich Kraft und Geduld und reibt sich sein Leben lang an seiner Umwelt auf. Ein Schicksal, dass man seinem übelsten Feind nicht wünschen würde.
Für mich als steinalter Regular fühlt sich jedenfalls diese neue Welle aus Inklusivitäts-Schneeflocken genau wie die alte Welle der AOL-Idioten an. Gut, die fordern inhaltlich was anderes, aber praktisch ist da kein Unterschied. Die halten sich 100% im Recht, die Frage stellt sich überhaupt nicht für die, ob sie sich möglicherweise gerade wie Arschlöcher verhalten. Sie kommen rein, stellen Forderungen, und wenn die nicht sofort beantwortet werden — für freie Software, wohlgemerkt, an der niemand was verdient! —, dann kommen sie mit Geld-Zurück-Mentalität und drohen damit, schlechte Bewertungen zu hinterlassen. DIE Art von Person. So "ihr habt euch jetzt gefälligst alle nach mir zu richten"-Leute, die in ihrem Leben noch keine Leistung erbracht haben, außer andere zu drangsalieren. So fühlte sich das damals bei AOL an. Und ich kann da gerade aus der Ferne keinen großen Unterschied erkennen, muss ich sagen. Wenn ihr Schneeflocken euch so sicher seid, dass ihr besser wisst, wie man das macht, dann macht doch mal ein eigenes Projekt. Nein, nicht jemand anderes Arbeit forken. Kommt erst mal dahin, dass ihr Code habt, den jemand forken könnte. Ich kenne kein einziges erwähnenswertes Projekt von solchen Leuten. Nicht eines. Ich kenne die immer nur als marodierende Barbaren, die in anderer Leute Projekten einfallen und alles kaputtmachen und am Ende noch den Code annektieren und abforken wollen, der aus freien Stücken und nobler Grundhaltung der Welt kostenlos zur Verfügung gestellt wurde. Ich habe jetzt eine Weile versucht, Mitgefühl zu entwickeln. Es will mir nicht gelingen.
Dabei ist es so einfach, sich in einem Projekt Respekt zu erarbeiten. Leiste einfach was. Erwarte nichts als Gegenleistung. Problem: Jede Minute über dich oder deine Leistungen reden macht 10 Minuten tatsächliche Leistung kaputt.
Das sind die Regeln.
Niemand schuldet euch die freie Software, und niemand schuldet euch Support für die freie Software, und euch mitmachen zu lassen schuldet euch auch niemand. Wer herkommt und Forderungen stellt, der hat sich sofort 100 Minuspunkte erarbeitet. Daraufhin kriegt der erst Recht keine Hilfe mehr und wird im Gefühl bestärkt, in einer feindlichen Umgebung zu sein.
Ist alles so einfach, und so berechenbar. Niemand verhält sich hier irrational. Idioten wird es immer geben. Sei einfach keiner von ihnen. Ganz einfach!
Der Rant hier kommt daher, dass ich die Tage einen Bug in umatrix filen wollte. Der Autor hat das Bugtracking-System zugemacht. Oben stand klar und deutlich drüber: Keine Bugs für Seiten melden, die man sich kaputtkonfiguriert hat. Und die Leute haben das gesehen und trotzdem lauter solche Bugs aufgemacht. Also hat der Autor das Bugtracking-System zugemacht und jetzt ist es für alle Scheiße. Und ich bin mir fast sicher, dass keiner von denen sich im Unrecht wähnt, oder auch nur verstanden hat, dass er das gerade für alle kaputt gemacht hat. Die legen sich selbst gegenüber das bestimmt genau so zurecht, wie die SJWs sich die Welt zurechtlegen.
Völlig unvermittelt und ohne Provokation hat der fiese weiße Projektmaintainer seine Privilegien über den Github-Account genutzt, um mich zu unterdrücken, indem er meine Bugs nicht mehr annimmt! Da sieht man mal wieder, dass das nichts wird mit alten weißen Männer, die ihre Privilegien nicht gecheckt haben!1!!
Update: Kris hat einen "Gegenrant" dazu gemacht. Über den hab ich mich inhaltlich so geärgert, dass ich ihm eine lange böse Mail geschickt habe :-)
Es geht direkt mit einem Strohmann los, "programmers are able to do anything just because they are able to do one thing". Ich hatte tatsächlich das genaue Gegenteil davon behauptet. Dann fand ich seine Übersetzung an einer Stelle doof, aber Schwamm drüber. Auffällig fand ich, dass die Situation, die er beschreibt, genau die ist, die ich auch beschrieben habe. Nur dass er sie sich schönredet. Ich habe auch auf Mailinglisten und in Newsgroups rumgehangen und sogar die FAQ erstellt und geupdated. Ich habe wie Kris pro Tag 60 Minuten oder so damit verbracht, die Postings durchzugehen und jeweils den Link auf den FAQ-Eintrag zu mailen. Natürlich haben wir den Leuten auch erklärt, dass hier alle unentgeltlich arbeiten, und dass das ein Community-Projekt ist, und sie herzlich zum Mitmachen eingeladen sind, und zwar nicht nur Patches sondern auch Dokumentation und Community Management. Jeder nach seiner Fasson.
Aber aus meiner Perspektive ist das ein Todesmarsch durch die Wüste der Verdammnis. Eine Stunde pro Tag, die dir niemand zurück gibt. Klar hatte ich damals auch ein paar "Jünger", die das gut fanden und mitgeholfen haben. Aber im Wesentlichen habe ich da wie Sisyphos einen großen Stein einen Berg hochgerollt, und kam nicht voran.
Kris schildet genau das selbe, aber fokussiert sich auf die positiven Aspekte. Aus meiner Sicht ist das eine enorme Leistung, sich so zu bullshitten, dass man dieses nie endende Jammertal jahrelang erdulden kann, und am Ende noch der Meinung ist, man habe etwas zum Besseren gewandelt. Ich bin Kris übrigens ewig dankbar für seine Arbeit in de.comp.lang.php, denn die ganzen PHP-"Entwickler", die er da nicht rausgeekelt hat, sondern mit seiner Inklusivität ins Boot geholt hat, die haben die Altlasten hinterlassen, mit deren Aufräumen ich heute mein Brot verdiene :-)
Aber mit meiner ursprünglichen Fragestellung hat sein PHP-Community-Zeug nichts zu tun, denn er hat da eine User Community gepflegt. Bei vim (dem Editor) haben wir relativ früh die Mailingliste gespalten, in "für Developer" und "für User". Das hat gut funktioniert, weil die User-Fragen nicht mehr die Developer vom Arbeiten abgehalten haben. Aber ob da jetzt ein Kris bei der User-Mailingliste mithilft oder nicht, das spielt für meine Fragestellung keine Rolle, weil meine Frage ist, was man von den Autoren einer freien Software erwarten kann.
Ich bleibe bei meiner Linie, dass man von Fragestellern ein Mindestmaß an Respekt erwarten kann. Und dazu gehört: Filed keine Bugs, die schon jemand anderes gefiled hat. Stellt keine Fragen, die in der FAQ beantwortet werden, oder die im Archiv der letzten Woche schon mal beantwortet wurden. Nervt nicht rum, wenn euch niemand hilft, sondern versteht, dass das alles Freiwillige sind und bietet daher lieber von euch aus Hilfe an, als von anderen Hilfe einzufordern.
Allerdings gibt es halt beim Selberbauen immer mal wieder Stress.
Eine Weile gab es Konflikte, weil Firefox auf einer über 10 Jahre alten Version von GNU autoconf bestand, die ich nicht hatte.
Dann gab es Ärger, weil Firefox H.264-Playback (Youtube und co) nur abspielen wollte, wenn man gstreamer installierte — aber es bestand auf einer 10 Jahre alten Gammelversion, die schon längst nicht mehr gewartet wurde.
Inzwischen hat Firefox auf ffmpeg umgestellt, und das tat auch eine Weile ganz gut, aber vor ein paar Tagen stellte es die Arbeit ein. Ich bin dann auf die Vorversion und zurück und habe mir das für das Wochenende vorgenommen. Jetzt ist Wochenende, und ich habe erstmal die neue glibc 2.26 installiert (die endlich reallocarray von OpenBSD übernommen hat, und einen per-Thread malloc-Cache hat, was die Performance massiv verbessern sollte in Programmen mit mehreren Threads).
Das brach mir dann erstmal alles.
Die Shell konnte plötzlich nicht mehr meinen Usernamen herausfinden, screen wurde konkreter und sagte, getpwuid könne meinen User nicht auflösen. Sowas gibt es bei glibc häufiger, weil die gerne mal Dinge als "deprecated" markieren, für die es keinen Ersatz gibt. Zum Beispiel pt_chown vor einer Weile. Das war halt unsicher, also haben sie es weggemacht. pt_chown ist das Vehikel, über das die einschlägigen libc-Routinen (grantpt) ein PTY allozieren, und es liegt in /usr/libexec, wenn es denn überhaupt liegt. Und plötzlich kam mein X nicht mehr hoch, weil mein X solange läuft, wie mein Terminal in X läuft, und das konnte kein PTY mehr allozieren.
Später hat glibc dann Sun RPC rausgeschmissen, und dann ließ sich mount(8) nicht mehr bauen. Ja super. Und jetzt haben sie nsl für obsolet erklärt und in nss ausgemistet (NIS rausgekantet und so). Gut, NIS verwende ich nicht. Als das nicht ging, habe ich halt neu gebaut, diesmal mit --enable-obsolete-nsl, aber das brauchte auch nichts. Stellt sich raus: in meine /etc/nsswitch.conf stand drin:
passwd: compatUnd das sorgte dafür, dass die glibc libnss_compat.so oder so zu laden versuchte, und das gibt es nicht mehr. Die glückbringende Änderung war dann:
shadow: compat
group: compat
passwd: filesSeufz. Bei solchen Gelegenheiten bin ich ja immer froh, dass mein getty und mein login gegen dietlibc gelinkt sind, und für Notfälle noch eine diet-shell rumliegt. So komm ich auch nach solchen glibc-Sabotageakten immer noch irgendwie ans System ran und kann Dinge fixen.
shadow: files
group: files
Aber eigentlich wollte ich ja von Firefox erzählen. Nach dem glibc-Update baut auch Firefox nicht mehr, weil glibc in sys/ucontext.h eine struct von struct ucontext zu struct ucontext_t umbenannt hat. Ich bin mir sicher, dass es da Gründe für gab, aber meine Phantasie reicht nicht, um mir welche auszudenken. Was für ein Scheiß ist DAS denn bitte?! Firefox hat einen Crash Reporter, und der will halt in diesen Strukturen herumfuhrwerken, weil man das tun muss, wenn man sehen will, in welchem Zustand das Programm beim Crashen war.
Gut, nur ein Dutzend Dateien musste ich anfassen, dann baute Firefox wieder. Aber H.264 war immer noch kaputt.
Und die Story ist richtig interessant, daher will ich sie hier mal bloggen. Wenn man so ein Problem hat, dann ist unter Linux eine der ersten und besten Debugmöglichkeiten, dass man strace benutzt. Programme unter Linux laufen im User Space, und die interagieren mit dem Kernel über Syscalls. strace fängt die Syscalls ab und gibt ihre Argumente und Ergebnisse aus. Hier ist ein Beispiel:
$ strace /opt/diet/bin/cat true.cHier sieht man ganz gut, was cat tut. execve gehört noch nicht zu dem cat selber, das ist der Aufruf von dem cat. arch_prctl ist ein Implementationsdetail, das man auf x86_64 macht, um thread local storage einzurichten (die libc weiß an der Stelle nicht, dass cat das nicht benutzt). strace auf Firefox ist natürlich viel umfangreicher, aber mit ein bisschen Geduld kann man da trotzdem sehen, was passiert, bzw. was nicht passiert. Und zwar sah ich das hier:
execve("/opt/diet/bin/cat", ["/opt/diet/bin/cat", "true.c"], [/* 60 vars */]) = 0
arch_prctl(ARCH_SET_FS, 0x7fff5e690f70) = 0
open("true.c", O_RDONLY) = 3
read(3, "int main() {\n return 0;\n}\n", 65536) = 27
write(1, "int main() {\n return 0;\n}\n", 27int main() {
return 0;
}
) = 27
read(3, "", 65536) = 0
close(3) = 0
exit(0) = ?
+++ exited with 0 +++
7194 openat(AT_FDCWD, "/usr/lib64/libavcodec-ffmpeg.so.57", O_RDONLY|O_CLOEXEC) = 257
7194 --- SIGSYS {si_signo=SIGSYS, si_code=SYS_SECCOMP, si_errno=EEXIST, si_call_addr=0x7fc218252840, si_syscall=__NR_openat, si_arch=AUDIT_ARCH_X86_64} ---
7194 socketpair(AF_UNIX, SOCK_SEQPACKET, 0, [39, 40]) = 0
7194 sendmsg(36, {msg_name=NULL, msg_namelen=0, msg_iov=[{iov_base="\0\0\0\0\0\0\10\0\0\0\0\0\0\0\0\0", iov_len=16}, {iov_base="/usr/lib64/libavcodec-ffmpeg.so."…, iov_len=35}, {iov_base=NULL, iov_len=0}], msg_iovlen=3, msg_control=[{cmsg_len=20, cmsg_level=SOL_SOCKET, cmsg_type=SCM_RIGHTS, cmsg_data=[40]}], msg_controllen=24, msg_flags=0}, MSG_NOSIGNAL <unfinished …>
7196 <… recvmsg resumed> {msg_name=NULL, msg_namelen=0, msg_iov=[{iov_base="\0\0\0\0\0\0\10\0\0\0\0\0\0\0\0\0", iov_len=16}, {iov_base="/usr/lib64/libavcodec-ffmpeg.so."…, iov_len=8194}], msg_iovlen=2, msg_control=[{cmsg_len=20, cmsg_level=SOL_SOCKET,cmsg_type=SCM_RIGHTS, cmsg_data=[66]}], msg_controllen=24, msg_flags=MSG_CMSG_CLOEXEC}, MSG_CMSG_CLOEXEC) = 51
7194 <… sendmsg resumed> ) = 51
7196 openat(AT_FDCWD, "/usr/lib64/libavcodec-ffmpeg.so.57", O_RDONLY|O_NOCTTY|O_CLOEXEC <unfinished …>
7194 close(40 <unfinished …>
7196 <… openat resumed> ) = 95
7194 <… close resumed> ) = 0
7196 sendmsg(66, {msg_name=NULL, msg_namelen=0, msg_iov=[{iov_base="\0\0\0\0", iov_len=4}], msg_iovlen=1, msg_control=[{cmsg_len=20, cmsg_level=SOL_SOCKET, cmsg_type=SCM_RIGHTS, cmsg_data=[95]}], msg_controllen=24, msg_flags=0}, MSG_NOSIGNAL <unfinished …>
7194 recvmsg(39, <unfinished …>
7196 <… sendmsg resumed> ) = 4
7194 <… recvmsg resumed> {msg_name=NULL, msg_namelen=0, msg_iov=[{iov_base="\0\0\0\0", iov_len=4}], msg_iovlen=1, msg_control=[{cmsg_len=20, cmsg_level=SOL_SOCKET, cmsg_type=SCM_RIGHTS, cmsg_data=[40]}], msg_controllen=24, msg_flags=MSG_CMSG_CLOEXEC}, MSG_CMSG_CLOEXEC) = 4
Die Ausgabe ist ein bisschen verwirrend mit dem unfinished und resumed; das kommt daher, dass Firefox mehr als einen Prozess/Thread aufmacht, und die miteinander reden, und ich alle von denen auf einmal beobachte. Aber mal grob: Prozess A ruft openat(AT_FDCWD,…) auf, das ist äquivalent zu open(…). Kriegt als Ergebnis 257 und direkt ein Signal SIGSYS mit si_code SYS_SECCOMP.Das ist ziemlich coole Scheiße, weil das genau das ist, was ich auf dem 32c3 in meinem Vortrag "Check your privileges" als Broker-Architektur vorgestellt hatte. Die haben das aber nicht über Überladen von openat gemacht, sondern die haben das so gemacht, dass SECCOMP nicht den Prozess abbricht sondern dieses Signal schickt. Das Signal fangen sie dann ab, und der Handler von dem Signal kann dann nachvollziehen, was der Code zu tun versucht hatte, in diesem Fall openat, und das anders lösen — nämlich über sendmsg an den Broker, wie wir in dem strace schön sehen können. Der Broker macht recvmsg, kriegt die Anfrage (und wir sehen in den Daten von dem sendmsg auch schön den Dateinamen), und öffnet die dann. Die Zahl am Anfang ist übrigens die PID bzw. Thread-ID.
Der Broker macht dann selber nochmal openat, hat keinen SECCOMP-Filter installiert, das openat läuft durch, und dann schickt der Broker mit dem zweiten sendmsg oben den Deskriptor 95 zurück an den anfragenden Prozess in der Sandbox. Der kriegt das dann in dem recvmsg als Deskriptor 40 reingereicht (Deskriptoren sind immer relativ zum Prozess, daher findet hier im Kernel eine Übersetzung statt). Das ist mal echt coole Scheiße, und ich bin einigermaßen schockiert, dass Firefox so Bleeding-Edge-Kram überhaupt implementiert hat. Sehr cool!
Warum ich das hier alles erwähne: weil das bei mir auf die Nase fiel, denn zum Abspielen von H.264 lädt Firefox libavcodec von ffmpeg, und ffmpeg ist gegen einen Haufen Codecs und Libraries gelinkt, und die liegen bei mir eben nicht alle in /usr/lib64, sondern beispielsweise liegt libva in /usr/X11R7/lib64 (libva macht hardware-assistierte Dekodierung und Anzeige von u.a. H.264-Videos). Und es stellt sich raus, dass Firefox in dem Broker eine Liste von erlaubten Verzeichnissen hat, aus denen Dateien geöffnet werden können, und die wird nicht aus /etc/ld.so.conf oder so generiert, sondern die ist hardkodiert im Quellcode. Falls jemand mal selbst gucken will: Das ist in security/sandbox/linux/broker/SandboxBrokerPolicyFactory.cpp (nach policy->AddDir gucken).
Nachdem ich da meine Pfade eingetragen habe, kann der Firefox ffmpeg laden — aber das Video immer noch nicht spielen. Das sei jetzt korrupt, sagt er. Ist es natürlich nicht. Mist. Na mal schauen. Fortschritt ist immer nur ein Schritt zur Zeit.
Update: Ein Einsender zur glibc-Situation:
Das Update habe ich für unsere cross-gebauten Umgebungen diese Woche auch gemacht. Mal so ein paar Sachen, die aufgefallen sind:
- gcc 5.4 baut dann nicht mehr (ucontext_t, auch ein paar Stack-Sachen), betrifft auch neuere Versionen von gcc
- iproute2 4.11 baut auch nicht mehr (4.12 schon, also mir egal). IIRC haben sie irgendwo vergessen stdint.h für UINT16_MAX einzubinden, und das muss vorher zufällig über irgendeinen anderen Header mit reingekommen sein (also ganz klar nicht die Schuld von glibc)
- gdb 8.0 baut nicht mehr auf x64 (ARM geht), irgendwas mit putc(), das nur ein Argument bekommt oder so.
Ganz großes Kino.
In der Tat. o_O
Bonus: Einziger Betroffener ist systemd, der Bug wurde von Lennart Pöttering aufgemacht.
When I previously tried to
report bugs in exiv2 found via fuzzing the upstream author made it
clear to me that he has little interest in fixing those issues and
doesn't consider his software suitable to parse defect files (which
basically means it's unsuitable for untrusted input).Weil Das Bugtracking-System so schnarchlahm ist, hier ein paar Money Quotes:Returning to Hanno's request that we say that Exiv2 is "not suitable for untrusted input". I will not do that. The default (for all open source software) is that the user must determine suitability for his/her purposes. We do not claim that Exiv2 is safe for all files. I doubt if we could ever make such a claim even if we pepper our code with checks for malicious images. I don't believe in 2016 that it is possible to guarantee the safety and reliability of any software.UndI know nothing about hacking and exploiting buffer overflows. Perhaps we need more caution about them. This is a mind-boggling issue. The code to defend our image read/write code could be larger than the current library.Wie schlimm ist es? So schlimm:Are you aware of the term "fuzzing"? I believe this is the art of creating illegal files to put software under stress. I am aware that libexiv2 can be exploited in this way, however I have never had time to work on this topic.
Given the wide prevalence of the unrar source code in third-party software, quite a few
downstream parties will be affected. The source code with the fixes can be found
under http://www.rarlab.com/rar/unrarsrc-5.5.5.tar.gz - downstream parties are
encouraged to quickly update and ship fixes.Oh gut, das betrifft bestimmt so gut wie niemanden!1!! Ja gut, ausgenommen 7-zip und so, und natürlich die ganzen Antiviren. Dort war der Bug übrigens zum ersten Mal aufgefallen.It appears that the VMSF_DELTA memory corruption that was reported to Sophos AV in 2012 (and fixed there) was actually inherited from upstream unrar. For unknown reasons the information did not reach upstream rar or was otherwise lost, and the bug seems to have persisted there to this day.
Ja warum würde man auch upstream Bescheid sagen! Da hat man ja einen wettbewerblichen Nachteil von als Schlangenöl, wenn die anderen Schlangenöler informiert werden, und wenn die Software insgesamt sicherer wird!1!!
Dass das ein Problem ist, war schon immer klar. Der Heap wächst nach oben, der Stack nach unten, was wenn die sich treffen?
Das Problem ist so alt, dass früher die "Lösung" einfach war, zu sagen, naja, dann ist Speicher alle, und wenn Speicher alle ist, dann crashen die Programme ja auch ohne Kollision!1!!
Die besseren Programme haben dann irgendwann angefangen, Speicherknappheit zu erkennen und nicht zu crashen, und so gab es auch irgendwann eine halbherzige "Lösung" für das Kollisionsproblem — eine "Guard Page". Speicherschutz funktioniert über eine Hardware-Komponente namens MMU, Memory Management Unit, und die arbeitet nicht auf Bytes sondern auf Pages. Pages sind im Allgemeinen 4KiB groß. Wenn man auf eine Page zugreift, die nicht da ist, dann wirft der Prozessor eine Exception, die das Betriebssystem abfangen kann. So wird beispielsweise Swapping implementiert. Aber wenn der Zugriff auf eine Page war, die nicht da sein sollte, dann kriegt das laufende Programm einen Segmentation Violation signalisiert (theoretisch auch abfangbar, aber üblicherweise nicht abgefangen und prinzipiell auch keine so gute Idee) und crasht.
Die Idee der Guard Page ist, dass man zwischen dem Ende des Heaps und dem Anfang des Stacks eine Page leer und ungemappt lässt. Das klingt erstmal gut, ist es aber nicht.
Denn auf dem Stack kann man auch lokale Variablen deklarieren, die größer als eine Page sind, und so die Guard Page überspringen.
Nichts hiervon ist irgendwie überraschend oder eine neue Erkenntnis. Und die Lösung ist auch offensichtlich. Wenn der Compiler auf dem Stack etwas größer als eine Page alloziert, dann emittiert er eben auch Code, der alle Pages auf dem Weg einmal kurz anfasst.
Visual Studio tut das seit über 10 Jahren, wahrscheinlich schon viel länger. Seit ich mir das erste Mal deren Disassemblat angeguckt habe, tut es das.
gcc tut es aber nicht.
Ich erinnere mich noch, mich 2005/2006 mit meinem Kumpel Ilja über genau dieses Problem unterhalten zu haben, und ich bin mir fast sicher, dass er den gcc-Leuten gesagt hat, sie sollen da mal solchen Code emittieren. Aber er findet gerade kein verlinkbares Material. Dafür, dass gcc da seit 20 Jahren auf einem bekannten Problem sitzt, lege ich aber meine Hand ins Feuer. das war komplett vermeidbar, und die, die es hätten vermeiden müssen, haben es nicht getan. Ohne eine Ausrede dafür zu haben. Hier ist z.B. ein Beitrag von 2013, der das Problem beschreibt. Krasserweise gibt es sogar grundsätzlich Support für Stack Probing in gcc, der ist nur bei C und C++ nicht angeschaltet. Hier ist ein Bug von 2007 dazu. Ich bin mir aber sicher, dass das Problem schon länger bekannt ist.
New hotness: Starbug hackt den Iris-Sensor vom Samsung Galaxy S8.
Erstens: Gerade im Bahnumfeld gibt es harte Zertifizierungs-Zwänge, und eine Zertifizierung zertifiziert halt immer einen genauen Versionsstrang und da kann man dann halt nichts machen. Oh, und: Zertifizierung ist teuer und dauert Monate.
Tja, dann müssen wir da eben ansetzen. Dinge, die häufiger gepatcht werden müssen, als man nachzertifizieren kann, können dann halt kein Zertifikat kriegen. Wir müssen endlich Security als Teil von Safety betrachten.
Und zweitens: Das Patch Management der Hersteller ist auch Scheiße. Leute schrieben, dass Windows Update gerne mal hängt, das man tage nach dem Patchday noch nichts angeboten gekriegt hat, usw. Das stimmt alles und ist eine Riesensauerei. Insbesondere da man heute davon ausgehen muss, dass es unter 24h dauert nach der Verfügbarkeit von einem Patch, bis der Exploit dazu reverse engineered wurde. Wenn also das Patch-Verteilen länger als 24h dauert, ist es zu langsam. Das ist eine harte Grenze. Ich würde sogar "die Welt muss die Patches innerhalb von 12h haben" sagen. Da muss Microsoft halt in bessere CDN-Infrastruktur investieren, wenn sie die Load nicht hinkriegen.
Drittens: Neuronale Netze sind ja gar nicht so undebugbar. Ich zitiere:
die Aussage, dass wir nicht verstehen wie Neuronale Netze, Reinforcement Learning etc. ihre "Magie" wirken stimmt nicht so absolut. Das Feld ist zwar gerade noch im kommen, aber Paper wie dieses hier (was versucht CNNs auf Wavelet Filterbanken zurückzuführen), dieses (was ein RNN analysiert und dort ein "Sentiment Neuron" findet) und die bereits von dir verlinkten adversarial input paper zeigen, dass wir es eben doch verstehen können. Das verstehen und erklären warum die Modelle funktionieren ist ein aktives Forschungsfeld, und die zugrunde liegende Mathematik wird immer verstanden.Richtiger wäre es also zu sagen, dass die ganzen Machine Learning Ansätze instant-technical debt oder instant bloat sind. Wenn in einer Firma oder einem Software System nicht auf einen guten Prozess geachtet wird, ist es sehr schnell unmöglich (oder zumindest sehr teuer) den Code und alle Interaktionen zu verstehen. Vor allem bei den ganzen Compile-to-X Sprachen, dynamisch getypten Sprachen (NodeJS :-/) und Distributed Systems ist man von der Komplexität her schnell bei dem eines DNN. Der Unterschied ist, dass zumindest am Anfang jemand das ganze designed hat damit es läuft, und das organische im Nachhinein kommt wenn sich die Aufgabe verändert. Bei NNs ist das erschaffen organisch, das verändern mit der Aufgabe ist eingebaut und es ist nicht *zwingend* notwendig es zu verstehen, weil man ja eh nur mit statistischen Garantien arbeitet. Daher wird auf die Analyse WARUM und WIE dein System funktioniert meist verzichtet.
Das Problem mit ML ist also dasselbe wie mit Software Pfuscherei im allgemeinen: Qualitätssicherung macht kein Geld, man kann sich noch besser mit "Act of God" artigen Ausflüchten vor Verantwortung drücken und daher gibt es keinen Anreiz dafür sicherzustellen, dass man weiß was da passiert.
Viel gefährlicher finde ich aber (abgesehen von der Tatsache dass AI das Missverhältnis zwischen Kapital und Labor noch mehr zum Kapital kippt), dass wir noch kein Äquivalent zur GPL für ML haben. Bei normaler Software kann dank RMS und Linus wenigstens 99% der Zeit den Code überprüfen, selber fixen und mich zum Teil auf eine Community verlassen. Bei ML Modellen ist die Software vielleicht noch MIT, die Architektur VIELLEICHT noch dokumentiert, aber weder die Hyperparameter, die genauen Tainingsdaten noch die "ah Sepp, mach da doch noch diese L2 norm drauf" gegeben. Reproduzierbarkeit, Überprüfbarkeit, Identifizierbarkeit? Nope. Es kommt jetzt zwar wenigstens langsam pretraining in den Mainstream (was die Modelle modifizierbar macht) und Google hat vor kurzem einen underrated Paukenschlag mit ihrem Privacy respecting Distibuted Training rausgebracht, der es vlt. möglich macht dezentralisierte Datensätze unter einer AGPL style Lizenz zu organisieren, aber ich sehe da noch einen harten Kampf auf uns zukommen. Tivoization wird nix dagegen.
Traditionelle Software wird entwickelt, konstruiert. Das ist am Ende eine Konstruktion. Wenn etwas fehlschlägt, kann man gucken, welcher Teil der Konstruktion das Problem war, und das reparieren. Man kann das debuggen.
Das ist bei Machine Learning nicht mehr so. Neuronale Netze sind nicht konstruiert, sondern werden trainiert. Wenn da was falsch läuft, dann kann man das nicht debuggen. Man kann nur nach-trainieren. Und läuft dabei Gefahr, bisher erlerntes wieder zu ent-lernen.
Nun kann man bei den ganzen Problemen, die wir mit Software haben, zu dem Schluss kommen, dass wir das alles so wenig im Griff haben, dass Debugbarkeit vielleicht eh nicht so wichtig ist. Ist eh alles ständig kaputt, und so. Dem würde ich gerne laut widersprechen. Das ist unser einziger Notnagel, der uns vom dem Abgrund fernhält.
Und es gibt noch einen weiteren Aspekt. Wenn wir ein neuronales Netz trainieren, und es ist besonders gut beim Erkennen von irgendwas, dann können wir davon nicht lernen, auch besser zu werden. Konstruierte Dinge kann man reverse engineeren. Neuronale Netze nicht. Die kann man nur anwenden und trainieren. Das ist alles.
Ich linke so gut wie nie auf den Technology Review, aber heute mache ich mal eine Ausnahme. Wir bewegen uns mit hoher Geschwindigkeit auf eine Zukunft zu, in der wir von Maschinen umgeben sind, denen wir nicht vertrauen können, und die wir nicht verstehen können. Der Zeitpunkt zum Kurswechsel ist jetzt.
Update: Hups, Tweet ist wieder weg. Mehr als den Tweet hatte ich auch nicht dazu.
Update: Lutz Donnerhacke dazu:
Der Killswitch ist kein Killswitch, sondern eine primitive Anti-Debug Maßnahme. In der Sandbox werden üblicherweise alle extenen Kommunikationen umgelenkt. Er testet also nur auf das Vorhandensein einer Analyse-Sandbox.
Zum Tweet ... Dort wurden verschiedene Teile der Malware miteinander verglichen, nicht verschiedene Versionen. Als er das nach einigen Minuten bemerkt hatte, hat er den Tweet gelöscht.
Empfehle doch allen Lesern, Resolverlogs und Firewalllogs nach der Domain oder deren Auflösung zu durchsuchen. Das zeigt auch inaktive Installationen.
Die Empfehlung reiche ich gerne weiter.
Konkret ist da so ein System-Tray-Dingens bei, das auch auf bestimmte Sondertasten mancher Tastaturen reagieren soll, wie die Lautstärke-Regel-Tasten. Das haben die implementiert über einen Hook, und der kriegt dann natürlich alle Tastendrücke rein. Allerdings haben sie aus dem Treiber anscheinend die Debugging-Funktionalität nicht entfernt, und so fallen die Scancodes in einem Logfile im Dateisystem raus, auf das alle User Lesezugriff haben. JA SUPER!
Das sieht jetzt nicht wie böse gemeint aus, aber das finde ich an der Stelle kein relevantes Kriterium. Solcher Code wird von keiner Qualitätssicherung erkannt, und HP merkt jahrelang auch nichts sondern reicht das schlicht durch. Als ob die nicht zuständig wären, nur weil der Treiber von einem Drittanbieter kommt!
Oh und natürlich hat das auch kein Antivirus erkannt. Auch nicht die proaktiven verhaltensbasierten Module, mit denen sich die Hersteller gerade rauszureden versuchen, dass ihre Signaturen wertlos sind. Das ist jetzt keine klassische Malware, aber es ist ein schönes Beispiel, bei dem sich mal jeder Gedanken machen kann, was man von so einer verhaltensbasierten Malware-Erkennung eigentlich für eine Erwartungshaltung hat bzw. realistisch haben kann.
Update: Heise darüber
Meine Vermutung war ja, dass es SChannel ist. Das ist die TLS-Implementation von Microsoft, die sich im Vergleich zu allen anderen TLS-Implementationen auf dem Planeten verdammt gut geschlagen hat bisher. Zu gut, fand ich, und dachte mir, die sind jetzt dann wohl doch mal fällig gewesen.
Aber das war es nicht. Nein. Viel besser. Es war der Microsoft-Antivirus. Stellt sich nämlich raus: Der hat eine Scripting-Sprache, und die hat die selben Bugs, die auch andere Skripting-Sprachen von Microsoft plagen: Type Confusion.
Die Skripting-Sprache ist für Netzwerk-Überwachung. Das ist eigentlich eine gute Idee. Microsoft hat auch sowas ähnliches wie Wireshark im Angebot, und da ist auch fast die gesamte Decoding-Logik mit einer kleinen Mini-Beschreibungssprache erschlagen worden. Ergo hat das Ding so gut wie keine Security-Bugs, während Wireshark der Moloch zwischen Sodom und Gomorrah ist.
Aber ich weiche vom Thema ab. Microsoft hat einen Bug im Antivirus. Genau was ich seit Tagen auf der Heise Show als Szenario an die Wand gemalt habe. Und weil es eben Microsoft und kein gammeliger Schlangenöl-Hersteller ist, gibt es da jetzt keine Nebelbank sondern das wird als das bezeichnet, was ist es: Critical, Remote Code Execution, Wormable.
So und jetzt kann sich ja jeder nochmal selber überlegen, wie wahrscheinlich das ist, dass Microsoft mit ihren Milliarden an Ressourcen, mit ihren fünfstellig vielen Security-Experten, mit ihren monatelangen Testzykeln, dass DIE das nicht hinkriegen, aber die anderen kriegen es hin. Ja nee, klar.
Hier ist so ein Post Mortem, von einer Hipster-Bullshitbingo-Startup-Klitsche.
Nun wird vielleicht euer erster Instinkt sein, dass die halt Bullshitbingo-Tech verwenden, so Rethinkdb und Nodejs und so, das betrifft euch vielleicht gar nicht. Lest es trotzdem, und zwar ganz.
Update: Aus der libstdc++-Doku:
Notes about deallocation. This allocator does not explicitly release memory. Because of this, memory debugging programs like valgrind or purify may notice leaks: sorry about this inconvenience. Operating systems will reclaim allocated memory at program termination anyway.
Einer für die Geschichtsbücher. "This is why we can't have nice things", wie man so schön sagt.
G-Data stimmt mir grundsätzlich zu, dass Zahlen zur Wirksamkeit von Antiviren schwierig zu beschaffen sind, weil die im Allgemeinen von den Herstellern kommen und daher nicht als neutral gelten können. Die Zahlen, die eine große Bibliothek an Malware gegen Antiviren werfen, finden häufig hunderte von Viren, die nicht gefunden wurden, und die Antivirenhersteller reden sich dann mit angeblicher Praxisferne der Tests heraus. Ich las neulich von einer Studie, bei der eine Uni alle ihre einkommenden die Malware-Mail-Attachments bei Virustotal hochgeladen hat und auf unter 25% Erkennungsrate kam. Leider finde ich die URL nicht mehr. Vielleicht kann da ja ein Leser helfen. Mein Punkt ist aber unabhängig davon, ob das jetzt 5%, 25% oder 90% Erkennungsrate sind. Es reicht, wenn ein Virus durchkommt. Eine Malware ist nicht wie die Windpocken. Wenn man sie kriegt hat man halt rote Pünktchen im Gesicht und nach ner Woche ist wieder alles OK. Nein. Eine Infektion reicht, um die gesamten Daten zu klauen, die Platte zu verschlüsseln, und an einem DDoS-Botnet teilzunehmen. Die Erkennungsrate ist, solange sie nicht 100% ist, irrelevant. Ich bin immer wieder schockiert, mit welcher Selbstverständlichkeit Leute nach einer Malware-Infektion halt "desinfizieren" klicken in irgendeinem Tool und dann weitermachen, als sei nichts gewesen. Das ist wie wenn jemand in eine Schwimmbecken scheißt, und man fischt den größten Klumpen raus, und dann schwimmen alle weiter. WTF!?
Der nächste Talking Point der AV-Industrie ist (angesichts der miserablen Erkennungsraten in der Praxis), dass man ja nicht mehr rein reaktiv arbeite sondern auch magischen Einhorn-Glitter aus der Cloud habe. Erinnert ihr euch noch an den Aufschrei nach Windows 10, als Microsoft sich das erstmals explizit von euch absegnen ließ, dass sie eure Daten in die Cloud hochladen? Wie jetzt?! Die wollen gerne als Debugginggründen sehen, welche crashenden Programme ich ausführe!? DAS GEHT JA MAL GAR NICHT!!1! Ja was denkt ihr denn, was das ist, was die AV-Industrie mit der Cloud macht? Die werden im Allgemeinen nur die Hashes der Software hochladen, aber das heißt trotzdem, dass die sehen können, wer alles Winzip benutzt, oder dieses eine hochpeinliche aus Japan importierte Hentai-"Dating-Simulator"-Anwendung. Aber DENEN traut ihr?!
Ich sage euch jetzt mal aus meiner Erfahrung, dass die Analyse von einem Stück Software Wochen dauert, besonders wenn die Software gerne nicht analysiert werden möchte. Wenn die AV-Industrie also so tut, als könnte ihre magische Cloud "innerhalb von Sekunden" helfen, dann gibt es nur zwei Möglichkeiten: Entweder sie haben ein paar Wochen gebraucht und tun jetzt nur so, als sei die paar Wochen lang schon niemand infiziert worden. Oder sie haben da irgendwelche Abkürzungen genommen. Überlegt euch mal selbst, wieviel Verzögerung eurer Meinung nach akzeptabel wäre. Dann, wieviel Arbeit das wohl ist, anhand einer Binärdatei Aussagen zu machen. Zumal man solche Aussagen im Allgemeinen in einer VM macht, und Malware im Allgemeinen guckt, ob sie in einer VM läuft und dann die bösen Funktionen weglässt. Eine denkbare Abkürzung wäre also, schon so einen Check als Zeichen für Malware zu deuten. Da sind wir aber nicht mehr in der Branche der seriösen Bedrohungsabwehr, sondern in der Branche der Bachblüten-Auraleser-Homöopathen, das ist hoffentlich jedem klar.
Das ganze Gefasel mit proaktiven Komponenten halte ich auch für eine Nebelkerze. Wenn das funktionieren würde, gäbe es Weihnachten keine wegzuräumende Malware auf dem Familien-PC, und in der Presse wäre nie von Ransomware die Rede gewesen, weil das schlicht niemanden betroffen hätte.
Ja und wie ist es mit dem Exploit-Schutz? Das ist Bullshit. Das erkennt man schon daran, dass Microsoft diese angeblichen Wunderverfahren der AV-Industrie nicht standardmäßig ins System einbaut. Googelt das mal. Microsoft hat hunderttausende von Dollars für gute Exploit-Verhinder-Ideen ausgeschrieben und ausgezahlt. Und wieviele Prämien für gute Ideen findet ihr von der AV-Branche? Na seht ihr.
Überhaupt. Kommen wir mal zu den Standards. Microsoft hat den Prozess etabliert, den gerade alle großen Player kopieren, die SDL. Ich weiß das, weil ich dabei war, als sie das bei sich ausgerollt haben. Microsoft hat, was ich so gehört habe, sechsstellig viele CPU-Kerne, die 24/7 Fuzzing gegen ihre Software-Komponenten fahren, um Lücken zu finden. Microsoft hat ganze Gebäude voller Security-Leute. Ich würde schätzen, dass Microsoft mehr Security-Leute hat, als die typische AV-Bude Mitarbeiter. Microsoft hat geforscht, ob man mit dem Umstieg auf .NET Speicherfehler loswerden kann, ob man vielleicht einen ganzen Kernel in .NET schreiben kann. Sie hatten zu Hochzeiten über 1/4 der Belegschaft Tester. Es gibt periodische Code Audits von internen und externen Experten. Sie betreiben eine eigene Security-Konferenz, um ihre Leute zu schulen, die Bluehat. Aus meiner Sicht stellt sich also die Frage: Wenn DAS die Baseline ist, trotz derer wir immer noch ein Sicherheitsproblem haben, dann müssten ja die AV-Hersteller nicht nur genau so gut sondern deutlich besser sein. Sonst wären sie ja Teil des Problems und nicht Teil der Lösung. Das hätte ich gerne mal von den AV-Leuten dargelegt, wieso sie glauben, sie könnten das besser als Microsoft.
Oh und einen noch, am Rande:
Wenn Daten signiert sind ist klar, von wem die Informationen stammen. Oft ist es schon ein beträchtlicher Sicherheitsgewinn, wenn man weiß, dass die Information von einem bekannten und ergo vertrauenswürdigen Quelle stammen.Das ist natürlich Bullshit. Es sind schon diverse Malware-Teile mit validen Signaturen gefunden worden, und alle alten Versionen mit bekannten Sicherheitslücken sind ja auch noch gültig signiert. Code Signing dient nicht dem Schutz des Kunden sondern dem Schutz von Geschäftsmodellen.
Mir ist außerdem wichtig, dass ihr merkt, wenn ihr hier mit einer bestimmten Haltung an das Thema rangeht, weil ihr selbst schon entschieden habt, und jetzt nur noch die Argumente rauspickt und höher bewertet, die eure getätigte Entscheidung bestätigen. Das ist ein sehr menschliches und normales Verhalten, aber dem Erkenntnisgewinn dient das nicht. Wo kommen denn die Zahlen her, dass angeblich noch niemand über Lücken in Antiviren gehackt wurde? Wenn ihr zu Weihnachten 10 Viren findet — macht ihr dann erstmal eine wochenlange forensische Analyse, wo die herkamen? Nein, macht ihr nicht! Ihr seid froh, wenn die weg sind. Aussagen wie "noch keiner ist über seinen Antivirus gehackt worden" sind unseriös, und Aussagen wie "es sind keine Fälle bekannt" sind irreführend und Nebelkerzen.
Update: Wer übrigens die Früchte von Microsofts Exploits-Schwieriger-Machen haben will, der muss a) immer schön Windows updaten; weg mit Windows 7 und her mit Windows 10, und/oder b) EMET installieren.
Update: Hups, EMET-Link war kaputt.
Update: Ein Einsender weist darauf hin, dass es doch mal einen Fall von einer massenhaftung Malware-Verbreitung via Antivirus-Sicherheitslücke gab.
Update: Ein fieser Wadenbeißer hat sich mal durch die Archive gegraben:
es gibt noch weiteres Argument gegen die Schlangenöl-Branche, das ich glaube ich bei dir noch nicht gelesen habe, wenngleich das eher nicht gegen die Microsoft-Lösung zielt:
Kollateral-Schaden.
Wie oft hatten wir es bitte schon, dass ein Amok laufender Scanner von einem marodierenden Wozu-Testen-AV-Riesen schlicht Windows & co als Virus/Trojaner/Whatever eingestuft hat?
Gucken wir doch mal:
Das passt auch sehr schön dazu, welchen Testaufwand Microsoft im Vergleich betreibt.
Oh und was ist eigentlich mit Virenscannern, die Inhalte aus dem Netz nachladen, die nicht unbedingt... naja, gab es schließlich auch schon:
Soll man daraus schließen, dass die ihr eigenes Gift vmtl selbst gar nicht einsetzen?
Ach ja, ich vergaß, alles bedauerliche Einzelfälle vom Werksstudentenpraktikanten, die natürlich nie, nie, nie wieder passieren. Ungeachtet dessen, dass sie nie hätten passieren dürfen, das wäre eigentlich der Anspruch an diese Software.
So wie auch schon Schlangenöl auch nur in den besten Fällen keine Wirkung hatte.
Ich habe bisher auf diese Art von Linksammlung verzichtet, weil es mir gerade nicht darum geht, mit dem Finger auf einzelne Hersteller zu zeigen. Es gibt da sicher auch Pfusch bei einzelnen Anbietern, das sehe ich auch so, aber mir ist die fundamentale Kritik am Konzept des Antivirus wichtiger. Pfusch in Software gibt es ja leider häufiger.
Update: Ein anderer Einsender kommentiert:
Zum Thema Proaktive Komponente kann ich dir aus unserer Infrastruktur klar sagen: DAS ist das was am Meisten Fehlmeldungen produziert. Ich habe z.B. einen lang vergessenen Texteditor auf einer Netzwerkfreigabe rumliegen. Seit 2007. Und 2016 auf einmal meldet der Antivirus, dass das Ding verseucht ist und sofort desinfiziert werden muss. Ich warte zwei Tage (=zwei Signaturupdates) ab und lass den Ordner wieder scannen. Diesmal: Nix. Oder letzte Woche hat er uns 6 Userworkstations als virenverseucht gemeldet, weil die User Proxy PAC-Scripte im Browser konfiguriert haben. Ja, haben sie weil so unser Internetzugang funkioniert, aber ich frag mich ernsthaft warum der AV nur diese 6 Workstations gemeldet hat und nicht noch die anderen 400 die das AUCH haben. Tags drauf war wieder alles gut. Für mich als Admin ist das keine zusätzliche Sicherheitskomponente sondern nur zusätzliche Arbeit.
Und ich möchte auch zu der Cloud-AV-Sache noch mal klarstellen, wie sehr das Bullshit ist. Der CCC hat vor ein paar Jahren den Staatstrojaner veröffentlicht, ihr erinnert euch wahrscheinlich. Natürlich in einer entschärften Version, die keinen Schaden angerichtet hätte. Diese Version tauchte dann relativ zeitnah in den Cloud-Antivirus-Datenbanken auf. Die nicht entschärfte Version tauchte nicht auf. Nur falls sich da jemand Illusionen gemacht hat.
Update: Ein Biologe kommentiert:
Es gibt ja ein paar hübsche Analogien zwischen Computerviren und deren Verbreitung und der realen Welt. Beim Lesen des G-Data Pamphletes musste ich an einer Stelle herzlich lachen, als sie ihre "über 90% Erkennungsrate" beweihräucherten. Auf die Mikrobiologie übertragen ist das eine log1-Reduktion, also so knapp über Homöopathie und Gesundbeten. Ich arbeite mit Lebensmitteln, da darf man etwas "Debakterisierung" nennen, wenn man im log3-Bereich unterwegs ist. Also wenn 99.9% aller Keime gekillt werden. Pasteurisierung ist bei log5, also 99.999%. Und auch da wird die Milch nach 21 Tagen sauer.
90% ist da auf jeden Fall der Bereich "lohnt den Aufwand nicht". Da ist eine sinvolle Backup-Strategie und eine gewisse Routine im Rechner-wiederaufsetzen sinnvoller eingesetzt.
Update: Viele meiner Leser scheinen eine Statistik-Schwäche zu haben, und kommen mir hier mit Analogien wie "Kondome schützen ja auch nicht 100%" oder "im Flugzeugbau hat man auch nicht 100% als Anforderung". Vergegenwärtigt euch mal, wie viele Viren es gibt, und wie viele Malware-Angriffe pro Tag es auf typische Systeme gibt. Und dann rechnet euch mal aus, bei einer Erkennungsrate von 90%, oder sagen wir 99%, oder sogar 99.9%, wie viele Stunden es dauert, bis der Rechner infiziert ist. Ich habe in Köln und Hamburg das Publikum gefragt, wer schonmal Weihnachten einen Familien-PC säubern musste. Fast alle. Dann, bei wie vielen ein Antivirus drauf war. Jeweils einer weniger. EINER weniger. ALLE ANDEREN haben trotz Antiviren Malware eingefahren. Wir reden hier nicht von "ich habe dreimal pro Tag mit Kondom Sex und habe nie HIV gekriegt", sondern von über einer HIV-Infektion pro Tag. Und da, behaupte ich mal, wären auch die Nicht-Statistiker unter euch plötzlich mit der Kondom-Performance unzufrieden. Was ihr gerade am eigenen Leibe erlebt, das nennt man Rationalisierung. Ihr habt eine Entscheidung getroffen, nämlich einen Antivirus einzusetzen, und greift jetzt unterbewusst nach Strohhalmen, um das irgendwie zu rechtfertigen. Ich meine das gar nicht böse. So funktionieren Menschen. Euch kommt zugute, dass die meisten Viren bisher wenig kaputtgemacht haben. Vielleicht ein paar erotische Selfies exfiltriert, wenn es hochkommt an einem Botnet teilgenommen. Erst jetzt mit Ransomware werden Viren auch gefühlt richtig gefährlich. Ihr solltet nicht warten, bis euch das am eigenen Leib passiert.
Achtung: Das ist ziemlich heftiger Tobak.
Hut ab vor den Auditoren, die da an der Tastatur saßen, die waren echt fit.
Auch die "Can't reproduce"-Kommentare sind sehr schön. (Danke, Marian)
Ich habe mich ja mit der Idee von Microservices angefreundet, muss ich euch sagen. Wenn man das richtig anwendet, kann man damit Risiken schön isolieren und seine Anwendung in problematische und weniger problematische Teile aufspalten, und dann packt man die problematischen in eine kleine Ecke und achtet besonders darauf, da alles ordentlich zu machen. Ich sehe auch operationelle Vorteile, weil man das viel besser mit Standard-Mitteln debuggen kann.
Ich würde das dann freilich nicht in Java machen. :-)
Und das krasse ist: Nichts davon ist überraschend. Außer vielleicht dem Heap Overflow, heutzutage nutzt man eigentlich eher Type Confusion-Bugs in Browsern aus. Aber dass es Bugs allen diesen Stellen geben würde, das war nicht überraschend. Denn die Qualität unserer Software stinkt ganz barbarisch, und alle wissen es.
Nexus 9 ist ein Android-Tablet, und der Kopfhörerausgang von dem Ding hat an der Buchse einige Kontakte mehrfach belegt — über die man sogar I2C mit dem Gerät sprechen kann!
Wie geil ist DAS denn! Malicious Headphones! MWAHAHAHAHA
Hintergrund ist, dass ich ein Billo-Laptop mit Win10 als ersten Rechner für die Kinder gekauft habe, dort aber Linux drauf installieren wollte. Dank nicht ausreichender Recherche habe ich nun ein betroffenes Gerät. Es ist faszinierend zu lesen, wie die Intel-Entwickler seit über einem Jahr an diesem Bug herumsuchen, ohne dass die eigentliche Ursache gefunden wurde.
Update: Ein Einsender kommentiert:
den Bay Trail Bug, über den du geschrieben hast, den hat Intel meines Wissens nach schon vor einer Weile gefunden. Im Angehängten Dokument steht er unter VLP52. Kurz zusammengefasst: Wenn die CPU während einer Interrupt Service Routine in den C6-state wechselt, wird das EOI verschluckt, d.h. die Interrupts werden nicht wieder angeschaltet. Damit ist dann natürlich auch der Timer Interrupt weg und die Kiste hängt. Wohlgemerkt: Das betrifft nur C6, C7 ist ok. Der bessere "Fix" ist also, per sysfs alle C6-states zu deaktivieren, dann sind die Hänger weg, ohne dass der Energieverbrauch allzu kriminell wird.
Intel sagt in dem Dokument übrigens auch an, dass das nicht gefixt wird, weil das Problem in der Hardware liegt.
(Danke, Hanno)
Der re-keying code in vielen libraries, allermindestens openssl, nss, gnutls, ist total kaputt. Wir haben das über Jahre in postgres (nur openssl zu dem Zeitpunkt) verwendet, und haben unmengen von Bugs gefunden. Und weitgehend sind die immer noch vorhanden.Und zu meinem Bauchgefühl, dass dann ja auch der initiale Handshake im Arsch sein müsste, schreibt er:Das reicht von "passiert nichts mehr über der Verbindung" weil der interne Status keinen Sinn mehr macht bis zu crashes. In postgres war das wohl besonders schlimm weil wir a) non-blocking IO verwendet haben und openssl da noch weniger getestet ist b) teilweise sehr viele Daten transferiert werden (replication läuft auch über so eine Verbindung und eine Verbindung kann terrabytes überleben).
Zumindest in openssl würde ich sagen dass das nicht ganz so ist - während die renegotiation in progress ist muss openssl auch noch damit zurechtkommen dass Daten mit dem alten Schlüssel ankommen. Ich finde es schwer dem openssl code wirklich zu folgen, aber soweit ich es verstanden habe sind schlichtweg nicht alle korrekt implementiert.Oha. Mein Verständnis war, dass man renegotiation benutzt, um in TLS auszuschließen, dass die Cipher-Suites in der initialen (unverschlüsselten) Handshake-Negotiation von einem aktiven Angreifer ausgedünnt worden sind. D.h. wenn man Renegotiation wegschmeißt, man messbar Sicherheit einbüßt. Aber vielleicht habe ich das falsch verstanden.Man bemerke auch dass tls 1.3 key renegotiation komplett rausschmeisst.
Ich wäre *sehr* verwundert wenn der "live" renegotiation code in openssl nicht ein paar exploitable bugs hätte.
Update: Ein anderer Einsender erklärt:
bitte nicht Re-Negotiation mit Re-Keying verwechseln.
Re-Keying ist auch in TLS 1.3 noch drin.
Und das ist auch gut so, den im Gegensatz zur Re-Negotiation ist Re-Keying bei vielen (den meisten?) Krypto-Algorithmen einfach notwendig, da mit einem Key nur eine begrenzte Menge an Daten verschlüsselt werden darf, bevor das Verfahren unsicher wird. (z.B. weil dann die Wahrscheinlichkeit, dass zufällig gewählte Nonces per Birthday-Paradoxon mehrfach verwendet werden, zu hoch wird.)
If an attacker can execute arbitrary code in the guest kernel and a virtfs is set up, the attacker can access the entire filesystem of the host using a symlink attack.
Google hat da mal was veröffentlicht …
Hier sind die Details. "Cloudbleed" :-)
Begründung: Firefox setzt jetzt zwingend auf pulseaudio auf.
Ist bestimmt mein pulseaudio 8 braun, installiere ich mal pulseaudio 10. Der Daemon kommt ohne Fehlermeldung nicht hoch. Stellt sich raus, dass es da ein Consolekit-Modul gibt, das der reinlädt, und der failed anscheinend unklar, und damit kommt das ganze Ding dann nicht hoch. Modul gelöscht, Daemon kommt hoch. Findet kein Audio.
Nee, warum auch. Chrome findet Audio, Alsa findet Audio, Mplayer findet Audio, ffplay findet Audio, mpg123 findet Audio. Skype findet Audio. SKYPE! Das stinkende Flash-Plugin findet Audio! Gute Arbeit, Herr Pöttering. Flash findet Audio, dein Code nicht. Großartig. Das muss man erst mal hinkriegen, schlechter als Flash zu sein.
Nach ein bisschen Debugging stellt sich raus, dass es keine Fehlermeldungen gibt. pulseaudio findet ein Null Sink. That's it.
Gibt es eigentlich irgendwas, was der angefasst hat, das nicht als Totalschaden endete? Der Michelangelo der kritischen Infrastruktur! Was er anfasst, wird ein Gesamtkunstwerk! Kann nicht debuggt werden, nur bewundert. Der Midas der Middleware! Was er anfasst, wird zu … nunja.
Dann halt kein Firefox mehr. Die sind von der Security her eh nicht mit Chrome mitgekommen. Und das alleine ist ja schon ein Totalschaden, wenn man mal drüber nachdenkt.
Ich könnte mich ja über die FAQ von pulseaudio stundenlang amüsieren. Auf wie viele Arten das bei den Leuten da draußen nicht geht. Und an keiner Stelle kommt jemand auf die Idee, dass vielleicht Pulseaudio einfach noch nicht bereit ist für eine verantwortungsvolle Rolle.
Ach nee komm, da bauen wir noch eine dynamisch nachladende Modulschnittstelle an. Und eine IPC-Bus-Schnittstelle, die dann failed, wenn der Bus nicht da ist. Und eine Schnittstelle für Consolekit (was übrigens "not actively maintained" ist, KLAR dependen wir auf sowas!!1!). Ich würde ja einen CORBA-Joke machen, wenn Gnome nicht auch schon mal darauf eine Abhängigkeit gehabt hätte. Es ist alles so traurig.
Update: Ein Einsender weist darauf hin, dass jemand einen Pulseaudio-Emulator geschrieben hat. Wie krass.
Update: Das ist ein encfs-Wrapper, nicht Full Disk Crypto. Und wer encfs ohne dieses Cryptokeeper benutzt, ist nicht betroffen.
According to multiple support threads started in the last three weeks and merged into one issue here, users had complained about old folders that they deleted years ago, magically reappearing on their devices.Wie das so ist in der Cloud. Account löschen und Dateien löschen implementiert niemand wirklich. Das liefe ja dem Big Data-Anspruch zuwieder!
Gute Nachrichten: Ihr braucht keine Fernwartungssoftware mehr!
Ich weiß gar nicht, was da toller ist — die verkackte Architektur, oder dass die Spezialexperten von McAfee ein halbes Jahr für einen Patch brauchen.
Der Einsender kommentiert:
Es gibt hier 2 Aspekte, auf die ich näher eingehen möchte (selbst Webentwickler seit ~10 Jahren):1. Pornobranche als Innovationstreiber
Die Pornobranche ist gerade bei neuen Technologien immer weit vorne dabei - wenn es z.B. um WebVR oder 360° Experiences im Web geht, da sind die allen anderen meilenweit voraus. Ich weiß aus erster Hand dass die Abnehmer Nummer 1 für eine WebGL Engine sind, die genau das heute schon ziemlich gut möglich macht (https://delight-vr.com/).
Darüber hinaus hat Pornhub nicht zum ersten Mal gezeigt dass sie experimentierfreudig sind und sich nicht nur auf dem status-quo ausruhen - stattdessen werden kreative Wege gegangen, um den Zugang zu ihren Produkten attraktiv zu gestalten (pornhub statistics, BangFit, etc.)
2. Das Chromium Ticket
Bisher gab es keine Möglichkeit, dass eine Extension requests aus der webRequest API blockt - nun wird darüber diskutiert ob hier ein granulareres Rechte-Modell Sinn macht. Was mich aber wirklich überrascht hat, ist dieser Kommentar.
Hier wird zunächst rein die for-profit Variante erläutert, welche lediglich ihr „Acceptance Program“ durchbringen möchte. Ich frage mich ja, ob es by design nicht möglich war, oder ob es ein eher zufälliger exploit war.
Wie dem auch sei - auf der Hut sein, womöglich gibt es noch andere non-blockable Web-Technologien(WebRTC oder Service Worker?).
This post discusses a design issue at the core of the XNU kernel which powers iOS and MacOS. Apple have shipped two iterations of mitigations followed yesterday by a large refactor in MacOS 10.12.1/iOS 10.1. We’ll look at the bugs, how they can be exploited to escape sandboxes and escalate privileges, and how we can defeat each of the mitigations. Every step is accompanied by a working exploit.
Ich habe in gatling vor mehreren Jahren SSL-Support eingebaut, mit OpenSSL damals. Später habe ich auch Unterstützung für PolarSSL nachgerüstet, und als die sich nach mbedtls umbenannt haben, bin ich mitgegangen. Der Code für den SSL-Support war immer ziemlich krude, weil ich a) damit keine Erfahrung hatte und b) die APIs alle furchtbar und kompliziert sind und üblicherweise die Dokumentation eher untauglich ist. So mache ich, was viele in der Situation machen, und greife mir ein Stück Code, das ich irgendwo funktionieren gesehen habe, und übernehme das. Bei PolarSSL war das recht einfach, die liefern ein relativ minimales Beispielprogramm mit. Bei OpenSSL war das die Krätze. Es gibt da im Wesentlichen ein Beispielprogramm, nämlich den Code für s_client in dem OpenSSL-Binary, und der macht lauter unnötige und unklare Sachen. Die beschreiben das sogar irgendwo als Absicht, weil das eher Code zum Testen ist als Code zum als Vorbild nehmen.
Benutzung von SSL ist nicht so schwierig, man macht einfach statt read() SSL_read() und statt write() SSL_write(), mal ganz plump gesprochen. Hacks wie sendfile gehen dann halt nicht. Im Fall von gatling kommt erschwerend hinzu, dass ich da auf non-blocking sockets operiere, und SSL halt ein Protokoll ist, d.h. die Signalisierung ist komplexer. write() sagt unter Unix EAGAIN, um mir zu sagen, dass ich später nochmal probieren muss. Bei SSL kann es aber sein, dass ich SSL_write später nochmal probieren muss, aber das nötige Event ist nicht "kann auf diesem Socket schreiben" sondern "kann von diesem Socket lesen", beispielsweise wegen einer Renegotiation oder so. Daher haben SSL_write() und SSL_read() zwei Rückgabewerte, einen für "komm wieder, wenn ich schreiben kann" und "komm wieder, wenn ich lesen kann". Aber gut, kein Ding.
Haariger ist die Initialisierung der Sockets, das ist echt fummelig und nervig. Und die Dokumentation, die da ist, kommt in Form einer Referenz, nicht in Form eines Tutorials oder einer Einführung. Bei OpenSSL operiert man nicht auf Deskriptoren, sondern auf einer Abstraktion namens SSL*. Es gibt aber auch ein SSL_CTX*, und der Unterschied ist nicht so klar, insbesondere weil man seinen Private Key in das SSL reinlädt, nicht in das SSL_CTX. Jedenfalls war das in dem Code so, den ich damals kannibalisiert habe. Wie sich rausstellt, kann man den Private Key aber auch in den SSL_CTX reinladen, und damit steht der Wiederbenutzung des selben SSL_CTX nichts im Wege. Das habe ich neulich mal eingebaut, und die SSL-Performance hat sich wenig überraschend massiv verbessert. Ist ja auch irgendwie klar. Wieso haben die überhaupt ein API, um den Private Key in das SSL* reinzuladen statt in den SSL_CTX*? Kann ich nicht nachvollziehen, verwirrt bloß.
Aber egal, darum geht es nicht. Was ich erzählen wollte: Der SSL-Code hat zwar seit Jahren funktioniert, aber auf ptrace (meinem Blog-Server) habe ich immer bizarre Probleme gesehen, wenn ich eine größere Datei per SSL runterladen wollte. Größer ist so "ab 100 KB" in dem Kontext. Der genaue Stresspunkt variierte. Das Symptom war, dass die Verbindung in der Mitte abbrach. wget verbindet sich dann neu und probiert nochmal, aber das nervt schon. Und vor allem war völlig unklar, was das Problem war. Normale SSL-Verbindungsabbrüche schicken über die Verbindung vorher ein Alert-Paket, damit die andere Seite sieht, wieso die Verbindung geschlossen wurde. Das ist auch nichts, was ich in gatling programmatisch mache, sondern das macht OpenSSL unter den Abstraktionen. So ein Paket kam bei dem wget nicht an.
Daraus schloss ich, dass ich wahrscheinlich irgendwo versehentlich einen Deskriptor schließe, der zu einer anderen Verbindung gehört, und habe aktiv nach Race Conditions und so gesucht. Zuhause konnte ich das nie nachstellen. Schlimmer noch: Wenn ich einen zweiten gatling auf ptrace gestartet habe, konnte ich das auch nicht nachstellen. Nur auf dem Haupt-Blog-gatling mit der ganzen Last tauchte das Problem auf.
Diese Untersuchungen führten zu diesen Überlegungen. Und als ich den Bug da geschlossen hatte, … brachen die SSL-Downloads immer noch ab. Es war also klar, dass ich da noch tiefer analysieren muss. Ich fing also an, mir das Log mit SSL-Fehlermeldungen zuspammen zu lassen, und kriegte da Fehlermeldungen, die so aussahen, als machte ich beim Ausgeben der Fehlermeldungen was falsch. Ich machte also einen strace auf gatling, während das Problem auftauchte, und sah eine Abfolge von Syscalls in etwa so:
accept() -> 23Hier konnte ich also ganz klar sehen, dass kein Fehler vorlag, aber die Verbindung trotzdem geschlossen wurde.
ein paar kurze read/write auf Socket 23, kein Fehler
ein längerer read auf Socket 23, kein Fehler (offenbar der HTTP-Request)
ein langes write auf Socket 23, kein Fehler
noch ein langes write auf Socket 23, diesmal wurden von den 8k nur 4k geschrieben (der Socket ist non-blocking, das soll also so sein)
SSL-Fehlermeldung im Log
close(23)
Nun ziehe ich mir ja SSL-Fehler nicht aus dem Arsch, sondern die kriege ich vom API gemeldet. Da stimmt also was nicht, und es lag nicht daran, dass meine State Machine irgendwo versehentlich einen Socket zu früh oder von woanders schließt.
Die komische SSL-Fehlermeldung, die ich bekam, war übrigens, dass "Shutdown in der Init-Phase aufgerufen wird" (ich hab mir die genaue Fehlermeldung nicht aufgeschrieben, aus der Erinnerung). SSL_Shutdown wird in gatling in cleanup() aufgerufen, das ist die zentrale "fertig, mach mal alle Ressourcen weg"-Funktion. So und jetzt der Fnord: OpenSSL hat einen Error Stack, nicht bloß eine aktuelle Fehlermeldung. Nach SSL_Shutdown habe ich keine Fehler geprüft, denn ob das protokollmäßig funktioniert oder nicht ist mir egal, ich schließe danach den unterliegenden Socket und gebe das SSL* frei. Aber gut, für das Debugging habe ich da mal ein Stück Code eingefügt, das den Error Stack leert.
Plötzlich waren die Verbindungsabbrüche weg.
Ich reime mir das jetzt so zusammen:
Ich hoffe mal, ich freue mich nicht zu früh, und der Bug tritt jetzt wirklich nicht mehr auf. Der ist nicht so einfach zu reproduzieren.
Wir lernen daraus: Error Stack nicht global sondern pro Context oder noch besser pro State machen.
Update: Hier kommt noch der Hinweis rein, dass einem dieser globale Error-Stack dann bei Multithreading massiv auf den Fuß fallen kann. Das befürchte ich auch. gatling ist im Moment noch nicht multithreaded.
Update: Ah, der Error Stack ist pro Thread. Oh Graus ist das alles widerlich.
Ich habe kürzlich einen experimentellen Patch eingepflegt, der Syscalls im heißen Pfad sparen soll. Bei gatling funktionieren virtuelle Hosts über Verzeichnisse, d.h. für blog.fefe.de geht gatling zuerst in "blog.fefe.de:80" oder "blog.fefe.de:443" und öffnet dann "favicon.ico" oder was man halt angefragt hat. Das chdir wollte ich da weg haben, also habe ich statt open() openat() benutzt, da gibt man als zusätzliches Argument einen Deskriptor zu dem Verzeichnis an, zu dem das relativ sein soll. Und es gibt einen kleinen Cache für Verzeichnisse zu Deskriptoren.
Das funktionierte in der Testsuite und Benchmarks auch ganz prima. Aber auf dem Live-Server unter Last nicht so sehr. Leider muss ich das irgendwie nachstellen können, um es debuggen zu können, und wenn sich das nur auf dem Livesystem nachstellen lässt, dann müssen wir da jetzt halt alle durch. Sorry.
Frank empfiehlt als Ausrede, dass die Chinesen / Russen mich gehackt haben. :-)
>>> pytz.__version__Auflösung: Das ist LMT, die Local Mean Time. Das bezeichnet die durchschnittliche Zeitzone an einem Ort vor der Standardisierung der Zeitzonen.
'2014.3'
>>> pytz.timezone('US/Central')
<DstTzInfo 'US/Central' LMT-1 day, 18:09:00 STD>
>>> pytz.timezone('Europe/Berlin')
<DstTzInfo 'Europe/Berlin' LMT+0:53:00 STD>
Die Shared Library hat eine neue Version, d.h. man muss einmal alle Software neu bauen. wget, curl, alles. curl baut gegen das neue OpenSSL, aber ist damit allein auf weiter Flur. wget musste ich patchen, mutt musste ich patchen, neon (für Subversion) musste ich patchen. git war gut. Der SSL-Code aus gatling geht überraschenderweise auch ohne Änderung. Aber sonst so? Kahlschlag.
Python baut zum Beispiel nur die Module _hashlib und _ssl nicht mit. Ihr könnt euch ja ausmalen, was das alleine an Folge-Infrastrukturapokalypse nach sich zieht. Bei mir konkret geht daher gerade SCons nicht, welches das Buildsystem von serf ist, ohne das ich Subversion nicht reparieren kann.
Die Perl-Module gingen auch. Aber so gefühlt ist über die Hälfte der Software jetzt zerbrochen.
Ich hätte mir ehrlich gesagt erhofft, dass die OpenSSL-Leute da eine klitzekleine Warnung in ihren Bart säuseln, bevor sie so eine Apokalypse lostreten.
Auf der anderen Seite ist das ja auch ein schöner Impuls, mal generell von diesem OpenSSL wegzumigrieren.
Update: Bei Debian hat es auch das eine oder andere Paket zerrissen.
Update: Ein Leserbrief dazu:
Wollte nur kurz darauf hinweisen, daß die API-Änderungen bei OpenSSL 1.1 nicht nur jede Menge inkompatibilitäten nach sich ziehen, bei denen was laut kaputt geht (compiletime error), sondern auch API-Änderungen dabei sind, die stillschweigend security-buigs erzeugen können.
Beispiel: Die HMAC manpage sagt:
HMAC_Init_ex() initializes or reuses a HMAC_CTX structure to use the
function evp_md and key key. Either can be NULL, in which case the
existing one will be reused.HMAC_Init_ex liefert erst seit kurzem einen Fehlerstatus zurück - früher hatte sie keinen Rückgabewert und konnte nicht fehlschlagen. Daher testet auch ne Menge Software nicht auf sowas, und das wra bis vor kurzem auch korrekt.
In OpenSSL 1.1 gibt es aber folgende Änderung:
/* If we are changing MD then we must have a key */
if (md != NULL && md != ctx->md && (key == NULL || len < 0))
return 0;d.h. anders als dokumentiert, kann nicht "either NULL" sein. Aber alte Software kann das nicht prüfen, und welche HMAC dann im Endeffekt berechnet wird, steht in den Sternen.
Die Reaktion von OpenSSL upstream war, die Doku zu ändern.
D.h. nicht nur breaked openssl die API (teilweise unnötig) so, daß Programme nicht mehr kompilieren, nein Programme, die mal korrekt waren und jetzt immer noch kompilieren haben jetzt unter Umständen größere Sicherheitslöcher.
(Es gibt eine Reihe ähnlicher stiller API-Änderungen in OpenSSL 1.1)
(und ja, wegmigrieren hört sich gut an, aber es gibt häufig keine alternative mit gleichen Funktionsumfang ohne diese Probleme - gnutls hat z.b. mindestens bis vor kurzem kein RSA-OEAP padding unterstützt, sondern nur das extrem anfällige kaputte PKCS-padding).
Und zu meiner Aussage, dass interne Typen opak gemacht wurden, kommentiert der Einsender noch:
Das, so würde ich sagen, ist falsch. Erstens sind viele dieser Datentypen nicht intern, sondern man musste früher darauf zugreifen weil es keine accessors gab und das auch so dokumentiert war, und zweitens ist das Hautproblem nicht, daß die Typen opak sind, sondern daß man früher structs selbst allozieren musste und das jetzt nicht mehr geht, d.h. alter code nicht compiliert, auch wenn er nicht auf irgendwelche strukturen zugegriffen hat.
Der Hintergrund für viele solche Änderungen war, daß man man structs nicht mehr auf dem Stack hat - sehr löblich. Das wurde aber so gelöst, daß man jetzt alles dynamisch über eine spezielle openssl-Funktion allozieren muss, die es früher nicht gab, und code, der die structs selbst deklariert hast, schlägt fehl, weil der Typ opak ist, auch, wenn garnicht darauf zugegriffen wird.
Im Allgemeinen ist es deshalb nicht möglich, code zu schreiben, der mit der neuen und der alten API funktioniert (also, ohne #if-massengrab).
Mir ist aufgefallen, dass auch Code mit #if-Massengrab bricht mit Version 1.1. Früher konnte man mit OPENSSL_NO_SSL2 gucken, ob die verwendete Version mit SSL2-Support kommt oder nicht. OpenSSL 1.1 hat kein SSL2 mehr, aber deklariert auch dieses Präprozessorsymbol nicht.
Update: Noch ein Leserbrief zur OpenSSL-Version:
OpenSSL 1.1 Unterstützung für Python ist fertig, hängt aber noch im Codereview, weil Python Core Devs mit OpenSSL-Kenntnissen Mangelware sind. Neben mir gibt es zur Zeit nur drei weitere aktive, von denen zwei mit anderen Dingen beschäftigt sind. Zum Glück habe ich schon vor einem halben Jahr mit meinem Patch angefangen angefangen und einige Patches bei OpenSSL eingereicht. Andernfalls würden mir jetzt die Zugriffsfunktionen auf diverse struct member fehlen.
https://bugs.python.org/issue26470Zwei weitere Punkte:
1) Es reicht nicht, nur auf OPENSSL_VERSION_NUMBER zu prüfen. LibreSSL hat OPENSSL_VERSION_NUMBER gekapert und missbraucht das Makro für die eigene Versionsnummber 2.x. Man muss also immer noch zusätzlich auf nicht-LibreSSL testen:
#if (OPENSSL_VERSION_NUMBER > 0x10100000L) || !defined(LIBRESSL_VERSION_NUMBER)2) Nach sweet32 hat OpenSSL 1.0.2 nur noch einen sicheren Algorithmus für symmetrische Verschlüsselung. ChaCha20 gibt es erst in 1.1. Ich habe mit Richard Salz vom OpenSSL Team gesprochen. Er teilt meine Sorge, trotzdem wird OpenSSL 1.0.2 LTS keine Unterstützung für ChaCha20 erhalten.
https://twitter.com/ChristianHeimes/status/768434388052938756
Nur falls jemand dachte, hey, dann bleib ich halt bei OpenSSL 1.0.2! Übrigens sei an der Stelle der Hinweis erlaubt, dass Version vor 1.0.1 schon länger gar keine Updates mehr kriegen. Man sieht vereinzelt da draußen noch OpenSSL 0.9er-Versionen rumfliegen. Ganz, GANZ gruselig.
Das mit Chacha20 war bei mir übrigens auch der Auslöser für den Umstieg auf 1.1. OpenSSL 1.1 hat nämlich endlich Support für die Dan-Bernstein-Erfindungen Chacha20 und Poly1305. Je älter ich werde, desto weniger traue ich Krypto-Sachen, die nicht von djb kommen oder von ihm abgenickt wurden. Der Mann hat einfach zu oft Recht behalten, als alle anderen abgewunken, relativiert oder gelacht haben. Ich sehe übrigens keinen inhaltlichen Grund, wieso man Chacha20 und Poly1305 nicht auch in 1.0.2 haben sollte, das gibt es seit Jahren für 1.0x-Versionen von OpenSSL als Patch, und LibreSSL hat es auch von Anfang an drin. Finde ich absolut unverständlich, was das OpenSSL-Team sich da leistet.
It seems incredible that this bug wasn't found during testing or even on ITW documents just by chance.Mal wieder Tavis Ormandy von Google.Ein bisschen ausführlicher hat er das hier beschrieben.
New hotness: Microsofts Compiler baut Überwachungsfunktionen in anderer Leute Software ein.
Überwachung ist hier nicht im Sinne von "zum Überwachen der User" gemeint, sondern der Code sammelt Telemetrie. Es sieht für mich ein bisschen wie "gut gemeint" aus, eine Art Debugging-Schnittstelle nur halt nicht zum Debugging sondern zum Profiling oder so.
Aber nachdem Microsoft mit diesem Malware-artigen Windows-10-Drückerkolonnen-Gebaren sämtliches gute Karma verspielt hat, weckt das halt erstmal weniger harmlose Assoziationen.
Ihr werdet es euch schon gedacht haben: Ist gar kein Bug. Sowas geschieht nicht aus Versehen. Ist Absicht.
Und so passt es ganz schön, dass jetzt eine Motte in der Wüste von Nevada einen Tesla-Autopiloten außer Gefecht gesetzt hat.
echo "rootmydevice" > /proc/sunxi_debug/sunxi_debugDer github-Link zeigt allerdings inzwischen ins Leere.
Wer ein diff und patch für Binärdateien sucht, für den gibt es leider kein Standardtool. Es gibt da diverse Tools auf dem Markt, das bekannteste ist xdelta, aber es gibt auch bsdiff, BDelta, bdiff (lag mal auf Sourceforge herum, aber scheint verloren gegangen zu sein; ich hatte hier noch einen Tarball für Version 1.0.4 herumliegen), jptch/jdiff und sicher noch mehr, die ich nicht kenne.
Mein Anwendungsfall war, dass ich hier ein ISO-Image einer Linux-Distribution ändere, und gerne davon wegkommen wollte, immer das ganze ISO übertragen zu müssen. Und so ein ISO, das sind mal eben 4 GB oder so.
Bei solchen Datenmengen trennt sich die Spreu vom Weizen. Ich nehme im Wesentlichen das unveränderte ISO-Image und füge ein paar Dateien dazu. Meine Erwartungshaltung war: Der Patch sollte 1 MB nicht überschreiten.
xdelta rödert länglich herum und erzeugt einen mehrere hundert MB großen Patch (ich nehme das ISO und füge ein paar Dateien dazu, wir reden hier von sowas wie 100 KB zusätzlichen Dateien). Da brach ich ab.
bsdiff versucht, die ganze Datei (mit read statt mmap!) in den Speicher zu lutschen und failed dabei, weil read() von 4 GB unter Linux nur 2 GB liefert. Ich weiß nicht, welcher Vollpfosten das bei Linux entschieden hat. In meinen Augen ist das ein Bug. War wahrscheinlich ein gut gemeintes Security-Theater oder so. bsdiff ist also auch ausgefallen.
jojodiff rödelt anderthalb Minuten und erzeugt dann 1,3 MB. Geht doch!
bdelta braucht 10 Sekunden (!?) und erzeugt einen Patch von 1,6 MB. Der funktioniert dann leider nicht. Wie sich rausstellt, ist das Dateiformat von bdelta hirnrissig und failed nicht wie im README dokumentiert ab 4 GB sondern schon vorher. Für das Abspeichern der relativen Offsets zwischen Quellen für Patches nimmt der 32-bit signed Integer, und prüft natürlich auch nicht, ob der Wert, den er abspeichern will, auch passt. bdelta ist aber ansonsten ausgesprochen sympathisch, weil der Quellcode so winzig und unprätentiös ist, und das Format so trivial. Also habe ich mal einen Patch gemacht, damit er die Integer mit variabler Länge abspeichert (ich nehme dafür das Verfahren von den Google Protocol Buffers, das ist ganz schlau wie ich finde). Das ganze Ding platzt wahrscheinlich immer noch bei Dateien über 4 GB, aber für meinen konkreten Anwendungsfall tut es ganz gut.
Weil das Projekt soweit verlassen wirkt, tu ich den Patch mal auf meinen Webserver, falls das jemand braucht.
Update: Ein langjähriger Leser weist darauf hin, dass ich die Gründe für das 2 GB-Limit schon mal erklärt hatte. Mein Kumpel Erdgeist prüft das übrigens gerade unter BSD, und zumindest OS X hat auch ein 2 GB-Limit, sogar dokumentiert bei readv.
Update: Unter den freien BSDs hat read() auch ein 2GB-Limit. WTF!?
Update: Einige Leser haben herausgefunden, dass man unter FreeBSD das 2GB-Limit mit den sysctls debug.devfs_iosize_max_clamp und debug.iosize_max_clamp abschalten kann.
Und zwar nicht spezifisch, sondern hat einfach Code drin, der eine Warnung anzeigt, wenn der Benutzer eine grotesk lange veraltete Version fährt. Und das ist bei Debian halt so.
Ich habe ja noch nie verstanden, wieso irgendjemand Debian einsetzt.
Bis ich mir neulich RPM angeschaut habe.
Das Tollste ist, wie sich bei dem Bug jetzt die Debian-Sprallos darüber unterhalten, wie man DIE WARNUNG AM BESTEN WEGPATCHT! Nicht etwa liefern sie lieber neuere Versionen aus, nein, diese impertinente Warnung wird weggepatcht!1!!
Hier ist die jwz-Position dazu, hochamüsant wie immer (folgt unbedingt auch den ganzen Previously-Links!)
Normalerweise braucht man für sowas echt Fantasie, ein Forschungsprojekt vielleicht. Oder man guckt einfach, was die für ihre exzeptionelle Sicherheit bekannten Spezialexperten von Comodo tun. Tavis Ormandy vom Google-Security-Team hat mal einen Blick gewagt.
I've found some memory corruption issues with the emulatorOK an der Stelle kann man eigentlich schon aufhören. Die Tatsache, dass der Bericht von Tavis weitermacht, nachdem er damit eröffnet hat, das ist echt beunruhigend.So geht es weiter:
but Comodo also implement hundreds of shims for Win32 API calls, so that things like CreateFile, LoadLibrary, and so on appear to work to the emulated code. Astonishingly, some of these shims simply extract the parameters from the emulated address space and pass them directly to the real API, while running as NT AUTHORITY\SYSTEM. The results are then poked back in to the emulator, and the code continues.OOOOH NEEEIIIIINNNN!!!Und das, meine Damen und Herren, ist der Grund, wieso ich mir bei schlechter Laune immer die Schlangenöl-Industrie angucke! *badumm-tsss*
Daher: Hier ein innovatives Konzept, wie man Bugtracker besser machen kann.
Und Hier die Erkenntnisse zu Human Factors aus der Flugzeugbranche.
Es geht um Defect Management. Eigentlich geht es mir nur um Software, aber ich vermute, dass das Prinzip auch überall sonst anwendbar ist, wo Dinge gebaut oder entworfen werden.
Hier ist die Prämisse: Fehler zu fixen ist teuer und aufwendig, und je länger man mit damit wartet, desto teurer und aufwendiger wird es.
Jetzt die Frage: Entwickler wissen das. Manager wissen das. Tester wissen das. ALLE WISSEN DAS. Wieso haben wir immer noch dauernd Situationen, in denen Bugs herumgammeln?
Die offensichtliche Erklärung ist, dass es irgendwelche Anreize in die Gegenrichtung gibt. Die würde ich gerne sammeln.
Ich gehe hier von so Dingen aus wie "ich traue mir nicht zu, den Bug zu fixen, weil ich ihn noch nicht verstanden habe" (offensichtlich eine schlechte Ausrede, denn dann debuggt man das halt, bist man es verstanden hat; wird ja nicht besser!) oder "Ich werde hier für Softwareentwicklung bezahlt, nicht für Fehlerkorrekturen", vielleicht auch in Form von "Die Deadlines sind zu kurz, ich habe da keine Zeit für" oder so.
Ich hätte da gerne mal eine nicht repräsentative Umfrage gemacht und würde gerne mal die Antworten aus verschiedenen Firmen und Branchen sammeln.
Update: Zwischenergebnis nach ~100 Einsendungen: Einer (EINER!!) sagt, in seiner Firma gäbe es genug Zeit für das Finden und Fixen von Bugs, und ordentliche Prozesse und gutes Tooling. Das sei alles sehr teuer, und manchmal geht man mit Unschönheiten in Produktion, weil man für ein Redesign keine Zeit mehr hat, aber richtige Bugs sind ihm nicht bekannt. Einer. Alle anderen heulen sich bei mir aus, wie schlimm das alles ist.
Gemeinsame Nenner: Unrealistische Deadlines, kein Budget für Bugfixing zurückgelegt, Management im Vogel-Strauß-Modus, Verkäufer haben unrealistische Zusagen gemacht, bis hin zu so Dingern wie "der Kunde hat noch nicht gezahlt, also machen wir das Produkt nicht heile" und "die Ausschreibung hätten wir nie gekriegt, wenn wir ehrlich gerechnet hätten, und jetzt machen wir nur das, was in unserer Bewerbung drinstand, und da steht nichts von Bugs".
Und die eine oder andere Anekdote, die ich mal sammeln und vielleicht beizeiten veröffentlichen werde. Bei Startups scheint es auch üblich zu sein, dass das ganze Geschäftsmodell so dermaßen superriskant ist, dass das Risiko, das von Bugs ausgeht, im Vergleich zu den anderen inhärenten Risiken förmlich untergehen. So ala "Selbst wenn der Bug morgen platzt und uns die Datenbank korrumpiert, ... ich weiß gerade eh nicht, wovon ich die Gehälter zahlen soll nächsten Monat"
Update: Ein Einsender schreibt, dass sie bei ihm in der Firma auch einen Haufen Bugs vor sich herschieben, und sich dafür der Begriff „Bugwelle“ eingeschliffen hat. HARR HARR, sehr schön!
Ich kann dir als Pharmaziestudent sagen, dass bereits heute JEDES MEDIKAMENT (!!!) von KI in gewissem Maße gemacht wird.Hier noch ein Einsender, der in eine ähnliche Bresche schlägt:"Drug Design" bzw. die Suche nach Wirkstoffen funktioniert nämlich folgendermaßen:
Zunächst sucht man den Liganden, der an den gewünschten Rezeptor bindet. Da es unglaublich viele Moleküle gibt, muss zunächst am Computer vorausgewählt werden. Diese Programme werden von Bioinformatikern geschrieben, die ausschließlich KI benutzen. Woher ich das weiß? 90% der Programme sind zwar closed source (gehören der Pharmaindustrie), aber die, die es an der Uni gibt, nutzen neuronale Netze (http://www.mrupp.info/publications.html). Erst nachdem es die ersten "hits" gibt bzw. man eine Leitstruktur ausgesucht hat, wird mit rationaleren Methoden weitergearbeitet (z.b. unser Programm). Dies ist aber eigentlich auch nicht so toll, weil z.B. QSAR davon ausgeht, dass wenn wir gleiche Molekülteile haben, diese stets ähnliche Wirkung haben. Dies führt zum "QSAR paradox", das den Sachverhalt beschreibt, dass die Grundannahme nicht stimmt (Contergan! Nein! Doch! Oh!).
Ich denke, dass es hier eine große Marktlücke gibt. Die guten Chemiker, die auch Ahnung von Quantenmechanik haben, arbeiten an Programmen, die kleine Moleküle sehr gut beschreiben/ Eigenschaften vorhersagen.
Die "schlechteren" arbeiten u.a. bei uns in der Synthese und konkurrieren leicht mit den Pharmazeuten.
Die Biophysiker beschäftigen sich mit spektroskopischen Methoden von Biomolekülen. Dies erfolgt rational und es werden auch Fortschritte erzielt.
Die Bioinformatiker sind die einzigen, die sich mit Computermodellen von Proteinen usw. befassen, greifen aber fast ausschließlich auf machine learning zurück. Ich kenne nur eine Ausnahme: http://www.merzgroup.org/
a couple of thoughts of mine about Google's KI: you did mention neural networks and related things. In medicinal chemistry people have been classifying chemical compounds for 30 years (!) using neural networks. It works extremely well - this one is toxic, that one isn't, this is a Glycoprotein P substrate, that one is not - even in prospective studies. It's impossible to derive any rules from all of these studies but my thought has always been: if it were simple they wouldn't have to resort to neural networks.You also mentioned healthcare. People are slowly waking up to the realities of systems biology. It really isn't that there are metabolic cycles or feedback loops, biologial reality doesn't look like this at all. What really happens is that there are all sorts of interacting networks of things, some of which may compensate for others. This is how evolution works, after all, though gene duplication and repurposing of enzymes. The whole fabric is already impossible to understand for any human and cannot be turned into a simple model. Hence the very expensive realities of pharmaceutical R&D. There was no reason to expect that COX-2 inhibitors would put those that take it at risk of heart disease, but it is a fact that they do. No idea why.
Dann gab es noch einen schönen Kommentar aus der Sci-Fi-Ecke:Du sagst im Grunde, dass der Mensch die höchste Intelligenz auf diesem Planeten war und ist, und folgerst, dass er es selbstverständlich auch bleiben sollte. Wir Menschen verwenden einen Gutteil unserer Ressourcen darauf uns zu reproduzieren und das beste aus unserem Nachwuchs zu machen. Wenn wir nun plötzlich in der Lage sind ein System zu erschaffen, das uns intellektuell überflügelt, dann sollten wir vielleicht aufhören uns zu reproduzieren und unsere Ressourcen in die Entwicklung dieses "besseren" Systems stecken. Für mich klingt das nach dem logisch nächsten Schritt in der Evolution. Das Thema ist nur hochgradig angstbesetzt.und weiter (war eine sehr lange Zuschrift, ich gebe daher aus Platzgründen nur Teile wieder):
In der KI-Forschung ist die Frage der Vorhersagbarkeit solcher Systeme (beider Varianten) natürlich schon ausgiebigst diskutiert worden. Das Ergebnis ist ein interessantes Paper namens "Structural Risk Minimization", das besagt: Je mehr (Lern)Kapazität ein Modell hat, desto höher ist das Risiko, dass es "was falsches" lernt, also einen Generalisierungsfehler macht. Und umgekehrt: Je mehr "widersprüchliche" Daten von einem lernenden System korrekt gelernt werden können sollen, desto höher ist die benötigte Kapazität.Dann kam noch dieser Link rein (es geht um genetische Algorithmen im Chipdesign, Ctrl-F baffling für den spannenden Teil)Für diese Kapazität gibt es auch ein Maß, und zwar die sog. VC-Dimension. Die VC-Dimension ist genau die maximale Anzahl an Datenpunkte, für ein Lerner - unabhängig von der Färbung der Datenpunkte - ein Modell (Programm) ausspuckt, das diese Punkte korrekt klassifiziert.
Zurück übertragen auf deine Frage mit der KI-basierten Softwareentwicklung: Da von einer KI derzeit nur Programme entwickelt werden können, die auf endlichen Eingabedaten funktionieren, kann man die so entwickelten Programme auch leicht daraufhin überprüfen, ob sie die Eingabedaten korrekt wiedergeben. Man enthält der KI einfach einen Teil der Eingabedaten vor und prüft anhand derer das resultierende Programm. Wenn die Fehlerquote signifikant über der gemäß VC-Dimension zu erwartenden Fehlerrate liegt, ist das Programm falsch. Und das war's dann auch schon.
Der Ansatz, dass ein Mensch ein von einer KI entwickeltes Programm "semantisch" überprüft, ist nur insoweit zielführend, wie die von der KI entwickelten Programme überhaupt Semantik verarbeiten. Und wenn sie das tun, sind die Ableitungen der Regeln, die diese Programme vornehmen (wie in Prolog) für einen Menschen auch wieder nachvollziehbar.
Und zuletzt weisen einige Einsender darauf hin, dass AlphaGo mitnichten einfach ein neuronales Netz ist, sondern schon auch "normale" Monte-Carlo-Baumsuche verwendet, aber halt unterstützt mit neuronalen Netzen. Einer kommentiert noch:
Ich stelle mir den menschlichen Go-Spieler wie einen Ingenieur vor, der ohne Hilfsmittel arbeitet. Die Google-KI ist dagegen ein Ingenieur, der einen Rechenschieber oder einen Taschenrechner (ein an sich nicht intelligentes, aber schnell und präzise arbeitendes Hilfsmittel) direkt ins Gehirn implantiert hat.Ein Einsender hat mir noch Mut zuzusprechen versucht, indem er Parallelen zur Mechanik zieht.Ein Beispiel ist Zug 108 der ersten Partie gegen Lee Sedol: Dieser Zug ist vielleicht keiner der besonders „komischen Züge“, aber ein menschlicher Spieler hätte diesen Zug niemals gemacht, denn er ist aus seiner Perspektive riskant. Die möglichen Konsequenzen sind komplex und vielfältig, und es ist schwierig abzuschätzen, ob wirklich alle sich ergebenden Varianten für den Spieler von Vorteil sind. Die Google-KI hingegen wirft ihren Monte-Carlo-Taschenrechner an und kann mit hinreichender Sicherheit feststellen, dass dieser Zug eben kein Fehler ist. Auf diese Weise verbindet AlphaGo die „Intuition“ seiner neuronalen Netze mit mehr oder weniger klassischer Vorausberechnung der Züge.
Der „Fehler“ des Menschen, weshalb er verliert, ist also so gesehen, auf die „riskant“ aussehenden, aber in Wahrheit sicheren Züge verzichten zu müssen und statt dessen die offensichtlich sicheren, aber nicht ganz so guten Züge zu spielen.
Früher hat man mechanische Bauteile -z.B. Schubstangen oder Pleuel- nach Erfahrung ausgelegt. Später kam ein mathematisches Modell zur Beschreibung der Bauteile (Eulersche Knickfälle). Noch sehr viel später hat man dann das Modell nach innen gelegt (kleine Gitterzellen FEM) und mit den Ergebnissen daraus das äussere Modell daran angepasst.und zur Frage der Debugbarkeit meint er, das ginge bei Mechanik ja auch nicht. Da kann man das Teil nur anders auslegen und neu bauen.Wir können immer noch nicht sagen, warum dieses eine Pleuel genau an dieser Stelle geknickt/gebrochen ist. Wir können nur sagen, dass es mit hoher Wahrscheinlichkeit an dieser Stelle wegen diesem Lunker, dieser Kerbwirkung, dieser Resonanz versagt hat (insbesondere bei Resonanzen bin ich mir sicher, dass das nur ca 1/5 der Ingenieure versteht, bei Torsionsresonanzen nochmal die Hälfte weniger).
Wir können es beschreiben, und seit einiger Zeit so gut, dass es fast keine weiteren Forschungsgelder mehr für Mechanik gibt, weil nichts grundlegend neueres erwartet wird.
Ich habe nicht viel Ahnung von Go, aber ich habe mir mal ein paar Kommentare durchgelesen. Und mein Eindruck ist, dass wir gerade eine Zeitenwende erleben.
Bei Schach war das so, dass die Computer halt mehr Stellungen voraus probieren konnten, und sie haben gewonnen, weil die Menschen Fehler gemacht haben. Kommentatoren haben sich das angeguckt und konnten auf den Zug zeigen und sagen: Das war ein Fehler. Das hat dich die Partie gekostet.
Aber bei Go gerade ist das anders. Die KI hat eine bessere Bewertungsfunktion als wir Menschen gefunden. Die Kommentatoren gucken sich die Parteien an und verstehen nicht, wieso die KI gewonnen hat. Der Mensch hat doch genau richtig gespielt! Der hat alles richtig gemacht, und dann hat die KI diesen komischen Zug hier gemacht, und dann hat der Mensch plötzlich verloren.
So, glaube ich, fühlt sich so ein Sci-Fi-Szenario an, in dem eine überlegene außerirdische Intelligenz die Erde angreift, und wir sind nicht schlau genug, ihre Strategie zu verstehen. Wir sehen, was sie tut, aber wir verstehen es nicht.
Das ist übrigens auch der Grund, wieso ich neuronale Netze und KI nie eine gute Forschungsrichtung fand. Wenn man so eine Software trainiert, und sie tut dann Dinge, dann kann man nicht daraus lernen, was sie genau gelernt hat, und das dann auch so tun. Man kann nur daneben sitzen und vielleicht einzelne Perzeptronen oder so beobachten, und sich sozusagen am Feuerwerk erfreuen, aber verstehen, was da passiert, und warum es passiert, das geht halt nicht. Fehler debuggen geht auch nicht. Man kann nur mehr oder neu trainieren.
Und jetzt haben wir den Salat. Glücklicherweise „nur“ bei Go. Bei Go halte ich uns Menschen für grundsätzlich in der Lage, durch Beobachtung und Gehirnschmalz herauszuforschen, wieso wir gerade deklassiert wurden. Aber der Weg ist sehr gefährlich, den wir da gehen.
Man stelle sich mal vor, überlegene KI wird sagen wir mal im Gesundheitssystem eingesetzt, tut 15 mysteriöse Schritte und heilt damit Patienten. Und hat dann Nebenwirkungen, und wir verstehen gar nicht die Herleitung.
Oder noch schlimmer (und das halte ich für eine sehr reale Gefahr): KI entwickelt eines Tages Software. Wir haben schon Probleme, von Menschen geschriebene Software später zu verstehen und zu warten. Man stelle sich mal vor, die Software tut Dinge, die keiner erklären kann, weil die von einer KI geschrieben wurde.
Und das übelste an dem Gedankengang: Wir haben diese Art von Problem jetzt schon, ganz ohne KI. Völlig ohne Not.
Wir sind halt doof, so als Spezies.
Update: Wobei, „auch so tun“ kann man schon. Das war falsch ausgedrückt. Aber verbessern kann man halt nicht. Eingreifen. Kontrolle hat man nicht mehr. Das ist wie ein Vergleich von Ingenieur und Kindergärtner. Man baut nichts mehr, sondern man erzieht eine KI. Wenn die dann das richtige tut — gut. Wenn nicht, dann hat man halt Pech.
Wobei ich auch sagen muss, dass es sich hier um eine GNU-Extension in einer selten verwendeten Funktion handelt, und die ist obskur genug, dass ich noch nie von ihr gehört habe. Wenn ich schätzen müsste, wer sowas anwendet, würde ich vielleicht auf Bash tippen.
Update: Github findet fünfstellig Hits, und ein Leser schreibt, systemd benutzt das.
Zur Klärung einiger Punkte, die vielleicht von dem Report nicht so ersichtlich sind…Ich habe inzwischen auch mal ein bisschen in den PDFs geblättert und muss meine Meinung zu dem Audit revidieren. Schon das Inhaltsverzeichnis macht klar, dass hier methodisch und systematisch vorgegangen wurde, und nicht nur ein bisschen Cherry-Picking stattgefunden hat.
Da es praktisch unmöglich ist, den ganzen OpenSSL-Code durchzublicken und zu evaluieren, waren im Scope der Analyse vor allem folgende Punkte:
- OpenSSL server
- TLS 1.2
- Verifikation der Gegenmaßnahmen der bekannten Angriffe (Identifikation des relevanten Codes war im Scope)
- kryptografische Angriffe
Alle Analysen und Algorithmen sollten nachvollzogen werden.
Vor allem wegen dem dritten Punkt kann ein Eindruck entstehen, dass nichts neues gemacht wurde (ja, wir haben z.b. Heartbleed, EarlyCCS nachgeprüft und es tut mir leid, wenn es dir nicht gefällt). In der Studie waren aber andere Angriffe, die vorher nicht konkret auf OpenSSL evaluiert wurden, ich nenne nur ein paar Beispiele:
- Bleichenbacher Angriff: da sind wir konkret noch tiefer auf die Angriffe eingegangen, als in unserem USENIX Paper (Link).
- DH-Kleine Untergruppen: es sind mir keine öffentlichen Dokumente bekannt, wo die Angriffe auf die letzten OpenSSL-Versionen besprochen wären.
- Invalid Curve Angriffe: vorherige Papers untersuchen andere Art dieser Angriffe, daher finde ich eine Überprüfung legitim. Bei den letzten zwei Punkten wurde es festgestellt, dass SSL_OP_SINGLE_DH_USE und SSL_OP_SINGLE_ECDH_USE nicht default sind, was im Report steht…
Ein falscher Eindruck hätte auch dadurch entstehen können, dass die Ergebnisse erst jetzt publiziert wurden. Die Studie wurde im Zeitraum cca. 6-2014/3-2015 durchgeführt.
Generell finde ich es extrem schwer in einer Bibliothek bugs zu finden, die täglich von hunderten Forschern auch untersucht wird. Da wir keine super gefährliche bugs gefunden haben, bedeutet es nicht, dass unsere Analyse schlecht war. Ein Beweis dafür liefern auch die letzten CVEs: es ist mir nicht bekannt, dass in den letzten zwei Jahren bugs gemeldet wurden, die in unserem Scope gewesen wären und die wir übersehen hätten (oder?).
Besonders die erwähnten Krypto-Dinge gefallen mir gut, denn das sind die Sachen, bei denen ich mir nicht sicher bin, dass ich das ordentlich getestet gekriegt hätte.
Für die Zukunft fände ich es gut, wenn wir vom Reaktiven zum Aktiven übergehen könnten. OpenSSL braucht mehr als einen Audit. OpenSSL braucht zum Beispiel eine Infrastruktur, um den Krypto-Kram optional in einen eigenen Prozess auszulagern, damit bei einem Bug in Apache nicht auch die privaten TLS-Schlüssel lecken können. Und was mich bei OpenSSL neben der furchtbaren Codestruktur und den ganzen bizarren Abstraktionen und Indirektionen am meisten stört, ist dass die Defaults in so vielen Fällen Scheiße sind. Erstens braucht man eine metrische Tonne Cargo Cult-Code, um überhaupt den ganzen nötigen Buchhaltungsscheiß zu erledigen, und dann braucht man nochmal zwei metrische Tonnen Code, um die ganzen schlechten Defaults zu korrigieren. Das geht so nicht.
Ich weiß nicht, ob das BSI dabei helfen kann. OpenBSD hat ja mal angefangen, einfach ein anderes API anzubieten, das weniger schlimm zu benutzen ist. Ich denke, da müssen wir hin.
So ungefähr alle halbe Jahr haben wir Kernel-Bugs. Und praktisch immer in irgendwelchen neuen esoterischen Komponenten, in diesem Fall sogar in einer Komponente, deren einziger Daseinszweck Security ist, nämlich das Speichern von Krypto-Schlüsseln im Kernel.
Aber eigentlich war das gar nicht der Bug, den ich posten wollte. Denn der hier ist viel cooler :-)
For now, every on all operating systems, please do the following:Add undocumented "UseRoaming no" to ssh_config or use "-oUseRoaming=no" to prevent upcoming #openssh client bug CVE-2016-0777. More later.
Update: Details sind draußen. Sie sagen, es handele sich um Code im Client für ein Feature, das OpenSSH auf Server-Seite schon länger nicht mehr supported. Und es ist Post-Auth. D.h. jemand müsste den sshd durch einen Bösen ersetzt haben, oder man müsste sich per ssh zu einem unvertrauenswürdigen Server verbinden. Die Auswirkung war anscheinend ein Memory Leak, d.h. potentiell Schlüsselmaterial geleakt. Wer also per ssh Verbindungen zu sshd außerhalb seiner Kontrolle aufgenommen hat, sollte seine Client-Schlüssel mal neu machen.
Google has fixed a bug in an online tool after it began translating "Russian Federation" to "Mordor".In addition, "Russians" was translated to "occupiers" and the surname of Sergey Lavrov, the country's Foreign Minister, to "sad little horse".
Das war der Übersetzungsservice von Ukrainisch nach Russisch. Googles Übersetzung basiert auf statistischen Modellen und Machine Learning, und die Leute in der Ukraine haben seit der Krim-Krise offenbar tatsächlich Russland konsequent als Mordor bezeichnet :-)
SNI ist eine TLS-Erweiterung, bei der als Teil des Handshakes der Name des Servers überträgt. Vor SNI konnte man pro IP-Adresse nur einen Server per SSL hosten. Meines Wissens unterstützen alle Browser SNI. Dachte ich jedenfalls.
Ich trug also das Letsencrypt-Cert per SNI ein, testete und alles war gut.
Aber es sieht aus, als war das Zufall, denn alle Nase lang kriegte jemand noch das Fallback-Cert zu Gesicht.
Beim Debuggen kam raus, dass das SNI-Callback auch später in der Verbindung nochmal kommen konnte, nicht nur während des Handshakes am Anfang. gatling macht virtuelles Hosting über Unterverzeichnisse, d.h. die Daten für "blog.fefe.de" sind in den Unterverzeichnissen "blog.fefe.de:80" und "blog.fefe.de:443", je nach dem wie der Client reinkommt. Nach dem initialen Handshake ist gatling dann in dem jeweiligen Unterverzeichnis und findet im SNI-Callback das Zertifikat nicht mehr.
Ich habe das dann als kurzer Hack so gefixt, dass ich die Zertifikate mit dem vollen Pfad öffne. Aber im Moment bei meinem Testen habe ich den Effekt, dass Firefox das Letsencrypt-Cert sieht, aber Chrome das CACert-Cert. Ich habe ehrlich gesagt keine Theorie, wieso das so sein könnte. Ich debugge mal weiter.
Update: Nach Shift-Reload zeigt auch Chrome das Letsencrypt-Cert an. Die werden doch nicht ernsthaft die Cert-Daten cachen!? Nee, so blöde kann keiner sein!
Update: Doch, so blöde können die sein.
Update: Et tu, Firefox?
Weiß jemand, wieviel Funktionalität Wireshark einbüßt, wenn man es ohne Lua baut? Ich habe gerade wenig Lust, mich in dieses Lua-Problem hier reinzudebuggen, hätte aber schon gerne ein aktuelles wireshark.
Ich habe ja noch nie "bro" als abwertendes Wort für Frauen gehört. Ich habe immer nur gehört, wie Frauen mit dem Wort Männer abwerten. ABER SELBST WENN, was hat das mit einer Abkürzung in einem HTTP-Header zu tun?! Geht's noch?
Jedenfalls gab es da Kritik. Wie so häufig, wir hatten ja bei C ähnliche Vorschläge. "Hey, wenn wir dieses API hier besser machen, dann werden wir weniger Bugs haben". Und da kommen dann so Old Farts aus dem Unterholz und sagen "ihr infantilisiert C-Entwickler, die sind nicht so doof wie ihr sie hier darstellt". Aber am Ende des Tages geben die Nummern dem eben Recht, lieber die Umgebung schon so zu machen, dass es leichter ist, alles richtig zu machen.
Ich erwähne das hier alles, weil sich rausstellt, dass djb natürlich mal wieder völlig Recht hatte. Natürlich gibt es Leute, die bei komplizierter Materie das falsch machen. Ich zitiere mal:
We evaluated 8 crypto libraries and their vulnerabilities to invalid curve attacks. We found out that the Bouncy Castle library and the Oracle JCE provider were vulnerable and we could extract private keys from the TLS servers running these libraries. The attacks are quite powerful. For Bouncy Castle, we needed about 3300 real server queries. For Oracle JCE, we needed about 17000 real server queries. We tested with the NIST-256 curve. The high number of requests needed for the Java servers results from a strange behaviour (bug?) in the Java EC computation.Ich könnte jetzt ein paar Worte fallen lassen über Java und die ganzen Java-Apologeten, die mir seit Jahren Mails schreiben, dass mit Java alles besser ist als mit C. Aber ich lehne mich glaube ich lieber zurück und sage: Told you so. :-)Dass wir uns da richtig verstehen: Wer mit Java ECC-Krypto gemacht hat, der muss jetzt neue Keys generieren. Und natürlich gucken, dass er eine gefixte Library irgendwo her kriegt. Aber hey, Oracle fixt ja schn… never mind.
Wie das halt so ist, wenn man Security-Kram nicht sofort fixt, sondern da glaubt, noch ein paar Wochen bis Monate drauf herumsitzen zu können. Merkel-Politik ist halt immer Scheiße, in der Politik wie bei Softwareprojekten. Aussitzen funktioniert nicht.
Hier ist ein Ubuntu-Bug dazu, und der ist ganz instruktiv.
Wenn man den Darstellungen dort glauben darf, dann hat Samsung in ihrer Firmware angekündigt TRIM mit NCQ zu können, kann es aber nur ohne NCQ. Linux guckt sich an, was die Firmware ansagt, und macht das dann halt, und dann failed die SSD. Der Fix ist jetzt, die Samsung-Geräte in die schwarze Liste der Geräte aufzunehmen, bei denen der Hersteller zu blöde ist, die tatsächlichen Capabilities zu announcen.
Glücklicherweise kann man immer noch sowohl TRIM als auch NCQ machen, nur halt nicht in Kombination. (Danke, Thomas)
ENDLICH sind wir weg von diesem Flash-Binärkack und von Binaries für irgendwelche speziellen Plattformen und haben Skriptsprachen für eine gemeinsame Plattform. Endlich kann man einfach Ctrl-U machen und sich angucken, was da passiert. Kaputte Skripte zur Not selber debuggen. Selbstgehackte DRM im Web ist endlich weg (abgesehen von diesem Chrome-Netflix-Zeugs).
Und was machen diese Schwachmaten da? Erfinden ein neues Binärformat fürs Web. Und sagen explizit an, dass das ein Compiler-Target sein soll. JA SUPER! Ich sage gleich mal an, dass es eine Industrie geben wird, die auf Basis davon DRM baut, die "Obfuscation"-Technologien verkaufen wird, und wir werden eine neue dunkle Ära für geschlossenes Web einleuten. Und das alles so völlig ohne Not! Und dann werden wir wieder "works best in Internet Explorer" haben. Eine Frage der Zeit, bis Microsoft oder Apple spezielle proprietäre APIs für ihre "Web-Binaries" exportieren. DirectX für WebAssembly! Und am Ende haben wir dann ein verkapptes .NET für Arme im Browser. Hint: Hatten wir schon. Hieß Silverlight. Ist gefloppt.
Admin log entry said: "Cannot redeclare class OC\Security\SecureRandom at /MY_WWW_PATH/owncloud/lib/private/security/securerandom.php#24"
Klarer Fall, denkt ihr euch jetzt vielleicht. Na dann guckt euch mal den Fix an. Die Zeile da auskommentieren, dann geht es. Wait, what?!
Übrigens gab es zwei Wochen nach dem Melden dieses Bugs ein Update, das nicht nur den Fix nicht drin hatte, sondern einen etwaigen manuell eingespielten Fix wieder mit der kaputten Version zurück-überschrieb.
Es gibt einen zweiten schönen Bug, den ich hier mal gleichberechtigt mitlaufen lasse. Und zwar in SDL. Der Einsender erklärt dazu:
Das korrigiert den Bugfix #11 von Januar 2006.Wenn ich das richtig verstehe geht es darum, dass bei einem Blit von RGBA-Surface auf RGBA-Surface der Alphakanal der Quelle ignoriert wird und nur das Alpha des Ziels verwendet wird. Nach 9 Jahren funktioniert es nun endlich richtig. Faszinierend, dachte immer das ist by Design und ich habe einen Denkfehler in meinem Code. Hat aber anscheinend wirklich jeder hingenommen, der erste Bugreport dazu ist von 2012 (#1518).
The US air safety authority has issued a warning and maintenance order over a software bug that causes a complete electric shutdown of Boeing’s 787 and potentially “loss of control” of the aircraft.Immerhin ist das einigermaßen vorhersagbar:The plane’s electrical generators fall into a failsafe mode if kept continuously powered on for 248 days.Update: Als Theorie liegt ein Integer Overflow nahe, wenn die intern mit 1/100 Sekunden rechnen. Dann kommt bei 248 Tagen ungefähr INT_MAX raus.
The 80ies called, they want their bugs back!
clang -O3 -Rpass-analysis="." linpack.c
linpack.c:255:21: remark: idamax can be inlined into dgefa with cost=60
(threshold=275) [-Rpass-analysis=inline]
l = idamax(n-k,&a[lda*k+k],1) + k;
^
linpack.c:276:21: remark: dscal_r can be inlined into dgefa with
cost=-14965 (threshold=275) [-Rpass-analysis=inline]
dscal_r(n-(k+1),t,&a[lda*k+k+1],1);
…
linpack.c:309:21: remark: loop not vectorized: value that could not be
identified as reduction is used outside the loop
[-Rpass-analysis=loop-vectorize]
l = idamax(n-k,&a[lda*k+k],1) + k;
^
linpack.c:703:5: remark: loop not vectorized: unsafe dependent memory
operations in loop [-Rpass-analysis=loop-vectorize]
for (i = m; i < n; i = i + 4)
This configuration very quickly yielded a fair number of additional, unique fault conditions, ranging from NULL pointer dereferences, to memory fenceposts visible only under ASAN or Valgrind, to pretty straightforward uses of uninitialized pointers (link), bogus calls to free() (link), heap buffer overflows (link), and even stack-based ones (link).Das ist ziemlich krass schlimm, denn sqlite wird von echt viel Software verwendet, u.a. Firefox und Chrome. Das wäre richtig unangenehm, wenn eine SQL Injection-Lücke einen Stack Overflow im SQL-Backend auslöst und man so das System übernehmen kann.Übrigens:
PS. I was truly impressed with Richard Hipp fixing each and every of these cases within a couple of hours of sending in a report. The fixes have been incorporated in version 3.8.9 of SQLite and have been public for a whileDaran erkennt man gute Software. So und jetzt entschuldigt mich kurz, ich muss mal ein paar Softwarepakete upgraden.Update: Übrigens, wer seinen Firefox neu baut: --enable-system-sqlite. Sonst nimmt Firefox seine eigene mitgelieferte alte Version und ist immer noch verwundbar. JA SUPER, liebe Firefox-Leute!1!!
Update: Öhm, ich habe gerade mit --enable-system-sqlite kompiliert, und da liegt am Ende immer noch ein libmozsqlite3.so herum mit einer älteren Version. WTF?!
Ja nee, klar.
Bonus: Es hat mit out-of-band TCP data zu tun. Damit haben wir schon in den 80ern Netzwerkdienste abgeschossen *schwelg*
Oh und es wird noch besser:
Impact: A local application may escalate privileges using a compromised service intended to run with reduced privileges.Description: setreuid and setregid system calls failed to drop privileges permanently. This issue was addressed by correctly dropping privileges.
Apple, fuck yeah!
By reading from the same
address in DRAM, we show that it is possible to corrupt data
in nearby addresses. More specifically, activating the same
row in DRAM corrupts data in nearby rows.Öh, wie meinen? Naja gut, das wird ja wohl nur ein paar ranzige Chinaplaste-"Nur für Export"-Module betreffen, oder?We demonstrate
this phenomenon on Intel and AMD systems using a malicious
program that generates many DRAM accesses. We induce
errors in most DRAM modules (110 out of 129) from three
major DRAM manufacturers. From this we conclude that
many deployed systems are likely to be at risk.Oh fuck.Hmm, naja, die machen da mit FPGAs rum, das betrifft ja wohl in der Praxis niemanden, oder? Die Google-Leute haben mal geguckt und konnten das in Code umwandeln, der auf realen CPUs Bits in der Page Table flippen, und sich damit Schreibzugriff beschaffen.
Das ist einer dieser Momente, wo man sich fragt, ob man nicht doch lieber Schäfer in Neuseeland werden sollte.
Die nächste Frage wird sein, wie verbreitet das Problem in Cloud-Servern ist. So Amazon EC2 und Microsoft Azure und so. *schauder*
Ich zitiere mal aus den Marketing-Bullet-Points:
Layered architecture so validation and debug layers can be unloaded when not neededWait, what? Validation aus Performancegründen ausmachen?! NEEEEEIIIIIIINNNNNNNNNNNNNN!Of course it doesn't work, but look how fast it is!1!!
Nun, äh, ja, das ist die Idee :-)
Der Bug ist von 2013.
Aus dieser Blockadehaltung heraus entstand damals LLVM, das konkret das Ziel hatte, eine Plugin-fähige Infrastruktur zu bauen, aus der man dann schöne Dinge zusammenstöpseln kann. Und in der Tat hat LLVM in den letzten Jahren einen beispiellosen Siegeszug angetreten und hat — nicht zuletzt durch finanzielle Unterstützung von Apple — in Sachen Qualität des Codegenerators fast zu gcc aufgeschlossen.
Wenn ihr jetzt mal bei dem Link oben auf die Äußerungen von Stallman klickt, findet ihr dieses Statement:
It looks like there is a systematic effort to attack GNU packages.Ich fürchte, wir haben es hier mit einem entstehenden Grabenkrieg zwischen freier Software und Open Source zu tun. Wenn da keiner was tut, verlieren alle. Sehr traurig.
Update: Auf dem zweiten Platz: Javascript, ISO-8601 und Time Zones.
Highlights, die sich anzugucken lohnen, sind (völlig subjektiv, versteht sich):
Mit der Fnord-Show war ich dieses Jahr selber nicht so zufrieden. Wir hatten zu viele Folien. Das wussten wir auch vorher, aber wir hatten schon einen gehoben zweistelligen Prozentsatz an potentiellen Folien vorher weggeschmissen. Das werden wir nächstes Jahr anders machen. Dem Publikum hat es anscheinend trotzdem ganz gut gefallen, insofern will ich da jetzt mal nicht zu schlecht gelaunt sein. Aber zufrieden war ich nicht. Bin ich aber so gut wie nie nach meinen Vorträgen, wäre ja auch langweilig.
Den heutigen dritten Tag nutze ich hauptsächlich für Socializen und vielleicht das eine oder andere Interview. Für Erich Möchls Vortrag heute morgen konnte ich mich leider nicht rechtzeitig aus dem Bett quälen. Das will man sicher auf Video gesehen haben, er sprach über NSA-Niederlassungen in Österreich.
Meiner Einschätzung nach sollte man heute um 17:15 den DP5-Vortrag nicht verpassen, aber der leider parallel liegende Vortrag "What Ever Happened to Nuclear Weapons" ist mindestens genau so wichtig. Ich schau mal, wo ich einen guten Sitzplatz finde, und den anderen gucke ich dann auf Video. Um 18:30 würde ich den Thunderstrike-Vortrag gucken.
Um 21:15 gibt es in Saal 2 einen Vortrag über Nordkorea, der wird bestimmt voll :-)
Um 22:00 verspricht der Perl-Vortrag hochkarätig zu werden.
Heute morgen bin ich direkt von einem FAZ-Reporter zu Regin befragt worden, und habe das ein bisschen auf eine generelle Malware-Schiene umzubiegen versucht. Mal gucken, wie das wird. Danach wurde ich direkt von Tilo Jung abgefangen, der hier auf dem Congress herumrennt und Interviews führt. Wir haben uns vorher ein bisschen darüber unterhalten, was wir für ein gutes Interview halten, und ob der Interviewer da Positionen bekleiden sollte oder nur den Interviewpartner reden lassen sollte. Ich finde ja letzteres. Das optimale Interview ist eines, bei dem der Interviewer dem Interviewgast ein paar Stichworte hinlegt und ihm dann nicht dabei im Wege steht, wenn er sich um Kopf und Kragen redet. Tilo war kürzlich in Israel und Paälstina und hat dort mit allen Seiten Interviews geführt, und erzählte, dass er dann erst dafür kritisiert wurde, er würde ja nur die eine Seite zu Wort kommen lassen, und als er dann mit den anderen redete, wurde er dafür kritisiert, denen nicht ins Wort gefallen zu sein, als die da krude Parolen äußerten und sich zum Klops machten. Dieses Muster (jetzt nicht mit Israel und Palästina) habe ich schon häufiger beobachten können und finde es ausgesprochen deprimierend. Ich hatte da vor ein paar Wochen schonmal was zu gebloggt, und so fragte mich dann Tilo auch zu Ken Jebsen. Ich hoffe, ich habe mich da jetzt nicht zu sehr um Kopf und Kragen geredet *hust*. Soviel ist jedenfalls klar: Je weniger Struktur der Interviewer vorgibt, desto mehr Gelegenheiten zum Verplappern hat der Interviewpartner. Vorsicht bei Interviews mit Tilo! :-)
Was Aftenposten jetzt gemacht hat, ist dass sie mit einem Cryptophone herumgelaufen sind, und die Baseband-Firewall an hatten. Dabei wird das Baseband sozusagen in einem Debug-Modus betrieben und zeigt interne Dinge gegenüber dem Betriebssystem an, was das dann anzeigen kann. Nun ist das nicht völlig ungewöhnlich, wenn ein Mobiltelefon vom Netz Daten kriegt, ohne danach gefragt zu haben. Wenn eine SMS kommt, will man das ja, oder wenn man Web klickt und die Antwort kommt. Daher hat Aftenposten diese Aktivitäten rausgerechnet und nur die übrigen Aktivitäten geplottet. Auch davon sind einige normal, z.B. wenn man sich ein Update für das assisted GPS holt, und es gibt auch einige gutartige Ncahrichten, die das Netz einem schicken kann. So 10-15 davon pro Tag sind normal. Aber so eine geographische Häufung ist ungewöhnlich, daher sind die Aftenposten-Leute nochmal mit einer Counterintelligence-Bude und ordentlichem Messequipment losgezogen und haben da komische Dinge gemessen und die Details ihrer Regierung übergeben.
Multimedia betrifft euch nicht auf eurer Textkonsole? Na gut: Buffer Overflow in Mutt, im Header-Parser. Gefunden von Michal Zalewskis neuem Fuzzer. Der scheint überhaupt ziemlich cool zu sein, der Fuzzer. Kommt mit Compiler-Integration zur Maximierung der Abdeckung. Oh, Michal Zalewski arbeitet übrigens auch im Google Security Team.
Ich hatte mal angefangen, einen Artikel zu schreiben, der der Google-ist-böse-Hysterie ein paar Fakten entgegen stellt. Das fällt nämlich gar nicht so leicht, Googles Handeln von einer fiktiven Firma zu unterscheiden, die auf einem Goldesel sitzt und mit dem Geld tatsächlich Gutes tun will. Klar ist das Scheiße, dass der Goldesel darauf basiert, dass sie Daten einsammeln. Und klar ist das Scheiße, dass die Jurisdiktion mit den Daten die USA sind. Aber, mal unter uns, glaubt ihr wirklich, dass irgendeine andere Jurisdiktion anders wäre und da keine Begehrlichkeiten entwickeln würde?
Ich persönlich glaube nicht an wohlwollende Diktatoren. Aber vom Verhalten her kann ich Google wirklich nicht viele konkrete Dinge vorwerfen. Was Microsoft für die Industrie getan hat in Sachen Security, das tut Google jetzt für Open Source. Ich erinnere nur mal an die 1000 Bugs in ffmpeg, die die dem Projekt eingereicht haben.
Aber einen gibt es, der mit offenem Visier kämpft. Der sah sich glaube ich zu einer Reaktion genötigt, weil ich seinen Thread mit Mario Sixtus verlinkt hatte. Sascha versucht hier heldenhaft, sich auf die Seite von Julia zu schlagen, aber kann an meinem Blogeintrag auch beim besten Willen keine Schmähkritik finden, daher konstruiert er halt eine:
Lustig, gell, da liegt ne Frau am Boden, da prügelt noch jemand drauf ein.Ich weiß ja nicht, wie das bei Sascha zuhause so ist, aber da wo ich herkomme ist das nicht lustig, wenn jemand auf eine am Boden liegende Frau einprügelt. Ich finde das überhaupt nicht witzig und halte es auch für unangebracht, da Witze drüber zu machen. Die Formulierung damals war absichtlich so gewählt, um auf den Umstand hinzuweisen, dass hier jemand ohne Not auf Wehrlose einprügelt.
Ich bin ja fast ein bisschen gerührt, wie Sascha und co sich dann bemühen, meine Äußerungen zu dekonstruieren, um da irgendwelche angreifbaren Punkte zu isolieren. Leider ist da nichts, und so bleibt nur der Vorwurf, wenn ich auf den Hass aus der Richtung der Feministen hinweise, dass ich damit den Hass in Richtung der Feministen ignoriere oder geringschätze oder relativiere. Diese These ist besonders sportlich angesichts der Tatsache, dass ich am Vortag extra auf diesen Hass hingewiesen hatte.
Inhaltlich bleibe ich dabei, dass man nicht das Unrecht der eigenen Seite gegen das Unrecht der anderen Seite aufrechnen kann. Wer Unrecht begeht, hat die Legitimität seines Anliegens verloren. So einfach ist das. Das gilt für "Männerrechtler", die das Wort "Feminazi" gebrauchen, genau so wie für "Frauenrechtler", die Passanten als "Masku" oder "Nazi" beschimpfen. Und egal um welches Anliegen es geht, wenn jemand das Wort "menschlicher Abschaum" in den Mund nimmt, hat er vollständig und auf Jahre für sich und seine Mitstreiter verkackt, egal worum es ursprünglich mal ging.
Oh, und, Pro-Tipp: Wenn ihr in einem meiner Blogeinträge keine Schmähkritik findet, dann war da wahrscheinlich keine drin.
Im Übrigen haben bei mir alle Journalisten direkt für immer verkackt, die nicht in der Lage sind, den Namen ihres Gegenübers richtig zu schreiben. "Don Alphonso". Notiert es euch. Nicht Fonsi, nicht Fossi, nicht Alphons. Don Alphonso. Wer damit überfordert ist, den Namen seines Gegenübers zu schreiben, der hätte lieber nicht Journalist werden sollen. Ja, Herr Sixtus, damit sind Sie gemeint. Tippfehler kann man mal verzeihen, aber absichtlich den Namen falsch schreiben, um den Gegenüber der Lächerlichkeit preiszugeben, das geht in dem Gewerbe gar nicht. Bei aller Geringschätzung, soviel Niveau muss sein. Ich nenne Sie auch nicht Herr Sackstuss oder so.
Update: Ah, Twitter-Zeitaccount. Und der Tweet. Kämpft sie also doch auch mit offenem Visier. Und ein Teil der gehässigen Formulierungen oben ziehe ich zurück, das war dann meine Schuld, dass ich diesen Tweet nicht gefunden habe, von dem mir jemand einen Paste schickte, ich ihn aber dann nicht wiederfand.
Update: Um das noch mal ganz deutlich zu sagen: Ich sehe mich da nicht als Betroffenen, weder von den marodierenden Masku-Horden, noch von den unflätigen Feministen-Schreihälsen. Aber im Vorbeiscrollen begegne ich ja schon diversem Unrat, und da war bisher noch so gut wie kein Masku-Unrat dabei, aber jede Menge Feministen-Schreihals-Unrat. So war das gemeint.
Unfortunately, because of the large number of sites which incorrectly handled TLS v1.2 negotiation, we had to disable TLS v1.2 on the client.Dass diese Debilianisten und ihre Abkömmlinge das aber auch nicht lernen, die Finger von OpenSSL-Patches zu lassen!
Damit einen das betrifft, müsste ein Netzwerk-Dienst von remote Environment-Werte entgegennehmen und dann bash aufrufen. An der Stelle hat man dann aber auch Probleme mit $LD_PRELOAD und $IFS und so weiter.
Dennoch. Tolle Infrastruktur haben wir da!
Update: Hier gibt es ein paar Details. Es ist ungefähr wie ich gedacht hatte. Man muss sich schon anstrengen, um da betroffen zu sein. Und angestrengt haben sich: Leute, die Subversion oder git über SSH mit ForceCommand machen; Leute, bei denen der Webserver CGI via Bash aufruft; Leute, die ranzige DHCP-Clients einsetzen, die lokal irgendwelchen Shellskripte mit Environment auf Basis von Werten des Servers aufrufen. Das ist schon einmal ein richtig doll krass peinlicher Bug, und wer Bash auf dem System hat sollte jetzt updaten.
Update:
env x='() { :;}; echo vulnerable' bash -c "echo test"
In der Bestätigungsemail von Paypal steht dann der tatsächlich abgebuchte Betrag drin. Die sollte man also spätestens ab jetzt jeweils aufmerksam prüfen.
"When the screen is locked with password, if I hold ENTER after some seconds the screen freezes and the lock screen crashes. After that I have the computer fully unlocked.
Fakt ist: OpenSSL ist nicht in C, weil C so geil ist. OpenSSL ist in C, weil das Ziel ist, dass das von jeder Programmiersprache aus benutzbar ist. Und alle können sie C-Code aufrufen.
Fakt ist auch: Das ist ein komplexes Problem, SSL richtig zu implementieren. Und wenn man dann noch den Anspruch hat, alle Obskuro-Plattformen und alle Extensions zu unterstützen, dann ist das Ergebnis halt Scheiße. Wenn man sich anguckt, was OpenBSD da gerade mit der flammenden Machete alles aus OpenSSL herausoperiert, da wird einem ganz anders. Unter anderem Support für Big Endian x86_64 Plattformen. Hat jemals schon mal jemand von sowas gehört? Nicht? Wie ist es mit VMS? EBCDIC-Support? Support für "ungerade" Wortlängen? You name it, OpenSSL supports it.
Dieses Java-Ding ist übrigens auch in einer Dissertation von einem der Beteiligten drin. Die kann man hier lesen (208 Seiten). (Danke, Sebastian)
Aber die Kernbotschaft, egal ab wann Geheimdienste das exploited haben, ist: Geheimdienste arbeiten gegen ihre eigene Bevölkerung, nicht für sie. Die Geheimdienste wussten davon und haben nichts gesagt.
Oh und eine Sache noch: Das sieht jetzt hier aus wie eine Bankrotterklärung von Open Source. Das stimmt nicht. Der Bug wurde von zwei Leuten gleichzeitig gefunden und gemeldet. Einmal von einer Security-Firma, die eine Testsuite für SSL-Bugs programmiert hat. Die hätte das auch bei einem Nicht-Open-Source-SSL gefunden. Aber der andere Finder war ein Google-Angestellter, der einen Quellcode-Audit gemacht hat. Den hätte es so bei einem Nicht-Open-Source-SSL nicht gegeben. Wir haben hier also die Chancen direkt verdoppelt, solche Bugs zu finden. Wer weiß, was in Kommerzsoftware noch so für Untiefen lauern.
Meiner Erfahrung nach variiert die Codequalität bei Open Source und bei kommerzieller Software immens, und der Durchschnitt liegt ungefähr auf einem vergleichbaren Niveau. Man kann nicht davon ausgehen, dass kommerzielle Software grundsätzlich ein höheres Niveau hat.
Übrigens stört mich an der Debatte ein bisschen, dass so wenig Leute daraus Konsequenzen ziehen. Wir benutzen alle die ganze Zeit Open Source Software, ohne dafür zu zahlen, und wir benutzen Kommerzsoftware und bezahlen dafür. Dann wundern wir uns, dass die Hersteller von Kommerzsoftware Geld haben, um davon Audits machen zu lassen, aber die Open Source-Leute warten müssen, bis Google mal vorbeikommt.
Eine mögliche Konsequenz aus dem aktuellen Geschehen könnte sein, dass man mal einen Fonds macht, in den Benutzer von Open Source-Software einzahlen, und mit dem dann Qualitätssicherungsmaßnahmen bezahlt werden, für die Freiwillige bei den jeweiligen Projekten nicht die Motivation aufbringen. Das meint natürlich Security-Audits, aber es meint auch sowas wie ordentliche Testsuiten basteln; Dokumentation bereitstellen.
Update: Die US-Regierung dementiert. Was sollen die auch sonst sagen. Sie behaupten sogar, dass sie alle Lücken reporten, die sie finden. Ja nee, klar.
Hier ist der git commit. Das ist aber nicht der Punkt hier gerade.
Wo arbeitet der? Was meint ihr? Kommt ihr NIE drauf!
Robin Seggelmann T-Systems International GmbH Fasanenweg 5 70771 Leinfelden-Echterdingen DE
Update: Eine Sache noch. Nehmen wir mal an, jemand würde mich bezahlen, eine Backdoor in OpenSSL einzubauen. Eine, die auf den ersten Blick harmlos aussieht, die aber ohne Exploit-Schwierigkeiten auf allen Plattformen tut und von den verschiedenen Mitigations nicht betroffen ist. Genau so würde die aussehen.
Ich sehe in dem Code nicht mal den Versuch, die einkommenden Felder ordentlich zu validieren. Und auch protokolltechnisch ergibt das keinen Sinn, so eine Extension überhaupt zu definieren. TCP hat seit 30 Jahren keep-alive-Support. Es hätte also völlig gereicht, das für TLS über UDP zu definieren (und auch da würde ich die Sinnhaftigkeit bestreiten). Und wenn man ein Heartbeat baut, dann tut man da doch keinen Payload rein! Der Sinn von sowas ist doch, Timeouts in Proxy-Servern und NAT-Routern vom Zuschlagen abzuhalten. Da braucht man keinen Payload für. Und wenn man einen Payload nimmt, dann ist der doch nicht variabel lang und schon gar nicht schickt man die Daten aus dem Request zurück. Das ist auf jeder mir ersichtlichen Ebene völliger Bullshit, schon das RFC (das der Mann auch geschrieben hat), das ganze Protokoll, und die Implementation ja offensichtlich auch. Aus meiner Sicht riecht das wie eine Backdoor, es schmeckt wie eine Backdoor, es hat die Konsistenz einer Backdoor, und es sieht aus wie eine Backdoor. Und der Code kommt von jemandem, der bei einem Staatsunternehmen arbeitet, das für den BND den IP-Range betreut (jedenfalls vor ein paar Jahren, ob heute immer noch weiß ich nicht). Da muss man kein Adam Riese sein, um hier 1+1 zusammenzählen zu können.
Update: Es stellt sich raus, dass der Mann damals noch an seiner Dissertation geschrieben hat und an der Uni war und erst später bei T-Systems anfing. In der Dissertation geht es unter anderem um die Heartbeat-Extension, die mit UDP begründet wird. In dem Text steht auch drin, dass man keine Payload braucht. Aber lasst uns das mal trotzdem so machen, weil … Flexibilität und so!
Update: Echte Verschwörungstheoretiker lassen sich natürlich von sowas nicht aufhalten. Der Job bei T-Systems war dann halt die Belohnung!1!! Und echte Verschwörungstheoretiker googeln auch dem Typen hinterher, der den Code auditiert und durchgewunken hat, damit der eingecheckt werden konnte. Ein Brite, der nur 100 Meilen von Cheltenham (GCHQ-Sitz) entfernt wohnt!!1!
Update: Robin Seggelmann hat der australischen Presse erklärt, das sei ein Versehen gewesen.
Update: Hier ist eine Gegendarstellung dazu von Herrn Seggelmann:
Der Fehler ist ein simpler Programmierfehler gewesen, der im Rahmen eines Forschungsprojektes entstanden ist. T-Systems und BND oder andere Geheimdienste waren zu keiner Zeit beteiligt und zu meiner späteren Anstellung bei T-Systems bestand zu keiner Zeit ein Zusammenhang. Dass T-Systems im RFC genannt wird, liegt an der verspäteten Fertigstellung des RFCs und es ist üblich, den bei der Fertigstellung aktuellen Arbeitgeber anzugeben.
(Danke, Jürgen)
Aber selbst wenn das nur eine Sicherheitsfirma war, ist das natürlich ein ganz übler Verkacker, nicht nur für die betroffene Firma sondern auch für die ganze Branche. Fakt ist leider einfach mal, dass der Kunde bei Sicherheitsaudits im Allgemeinen dasteht wie der Patient beim Arzt, oder der Kunde beim Klempner oder in der Autowerkstatt. Der Experte kann dem Kunden da einen vom Pferd erzählen. Der Kunde kann das gar nicht prüfen, weil er die Materie gar nicht ausreichend versteht. Ausnahmen bestätigen die Regel.
Aber mal zum konkreten Interview hier. Die Überschrift sagt: Vier Security-Buden haben auditiert. Das Interview selbst sagt aber was anderes:
Wir testen unsere Produkte nicht nur selbst, sondern auch mit vier externen UnternehmenDa steht Test, nicht Security-Test. Wer sagt, dass das nicht sowas wie "Abstrahlung wegen CE-Siegel prüfen" oder so war. Weiter unten dann:
Diese Sicherheitsdienstleister, so Schöllhammer weiter, bekommen von AVM umfangreiche DokumentationenWie, nur Dokumentation? Nicht den Code? Dann kann man auch nicht wirklich von einem Audit reden, sondern nur von einem Penetrationstest.
AVM selbst macht auch noch Fuzzing, sagen sie. Was ich über den Bug bisher gesehen habe: Es ist eine Unix-Kommandozeilen-Injection über schlecht validierte URL-Bestandteile. Das Backend ist anscheinend ein großes CGI-Binary mit LUA drin. Ich hab ja nichts gegen LUA, aber dieser Ansatz heißt eben auch, dass dieses Binary mit den maximalen Zugriffsrechten laufen muss, die man für alle Aktionen braucht, die dieses Tool ausführen muss. Das Design hätte schonmal Punktabzug geben müssen im Audit.
Dann: Nicht ordentlich validierte URL-Bestandteile sind genau die Haupt-Angriffsfläche bei Web-Anwendungen.
Wenn ich den Quellcode für eine Webanwendung habe, greppe ich als erstes nach Dingen wie system() und Logging-Funktionen (für Format-String-Bugs) und SQL-Statement-Absetz-Routinen (für SQL Injection). Das ist das erste, was man tut, noch bevor man sich ein Kaltgetränk holt. Es ist aus meiner Sicht nicht glaubwürdig, dass ein Audit nicht findet, wenn URL-Bestandteile in system() landen, ob gefiltert oder nicht. Daher glaube ich, dass hier kein Audit stattfand sondern nur ein Penetrationstest ohne Quellcodezugriff.
Wenn man einen Penetrationstest macht, ist das erste, was man tut, dass man einmal alle URLs kartografiert, die in der Oberfläche so vorkommen. Dafür gibt es Tools. Dann geht man die alle durch und tut jeweils Sonderzeichen rein oder übergibt besonders lange Strings. Das ist, was ein Penetrationstest tut. Im Fall der Fritzbox sind die BIOS-Images öffentlich, d.h. man kann beim Kartografieren die Liste der Skripte sehen. Das senkt die Wahrscheinlichkeit dafür, dass man ein Skript übersieht.
Was ich sagen will: Selbst wenn die keinen richtigen Audit hatten sondern nur einen Pentest, selbst dann hätte dieser Bug gefunden werden müssen. Da gibt es keine Ausrede.
AVM sagt, dass sie Fuzzing machen. Der Kontext scheint zu sein, dass sie da ihre VOIP-Protokolle gefuzzt haben. Aber anscheinend nicht ihre Web-Oberfläche, denn Fuzzing der Weboberfläche hätte diesen Bug auch gefunden.
Ich kann mir das also nur so erklären, dass entweder gar keine Security-Tests stattgefunden haben, sondern nur Funktionalitätstests, oder dass der Dienstleister viel zu wenig Zeit gekriegt hat (das kommt leider häufig vor in der Praxis, dass da unter starkem Zeitdruck operiert wird, weil so ein Audit ja auch signifikant Geld kostet), oder dass da schlicht der/die Dienstleister überfordert war. Der Bug sieht für mich jedenfalls nicht wie die Art von Bug aus, bei denen man halt mit den Schultern zuckt und Shit Happens sagt. Dieser Bug war vermeidbar.
Bei allem Bashing über die AVM-Prozesse muss man aber auch anerkennen, dass die vorbildlich reagiert haben. Hoffentlich machen sie jetzt auch einen Anlauf und suchen nach den anderen Bugs, die vermeidbar gewesen wären :-)
Update: Oh, eine Sache noch. Wie gesagt ohne jeden Einblick in diesen speziellen Fall. Was auch passieren kann, wieso so ein Bug nicht gemeldet wird: Wenn man beim Audit SO VIELE BUGS findet, dass man die gesamte verfügbare Zeit damit beschäftigt ist, die bereits gefundenen Bugs zu Protokoll zu geben, dann fällt hinten auch was runter. Das kommt gelegentlich vor. An der Stelle kann man dann dem Sicherheits-Dienstleiter keinen Vorwurf machen.
Ich behaupte auch nicht, dass dieser Bug aus irgendeinem automatisierten Tool hätte rausfallen müssen. Aber ich behaupte, dass das genau die Art von Angriffsoberfläche ist, die man bei einem Penetrationstest prüft. Das ist kein Obskuro-Spezial-Unfindbar-Krypto-Heisenbug, der sich nur bei bestimmten Sternenkonstellationen und Außentemperaturverhältnissen ausnutzen lässt.
No. MediaWiki doesn't target this type of environment, and our policy is to be open about the fact that we are not built for that, since security problems in an unmaintained, half-done approach are likely to crop up constantly.If you actually need fancy read restrictions to keep some of your own people from reading each others' writing, MediaWiki is not the right software for you.
I hadn't realized this bug was actually still open, I'm resolving it as WONTFIX.
*schenkelklopf* (Danke, Lukas)
A bug in the bitcoin software makes it possible for someone to use the Bitcoin network to alter transaction details to make it seem like a sending of bitcoins to a bitcoin wallet did not occur when in fact it did occur. Since the transaction appears as if it has not proceeded correctly, the bitcoins may be resent. MtGox is working with the Bitcoin core development team and others to mitigate this issue.Das ist der Supergau.Update: Die Situation scheint weniger klar zu sein als da steht. Es mehren sich Stimmen, die behaupten, dass das doch "bloß" die Implementation bei diesem einen Exchange betrifft. Das Problem ist zwar im Protokoll, weil dieser ID-Wert nicht Teil der Checksumme ist, aber der Fehler, der zu Mehrfachauszahlen führt, ist bei MtGox, weil die ihre Auszahlentscheidung u.a. auf dieser ID basieren. Siehe u.a. hier.
Update: Und hier. (Danke, Rop)
CVE-2013-4458 Stack overflow in getaddrinfo with large number of results for AF_INET6 has been fixedDas ist remote code execution via unvertrauenswürdiger, unverschlüsselter Daten aus dem Internet. GANZ gruselig. Man würde denken, die libc ist der stabilste, sicherste Teil des Codes. Der ordentlich auditierte Code. Aber offensichtlich nicht. Auch die anderen Bugs sind gruselig, aber für die muss man schon auf dem System sein, um die ausnutzen zu können. Mein Lieblingsbug ist der hier:CVE-2013-4788 The pointer guard used for pointer mangling was not initialized for static applications resulting in the security feature being disabled.Das ist ein typischer Ulrich Drepper. Als der noch glibc-Maintainer war, fand er, dass statisches Linken alt und scheiße ist und nicht mehr unterstützt gehört. Als er dann "Pointer mangling" einbaute, hat er es daher nur für dynamische Programme getan. Denn hey, wer linkt heutzutage noch statisch!1!!
Ich prüfe da nicht viel, im Wesentlichen will ich, dass das Opcode-Byte sagt, dass es ein Handshake ist, und dass die TLS-Version gültig aussieht, und dass die Länge des Handshake-Paketes nicht größer als 256 ist. Warum 256? Weil das nach damaligen Verhältnissen exorbitant viel war und weil 256 in Binärdarstellung ein 1-Byte in der höherrangigen Hälfte des Längenfeldes war, was sich dann leicht testen ließ.
Was jetzt passiert ist, ist dass Chrome so viel Bloat mitschickt, dass bei denen 0x200 als Länge im Header steht, also 512. Wir erinnern uns: Chrome, das waren die Leute, die wegen des angeblichen HTTP-Header-Bloats ein eigenes Konkurrenzprotokoll namens SPDY erfunden haben, das so super toll optimiert ist, dass für die zwei e kein Platz mehr im Namen war. DIE Leute haben jetzt ihr SSL-Handshake soweit aufgebläht, dass es in meinen Sanity-Check rannte.
SPDY basiert übrigens auch auf SSL.
Einmal mit Profis arbeiten!
Update: Vier der Extensions sind so neu (oder Google-proprietär?), dass Wireshark sie noch nicht kennt.
Update: Es gibt eine Erklärung, wieso der SSL-Header so groß ist. Das ist kein Bloat, sondern die machen das absichtlich, um um eine ranzige F5-Firmware herumzuarbeiten. m(
Dear sir or madam. Please consider my submission for the most pedantic bug ever reported.The sixth word in the loremipsum macro should be "consectetur", not "consectetuer", which is a word not found in Cicero … or Latin.
Und die Punchline: Jemand weist darauf hin, dass auch das erste Wort, lorem, kein Latein ist, sondern dolorem sein sollte. Das stimmt übrigens :-)Der verlinkt auch auf den Ursprungstext von Lorem Ipsum — das kommt tatsächlich von Cicero.
Neque porro quisquam est qui dolorem ipsum quia dolor sit amet consectetur adipisci velitÜbersetzung: Und es gibt auch niemanden, der Schmerzen liebt, anstrebt oder herbeiführt, weil es Schmerzen sind.
Cicero hat echt wunderbare Reden gehalten (und ja, er war Anwalt, falls sich jemand über die Formulierung wundert). Einer der Höhepunkte einer humanistischen Schulbildung.
Inhaltlich ist das glaubwürdig. Der Irak glaubt hoffentlich nicht ernsthaft, die Amerikaner würden ihnen Kriegsgerät ohne Hintertüren liefern. (Danke, Torsten)
Bei dieser Pointer-Verschlüsselung handelt es sich um eine Buffer Overflow Mitigation, also eine Maßnahme, die im Falle von Buffer Overflows die Ausnutzung erschweren soll. Die traditionalle Methode sind Stack Canaries, das sind "zufällige" Werte auf dem Stack. Und bevor man potentiell im Rahmen eines Buffer Overflows überschriebene Werte übernimmt, prüft man, ob der Kanarienvogel noch lebt, wie damals in den Minen. In der glibc wurde ein anderer Weg gewählt, nämlich dass die Pointer "verschlüsselt" werden. Dafür wird statt des tatsächlichen Wertes ein XOR mit einem "zufälligen" Wert und eine Rotation gemacht. Die Idee ist, dass der Angreifer das dann zwar überschrieben kann, aber da er den XOR-Wert nicht kennt, kann er nicht wissen, welchen Wert er da hinschreiben muss. Und der Wert ändert sich mit jedem Programmaufruf. Außer halt wenn man glibc nimmt und statisch linkt.
Grimes: How many exploits does your unit have access to?Cyber warrior: Literally tens of thousands — it's more than that. We have tens of thousands of ready-to-use bugs in single applications, single operating systems.
Grimes: Is most of it zero-days?
Cyber warrior: It's all zero-days. Literally, if you can name the software or the controller, we have ways to exploit it. There is no software that isn't easily crackable. In the last few years, every publicly known and patched bug makes almost no impact on us. They aren't scratching the surface.
Ich halte den Typ vom Stil her für einen Pfuscher, einen Angeber, jedenfalls weit von dem entfernt, als was er sich hier hinzustellen versucht. Und so würde ich auch von den Zahlen der verfügbaren Exploits ein paar Ziffern rausstreichen, um zu realistischen Zahlen zu kommen. Und so trivial ist das mit dem Exploiten ja auch nicht mehr heutzutage, wenn man nicht gerade echt Glück hat mit einem Bug. Mit anderen Worten: da protzt ein Kiddie rum. Muss man sich m.E. keine Sorgen machen, dass an dessen Zahlen was dran sein könnte.Aber ich dachte mir, ich schreibe das hier mal, bevor da groß Panik ausbricht. Faustregel: In einem Raum voller Security-Leute ist der einzige interessante der Ruhige in der Ecke, der es nicht nötig hat, seine angeblichen Fähigkeiten herauszustellen.
DROPMIRE implanted on the Cryptofax at the EU Embassy D.C.
The EU pass diplomatic cables via this system back to the MFA.Und DIE haben groß rumgepupt und Bradley Manning in Isolationsfolter gesteckt, als IHRE Cables wegkamen. Aber UNSERE Cables sind offensichtlich fair game.Überhaupt regt mich die Doppelzüngigkeit der Dementis tierisch auf. Eines (!) der Systeme saugt nur Metadaten auf, weil man mehr für Trafficanalyse und co eben nicht braucht. Und die verteidigen sich jetzt konkret gegen dieses System, sagen das aber nicht dazu, und so ist bei einigen Europäern als Fazit angekommen, dass die ja nur Metadaten speichern und nicht Inhalte. Wohlgemerkt ist auch das mehr als ausreichend für einen Totalverlust der Privatsphäre. Aber ich möchte das mal ganz explizit ansagen: Nein, die sammeln nicht nur Metadaten. Lasst euch nicht verarschen von deren PR-Dementis. Natürlich schnorcheln die auch die ganzen Inhalte ab, da könnt ihr mal einen drauf lassen. Das ist das Zeitalter von Big Data, Baby. Wenn irgendwas irgendwo als Daten vorliegt, schnorcheln wir es ab. Was man da später draus gewinnen kann, das wird man ja dann sehen später.
QuickTimeAvailable for: Windows 7, Vista, XP SP2 or later
Impact: Playing a maliciously crafted movie file may lead to an unexpected application termination or arbitrary code execution
Description: A buffer overflow existed in the handling of H.263 encoded movie files. This issue was addressed through improved bounds checking.
CVE-ID
CVE-2013-1016 : Tom Gallagher (Microsoft) & Paul Bates (Microsoft) working with HP's Zero Day Initiative
Hmm, bestimmt ein Copy+Paste-Fehler, denkt ihr euch vielleicht. Microsoft würde doch keine Sicherheitslücken an Apple weitergeben, die sie in deren Produkten finden?
Und dann findet man diese ZDI-Seite mit den "upcoming advisories". ZDI kauft Sicherheitslücken, gibt die dann an die Hersteller weiter, und bezahlt den Einreicher. Deren Geschäftsmodell ist, dass sie die auch weiterverkaufen, bevor die Hersteller die fixen. Und da sieht man dann z.B. das:
ZDI-CAN-1737 Apple CVSS: 6.8 2013-05-14 (27 days ago) 2013-11-10Und so wird dann ein Schuh draus. Dieser Tom Gallaghar arbeitet an der Security von Office. Und Office kann Quicktime einbetten. Und so ergibt sich plötzlich ein stimmiges Bild. Die werden da ihre Office-Dokumente gefuzzt haben, und da waren teilweise Quicktime-Objekte drin, die dann beim Parsen in die Luft flogen. Und dann haben die das halt an ZDI verkauft. Ich wundere mich nur, dass Microsoft das zulässt. Und dass die da nicht nur ihre Namen sondern auch "(Microsoft)" dranschreiben.Discovered by: Tom Gallagher (Microsoft) & Paul Bates (Microsoft)
Ich habe also ein paar Abhilfen implementiert, um das zu beschleunigen. Die selben Dinge, die ich auch im Blog implementiert habe, im Wesentlichen. Ich sende einen Date-Header, einen Last-Modified-Header, und beantworte If-Modified-Since-Header. Chrome war unbeeindruckt. Ich habe dann zum Testen einen Expires-Header in der Zukunft eingefügt, und das hat auch nichts gebracht. Jetzt glaube ich, die Erklärung gefunden zu haben: Chrome cached keine Seiten über SSL mit "ungültigem" Zertifikat. Dazu gehören alle Zertifikate, bei denen die rote Warnseite kommt, die man wegklicken muss. Aber selbst wenn man die wegklickt, schmeißt Chrome alle Daten nach dem Anzeigen weg und cached nichts, auch nicht temporär nur im RAM.
Wenn also einer von euch bei meinem Blog aus Faulheit (nicht aus anderen, möglicherweise validen Gründen) das Root-Zertifikat von cacert.org nicht importiert hat, und stattdessen immer die rote Warnseite wegklickt, dann erzeugt das bei meinem Blog unnötigen Traffic. Ich bitte diejenigen, lieber das Root-Cert zu importieren. Und wenn einer von euch bei Chrome mitarbeitet, fände ich es prima, wenn ihr da mal Stunk machen könntet. Das Verhalten ist nicht akzeptabel. Das nicht auf Platte zu speichern ist OK, aber das nicht mal in der History im RAM zu halten ist in meinen Augen nicht zu verteidigen.
Es gibt für den Laden kein direktes Äquivalent in Deutschland, das wäre vermutlich sowas wie eine Mischung aus Rohde&Schwarz, T-Systems und IABG. Deren Beteuerungen sind grob vergleichbar mit Nokia Siemens Networks, die ja auch beteuern, ihre Hände durch die Ausgliederung von Trovicor reingewaschen zu haben. Von denen würde man sich ja auch keine Hackerveranstaltung sponsern lassen wollen.
Ich war ja immer ein Freund der holländischen Hackercamps, aber unter diesen Umständen gehe ich da lieber nicht hin.
(Falls jetzt jemand seinen PDF-Reader deinstallieren will: Foxit Reader kommt nicht von Fox-IT. Verschiedene Firmen.)
GCC now uses a more aggressive analysis to derive an upper bound for the number of iterations of loops using constraints imposed by language standards. This may cause non-conforming programs to no longer work as expected, such as SPEC CPU 2006 464.h264ref and 416.gamess.gcc 4.8 erzeugt falschen Code bei den SPEC Benchmarks. Die SPEC Benchmarks. DIE SPEC-BENCHMARKS!! Compilerhersteller kriegen seit Jahren von der Presse aufs Maul, wenn sie Spezialoptimierungen für die SPEC-Benchmarks einbauen, weil man das u.a. benutzt, um die Performance von Optimierern in Compilern zu messen. Und was macht gcc? Scheiß drauf, wir machen das mal kaputt. Ist ja nur die SPEC-Suite!1!!Die besteht im Übrigen aus lauter Programmen aus der echten Welt, das sind keine synthetischen Benchmarks. Die Programme, die gcc da zerschießt, sind auch ganz apart. h264ref kommt, wie der Name schon sagt, aus der H.264 Referenz-Implementation. GAMESS ist eine Software der Ames Labs (US-Regierungsinstitution) für Simulation von "Quantum Chemistry". Alle Teile in Spec sind Programme dieses Kalibers. In ihrem Fach sowas wie die Referenz für Code aus diesem Fachbereich. Und das wagen diese gcc-Sprallos kaputtzumachen. Und wofür?
Ein enormer Aufwand, der da getrieben wird. Lustigerweise hab ich kürzlich einen Bug gegen gcc gefiled, wo mir dann gesagt wird, dass sich diese Optimierung nicht lohnen würde. Ach aber SPEC kaputtmachen lohnt sich?
Inzwischen hat übrigens clang/LLVM soweit aufgeholt, dass sie auch Vektorisierung können. gcc ist daher aus meiner Sicht angezählt. Schade für das GNU-Projekt.
#include <string.h>
void foo(int x) {
char buf[10];
int i;
for (i=0; i<sizeof(buf); ++i)
buf[i]=x++;
memset(buf,0,sizeof(buf));
}
Die Funktion hat einen lokalen Puffer, buf, tut damit irgendwas (die sinnlose for-Schleife) und ruft dann memset auf. Das ist ein lokaler Puffer, der ist auf dem Stack und eh "weg", wenn die Funktion beendet wird. Insofern ist das gut, was gcc da macht. Und warum würde man überhaupt memset am Funktionsende machen, wenn der Buffer gleich weg ist!Nun, das kommt häufiger vor als ihr vielleicht denkt. Das macht man nämlich in Verschlüsselungs-Code, damit nicht Teile des Schlüssels irgendwo im Speicher rumgammeln, wo sie später gefunden werden können. Auch abgeleitete Daten will man so wegräumen. Das ist natürlich dann doof, wenn der Compiler das wegschmeißt.
Das Problem ist schon älter, der Microsoft-Compiler macht das schon länger so. Und weil das für Krypto-Code ein Problem ist, gibt es im Windows-API eine spezielle Funktion namens SecureZeroMemory, die am Ende auch nur memset macht, aber der Compiler weiß das nicht und optimiert es daher nicht weg.
Ich kompilier obige Funktion mal mit gcc 4.7.2:
$ gcc -O3 -c t.c $ objdump -dr t.o t.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <foo>: 0:f3 c3 repz retq $
Wie ihr seht ist von dem Körper der Funktion nichts übrig geblieben, weil natürlich auch die Schleife nur in einen Buffer schreibt, der dann nicht rausgereicht wird. Diese Optimierung nennt man Dead Store Elimination. clang/LLVM macht das schon länger. Der Intel-Compiler auch. Wenn ihr also Krypto-Code geschrieben habt, der memset benutzt, um Schlüssel wegzuräumen, und das war bisher kein Problem, weil ihr gcc benutzt habt: Jetzt ist das auch für euch ein Problem.
Diese Optimierung greift übrigens auch, wenn der Puffer nicht lokal auf dem Stack ist sondern per malloc vom Heap geholt und am Ende das memset vor dem free ist.
Typischer Anfängerfehler in Krypto-Code.
Vielleicht sollte ich noch sagen, was die Lösung ist: Eigenes memset haben, in eine Library tun (NICHT inline über ein Header-File!). Und nicht Link Time Optimization anschalten, sonst wird das doch wieder geinlined und fliegt möglicherweise insgesamt raus. Oooooder, wer ein bisschen das Abenteuer sucht, kann auch den gcc-Optimizer manuell davon überzeugen, das nicht wegzumachen. Dafür tut man hinter das memset folgende Zeile:
asm volatile("" : : : "memory");Langfristig vermutlich die solidere Lösung, tut aber nicht in clang (Bug, wenn ihr mich fragt; benutze aber auch den Subversion-Snapshot, nicht die Release-Version).Update: Lieber "asm volatile" als "asm". Sollte egal sein, ist es im Moment auch, aber ist vermutlich ein bisschen vorausschauender.
Update: Weil so viele Leute fragen, wieso man nicht den Puffer volatile deklariert: Das ist doof, weil es auch fast alle anderen Optimierungen ausschaltet. Wir reden hier von Krypto-Code, wo (allgemein gesprochen jetzt) jemand Monate investiert hat, um noch den letzten Taktzyklus rauszuoptimieren. Da will man den Optimierer schon grundsätzlich behalten.
Update: Hier empfiehlt gerade noch jemand das hier:
volatile size_t foo = (size_t)memset(buf,0,sizeof(buf));Das sieht gut aus, aber ich halte das eher für Glück. Der Compiler kann ja sehen, da das eine lokale Variable ist, und dass daher niemand von extern die Adresse haben kann (wenn man die nicht nimmt und irgendwas externes damit aufruft). Hab das aber jetzt nicht im Standard nachgeschlagen, ist nur Bauchgefühl.
Update: Habe einen Bug bei LLVM gefiled, und da hat jemand rausgefunden, dass dieses asm-Statement mit gcc und llvm funktioniert:
asm volatile("" : : "r"(&buf)" : "memory")Die Begründung ist, dass LLVM erkennt, dass das ganze Array nie benutzt wird, und es damit komplett entfernt, weil es "in Register gepasst hätte" (unabhängig davon, ob es tatsächlich in Register passt). Und tatsächlich, wenn man dafür sorgt, dass das tatsächlich im Speicher landet, dann wird auch ohne den Zusatz mit dem anderen asm-Statement ein memset ausgegeben. Insofern ist das kein Bug in LLVM sondern sogar ein Feature :-)
Update: Die Sudo-Sprallos veröffentlichen ernsthaft keine PGP-Signaturen für ihre Releases?!? Au weia.
Update: Oh und wo wir gerade bei peinlichen Bugs waren: Ubuntu fixt einen Buffer Overflow in cfingerd. Wo kommt der Bug her? Aus einem Ubuntu-Patch für cfingerd. Erinnert ein bisschen an das OpenSSL-Dingens damals.
Update: Ich höre gerade, dass OS X auch zu den Kinderunixen zählt, wo man ohne Superuserrechte die Systemzeit ändern kann. Und da steht "der User" auch im sudoers-File.
Ich dachte erst: Ziercke im Knast? GEIL!
Dann dachte ich: nee, warte, den Entwickler, nicht den Verantwortlichen. Nanu, Entwickler? Haben die doch gar keinen!
Dann dachte ich mir: Das BKA setzt doch gerade auf den Gamma-Trojaner! Martin Münch im Knast? GEIL!
Aber dann fiel mir ein, dass die den anderen BKA-Trojaner meinen.
Schade eigentlich.
Asked if the publicity he’s gotten for such surveillance powers inspires mistrust in the people he meets, Muench says he’s given up on a social life for now. “If I meet a girl and she Googles my name, she’ll never call back,” he says.Es ist unsere Pflicht, dass das auch allen anderen Leuten so geht, die an Trojanern mitarbeiten. Ich möchte an dieser Stelle nochmal ausdrücklich den Machern von Buggedplanet.info für ihre Arbeit danken. Wer berufsmäßig die Privatsphäre anderer zerstört, hat aus meiner Sicht selber auch keine verdient.
Researchers are purposefully placing bugs in open source software during the development stages, so that when code appears in completed products, those same researchers can highlight the flaws and profit from them where companies are willing to pay, Anderson has told TechWeekEurope. He claimed to know of several projects where this has happened, but declined to name names.Mit "companies" sind hier die 0-day-Buden gemeint, über die wir uns auch in Alternativlos 25 unterhalten hatten. Ross Anderson ist ein britischer Professor und einer der coolsten Leute, die es auf dieser Welt gibt. Wer das nach der Lektüre seines großartigen Buches "Security Engineering" nicht auch findet, für den habe ich noch eine kleine Anekdote.Das Bundesinnenministerium hatte eine Tagung organisiert, bei der es um Trusted Computing gehen sollte, Palladium war damals das Stichwort, und die Experten warnten vor Orwellschen Zuständen und erinnerten an die Vorgängertechnologie, bei der jede Intel-CPU eine eindeutige Seriennummer haben sollte, die per Software abfragbar ist. Das hatte ein öffentlicher Aufschrei verhindert, und das war der Präzedenzfall für Palladium, was im Wesentlichen eine Microsoft-Initiative war. Microsoft sah schlicht, dass sie den Kampf gegen Viren und Würmer verloren haben, solange man ihre Lösung Code Signing per Manipulation der Boot-Chain umgehen kann, wofür damals Software öffentlich vorgeführt worden war. Also musste das Code Signing früher ansetzen, schon im BIOS, und das Konzept dafür hieß Palladium. Das Innenministerium war besorgt und lud zu dieser Veranstaltung ein.
Als Experten waren u.a. ein Pressefuzzy von Microsoft geladen, und Ross Anderson, und vom CCC war auch jemand dabei, so kam ich als Kofferträger in die Veranstaltung rein. Der Pressefuzzy von Microsoft hielt zuerst seine Präsentation, wo er mit Powerpoint ein Multimedia-Desaster an die Wand projizierte, so mit animierten kleinen Viren, wie in der alten Zahnpastawerbung, die dann am Rechner hochkletterten, es war grotesk. Und danach war Ross Anderson dran. Der Projektor wurde ausgeschaltet. Jemand trug einen OH-Projektor rein. Ross Anderson legte handgemalte Folien auf. Handgemalt! Mit farbigen Filzstiften! Verschiedene Textpassagen mit anderen Farben, je nach Wichtigkeit. Das war so ein Kontrastprogramm, dass das Publikum erstmal ihren Kulturschock überwinden musste. Aber niemand sagte was, und Ross zog das mit einer professoralen Coolness ab, die ich so noch nie irgendwo anders gesehen habe. Der Mann rockt einfach.
Oh und man muss wissen, dass er an der Cambridge University eine Abteilung für Sicherheitsforschung aufgebaut hat, die seit Jahren die Bankindustrie geradezu vorführen, weil sie nacheinander alle Generationen von Chip&Pin-Karten und zwischendurch einige Hardware-Kryptomodule zerlegt haben. Von der Gruppe kommen auch häufig Hacker und tragen auf dem CCC-Congress vor. Gute Leute, diese Gruppe.
Insgesamt scheint das ein gutes Beispiel dafür zu sein, wieso Release Management wichtig ist. Das war gar nicht so, dass die Software völlig kaputt war, sondern die war im Testmodus konfiguriert, wo sie zum Simulieren eines Marktes immer am oberen Ende des Spreads Käufe in den Markt getreten hat, und am unteren Ende Verkäufe. Erfahrene Beobachter werden an der Stelle merken, dass man normalerweise billig kauft und teuer verkauft, nicht anders herum, sonst macht man Verlust statt Profit, und so war es dann auch. Innerhalb von 45 Minuten hat die Software 440 Millionen Dollar verpufft. Das klingt barbarisch viel, aber noch nicht so schlimm wie die anderen Milliardenverluste, von denen wir in letzter Zeit so gehört haben, z.B. der Jerome Kerviel, falls sich noch jemand an den erinnert, der fast fünf Milliarden verbrannt hat. Aber das war Lebensleistung, in diesem Fall war das innerhalb von 45 Minuten. Wenn man dieser Software so viel Zeit gelassen hätte wie den Menschen, dann wäre das noch mal eine ganz andere Kategorie geworden. Das ist schon die Kernschmelze, was hier passiert ist.
Bei der Gelegenheit stellen sich natürlich diverse Fragen. Erstens: wie konnte das durch die Qualitätssicherung? Wieso hat das nicht sofort jemand gemerkt? Ich weiß ja nicht, wie das bei euch ist, aber wenn ich ne neue Softwareversion einspiele, dann beobachte ich die erstmal ein paar Minuten, um zu gucken, ob was offensichtliches kaputt ist. Das dauert doch keine 45 Minuten, bis ich merke, dass meine Tradingsoftware nur Verlust einfährt!?
Und dann die Größenordnung. Die Berichte gehen auseinander, aber von 70% bis 100% der Marktkapitalisierung von Knight Capital hab ich gehört. Hallo? Bei so einem Laden fällt erst auf, dass gerade was schief läuft, wenn schon 50% des Kapitals weg sind!?!?
Dann: die Börsen haben Testsysteme zum Testen. Solche Software würde man an einem Testsystem testen, nicht am Livesystem. Kann sein, dass sie das gemacht und dann die Test-Config-Dateien mitkopiert haben. Oder sie haben es direkt am Livesystem getestet. Beide Optionen lassen tief blicken.
Kurz gesagt: wenn die auf dem Niveau arbeiten an den Kapitalmärkten, dann wundert mich gar nichts mehr. So eine Schlamperei würde man vielleicht von der Polizei oder der Bundeswehr erwarten, aber doch nicht vom freien Markt?! Private Betriebe sind doch so viel effizienter als Staatsmanagement!1!!
In the case of Pinkie Pie’s exploit, it took a chain of six different bugs in order to successfully break out of the Chrome sandbox.Wer sich jetzt denkt, hey, 6 Bugs in Reihe exploiten, das ist bestimmt eher die Ausnahme:In an upcoming post, we’ll explain the details of Sergey Glazunov’s exploit, which relied on roughly 10 distinct bugs.OMGWTF :-)
<? if ('9223372036854775807' == '9223372036854775808') { echo "hurz!\n"; } ?>Und wer gerade in der Stimmung ist: Eine Familienpackung PHP-Bashing!
Diese Kapitulation hat sich in den letzten Jahren konzeptionell bedrohlich verschlimmert, weil die Hersteller inzwischen dazu übergeben, von dem eh überforderten Bug-Fix-Team Budget abzuziehen und damit Mitigations zu bauen. Sandboxing ist ein Trend, den man gerade bei allen möglichen Browsern sehen kann. Ausgehend von Mobiltelefonen sind jetzt auch schon die regulären Betriebssysteme zusehends Sandbox-Umgebungen für die Anwendungen.
Ich halte das alles für Snake Oil, schlimmer noch, für aktiv sicherheitsreduzierend. Denn mit dem Geld, mit dem hier sinnlose Techniken eingeführt werden, hätte man wunderbar Bugs fixen oder gar den Entwicklungsprozess verbessern können.
Der aktuelle Höhepunkt in diesem Kasperletheater ist der Security-Chef von Adobe (Der Brüller! Adobe hat tatsächlich einen Security-Chef!)
Der hat sich tatsächlich hingestellt (auf einer Kaspersky-Konferenz, das passt auch mal wieder wie Arsch auf Eimer) und dem staunenden Publikum erklärt, dass es Adobe ja gar nicht darum geht, die Bugs zu fixen. Stattdessen sei das Ziel, das Ausnutzen der Bugs teurer zu machen. Und aus diesem Gesichtspunkt verurteilte er die Forscher, die es wagen, Papiere darüber zu veröffentlichen, wie man die sinnlosen Mitigations umgeht.
Kommt jemandem diese Argumentation bekannt vor? Genau so hat die Contentmafia es damals angestellt, dass das Umgehen von (egal wie lächerlich schwachen) Kopierschutz-Vorrichtungen unter Strafe zu stellen.
Wir als Kunden müssen uns gegen diese Leute zur Wehr setzen. Kauft keine Produkte von Firmen, die lieber in Mitigations als in ordentliche Entwickler-Schulungen und Qualitätssicherung investieren.
Falls die grotesken Aussagen von diesem Adobe-Clown demnächst aus dem Internet verschwinden, zitiere ich sie hier mal in Gänze:
“My goal isn’t to find and fix every security bug,” Arkin argued. ”I’d like to drive up the cost of writing exploits. But when researchers go public with techniques and tools to defeat mitigations, they lower that cost.”At Adobe, Arkin’s security teams have been working overtime to stem the flow of zero-day attacks against two of its most widely deployed products — Adobe Reader and Adobe Flash Player — and he made the point that too much attention is being paid these days to responding to vulnerability reports instead of focusing on blocking live exploits.
“We may fix one vulnerability that has a security characteristic but when we change that code, we are creating a path to other vulnerabilities that may cause bigger problems in the future,” he said.
Eigentlich könnte man den ganzen Artikel zitieren. Un-glaub-lich. Der weint da ernsthaft herum, dass Adobe ja soooo viele Bugs gemeldet kriegt, dass sie mit ihren Fixes mehr kaputtmachen als sie reparieren. Plötzlich geht Drucken nicht mehr und so. Das ist eine Selbstanklage von geradezu biblischen Dimensionen. Und der Höhepunkt des Unverständnisses:“We have patched hundreds of CVEs [individual vulnerabilities] over the last year. But, very, very few exploits have been written against those vulnerabilities. Over the past 24 months, we’ve seen about two dozen actual exploits,” Arkin said, making the argument that software vendors are not wisely using their security response resources.Hey, Arkin, DAS IST DER GRUND, WIESO MAN BUGS FIXT. Damit es nicht zu Exploits kommt! Wie konnte denn bitte diese Gestalt jemals Security-Chef werden?!Höhepunkt seiner Selbstzerfleischung ist die folgende Aussage:
Finding a bug is pretty straightforwardAha, soso, es ist also einfach, in Adobe-Software Bugs zu finden? Wieso tut ihr da nicht was gegen?
Die einzige gute Nachricht an der Stelle ist, dass das anscheinend nur den IA64-Branch betrifft, und IA64 ist ja eh tot.
The sources, however, said the investigators were surprised to find some computers with out-of-date software, misconfigured firewalls and uninstalled security patches that could have fixed known "bugs" that hackers could exploit. Versions of Microsoft Corp's Windows 2003 Server operating system, for example, had not been properly updated.So sieht das ja bei den meisten Firmen aus, die Windows im Einsatz haben. Je größer die Firma, desto antiker die Umgebung. Aber ausgerechnet NASDAQ hatte sich ja sehr weit aus dem Fenster gelehnt mit der angeblichen Güte ihrer Umgebung da, insofern ist das schon ein bisschen unerwartet.
Übrigens, kurzer Hinweis für andere Bundesländer: es gibt noch andere Trojanerlieferanten. Eine sehr umfangreiche Liste findet ihr bei buggedplanet.info. Das müsste mal jemand (Hint, Hint) mit dem EU-Amtsblatt zusammenführen, dann haben wir bis heute abend auch alle Skelette in den Kellern der anderen Bundesländer ausgebuddelt.
Die schlechte Nachricht: er bringt schonmal seinen Nachfolger in Position. Erinnert ein bisschen an Nordkorea.
Oh und einen humoristisches Detail hat die Story auch: Der Nachfolgekandidat ist ein Sizilianischer Justizminister. Und das klingt nicht nur wegen Sizilien und Justiz und von Berlusconi vorgeschlagen nach Mafia, nein, der Mann ist auch dadurch negativ aufgefallen, dass er am Mittwoch ein Gesetz durchs Parlament bugsiert hat, das das Bestechungs-Gerichtsverfahren gegen Berlusconi stoppen wird. Eine lupenreine Demokratie, dieser Berlusconi und seine ehrenwerte Gesellschaft.
Update: Die glibc-Patches, die das memcpy rückwärts kopieren lassen, kommen übrigens von Intel, weil sie auf dem Atom die Prefetch-Logik verkackt haben.
If there are any buffer overflows in your program, you should assume they are exploitable and fix them. It is much harder to prove that a buffer overflow is not exploitable than just to fix the bug.WHOA! Das ist eine Einsicht, die bei den meisten Firmen noch nicht angekommen ist. Die fangen dann immer noch zu verhandeln an, ob sie diesen Bug hier wirklich fixen müssen.
Ich sehe das anders, der CCC auch. Wir haben z.B. beim Wahlstift damit argumentiert, dass jemand einen USB Exploit fahren könnte. Solange man auch mit Windows-Autostart ans Ziel kommt, lohnt sich das natürlich nicht, da groß rumzuforschen, aber die Zeiten sind mit Windows 7 auch vorbei. Da kommt dann ein Popup, der einen explizit fragt, ob man den Autostart-Kram ausführen oder das Medium browsen will. Um da reinstecken-und-kisten-ownen zu kriegen, muss man schon den USB-Stack oder einen USB-Treiber angreifen. Das ist der erste mir bekannte Fall, wo das mal jemand gemacht hat. Daher: Hut ab! Respekt!
Ich finde sowas ja immer super, weil es schön die ganze Rhetorik von wegen Kompatibilität und plattformübergreifend und "write once" zersägt. (Danke, Nikolai)
The articles she wrote — all of which were selected from an algorithmically generated list — included How to Wear a Sweater Vest" and How to Massage a Dog That Is Emotionally Stressed," even though she would never willingly don a sweater vest and has never owned a dog."I was completely aware that I was writing crap," she said. "I was like, 'I hope to God people don't read my advice on how to make gin at home because they'll probably poison themselves.'
Genaugenommen läuft das sogar so, dass nicht mal garantiert ist, dass die dir den Artikel abnehmen. Und man kriegt so größenordnungsmäßig $30 für einen 1000-Worte-Artikel.
<img src="logo.svg">und alles wird gut, aber weit gefehlt! Stellt sich raus, dass Chrome das kann, Firefox aber nicht. Firefox erwartet ein object-Tag. Was für ein Hirnriss!
Aber das ist noch nicht alles. Stellt sich raus, dass Safari SVG kann (ist ja auch Webkit wie Chrome, damit war zu rechnen), aber NICHT auf dem Iphone oder Ipad. WTF?! Gerade das Ipad haben sie doch als Browser-Device verkauft!
An der Safari-Version kann man es nicht festmachen. Die Plattformstrings werden schnell unübersichtlich, es gibt da auch noch irgendein webtv-Zeugs, kenn ich alles nicht. Also ist da jetzt eine Javascript-Browsererkennung drin. Wie furchtbar ist DAS denn alles?! Ich dachte, die Zeiten seien vorbei im Web?
Also aus meiner Sicht: Schande über Apple und Firefox.
Und zur Krönung des Tages kommt hier auch noch einer an, der benutzt Epiphany mit Webkit, und das gibt sich als Safari unter Linux aus. Das bau ich da jetzt nicht ein. Was für ein Müll dieses Web doch ist.
Oh und bei Firefox ist offenbar das UI für das audio-Tag kaputt und man kann da nicht die Lautstärke regeln. Na suuuuuper. Bin ich wirklich der erste, der das Audio-Tag benutzt?! Ist das echt noch keinem aufgefallen?!?
Das Problem, wenn man seinen ganzen Scheiß selber schreibt, ist, dass gelegentlich was nicht funktioniert, und dann muss man rumdebuggen. Heute habe ich mal wieder eine längliche Session hinter mir. Das Symptom war, dass libjava in gcc nicht baut. Das erste Problem war, dass gcc ein GNU cmp feature benutzt, nämlich --ignore-initial, welches mein cmp nicht implementiert. Meine Versionen der Utilities implementieren im Allgemeinen nur die Features, die von der Single Unix Specification verlangt werden.
gcc möchte dieses cmp-Feature haben, weil der Buildprozess Dateien vergleichen will, ohne die ersten 16 Bytes mitzuvergleichen. Daher guckt configure, ob cmp die Option kennt, und wenn nicht, dann gibt es einen Fallback auf tail +16c in Tempdateien. Ich habe zwar auch ein tail, aber das war nicht in meinem $PATH, da war das tail von coreutils. Und das kennt seit ein paar Versionen +16c nicht mehr. Tolle Wurst.
Stellt sich raus, dass mein eigenes tail das doch gekannt hätte. Das habe ich mal aus genau dem Grund implementiert. Gut, weiter im Text. Kompiliert immer noch nicht. Symptom sind irgendwelche Linkfehler im Java-Toolkit. Stellt sich raus, dass da in einem .zip-File irgendwelche Klassen fehlten. Hat auch nur einige Stunden gedauert, das rauszufinden. Stellt sich raus, dass die folgendes tun: cp -pR dir1 dir2. Problem 1: mein cp kannte nur -r, nicht -R. Mein Fehler, schnell gefixt. Problem 2: mein cp hat sich geweigert, die Kopie durchzuführen, wenn das Zielverzeichnis schon existierte. Problem 3: mein cp hat dann zwar eine Fehlermeldung rausgehauen, aber keinen nonzero-Exitcode gehabt, daher hat der gcc-Build nicht abgebrochen. Nachdem ich das gefixt hatte, läuft der gcc-Compile anscheinend durch. Ich sage anscheinend, weil ich das in meinem 3 GB Ramdisk zu kompilieren versucht habe, und die war voll. 3 GB ist zu wenig, um gcc zu kompilieren. O tempora, o mores. Ich habe hier noch eine 40 MB Platte rumliegen irgendwo. Ja, MB. Nicht GB.
Oh und warum wollte ich gcc kompilieren? Um Dragonegg auszuprobieren. Und: Es funktioniert! Coole Scheiße!
Also haben Bug-Finder angefangen, der Öffentlichkeit zu erzählen, dass sie auf einem Bug sitzen, den sie für kritisch halten. Das interessiert normalerweise zu wenig Leute, um Firmen wie Apple zu motivieren.
Also gibt es das Konzept Full Disclosure. Man erzählt der Öffentlichkeit direkt von dem Bug, und zeigt auch genau, wo er ist. Dann haben es die Hersteller plötzlich immer sehr eilig und sind auch plötzlich überraschend in der Lage, innerhalb von Tagen einen Fix zu produzieren. Natürlich sind die Hersteller über sowas unglücklich und heulen rum. Das führt dazu, dass viele Securityfirmen ihren Mitarbeitern untersagen, ihre Bugs zu veröffentlichen, bevor es einen Fix vom Hersteller gibt, weil sie sonst womöglich weniger Aufträge kriegen. Meine persönliche Lösung ist, dass ich gar keine Bugs veröffentliche, weil ich gar nicht erst unbeauftragt nach Bugs suche. In Open Source Software, wenn ich einen Bug finde, file ich ihn, aber in Closed Source Software gucke ich gar nicht erst. Wenn was nicht geht, investiere ich keine Zeit in Debuggen, warum es nicht geht. Unter dem Strich verlieren also alle gegenüber Full Disclosure.
Nun, warum erzähle ich das alles? Weil man hier gerade hervorragend sehen kann, wie der nächste Schritt aussieht. Das ist ein Blog von Verizon, von deren Sparte, die Security verkauft. Das ist also kein Hersteller, sondern eine Security-Firma, sozusagen. Und die sind jetzt soweit, dass sie nicht nur Full Disclosure untersagen, sondern offen gegen Full Disclosure auftreten und sogar Hacker als Kriminelle und Bug-Veröffentlicher als "Narcissistic Vulnerability Pimp" beschimpfen.
Das ist so das schlechtestmögliche, was sie hätten sagen können. Es gibt auch für sie keinen Grund, das so zu sagen, denn wenn Leute Lücken veröffentlichen, hat Verizon mehr Punkte auf ihrer Liste, was sie bei einem Pentest beim Kunden alles checken können. Die einzige Motivation, so einen hanebüchenen Mist zu bloggen, ist, weil sie bis zum Anschlag im Rektum ihrer Auftraggeber versunken sind, und die Perspektive verloren haben. Man kann ihre Angst förmlich riechen, ihre Kunden zu verlieren. Nach Spaß am Gerät klingt das jedenfalls nicht für mich. Au weia. Da würde ich mir ja lieber einen neuen Beruf suchen, als mir öffentlich so eine Blöße zu geben.
Ein Detail noch: ich habe gehört, Verizon macht für die US-Regierung Aufträge, u.a. auch IT-Security bei Militärbasen. Die einzigen, die einen handfesten Vorteil davon haben, wenn Bugs nicht veröffentlicht und gefixt werden, sind Militärs.
Update: Weil ich darauf angesprochen wurde, ob man gefundene Lücken nicht auch unter Pseudonym oder anonym veröffentlichen kann. Klar, kann man. Ist auch eine gute Idee. Also, äh, für andere Leute. Nicht für mich. Iiiich würde sowas niemals tun!1!! *hust* *aufdieuhrguck* Oh guckt nur, wie spät es schon ist *weglauf*
open("/lib/fimware/updates/radeon/R520_cp.bin", O_RDONLY) = -1 ENOENT (No such file or directory)"fimware". Ja, fimware! udev versucht, die Firmware aus dem falschen Verzeichnis zu laden! Hab ich was kaputtkonfiguriert, würde man denken. Schaunmermal:$ cd /tmp/udev-152Wenn Inkompetenz weh tun würde, wären diese Knalltüten schon längst im künstlichen Koma. Versager, wo man hinguckt.
$ grep -r fimware .
./configure: with_firmware_path="/lib/fimware/updates:/lib/fimware"
./configure.ac: [with_firmware_path="/lib/fimware/updates:/lib/fimware"]
Dann brauchten wir ein devfs. Da hießen dann plötzlich alle Devices anders. Klar, liegt ja auch nahe. Also haben wir alle Software anfassen müssen, die mit Devices operiert.
Dann reichte das plötzlich nicht mehr, und wir brauchten udev. Da hießen dann plötzlich wieder alle Devices anders. Klar, liegt ja auch nahe. Also haben wir wieder alle Software anfassen müssen, die mit Devices operiert.
Das reichte dann plötzlich auch nicht mehr. Wir brauchten ein Layer darüber, "hald", von den Freedesktop-Spacken. Das habe ich noch nie irgendwo funktionieren sehen, es ist die Krätze auf Erden, ein unfassbarer Haufen Scheiße, das geht gar nicht. Der Antichrist persönlich würde sich in Grausen abwenden, wenn es ihn gäbe. Es ist so furchtbar, dass selbst seine Erfinder sich jetzt davon abwenden. Das neue X 1.8 zieht jetzt seine Device-Informationen nicht mehr aus hald, sondern aus udev. Das führt bei mir dazu, dass er weder Maus noch Keyboard findet. Warum auch. Braucht man ja auch nicht. Natürlich beendet sich X nicht, wenn er keine Devices findet, sondern er bleibt hängen, so dass man die Kiste resetten muss, um es wieder zu beenden. TOLLES ENGINEERING, ihr Spacken!
Nach nur wenigen Stunden meiner Lebenszeit, die ich in diesen undebugbaren Haufen Mist stecken mußte, habe ich folgende Lösung gefunden:
Section "ServerFlags"Ich neige ja an sich nicht zu Gewaltphantasien, aber diese Leute haben Ferien in Abu Ghraib verdient.
Option "AutoAddDevice" "false"
Option "AllowEmptyInput" "false"
EndSection
Oh und von dbus fange ich gar nicht an, das setzt dem nochmal eine Krone auf. Wieso erfinden die Leute alle Automatismen, die dann nicht automatisch funktionieren, sondern umfängliche Konfigurationsarbeiten benötigen?! Ich erinnere mich mit Grausen daran, diese furchtbare Bluetooth-Grütze debuggen zu müssen, die plötzlich dbus wollte. KOTZ!
Ich will an der Stelle mal einen Freund zitieren:
die freedesktop-leute spenden ja sonst ihre gesamte zeit damit, linux und x11 zu einem single-user-system zu machen. jetzt sind sie wohl noch einen schritt weiter beim zero-user-system
Das hat mich über die Jahre so viel Zeit gekostet und soviel Ärger gemacht, dass es auf dem besten Weg ist, den Ärger aufzuwiegen, den ich in der Zeit mit bei Windows bleiben gehabt hätte. Es ist eine Schande, dass wir es so weit kommen lassen. Ich bin ja fast gewillt, das langsam als Zersetzungsstrategie aufzufassen, zumal da ja auch die ganzen Distro-Versager mitpfuschen, die offensichtlich alle das Geheimwissen als Firmengeheimnis behalten wollen, das man braucht, um ihren Automatismus-Müll zum Funktionieren zu bewegen.
Bugs are understood to have been placed in the cabinet room, the waiting room, and the prime minister's study, at the request of Harold Macmillan in July 1963. They remained there until James Callaghan removed them in 1977.Oh und auch die Briten haben natürlich eine "Geheimdienstaufsicht", und die ist offensichtlich nicht weniger eine Farce als unsere.
"libcpu" is an open source library that emulates several CPU architectures, allowing itself to be used as the CPU core for different kinds of emulator projects. It uses its own frontends for the different CPU types, and uses LLVM for the backend. libcpu is supposed to be able to do user mode and system emulation, and dynamic as well as static recompilation.Das wäre quasi sowas wie qemu in statisch. Ausgesprochen cool. Wenn das was taugt, kann man damit auch diverse Code Obfuscation Dinger automatisch rückgängig machen. Das ist aktuell der neueste Schrei, wie man Debuggen erschwert. Und wenn das erstmal stabil läuft, kann man es auch dynamisch in Page Fault Handler oder über Breakpoints einbauen.
In secret meetings that draw on elements of Haitian Voodoo, Cuban Santeria and Mexican witchcraft, priests are slaughtering chickens on full moon nights on beaches, smearing police with the blood and using prayers to evoke spirits to guard them as drug cartels battle over smuggling routes into California.Wer schon mal einen wackeligen SCSI-Bus debuggen mußte, der wird Verständnis für diese Methoden haben. (Danke, Tobias)
Update: Die sind auch in den Root-Zertifikaten von OS X, mailt mir gerade jemand.
Update: Und angeblich sind die auch bei Windows im Certificate Store.
So hatte ich vor einer Weile das Problem, dass auf meinem Notebook mein WLAN nicht mehr funktionierte. Das lag daran, dass der Intel-WLAN-Treiber anfing, eine Firmware hochzuladen, und dafür das Hotplug-Interface zu benutzen. Hotplug, das ist eine archaische Shellskript-Sammlung von Greg Kroah-Hartmann, in einem Shellskript /sbin/hotplug gipfelnd, das dann andere Shellskripte aus /etc/hotplug/* aufruft, und dort die eigentlichen Daten über magische Environment-Variablen übergibt. Nach einer Weile rumdebuggen habe ich damals rausgefunden, dass das Hotplug sich aus den magischen Environment-Variablen (der ganze Prozess ist m.W. nicht brauchbar dokumentiert) einen Pfad zusammenpopelt, und dann am Ende cp aufruft, um /lib/firmware/radeon/RV770_me.bin nach /sys/devices/platform/r600_cp.0/data zu kopieren. Welches cp das am Ende wird, das hängt von $PATH ab. Ich habe ein /usr/bin/cp, ein /bin/cp und ein /opt/diet/bin/cp, alle unterschiedlich. Mein /usr/bin/cp ist von GNU coreutils, und das meinte der Autor von hotplug wohl. /bin/cp ist ein Notfall-cp aus einer alten Version von embutils, falls ich /usr nicht mounten kann oder mir die glibc zerschossen habe. /usr/bin ist vor /bin im Pfad, daher betrifft das nie jemanden. /opt/diet/bin/cp ist das aktuelle cp aus embutils, das ist für meinen User noch vor /usr/bin im Pfad. Hotplug wird aber direkt vom Kernel aufgerufen und erbt daher das Environment von init. Und das hat das Default-Environment, das der Kernel setzt beim Aufruf von init, nämlich
PATH=/sbin:/bin:/usr/sbin:/usr/binAm Ende hat hotplug also das alte Notfall-cp aufgerufen, das in Blöcken zu 1024 Bytes kopiert. Versteht mich nicht falsch: alle dieser cp Binaries sind willens und in der Lage, eine Datei zu kopieren, und hotplug benutzt auch keine komischen GNU-only Flags. Aber das Firmware-Interface des Kernels hat damals Dinge angenommen, die nur GNU cp so gemacht hat. Ich habe die genauen Details vergessen, aber das Notfall-cp hat 1024-Bytes geschrieben, und der Kernel nahm an, dass die Firmware in nur einem Chunk geschrieben wird, und daher schlug das fehl.
Nachdem ich meine Fassungslosigkeit überwunden habe, habe ich damals /etc/hotplug/firmware.agent angefasst, damit er händisch /usr/bin/cp aufruft und nicht bloß cp über $PATH, und damit war das Problem gelöst.
Gestern habe ich jetzt anlässlich dieser Meldung hier den Kernel 2.6.32-rc6 auf meinem Desktop probiert. Mein Desktop hat kein WLAN und lädt an sich keine Firmware. Auf meinem Desktop ist auch seit irgendwann mal vorbeugend /bin/cp ein Symlink auf /usr/bin/cp. Um so größer war meine Überraschung, als mit dem neuen Kernel plötzlich X nur noch ohne Grafik-Beschleunigung hochkam. Nach einer Packung debuggen stellte sich raus, dass er die Firmware nicht laden konnte. Nachtigall, ick hör dir trapsen, dachte ich mir, und prüfte, ob /bin/cp das richtige ist. War es. Mhh, nanu. Ich habe also geprüft, ob hotplug das richtige cp aufruft. Tat er, /usr/bin/cp. Komisch. Weiter debugged. Mal ein strace auf /usr/bin/cp gemacht. Und, was soll ich sagen, /usr/bin/cp kopiert bei mir in 32k-Blöcken. Mein embutils-cp benutzt hingegen mmap und kopiert in 4 MB Blöcken. Also habe ich /etc/hotplug/firmware.agent angefasst, damit er /opt/diet/bin/cp aufruft, und was soll ich euch sagen, jetzt ist mein X wieder beschleunigt.
Nur damit ihr mal seht, auf was für einem Treibsand-Fundament dieses Linux gebaut ist.
Wobei wahrscheinlich ich über drei Ecken Schuld bin. Mein coreutils ist Version 7.6, das ist AFAIK aktuell, aber meine hotplug-Shellskripte sind von 2006. Vielleicht gibt es da ein Update inzwischen.
Aber die Ironie, dass dieses Firmware-Interface so verstrahlt ist, dass es erst mit dem Fefe-cp nicht tat, und jetzt mit dem GNU-cp nicht tut, und ich es fixen kann, indem ich das Fefe-cp benutze, das ist schon grotesk. Freut euch alle, dass ihr solche Details nicht sehen könnt bei euren Distributionen. Und, falls das hier jemand liest, der für das Firmware-Laden-Interface im Kernel verantwortlich ist: SCHANDE! SCHANDE! SCHANDE!!
Update: hotplug ist seit Jahren obsolet und sollte ja eh nicht mehr installiert sein, weil es durch udev abgelöst wurde, was ich ja auch installiert habe. Nur leider hat das Vorhandensein von udev bei mir nie dazu geführt, dass der Kernel nicht trotzdem hotplug aufruft. Jetzt habe ich einige Zuschriften gekriegt, die mir erklärt haben, dass man beim Booten
echo > /sys/kernel/uevent_helpermachen muss. Nun starte ich ja beim Booten den udevd, und hätte mir gedacht, hey, wenn ich den da schon starte, dann ist der bestimmt auch so smart, obiges zu tun. Ist er aber nicht.
Einer der Forscher hat mir das so erklärt: der Cipher berechnet einige Werte doppelt, und hat auch die Logik dafür doppelt. Normalerweise würde man sowas rausoptimieren, weil man ja bei Chips immer die Gatter minimieren will, die machen schließlich den Preis aus. Der Effekt ist, dass der Cipher komplexer aussieht als er ist. Mit anderen Worten: … sieht wie eine Hintertür aus.
Das Ausrechnen des ersten Angriffs dauert allerdings eine Stunde, nachdem man 10 Sekunden mit der Karte kommuniziert hat. Ein anderer Angriff geht schneller, muss aber dafür 5-15 Minuten mit der Karte reden. Es gibt da noch mehr Angriffe, lest euch das mal selber durch (das andere Paper).
Alter one of the parameters and you have access to EVERYTHING: users, activation codes, lists of bugs, admins, shop, etc.Und DIE sollen die Windows-Rechner der Welt absichern?!
Mal gucken, was die dazu sagen. Das wäre sozusagen das SSH-Sicherheitsmodell. Wir haben sowas ähnliches im Moment bei self-signed certs, dass er sich das Zertifikat merkt und später nicht mehr rumheult, wenn das gleiche Cert wieder kommt. Nur wenn dann jemand MITM mit einem Cert von Verisign macht später, dann kriege ich das nicht mit, dass das nicht mehr das self-signed cert ist, dem ich mal vertraut habe.
Und das schockierende: vor mir hat das offenbar noch keiner gemerkt. Ich bin anscheinend der einzige, der Firefox aus den Sourcen kompiliert und dann auch Bugs filed, wenn was nicht klappt.
Übrigens: kann ich noch nicht empfehlen. Erstens ist der Javascript JIT offenbar nur für x86, nicht für x64-64, und zweitens gehen natürlich mal wieder die ganzen Add-Ons nicht mehr.
Das Problem bei Windows war, dass man da einen AcceptEx-Call mit overlapped I/O losgetreten hat, und der eine Call nahm dann halt eine Verbindung an, und signalisierte erst, wenn der was schickte. Wenn jetzt aber jemand eine Verbindung aufbaute und nichts schickte, dann nahm der Server gar keine Sockets mehr an. Kurz gesagt: ein dummes Denial of Service.
Nun, Linux hat auch sowas:
int one=1;Das habe ich irgendwann gesehen, in libowfat abstrahiert, und dann in gatling eingebaut. Und jetzt stelle ich gerade fest, dass die Linux-Implementation ein sehr ähnliches Problem hat. Nur halt dass nicht ein Socket für das DoS ausreicht.
setsockopt(sockfd,IPPROTO_TCP,TCP_DEFER_ACCEPT,&one,sizeof(one));
Ich habe da gerade eine Stunde rum debuggt (weil ich auch in meinem libowfat-Code gerade herum experimentiere und erst dachte, ich hab dabei was kaputt gemacht), bis ich beim Blick auf netstat gesehen habe, dass da 16 Verbindungen im SYN_SENT bzw SYN_RECV Stadium waren (SYN_SENT beim Client und SYN_RECV beim Server, liefen auf der selben Kiste hier), und ein Socket im SYN_SENT ohne dazu gehöriges SYN_RECV. 16 ist genau das Limit, das ich bei listen() als Backlog übergeben hatte. Die Verbindungen zählen also als "halbe Verbindungen", die man aber nicht annehmen kann; vom Problem her mit einer Syn Flood verwandt.
Und da fiel es mir wie Schuppen von den Augen. Das Linux-API ist gut gemeint aber ist in Wirklichkeit ein DoS gegen sich selbst, zumindest in der aktuellen Implementation in 2.6.27. Zu allem Überfluss wird das DoS auch noch von meinem eigenen bei gatling beiliegenden Benchmark-Tool getriggert. Ich hatte gedacht, dass mal bei früheren Versionen getestet zu haben, aber habe keine Aufzeichnungen und bin mir auch gerade nicht mehr sicher. Im Moment ist jedenfalls klar: vor dieser Funktionalität kann ich nur warnen. Benutzt das nicht in eurer Software!
Danke an Johannes, der mich überhaupt erst auf das Problem hingewiesen hat.
Die Theorie bei MCE ist, dass der Fehlercode nach einem Reset-Knopf-Einsatz noch lesbar ist, d.h. man startet dann ein Dekoder-Tool, und das dekodiert einem die Nachricht. Habe ich getan, hat nichts gefunden. Also doch kein MCE? Ich habe also einen älteren Kernel gebootet, und mit dem kriege ich plötzlich ein paar richtige MCE-Meldungen. Das ist ein Hex-String der Form
CPU 0: Machine Check Exception: 4 Bank 0: b200004000000800Und wenn man das durch das Decoder-Tool laufen lässt, kommt folgendes dabei raus:
CPU 0 BANK 0 MCG status:MCIPIch weiss nicht, wie euch das geht, wenn ihr das lest, aber ich brauche für diesen Decoder noch einen Decoder. Ist das jetzt ein RAM? Die CPU? Das Mainboard? Hach, Computertechnik ist schon was tolles. Und wahrscheinlich lohnt es sich angesichts der aktuellen Hardwarepreise auch gar nicht, da gross rum zu debuggen. Seufz.
MCi status:
Uncorrected error
Error enabled
Processor context corrupt
MCA: BUS Level-0 Originated-request Generic Memory-access Request-timeout Error
BQ_DCU_READ_TYPE BQ_ERR_HARD_TYPE BQ_ERR_HARD_TYPE
timeout BINIT (ROB timeout)
STATUS b200004000000800 MCGSTATUS 4
Das britische Flugzeug des Ferienanbieters First Choice mit 229 Passagieren an Bord war eben erst in Manchester gelandet. Da bemerkte das Bodenpersonal beim Entladen des Gepäcks, dass von einem Elektro-Rollstuhl im Frachtraum bläulicher Rauch aufstieg. Angestellte bugsierten den Rollstuhl darauf aus dem Flugzeug und stellten ihn auf einen Gepäckwagen. Darauf explodierte das Gefährt.Ab jetzt werden Rollstuhlfahrer am Flughafen noch weniger Spaß haben, fürchte ich.
Update: Ja, ist gefixt in der Snapshot-Version. (Danke, Michael)
Bosnian Serb wartime leader Radovan Karadzic was protected by the United States until a CIA phone bug caught him breaking the terms of his "deal", the Serb newspaper Blic reported Saturday, quoting a US intelligence source.The newspaper claims Karadzic was secretly granted immunity in return for keeping a low profile.
Die Türkei ist seit Atatürk laizistisch, und das Militär hat traditionell dafür gesorgt, dass da keine Fundamentalisten an die Regierung kommen. Insofern ist das nicht völlig von der Hand zu weisen. Aber was die da gleich alles an Verschwörungsgeschichten haben, das wärmt mir das Herz:
Tatsächlich spricht einiges dafür, dass Basbug den Teil der Armee repräsentiert, den die Geheimorganisation "Ergenekon", zu deren Mitglieder die Verhafteten gehören sollen, erst unter Druck setzen wollte - damit sich das Militär letztlich einer Machtübernahme nicht entziehen kann.Und sie haben da Details zu bisherigen Putsch-Plänen, 2002 und 2004, die offenbar am Generalstabschef Hilmi Özkök gescheitert sind. Es gab da ein Tagebuch des Marinechefs, das geleakt ist, und was der Admiral natürlich als Fälschung bezeichnet hat. Dann ist da noch die Rede von Zypern als Auslöser des Putsches:Wie Ismet Berkan, Chef der linksliberalen "Radikal", in einem Leitartikel darlegte, gibt es aber viele Indizien dafür, dass bereits seit Amtsantritt der Erdogan-Partei AKP 2002 ein Teil des Offizierskorps darüber diskutierte, die Regierung "unbedingt zu stoppen". Damals war der am Dienstag verhaftete General Sener Eruygur Chef der Gendarmerie, und Hursit Tolon, der zweite verhaftete General, Heereschef.
Obwohl die Anklage gegen insgesamt mittlerweile rund 60 "Ergenekon"-Verhaftete erst in den kommenden Tagen vorgelegt werden soll, ist schon so viel bekannt: Die Organisation soll versucht haben, durch politische Attentate, gezielte Manipulation der Öffentlichkeit und mit Unterstützung besonders nationalistischer ziviler Organisationen so viel Chaos und Aufruhr zu schaffen, dass das Volk nach der Armee ruft - die die Ordnung wieder herstellt.Und als ob das nicht schon alles hart genug wäre, gibt es dann auch noch eine angebliche Todesliste, u.a. soll das Militär auch hinter dem Mord des höchsten Richters gesteckt haben. Es steht auch ein Wechsel des Generalstabschefs an, und von dem neuen munkelt man, er sei für die Putschpläne.
Auch hatte der Ministerpräsident den künftigen Generalstabschef Basbug zu einem privaten Gespräch unter vier Augen eingeladen. Vorausgegangen war eine Kampagne islamistischer Zeitungen, die ein Foto von Basbug an der Klagemauer in Jerusalem druckten, um ihn als "Krypto-Juden" zu diskreditieren, der nicht Generalstabschef werden dürfe.(Danke, Mathias)Erdogan soll dem Heereschef in dem Gespräch versichert haben, dass er seine Ernennung zum Generalstabschef unterstütze. Dass bei dem Treffen, sozusagen im Gegenzug, auch über das "Ergenekon"-Verfahren gesprochen wurde, hat Basbug allerdings heftig dementiert.
Denn das Argument, Hunde lügen nicht, war für die Richter bislang allzu verführerisch. Der Theorie zufolge orientiert sich der Hund beim Mantrailing an niedergefallenen Hautschuppen eines Menschen. Bei deren bakterieller Zersetzung bilden sich Gase, die das Tier riechen und verfolgen kann. Bei idealen Wetterbedingungen sollen so Spuren angeblich auch noch nach Tagen oder gar Wochen identifiziert werden können.Nee, klar.
Doch ob ein Hund tatsächlich die Spur eines Verdächtigen aufgenommen hat oder nicht, ist schwer zu sagen - weil das Verhalten des Vierbeiners von seinem Führer interpretiert werden muss. Und der kann, wie alle Zeugen, irren. Das sahen die Richter des Bamberger Landgerichts anders. Für sie waren die Hundeführer "neutrale Zeugen", die "detailliert, kongruent und frei von Widersprüchen" ausgesagt hätten.Keine weiteren Fragen, euer Ehren.
Ich bin ja dafür, Richter nach solchen Fehlurteilen direkt die Gefängnisstraße antreten zu lassen, die sie jeweils verhängt haben. Wer denkt, das war schon die Krönung, sieht sich getäuscht:
Die Ermittler setzten nicht etwa Polizeihunde mit entsprechend ausgebildeten Beamten ein, sondern Amateur-Tiere eines Hundesportvereins, der sich "Mantrailer Bayern" nennt. Als Hundeführer agierten ein Kinderpfleger, ein Informatiker und - immerhin - ein Diensthundeführer der Bundeswehr.Das ist offenbar eine ähnliche Wachstumsbranche wie Esoterikmessen und ähnlicher Humbug. Wenn man mit solchen Blendern zusammen arbeitet, dann muss man normalerweise schon aktiv weggucken, um nicht auf die klaren Hinweise aufmerksam zu werden, dass man es mit Blendern zu tun hat. So auch in diesem Fall:
Klaus H., der Kinderpfleger, dessen Hund Bärschneiders Unterhose als Vergleichsprobe zu riechen bekam, blamierte sich mit einem entschiedenen Ja/Nein. Zunächst gab er an, sein Hund habe "nichts gefunden". Angesichts der Tatsache, dass seine Vereinskameraden Erfolge gemeldet hatten, kam er dann jedoch "zu dem Schluss", sein Hund habe "sehr wohl Witterung aufgenommen, wenn auch nicht so intensiv wie die beiden anderen".Unfaßbar. Auswandern, echt mal.
Solche Angriffe gibt es immer wieder. Den bisher spektakulärsten fand ich einen, der anhand des Timings der Pakete bei einer SSH-Sitzung über Wahrscheinlichkeiten und Tastenabstände getippte Worte rekonstruiert hat, und sogar Passwörter raten bzw den Suchraum stark einschränken konnte.
Das generelle Problem von Timingangriffen betrifft auch z.B. TOR, was ja immer wieder gerne als Lösung für anonymes Webklicken empfohlen wird. Aus den Paketen läßt sich der einzelne User gut rekonstruieren. Aus der Ecke wird noch einiges auf uns zukommen.
Update: gibt sogar schon einen Bug von 2002 dazu :-)
Date Public 03/30/2008Ach ja? Tatsächlich? Ist das so, ja? Völlig unbekannt vor 2008, das Problem, wie? GRRRR!
Und wer ist überhaupt dieser Russ Cox? Plötzlich ist das ein Kategorie ZOMFG Problem, und Onkel Fefe kriegt nicht mal einen Keks dafür. Außerdem ist das Advisory auch noch falsch, denn man muss einen positiven Wert dazu zählen, damit gcc das wegoptimiert. Übrigens, in dem Original-Bug steht, dass sie das gefixt haben. Haben sie nicht. In gcc 4.3 ist das immer noch so.
Update: Sie haben das Advisory geupdated, es linkt jetzt auf mich! Yeah! (Danke, Justin)
Diesmal geht es um Abschneiden von Integer-Werten. Das ist ein seltener Bug, aber es wäre trivial für gcc, in dem Fall eine Warnung rauszuschmeißen. Ich habe schon Produktionscode auditiert, der den Bug hatte, das ist also nicht theoretisch. Die Idee ist folgende:
int needed=0;Wenn die Liste nicht aus tatsächlich allozierten Dingen besteht (oder auf einer 64-bit Plattform läuft), sondern sagen wir aus Regionen in einer in den Speicher gemappten Datei, oder einer virtuellen Sache wie bei einem Webserver in einer HTTP-Anfrage die Ranges, dann ist das ein Integer Overflow. Bug 1 ist, dass hier int benutzt wird, das ist vorzeichenbehaftet, das gibt nur Ärger. Bei einem Overflow kommt am Ende ein negativer Wert raus, und dann hat man Code wie diesen:
struct node* l;
for (l=listhead; l; l=l->next) {
needed+=l->chunksize;
}
if (needed < MAX_ALLOC) {
buf=malloc(needed);Wenn needed negativ ist, läuft der Check durch, aber malloc nimmt size_t, der Compiler konvertiert das implizit, und dabei wird das dann ein sehr großer Wert und je nach System klappt womöglich sogar die Allokation.Bug 2 ist, dass der Overflow nicht abgefangen wird. Wenn ihr euch an das hier erinnert, ist das der 2. Grund, keine vorzeichenbehafteten Werte für Längen oder Größen zu nehmen. Gut, nun nehmen wir mal an, jemand konvertiert das nach unsigned long long, um den Overflow loszuwerden. Haben wir alles schon gehabt. Er checkt auch ordentlich, dass es bei der Addition keinen Überlauf gibt. Aber auf einem 32-bit System ist size_t normalerweise 32-bit breit, und unsigned long long ist 64-bit breit. Bei der Übergabe des Arguments schneidet gcc daher den oberen Teil ab. Ein schlauer Angreifer kann dann den Wert so zurecht fummeln, dass die Summe nach Abschneiden 1 ergibt, aber in der Reinkopier-Schleife dann mehr reinkopiert wird. Ein klassischer Heap-Overflow.
Daher mein Vorschlag, dass man bei Allokations-Längen dem Compiler mitteilen kann, dass hier ein Abschneiden ein echtes Problem wäre.
Wenn die gcc-Leute sich weigern, werde ich bei der dietlibc wahrscheinlich so etwas wie das hier machen:
#define malloc(x) ({typeof(x) y=x; (y<0 || (size_t)(y)!=y ? 0 : malloc(y));})Kommentare? Übrigens möchte ich bei der Gelegenheit auch noch mal meine Integer Overflow Seite pluggen.
Oh, und weil man da nicht oft genug drauf linken kann: Operation Clambake. Jedes Mal, wenn ich da rumblättere, bin ich entsetzt, was für eine schlechte Prosa dieser Hubbard hatte. Wenn der wenigsten ein gutaussehender, charismatischer Mann gewesen wäre, der gut schreiben kann, aber nicht mal das! Ich kriege Ausschlag, wenn ich da auch nur Auszüge von lese. Sowas hanebüchenes kann ich nicht einmal ohne Schmerzen konsumieren, wie kann man das auch noch glauben?! Naja, jedem das Seine. An dem Tom Cruise Video neulich hat man ja gesehen, was dieser Humbug aus Menschen machen kann :-)
Aber macht euch keine Sorgen, ist nur halb so schlimm, denn die Daten aller Apple-User sind eh alle schon dank der sieben Remote Exploits in Quicktime korrumpiert oder gelöscht.
One particular bug that has appeared exists not in Mozilla, but in IPv6-capable DNS servers: an IPv4 address may be returned when an IPv6 address is requested. It is possible for Mozilla to recover from this misinformation, but a significant delay is introduced.Under certain versions of OS X, this bug is compounded by another bug wherein the OS still makes IPv6 DNS requests even if IPv6 support is disabled. A significant delay is introduced in all connections requiring DNS lookups while the OS and the DNS server exchange unnecessary (or redundant) queries and responses to resolve the address.
Kann man sich gar nicht ausdenken, sowas.
struct node {
struct node* next, *prev;
};void foo(struct node* n) {
n->next->next->prev=n;
n->next->prev->next=n;
}
Die Lektion an der Stelle sollte sein, daß n->next zwar wie ein gemeinsamer Teilausdruck aussieht, den Compiler normalerweise wegoptimieren, aber der Compiler es trotzdem nicht tut, weil hier eben über Zeiger auf Speicher zugegriffen wird. Insbesondere könnte n->next->next->prev so ungünstig liegen, daß bei der ersten Zuweisung n->next überschrieben wird. Das nennt sich Aliasing, und an sich darf der C-Compiler daher hier kein CSE machen. Ich kompiliere das also, und folgender Code kommt raus:movq (%rdi), %rdxWie man sieht, hat gcc hier n->next in rdx gecached. Dieser Code kommt selbst dann raus, wenn man gcc -Wno-strict-aliasing mitgibt. Also vielleicht übersehe ich da ja gerade noch was, aber für mich sieht das wie ein gcc-Bug aus. Seufz.
movq (%rdx), %rax
movq %rdi, 8(%rax)
movq 8(%rdx), %rax
movq %rdi, (%rax)
BP executives working for Lord Browne spent millions of pounds on champagne-fuelled sex parties to help secure lucrative international oil contracts.The company also worked with MI6 to help bring about changes in foreign governments, according to an astonishing account of life inside the oil giant. […]
Mr Abrahams tells how he spent £45 million in expenses over just four months of negotiations with Azerbaijan's state oil company.
Armed with a no-limit company credit card, he ordered supplies of champagne and caviar to be flown on company jets into the boomtown capital, Baku, to be consumed at the "sex parties".
The hospitality continued in London, where prostitutes were hired on the BP credit card to entertain visiting Azerbaijanis. […]
He described a Wild West world in which oil executives with briefcases full of dollars rubbed shoulders with mafia members, prostitutes and fixers and cut their deals in smoke-filled back rooms. […]
"Sometimes I would charter an entire Boeing 757 to carry as few as seven staff. Their main base was the hard currency bar of the old Intourist hotel - so named because it accepted only dollars and was only open to foreigners.
It was full of prostitutes and many of us, including me, used them on a regular basis, although we quickly established they all worked for the KGB.
If we went back to the rooms, not only were they bugged, but the girls would quiz us closely about what we were doing and where we were going, and reported straight back to their handlers.
Everywhere was bugged, and all the phones were tapped. One of our executives was recorded saying unflattering things about the president, and his comments were played back to us in a meeting with local state oil company officials.
We were then told clearly that he was no longer welcome in the country.
Großartige Räuberpistole… kein Wunder, daß die Briten das ungerne in der Presse sehen würden.
I disagree. Saying you can either crash or get owned is a false dilemma.Crashing instead of getting owned does not help the customer, because he can still lose his data. He won't get a worm (unless you missed some other wormable issue), but still, that's just reducing the severity from "critical" to "moderate". It's still a bug. The customer still wants it fixed. The only one who has an actual advantage of this is you, because you only have to answer for a DoS, not a worm.
So my point of view is: crashing if you detect an error is a cop out, an ass covering mechanism big companies like to use, because it's easier to crash than to implement error handling.
Similar issue: using try/except to catch AVs and then pop up a window saying "uh, that Word file smelled funny". That is not error handling, that is ass covering.
Security is never simple. Security is work. Yes, you will actually have to do something to make your code more secure. Just adding a try/except or SafeInt band-aid does not make the product more secure, it's just ass covering. Why am I paying $500 for a piece of software that does not even really try to be secure but just applies some ass covering filter?
I'm not just ranting about Windows here, btw. Linux has limited the size_t arguments to read() and write() to below 2 gigs, because some crappy kernel code might use signed ints for lengths, and then it would blow up. O RLY? That's not security, that's just ass covering. And coming from the GNU people who used to distinguish their software from other Unix software by removing arbitrary limits.
This attitude is pervasive in the software industry, and I hate it. Also because you will do the work twice. First you will apply a band-aid, then someone will find a way around your band-aid, or someone will notice that a crash during trying to save a document can destroy data and is just as bad for the customer, and you will have to fix it again, this time for real.
Ein Fehler im Telnet-Dienst ermöglicht einem Angreifer darüber hinaus die Anmeldung mit Root-Rechten, in dem er nur einen präparierten Nutzernamen angibt.… dann kommt mir spontan das hier in den Sinn :-)
nicht nur -froot, auch ein $IFS-Problem! BWAHAHAHAHA, the 80ies called, they want their bugs back.
What were you doing when the application crashed?
smoking a joint.
Also ich bin ja fast zu wetten gewillt, daß das irgendeine DRM- oder Copyright-Enforcement-Kacke ist, an dem das wieder hängt. Irgendein Antidebug-Scheiß vielleicht? Mann Mann Mann. Das ist selbst für Apple-Verhältnisse schlecht, und hey, das heißt was.
Update: Oh, hier ist noch was schönes:
In light of the recent extremely long article about how cool Macs are, I figured I would provide instructions on how to wreck a brand spankin' new not-even-off-the-shelf Apple Macintosh computer.
- Go to the Apple store.
- Get on a brand new computer.
- Run the Calculator widget.
- Type 99999999*99999999 in the widget.
- Hold down the Enter key until the numbers stop changing.
Voila.
Der Browser (als IE7, Mozilla macht bei diesem Humbug nicht mit) soll dann die URL-Leiste grün hinterlegen.
Jetzt ist eine Studie rausgekommen, die zeigt, daß mit Extended Validation Certificates Phishing-Erkennungsraten nicht steigen. Im Gegenteil, wenn man die User schult, sinken die Phishing-Erkennungsraten sogar. Und wer hat die Studie gemacht? MS Research. Autsch!
Manche Leute sagen ja, sie virtualisieren, damit die OS-Images austauschbar bleiben. Das halte ich für ein Scheinargument. Man kann auch ein OS Image haben, das mehrere Hardware-Plattformen unterstützt.
Es gibt eigentlich nur einen Grund, wieso Virtualisierung in meinen Augen cool ist: man könnte damit einen echt fetten Debugger schreiben. Einen Kernel-Debugger, wie ihn die Welt noch nicht gesehen hat. Naja, die PC-Welt sagen wir mal :-)
Xen und Konsorten finde ich profund uninteressant. Interessiert mich nicht die Bohne. Nicht mal mit Anstrengung kann ich mir irgendwas daran überlegen, das mich auch nur am Rande interessieren könnte. Und was wird da für eine Zeit mit verschwendet! Also, Leute, gebt mir ein Soft-Ice 2.0 in Form eines Hardware Hypervisors. DANN habt ihr meine Aufmerksamkeit. Aber bleibt mir mit diesem ganzen Xen-Scheiß vom Hals.
assert(len+100 > len);len ist ein int. Hier sind zwei Beispielprogramme: int.c (signed) und unsignedint.c (unsigned). Nicht zu fassen. Das betrifft konkret den gnupg-Patch. FINSTER. Probiert das mal bei euch aus. Ich habe hier amd64 und x86 und kann das mit gcc 4.1.1 bei beiden nachvollziehen. Sehr gruselig. Was jetzt? Ich werde mal einen Bug bei gcc einreichen, aber ich fürchte ja, daß da wieder irgendein Language Lawyer kommt und mir sagt, daß man das formaljuristisch so auslegen kann in C.
Update: Hier ist der Bug, und wie ihr sehen könnt, findet der gcc-Typ, der an dem Problem Schuld ist (das gibt er in dem anderen Code-Stück zu), daß das in Ordnung ist, wenn Leute geownt werden, weil er eine Optimierung formaljuristisch rechtfertigen kann. Krank. Da fragt man sich ja schon, für was man eigentlich Audits macht, wenn man dann so torpediert wird. Oh, übrigens: mit icc (dem Intel-Compiler) kriegt man korrekt eine Assertion.
Update: Der Kracher: das macht so viel Software kaputt, daß die autoconf-Leute darüber nachdenken, -fwrapv zu den Default-Optimierungen zu tun, was das alte Verhalten wieder anschalten. Way to go, GNU! Macht ja nichts, wenn euer Schweinecompiler anderer Leute Software kaputt macht, solange ihr einen Workaround für eure eigene Software habt!1!!
Update 2: Offenbar optimieren auch gewisse gcc 2.95.* und gcc 3 Versionen (3.4.6 auf MirBSD und 3.4.3 auf Dragonfly BSD) diesen Code weg, aber der offizielle Workaround (-fwrapv) existiert nicht bei diesen gcc-Version. Die Antwort des gcc-Typen, der an dem ganzen Problem Schuld ist (Andrew Pinski) ist: gcc 2 und 3 sind nicht mehr supported und im Übrigen "why should we support older GCC when we can barrely support the current ones".
Update 3: Und Florian Weimer hat schon 2002 gesagt, daß das mal passieren würde. (Danke, Sebastian)
Obol is a specialized high-level programming language for security protocols. […] The language is interpreted, and the runtime written in Java.But wait, there's more!vtmalloc is a fast memory allocator for multi-threaded applications and Tcl. It provides low contention and the ability to return memory to the system.Ooooh NOCH mehr:SpadFS is an attempt to combine features of advanced filesystems […] crash recovery […] journaling […] hash […] btree]Changes: The main fixes are some spadfsck crashes and creating bad directory entries when a user tried to create s filename longer than 255 characters.
Oh Mann, und NOCH so einer:The Akelos Framework is a PHP4 and PHP5 port of the Ruby on Rails Web development framework.OH NOOOOOOOO!OMFG, und hier ist noch ein schöner, damit hier nicht immer nur schlechte Nachrichten kommen:
sendmail 8.14.0.Beta4: Changes: Header field values are now 8-bit clean. […] This release also contains various bug features, […]
Nun kann ich mit einem Speicherleck eher umgehen als mit crashender Infrastruktur, und so habe ich das kurzerhand auskommentiert. Dann crasht git nicht mehr, aber das update schlägt immer noch fehl:
Fetching head…Ihr glaubt ja gar nicht, wie wenig Toleranz ich solcher Kinderkacke gegenüber aufzubringen habe. Ich habe das jetzt nicht genug debugged, um mit Sicherheit sagen zu können, daß curl Schuld ist, aber curl hat mich ja schon damit gegen sich aufgebracht, daß ich nach dem Update alle Applikationen neu linken mußte, die dieses Stück Sondermüll benutzen, insbesondere centericq und ogg123. NERV!!
Fetching objects…
error: Request for c9701c80af9b9c3be27dfe4076280a24aa3059dd aborted
Getting pack list for http://elinks.or.cz/elinks.git/
error: Unable to start request
Getting alternates list for http://elinks.or.cz/elinks.git/
error: Unable to find c9701c80af9b9c3be27dfe4076280a24aa3059dd under http://elinks.or.cz/elinks.git/
Cannot obtain needed none c9701c80af9b9c3be27dfe4076280a24aa3059dd
while processing commit 0000000000000000000000000000000000000000.
progress: 0 objects, 0 bytes
cg-fetch: objects fetch failed
These are the packages that would be merged, in order:
Calculating world dependencies… done!
Traceback (most recent call last):
File "/usr/bin/emerge", line 3263, in ?
mydepgraph.display(mydepgraph.altlist())
File "/usr/bin/emerge", line 1652, in display
verboseadd += create_use_string(key.upper(), cur_iuse_map[key],
cur_use_map[key],
KeyError: 'elibc'
You need to update portage. `emerge portage` should do the trick."Can't make this shit up.BTW: Das Problem hat sich geklärt.
Aber wie ich meine Freunde von freedesktop.org kenne, machen die keine halben Sachen. Wenn kaputt, dann auch verbrannte Erde. Und tatsächlich, es gibt da jetzt knapp 300 Pakete. Sah erst nicht so schlimm aus, weil ich nur gezogen hatte, was im X11R7.1 Verzeichnis lag. Stellt sich raus, daß das nur die Hälfte ist! Die Pakete, die sich seit X11R7.0 nicht geändert haben, die haben sie nicht rüber gesymlinkt, sonst könnte ja noch jemand darauf kommen, daß man die auch ziehen muss!
Und nun muss man sich mal in die Lage von freedesktop.org versetzen. Man gibt den Leuten 300 Pakete, die in unklarer Weise voneinander abhängen. Wieso überhaupt 300 Pakete? Weil die da echt mit dem Fleischwolf kompartmentalisiert haben; ein Dutzend der Pakete beinhalten überhaupt nur Header! Kommen natürlich trotzdem mit configure-Skript und allem Tamtam:
Seht ihr die sagenhafte Effizienz dieses Systems? Für nicht mal 10k Nutzdaten haben sie mir fast 200k Müll geschickt.-rw-r--r-- 1 leitner users 1315 May 17 2005 COPYING
-rw-r--r-- 1 leitner users 415 Mar 31 10:39 ChangeLog
-rw-r--r-- 1 leitner users 223 May 9 2005 Makefile.am
-rw-r--r-- 1 leitner users 15837 May 20 16:58 Makefile.in
-rw-r--r-- 1 leitner users 21739 May 20 16:58 aclocal.m4
-rwxr-xr-x 1 leitner users 195 May 5 2005 autogen.sh
-rwxr-xr-x 1 leitner users 81157 May 20 16:58 configure
-rw-r--r-- 1 leitner users 225 Mar 31 10:39 configure.ac
-rwxr-xr-x 1 leitner users 9233 May 20 16:58 install-sh
-rwxr-xr-x 1 leitner users 11014 May 20 16:58 missing
-rw-r--r-- 1 leitner users 1962 Mar 31 10:39 saver.h
-rw-r--r-- 1 leitner users 5349 Mar 31 10:39 saverproto.h
-rw-r--r-- 1 leitner users 4298 Mar 31 10:39 scrnsaver.h
-rw-r--r-- 1 leitner users 197 May 9 2005 scrnsaverproto.pc.in
Das ist ja schon ziemlich grobe WMD-Qualität, freedesktop.org blieb überhaupt nur eine Möglichkeit, das noch schlimmer zu machen: sie dokumentieren nicht die Abhängigkeiten. Ja, I kid you not, die Abhängigkeiten sind nicht dokumentiert. Und als ob sie genau wüßten, daß ich Python-Software aus religiösen Gründen nicht auf meine Platte lasse, bieten sie ein Build-Tool an, das in Python geschrieben ist. Und wo ist das dokumentiert? In ihrem… Wiki. Kann man sich noch lächerlicher machen? Oh ja, man kann! Indem man die pkg-config (JA! Das erwähnte ich noch nicht, sie verwenden tatsächlich das Schweinetool aus der Hölle, _pkg-config_!) Pakete anders benennt als die Verzeichnisse und Tarballs (Beispiel: evieproto -> evieext-X11R7.0-1.0.2). Kurz gesagt: in der Zeit, mit der ich mich jetzt schon darüber aufgeregt habe, habe ich das früher dreimal gebaut, und ich habe hier noch nicht mal den X-Server fertig gebaut, geschweige denn irgendwelche Grafiktreiber.
But wait, there is more! Es gibt Patches für Sicherheitslücken. In X11R7.1 liegen die Patches, aber die gepatchten Pakete sind von X11R7.0, und der Patch heißt nicht mal komplett so wie der zu patchende Tarball, und, ja liebe Gemeinde, es geht noch übler, die Patches haben nicht mal die selbe -p Konvention! Manche brauchen -p0 bei patch, andere -p1. Offensichtlich wollte da jemand verhindern, daß man das automatisiert oder im Halbschlaf bauen kann.
Was für Sicherheitslücken sind denn das, werdet ihr jetzt wissen wollen? Das Projekt ist 25 Jahre alt, das müssen ja immens subtile Dinge sein, die sie da jetzt erst gefunden haben, richtig? Sie haben vergessen, bei seteuid den Rückgabewert zu prüfen. OMFG!!
Ihr werdet euch jetzt fragen, wie ich das überhaupt gebaut kriege mit den Abhängigkeiten und so. Ich rufe configure bei dem Paket auf, das ich wirklich haben will, warte eine Minute, dann laufe ich den Abhängigkeiten hinterher. Rekursiv.
Liebe Freedesktop-Leute, wenn ich euch mal im Dunkeln begegne, und zufällig einen Clue-by-Four dabei habe, dann gnade euch Gott!1!!
Update: Beeindruckend. Vier Stunden später, X startet, lädt den richtigen Treiber, aber weigert sich dann, etwas anderes als 640x480 zu fahren. Alle an die Wand stellen nach der Revolution, das sage ich euch.
MyOODB (My Object-Oriented Database) is an integrated database and Web environment that provides true distributed objects, implicit/explicit multi-concurrent nested transactions, seamless Web tunneling, and database self-healing. MyOODB is one part of a two part SDK solution. Together with MyOOWEB, MyOOSDK provides a development environment for people who desire small, fast, but powerful applications.Das reicht ja vermutlich schon, um das Bullshit-Meter des durchschnittlichen Fefeblog-Lesers zum Abbrechen des Zeigers zu bewegen, aber mal schauen, ob wir da vielleicht noch mehr herausholen können. Erste Beobachtung: wir werden mit Buzzwords geflutet, und zwar nicht nur mit bekannten, sondern auch mit frisch erfundenen ("seamless Web tunneling"). Das ist schon mal ein klares Indiz für einen Java-User. Dazu kommt, daß "OO" im Namen ist (nur Java-Deppen halten das per se für eine Errungenschaft oder Wert). Und wenn da so eine Bloat-Sickergrube auch noch als klein und schnell beschrieben wird, dann ist ja evident, daß der Autor nichts kann. Dieser Eindruck verstärkt sich noch, wenn man den "My" Prefix betrachtet. Wer das für ein Qualitätsmerkmal hält, kann nicht viel Erfahrung haben. Self-Healing, yeah right. Und, liebe Leser, Transaktionen anständig hinzukriegen, dazu noch performant und korrekt, das ist nicht einfach, selbst wenn man weiß, was man tut (was hier ja offensichtlich nicht der Fall ist). Da liegt die Vermutung nahe, daß er seine Transaktionen verkackt hat. Mal schauen, was das Changelog sagt:This release fixes a bug where if the "Mighty Write" was piggybacking on another nested transaction, rollback might fail.HAHAHAHAHAHA
But wait, there's more! zu strfry gibt es auch noch ein Security Advisory (das ich allerdings für hirnrissig halte, das könnte man genau so gut bei strlen bemängeln), und der absolute Oberhammer ist dieser Debilian Bugreport. Un-fucking-believable. Wenn es ein Code-Killfile gäbe, Ulrich Drepper wäre drin.
Oh, und wo wir gerade beim glibc-Bashing sind: man kann bei der glibc Callbacks definieren, um bei printf neue Format-Zeichen zu definieren. Und nun ratet mal, welche Qualitätssoftware dieses großartige Feature benutzt: richtig, reiserfsprogs. Die definieren damit z.B. einen Callback, um ein Tupel von zwei Zahlen auszugeben IIRC. Unfaßbar. Aber hey, reiserfs benutzt ja eh niemand, oder? Oder?!
Vielleicht sollte ich echt mal eine Webseite aufmachen, und dort ein Coder-Killfile unterhalten. Drepper, die Reiserfs-Jungs, Schilling, … da kämen aber nur die besonders harten Fälle hin. Ich will ja auch noch zu anderen Sachen kommen.
Ich beobachte aber auch, wie immer weniger Leute bereit sind, überhaupt hinreichend Energie in etwas zu investieren, um sich damit jemals in die Nähe einer Perspektive zu bringen, Hacker zu werden. Natürlich kann nicht jeder überall der Oberheld sein, aber ich erwarte schon von jedem, daß er genug Ausdauer hat, sich in zumindest ein Thema mal tiefschürfend genug einzuarbeiten, daß ihm dort keiner mehr etwas vormachen kann. Und das kann ich immer weniger beobachten. Die Leute tendieren heute eher zu einer Art Universal-Durchschnitt. Die Abstände zwischen tollen neuen Hype-Trends werden immer kleiner, keiner hat mehr Zeit und Lust, sich die Sachen genauer anzugucken. Als ich jung war (*hust*), kamen PCs noch mit Handbüchern, in denen alle Befehle von GWBASIC beschrieben wurde, genau so wie debug.com und link.exe. Später wurden diese Sachen nicht mal mehr mitgeliefert. Ich war jung und hatte Zeit und habe mir das dann eben in Ruhe angeguckt. Ich enthülle hiermit: man wird Hacker, indem man Zeit hat und sie aufwendet, um sich mit einem Thema gut genug auszukennen, daß man mehr weiß als die Autoren der Standard-Fachliteratur zum Thema. Je nach eigenem Anspruch kann man sich auch nur dann Hacker nennen, wenn man sich in einem Gebiet erschöpfend auskennt, zu dem es (noch) gar keine Literatur gibt… :-)
Und dabei waren die Voraussetzungen noch nie so gut wie heute zum Hacker-Werden! Es gibt heute freie Betriebssysteme mit Editor, Compiler, Assembler und Linker kostenlos im Internet — mit Quellcode! Es kostet nichts mehr (außer Zeit), sich in die Sachen richtig gut einzuarbeiten! Man muss nicht mal Bücher kaufen, und heutzutage gibt es Suchmaschinen. Ihr wißt ja gar nicht, was das für ein Luxus ist, Kinder!
Zurück zum Thema. Heute kann jeder Hacker werden, der nur genug Zeit investiert. Als Hacker gewinnt man enorm an Selbstsicherheit, man ist gefragt auf dem Arbeitsmarkt, alles ist prima, aber aus irgendeinem Grund werden die Leute heute nicht mehr Hacker. Stattdessen hat die Verfügbarkeit freier Software zu einer Anspruchshaltung geführt, daß die Leute finden, wenn man schon nichts für Download und Installation zahlen muss, dann muss man auch danach keinen Aufwand investieren müssen. Den Nachwuchs in meinem Bekanntenkreis wird eher so High-Level-Fummler, klickt sich GUI-Anwendungen in einer IDE zusammen, hackt ein Python-Skript zum Mail-Sortieren, hat ein bißchen Java aus der Uni mitgenommen, steigt gerade auf C# um, sowas. Womit ich das nicht abwerten will, aber Hacken ist was anderes.
Es ist besser, in einer Sprache richtig gut als in 20 Sprachen Anfänger zu sein. Denkt da ruhig mal aus Sicht eines HR-Menschen drüber nach. Stellt euch vor, ihr seit der Headhunter, und ihr wäret mit einem Lebenslauf konfrontiert, bei dem jemand ein paar Applets (das klingt schon von alleine mittelmäßig und irgendwie abwertend) in Java gemacht hat, der gerade Windows Forms in Visual C# zusammenklicken lernt, der ein paar dynamische Webseiten mit PHP gemacht hat. Für was für einen Job soll so jemand denn bitte qualifiziert sein? Zum ct Lesen? Anspruchsvolle Jobs kann man so jemandem doch gar nicht geben! Wer sich nur oberflächlich mit Sachen beschäftigt, der wird auch nur oberflächliche Jobs bekommen. Was für eine grauenvolle Vorstellung… Insofern: setzt euch hin, sucht euch etwas aus, das ihr am besten noch nicht kennt, und arbeitet euch richtig tief ein. Nehmt euch dafür ein paar Monate. Hört erst auf, wenn ihr das Gefühl habt, selbst der Erfinder der Sache könnte euch nichts wirklich überraschendes mehr dazu erzählen. Solche Leute braucht das Land, nicht noch mehr Visual Basic Pfuscher.
{kind=link}
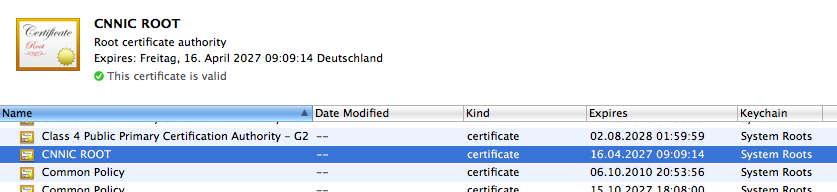{kind=link}